COPYRIGHT © 2016-2017 by Michael Herman, Toronto, Canada. All rights reserved.
First Draft: April 5, 2017
This article documents a number of parallel efforts to improve the usability, understandability, utility, and correctness of the ArchiMate 3.0 Specification. In particular, this article extends a well-received previous article Crossing the EA Chasm: Graphitization of ArchiMate 3.0 – Iteration 1 where I posed the question:
Wouldn’t it be nice to have an authoritative reference for ArchiMate 3.0, more specifically, a repository for the enterprise architecture language‘s elements and relationship matrix, that is queryable.
This article documents the current iteration of the ModelMate project, Iteration 2, whose goal is to create an improved queryable repository for a corrected version of relationship matrix (more correct relative to the Appendix B tables in the current ArchiMate 3.0 Specification).
Background
Over the past few months, I’ve written several articles commenting on the current state of the ArchiMate language for Enterprise Architecture including:
- Modeling a Company and Its Locations, Markets, Employees, Investors & Roles: Proposals, Wishes & Dreams
- Crossing the EA Chasm: Graphitization of ArchiMate 3.0 – Iteration 1
- Crossing the EA Chasm: Re-visioning ArchiMate 3.0 Relations as Verbs
- Crossing the EA Chasm: Reflections on the Current State of ArchiMate
- Crossing the EA Chasm: Re-visioning the ArchiMate Specification
- Crossing the EA Chasm: ArchiMate “Keep Calm and Have IT Your Way”
In addition, there are almost weekly postings about usability issues or errors with the Specification in the Linkedin ArchiMate group, the GitHub Archi issues log, LinkedIn Pulse, and the Google ArchiMate group; as well as other forums [1][2].
The recent effort, called the ModelMate project, is a focused effort to create a more broadly applicable, usable, useful, ArchiMate-based, extensible language environment for enterprise architecture as described in these 4 articles:
- Crossing the EA Chasm: ArchiMate 3.0, fix it or re-purpose it?
- Graphitization of the Enterprise
- Graphitization of Ray Dalio’s Principles: Iteration 1
- Graphitization of Ray Dalio’s Principles: Iteration 2
Current Scenario
The current scenario is highlighted by the following points taken from the above references:
- “[People should be] encouraged to try to model these examples for yourself: to start learning how to “think in ArchiMate” as your second or third written language.” The way the ArchiMate language is currently designed and, more importantly, described makes this difficult.
- In an abstract sense, the extension of the ArchiMate language is supported but, in reality, few if any broadly adopted extensions have appeared in the market. A better approach is described here: Crossing the EA Chasm: ArchiMate 3.0, fix it or re-purpose it?
- There is no single, authoritative, machine-readable version of the ArchiMate 3.0 relationship matrix; let alone one that is easily accessible and queryable.
- The Open Group’s insistence on using abstract terminology to name element types and relation types presents users with additional challenges.
Problem Description
At a data level, the root causes of the problems with the ArchiMate 3.0 relationship matrix in Appendix B of the ArchiMate 3.0 Specification include:
- No machine-readable version of the tables are available for external validation for correctness
- The tables contain errors in the approximately 11,000 relations that are represented in the tables. Is is estimated that there are few hundred to a few thousand errors present in the current ArchiMate 3.0 tables
- The tables contain all possible (valid) relations but do not differentiate between Core relations and Derived (non-Core) relations.
All three issues are critical for the ArchiMate 3.0 Specification and these tables to be trusted and more generally useful.
In addition, the Derived Relation Derivation Algorithm has never been published by The Open Group. Attempts to create an alternative algorithm have highlighted that the text of the ArchiMate 3.0 Specification is neither consistent nor complete when it comes to identifying the set of Core Relations and a correct and complete Derviation Algorithm.
Lastly, when dealing with 1000+ Core Relations and several thousand Derived Relations (8000-9000 or more), it’s difficult to analyze and visualize what the ArchiMate 3.0 relationship matrix looks like in total, or when subdivided by Domain (Layer) or Aspect, or when focused on a specific element prototype (e.g. Node).
Solution Overview
The goal of this solution is to publish a very detailed, rich, unnormalized version of the latest and greatest ArchiMate 3.0 relationship matrix in multiple formats; including:
- CSV text file
- Microsoft Excel workbook
- Microsoft Access database
- Neo4j Cypher Query Language (CQL) queryable graph database file
When loaded into Microsoft Excel, the CSV and Microsoft Excel workbook format files appear as shown in Figure 1 (below).
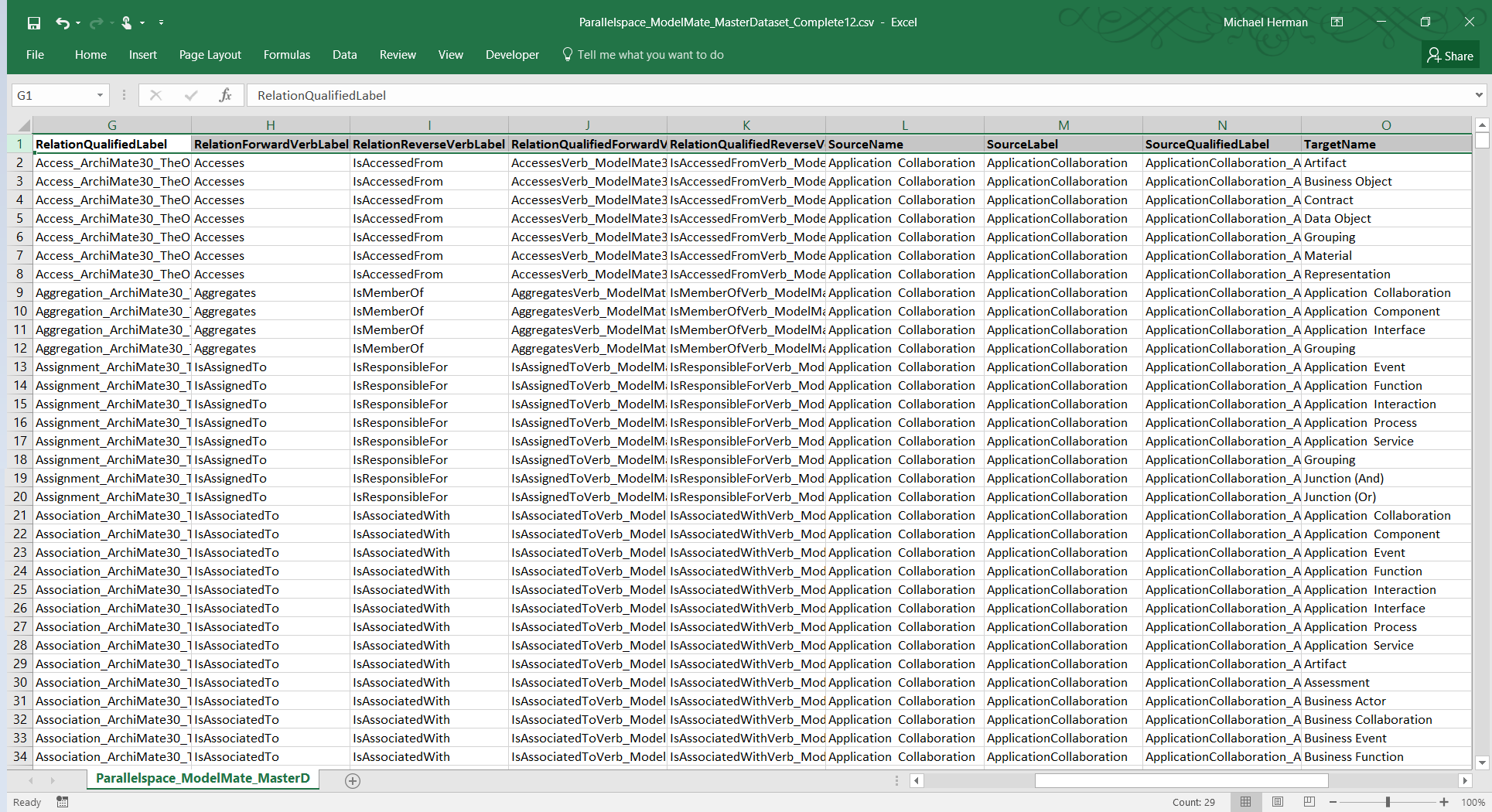
Figure 1. ModelMate Master Datasets: Excel 2016 and CSV File Formats
The Microsoft Excel (and CSV) format file can also be used with the Microsoft Excel Web App (Figure 2) and the Microsoft Excel format can be used to create custom SharePoint lists (Figure 3).
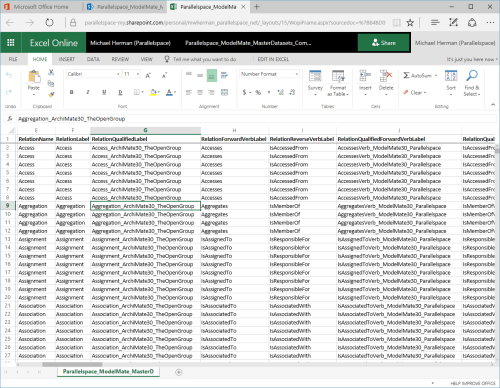
Figure 2. ModelMate Master Datasets: Excel 2016 format file in MIcrosoft Excel Web App
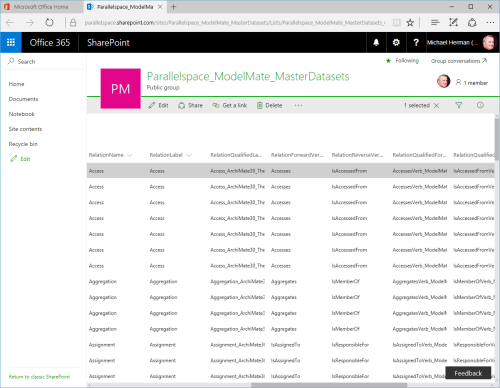
Figure 3. ModelMate Master Datasets: Custom SharePoint List created from Imported Excel 2016 Format File
When loaded into Microsoft Access, the Microsoft Access database format files appear as shown in Figure 4 (below).
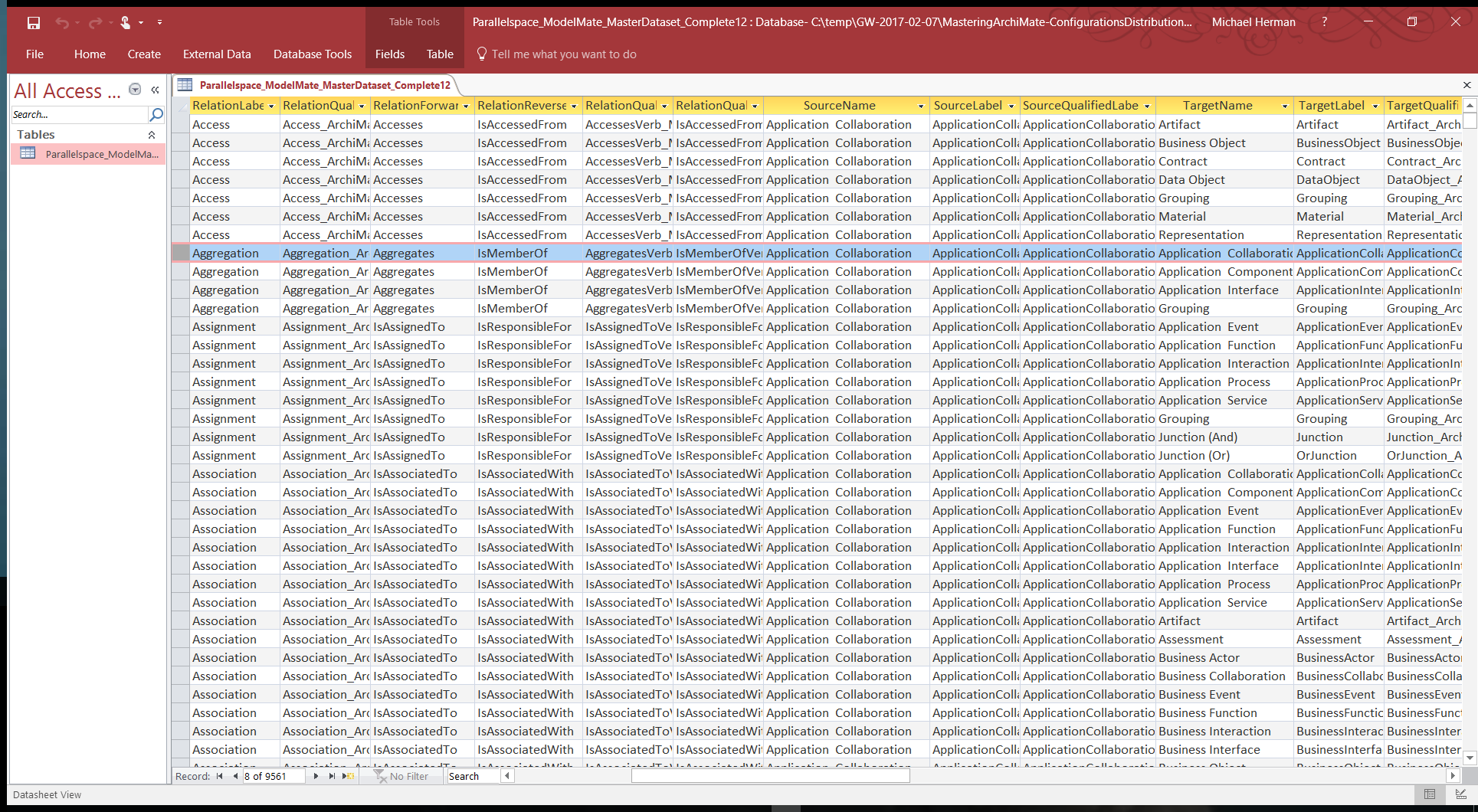
Figure 4. ModelMate Master Datasets: MS Access Database file format
To create a queryable graph database version of the ArchiMate 3.0 relationship tables (in effect, the entire ArchiMate 3.0 metamodel), the Cypher Query Language (CQL) file depicted in Figure 5. was created.
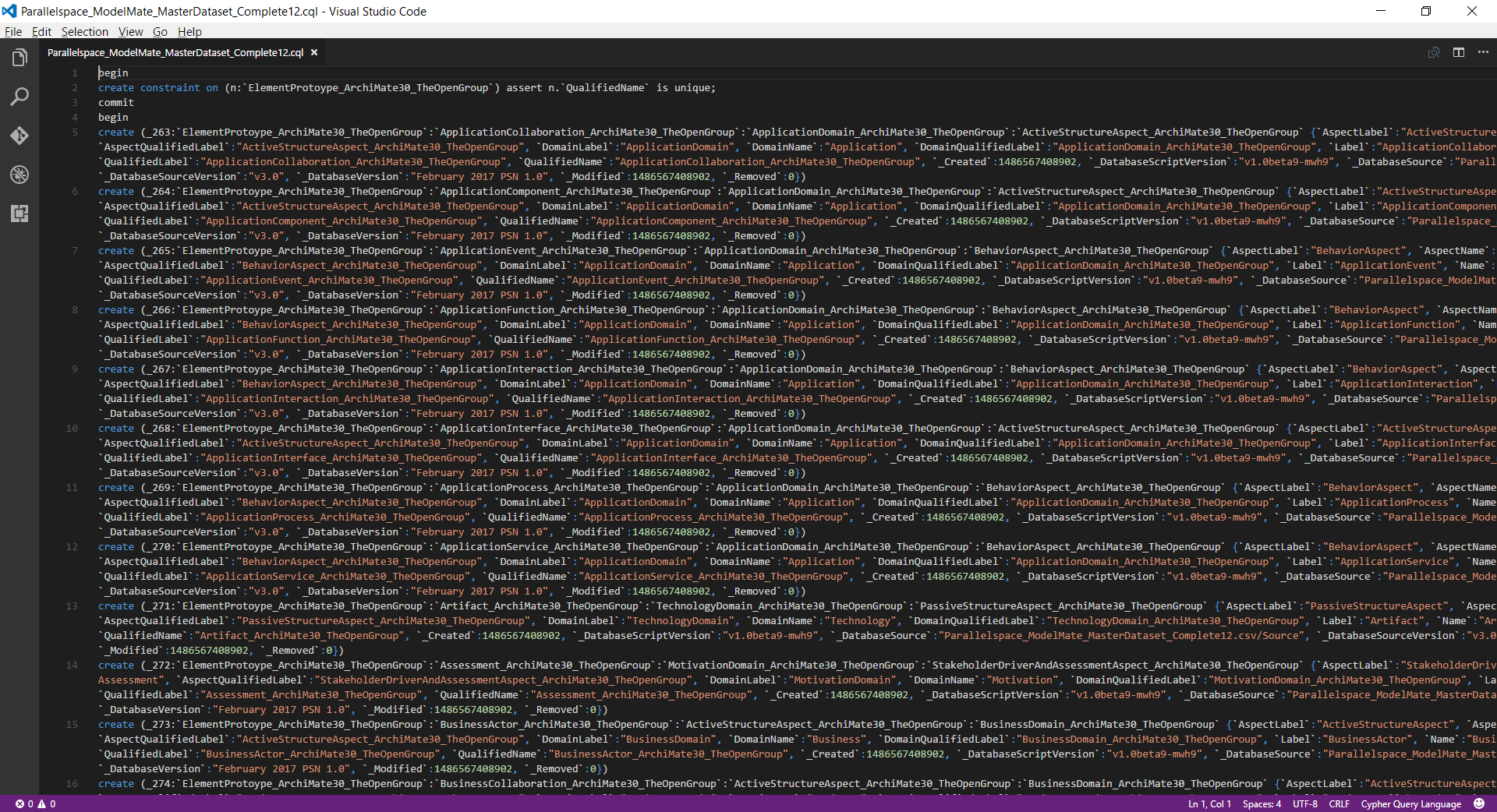
Figure 5. ModelMate Master Datasets: Neo4j CQL File
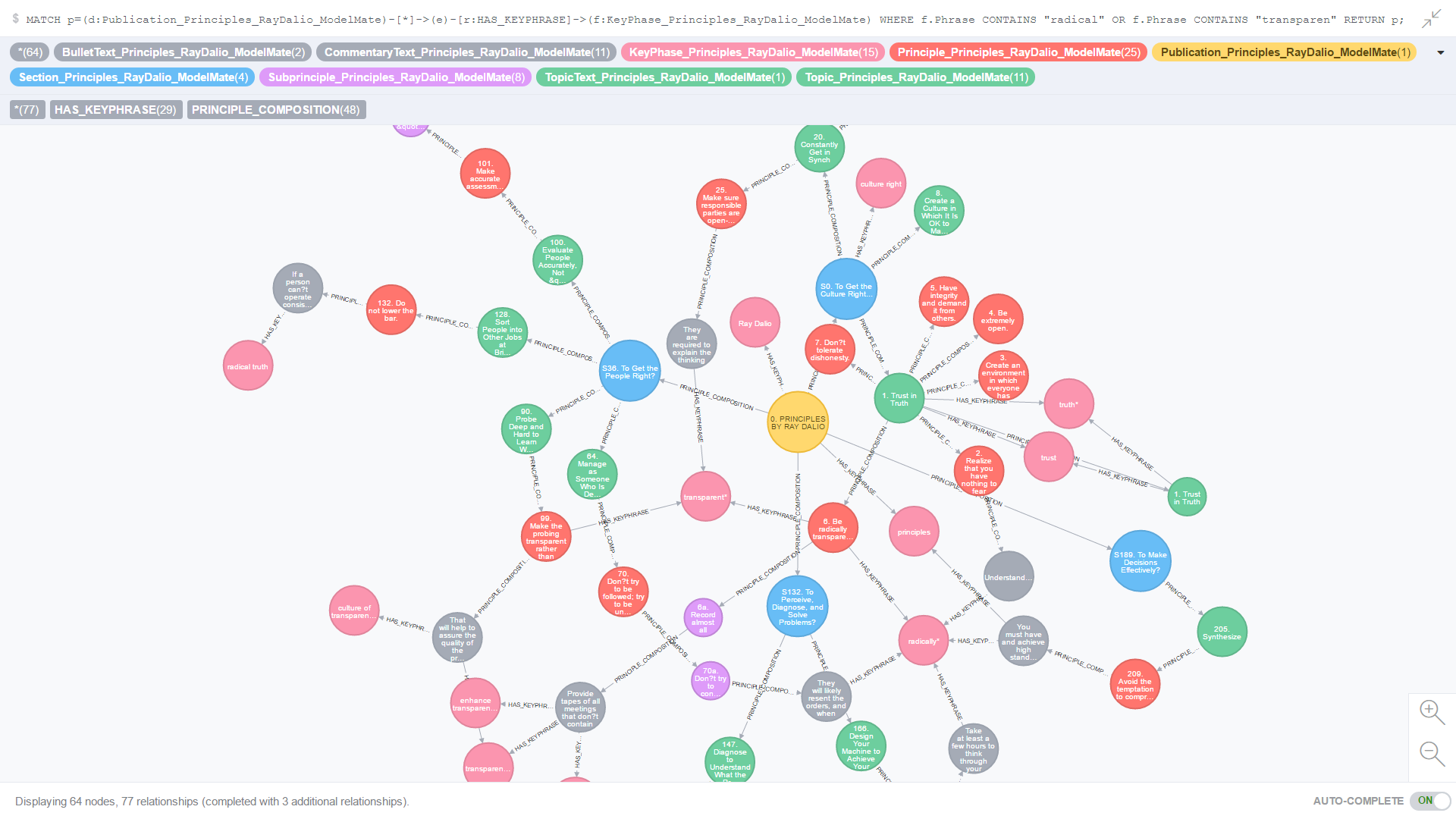
Figure 6 is an example of the output from a single line CQL query run against the ArchiMate 3.0 graph database (implemented using Neo4j). If you look closely at the CQL statement at the top of this screen shot (click Figure 6. to enlarge it), you’ll see that it is selecting all of the relationships across all of the element prototypes in the Technology/Infrastructure domain of the ArchiMate 3.0 metamodel that connect to the Node element prototype.
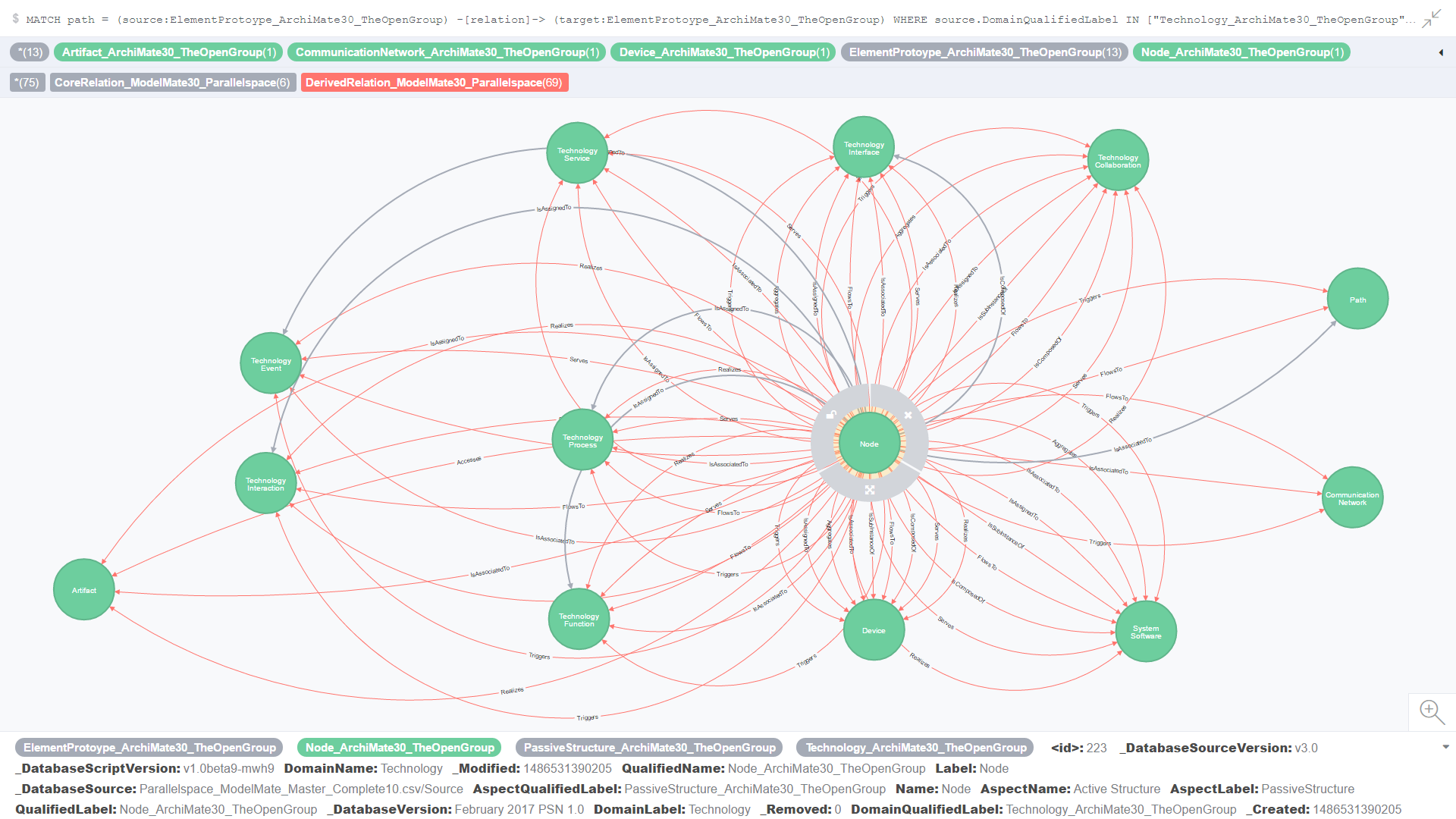
Figure 6. ModelMate Master Datasets: Graph Mining Analysis Sample
File Downloads
You can download the files referred to in this article from the GitHub repository. Click here to download the ModelMate Master Datasets files.
In addition, there is a Neo4j Cypher Query Language (CQL) file available for download that will ingest all of the element prototypes and relations into a graph database using a single Neo4j shell invocation. From the Windows Powershell or Windows Command Prompt, use:
“C:\Program Files\Java\jre1.8.0_91\bin\java.exe” -classpath “C:\Program Files\Neo4j CE 3.0.6\bin\neo4j-desktop-3.0.6.jar” org.neo4j.shell.StartClient -c dump > MasterDataSet.cql
Lastly, there is Microsoft Access 2016 database version of the CSV file that is available for download if you prefer using Microsoft Access SQL queries or graphical SQL queries.
Solution Details
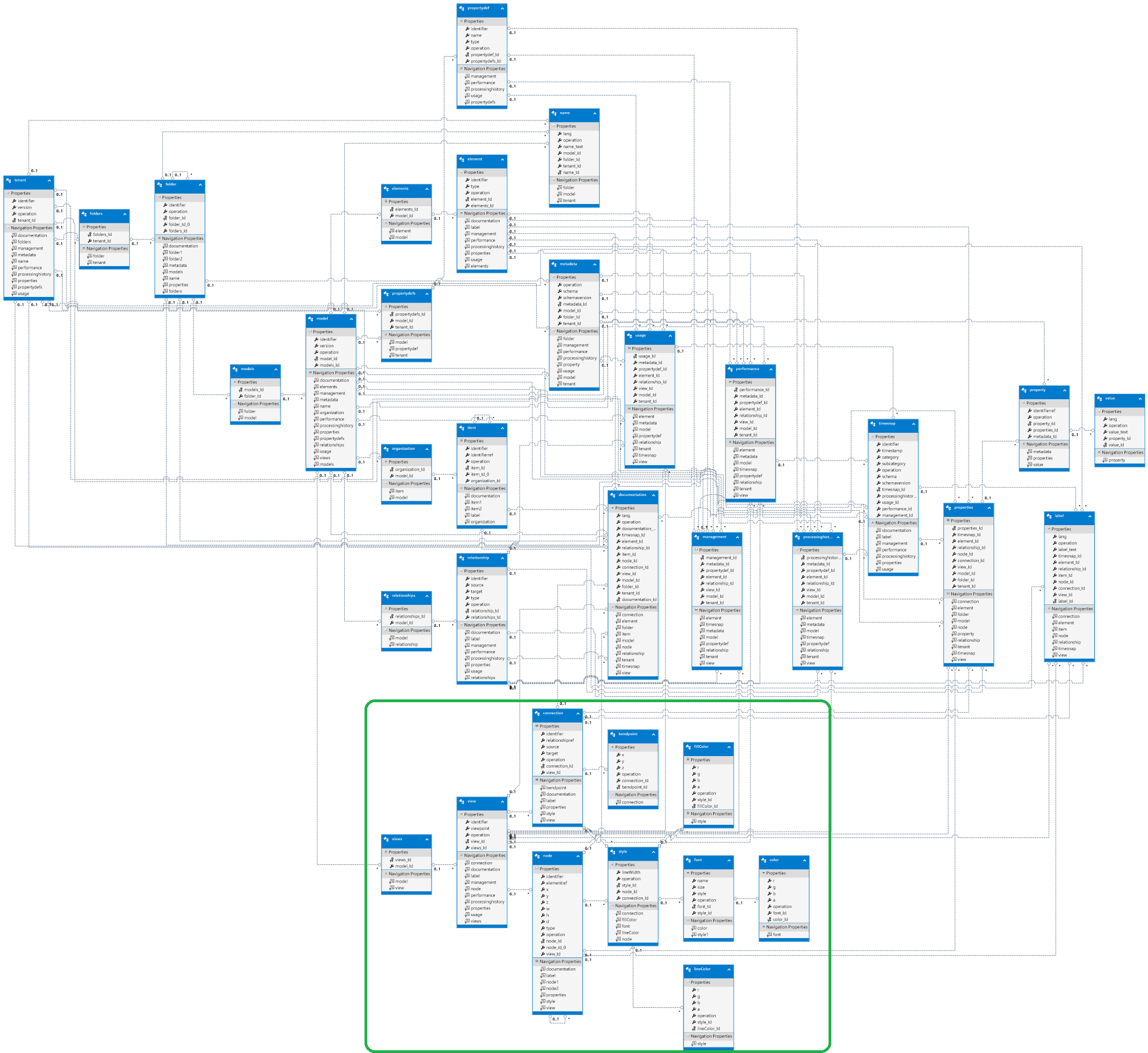
Below is a copy of the workflow and dataflow used to create the Parallelspace ModelMate Master Datasets. It’s not as messy as it looks – it’s true mashup and a valuable one at that. It’s primarily the result of the truly ad-hoc collaboration between 3 enterprise architecture professionals with an interesting mix of diverse goals (Gerben Wierda, Ed Roberts and myself); each of us with our own set of preferred development technologies and goals (with Excel being the greatest common denominator (GCD)).

Figure 7. ArchiMate 3.0 Relationship Matrix Resolution Process
The numbered steps in Figure 7. are explained below:
 Data Sources. There are many sources of information about the ArchiMate relationship matrix in addition to the Appendix B tables in the ArchiMate 3.0 Specification. The list in Figure 7. is a fairly complete. Key data sources include the GitHub Archi repository for the most widely used ArchiMate modeling tool for enterprise architecture and Gerben Wierda’s multiple ArchiMate resources publishing under the Mastering ArchiMate brand.
Data Sources. There are many sources of information about the ArchiMate relationship matrix in addition to the Appendix B tables in the ArchiMate 3.0 Specification. The list in Figure 7. is a fairly complete. Key data sources include the GitHub Archi repository for the most widely used ArchiMate modeling tool for enterprise architecture and Gerben Wierda’s multiple ArchiMate resources publishing under the Mastering ArchiMate brand.
 “MA Core Set” Spreadsheet. Wierda worked to consolidate various data sources from Step 1 above to create the “MA Core Set” Mastering ArchiMate relationship matrix (plus a number of other relationship matrices that Wierda used for comparative analysis and troubleshooting purposes). The “MA Core Set” represents the “seed” or Core Set of (non-derived) ArchiMate relations. Wierda created this Core Set over several iterations reviewing the word-for-word text of the Specification, the inheritance diagrams, as well as incorporating his extensive practical knowledge and experience documenting ArchiMate in the book entitled Mastering ArchiMate – Edition II.
“MA Core Set” Spreadsheet. Wierda worked to consolidate various data sources from Step 1 above to create the “MA Core Set” Mastering ArchiMate relationship matrix (plus a number of other relationship matrices that Wierda used for comparative analysis and troubleshooting purposes). The “MA Core Set” represents the “seed” or Core Set of (non-derived) ArchiMate relations. Wierda created this Core Set over several iterations reviewing the word-for-word text of the Specification, the inheritance diagrams, as well as incorporating his extensive practical knowledge and experience documenting ArchiMate in the book entitled Mastering ArchiMate – Edition II.
The “MA Core Set” tab in the AllowedRelationsArchiMate30VBA-public.xlsm Excel spreadsheet also includes additional columns that are reserved for calculating and storing an intermediate 3-column, reverse-transposed version of the relationship matrix (Step 3 below).
 CreatePrologList() Visual Basic for Applications (VBA) Macro: This macro is used to perform the actual reverse-transposition of the “MA Core Set” relationship matrix into the 3-column format which including a column for storing the relation(source,target) 3-tuple formatted data (in Prolog format). The 2-D relationship matrix is the input to the macro (along with some additional master data tables that are part of the VBA code). The 3-tuples are the essential output of the VBA macro (stored “in-place” in the first 3 columns of the spreadsheet).
CreatePrologList() Visual Basic for Applications (VBA) Macro: This macro is used to perform the actual reverse-transposition of the “MA Core Set” relationship matrix into the 3-column format which including a column for storing the relation(source,target) 3-tuple formatted data (in Prolog format). The 2-D relationship matrix is the input to the macro (along with some additional master data tables that are part of the VBA code). The 3-tuples are the essential output of the VBA macro (stored “in-place” in the first 3 columns of the spreadsheet).
 CoreSet.prolog File. To proceed through to the next step of the workflow, the Prolog format data is copied from the spreadsheet and pasted into a plain text file called CoreSet.prolog, for example (or any other filename you would like to use).
CoreSet.prolog File. To proceed through to the next step of the workflow, the Prolog format data is copied from the spreadsheet and pasted into a plain text file called CoreSet.prolog, for example (or any other filename you would like to use).
 Derivaton.py Python Script and outfile.csv. The Derivation.py script contains is the “magic sauce”. Written by Wierda, Derivation.py reads the CoreSet.prolog file and executes a complex and detailed algorithm to expand the Core Set of ArchiMate relations read from the CoreSet.prolog file into a number of alternative output formats, including CSV and Prolog formats.
Derivaton.py Python Script and outfile.csv. The Derivation.py script contains is the “magic sauce”. Written by Wierda, Derivation.py reads the CoreSet.prolog file and executes a complex and detailed algorithm to expand the Core Set of ArchiMate relations read from the CoreSet.prolog file into a number of alternative output formats, including CSV and Prolog formats.
To support the ModelMate project, a version of Derivation.py was modified to output a number of additional CSV columns (outfile.csv). Columns:
- SourceElement
- TargetElement
- Relation
- RelativeStrength
- IsInputRelation
- StandardVersion
- ScriptVersion
 Outfile.xml File. Steps 6 and 7 are part of a sequence of activities that were used to create a relationships.xml file that is compatible with the relationship configuration requirements of the Archi modeling tool. This process, originally implemented by Ed Roberts, owner of Dallas-based Elparazim, uses Excel to load the outfile.csv save it out as an outfile.xml file.
Outfile.xml File. Steps 6 and 7 are part of a sequence of activities that were used to create a relationships.xml file that is compatible with the relationship configuration requirements of the Archi modeling tool. This process, originally implemented by Ed Roberts, owner of Dallas-based Elparazim, uses Excel to load the outfile.csv save it out as an outfile.xml file.
 For Step 7, Ed Roberts wrote an XSL Transform script that when applied to the outfile.xml file creates the Archi-compatible relationship.xml that is used by the Archi model to automatically configure the element-element relations supported in a given version of Archi (e.g. Archi 4.0).
For Step 7, Ed Roberts wrote an XSL Transform script that when applied to the outfile.xml file creates the Archi-compatible relationship.xml that is used by the Archi model to automatically configure the element-element relations supported in a given version of Archi (e.g. Archi 4.0).
 Steps 8-10 mark an alternative data flow created to support the needs of the ModelMate Master Datasets project.
Steps 8-10 mark an alternative data flow created to support the needs of the ModelMate Master Datasets project.
In Step 8, the contents of the ModelMate-compatible modified CSV output from Step 5 (outfile.csv) is copy-and-pasted into the Parallelspace_ModelMate_MasterDatasets_CoreAndDerivedNN.xlsx Excel workbook (where NN is a version number).
A matrix of automated Excel functions in the Complete spreadsheet merge the elements and relations master data attributes from the Elements and Relations spreadsheet with the data from the Derived spreadsheet to compute the corresponding column values in the Complete spreadsheet. Think of the Complete spreadsheet as a super-unnormalized version of the relationship matrix. The InInputRelation column values indicate whether a specific relation (and it’s companion source and target elements) are Core relations or Derived relations.
The workbook contains 4 spreadsheets (Derived, Complete, Elements, and Relations):
- Derived spreadsheet – copy-and-pasted version of the outfile.csv from Step 4. The “input” spreadsheet.
Columns:- SourceElement
- TargetElement
- Relation
- RelativeStrength
- IsInputRelation
- StandardVersion
- ScriptVersion
- Complete spreadsheet – leverages the master data in the Elements and Relations tabs to expand the columns in the Derived spreadsheet to include additional metadata property columns for the source and target elements as well as the relations. The “output” spreadsheet that will be saved as a CSV file in Step. 9.
Columns:- SourceElement
- TargetElement
- Relation
- RelativeStrength
- IsInputRelation
- StandardVersion
- ScriptVersion
- RelationName
- RelationLabel
- RelationQualifiedLabel
- RelationForwardVerbLabel
- RelationReverseVerbLabel
- RelationQualifiedForwardVerbLabel
- RelationQualifiedReverseVerbLabel
- SourceName
- SourceLabel
- SourceQualifiedLabel
- TargetName
- TargetLabel
- TargetQualifiedLabel
- SourceDomainName
- SourceDomainLabel
- SourceDomainQualifiedLabel
- SourceAspectName
- SourceAspectLabel
- SourceAspectQualifiedLabel
- TargetDomainName
- TargetDomainLabel
- TargetDomainQualifiedLabel
- TargetAspectName
- TargetAspectLabel
- TargetAspectQualifiedLabel
- Elements spreadsheet – master data attributes and values for each element prototype.
Columns:- ElementCode
- ElementLabel
- ElementName
- ElementQualifiedLabel
- DomainName
- DomainLabel
- DomainQualifiedLabel
- AspectName
- AspectLabel AspectQualifiedLabel
- Relations spreadsheet – master data attributes and values for each relation prototype.
Columns:- RelationCode
- RelationName
- RelationQualifiedLabel
- RelationForwardVerb
- RelationQualifiedForwardVerb
- RelationReverseVerb
- RelationQualifiedReverseLabel
 In Step 9, columns 4-32 of the Complete spreadsheet are saved as a separate CSV format file (using the same versioned file name as the parent workbook but with a suffix of .csv).
In Step 9, columns 4-32 of the Complete spreadsheet are saved as a separate CSV format file (using the same versioned file name as the parent workbook but with a suffix of .csv).
Also considered part of Step 9, the CSV file is imported into an empty Microsoft Access database. The datatype of the InInputRelation is changed to be a Yes/No (boolean) field. The database file is given the same name as the CSV file but with a suffix of .accdb.
 Step 10 uses a series of Cypher Query Language (CQL) script files to create and populate a Neo4j graph database – to enable simple but powerful ad-hoc queries against the ArchiMate 3.0 relationship tables/metamodel.
Step 10 uses a series of Cypher Query Language (CQL) script files to create and populate a Neo4j graph database – to enable simple but powerful ad-hoc queries against the ArchiMate 3.0 relationship tables/metamodel.
Step 10.1. Merge all of Source and Target Element Prototypes

Script 1. Merge Source and Target Element Prototypes
Step 10.2. Label Elements with Element, Domain and Aspect Names

Script 2. Label Elements with Element, Domain and Aspect Names
Step 10.3 Create the Metamodel Relationships
TODO
Results
Use Cases
This section documents the results of the following use cases (queries against the Neo4j graph model):
- All Business domain source and target element prototypes and all related Core and Derived relationships
- All Core relationships where the source element prototype is from the Business domain
- All Core relationships where the source and target element prototypes are from the Business domain
- All Application domain source and target element prototypes and all related Core and Derived relationships
- All Core relationships where the source and target element prototypes are from the Application domain
- All Core and Derived relationships where the source and target element prototypes are from the Technology/Infrastructure domain
- All Core relationships where the source and target element prototypes are from the Technology domain
- All Core relationships where the source and target element prototypes are from the Technology domain and are identical to each other
- All Core relationships where the source and target element prototypes are from the Technology domain and are different from each other (non-self referencing)
- All Core and Derived relationships where the source and target element prototypes are from the Technology domain and are different from each other (non-self referencing)
- All Core and Derived relationships where the source and target element prototypes are from the Technology domain and connected to the Node element prototype
- All Core relationships where the source and target element prototypes belong to the Passive Structure aspect
- All Core relationships where the source and target element prototypes belong to the Active Structure aspect
- All Core relationships where the source and target element prototypes belong to the Behavior aspect
Use Case Results
Click on any of the figures to enlarge them in a separate browser tab.
Business Domain Use Case Results
Use Case 1: All Business domain source and target element prototypes and all related Core and Derived relationshipsUse Cases
Figure 8. is the result of an ad-hoc CQL query against all element prototypes in the Business domain; more specifically, where both the source and target element prototypes are in the Business domain.
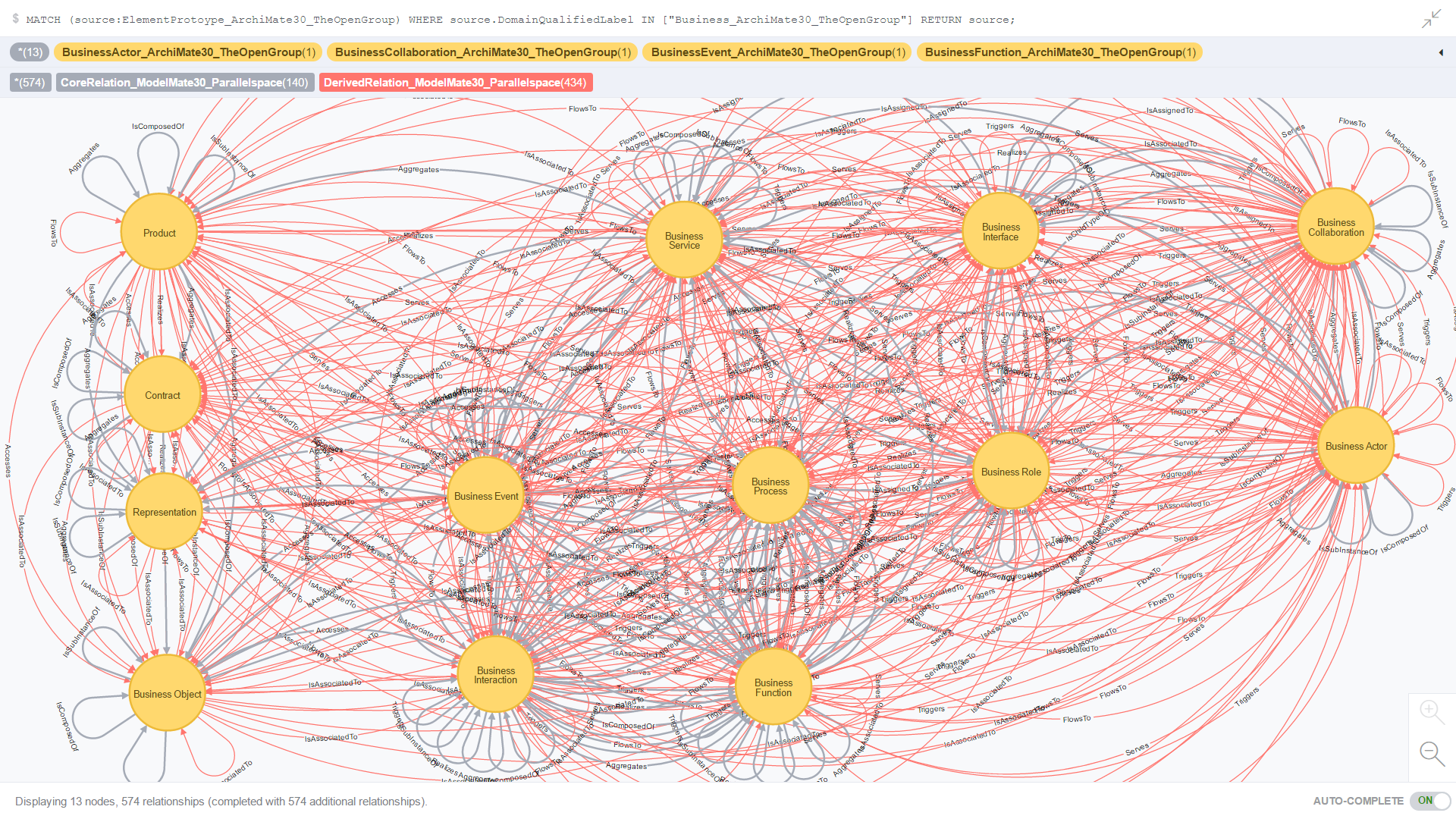
Figure 8. All Business domain source and target element prototypes and all related Core and Derived relationships
Use Case 2: All Core relationships where the source element prototype is from the Business domain
Figure 9. is the result of an ad-hoc CQL query against all Core relationships where the source element prototype is from the Business domain.
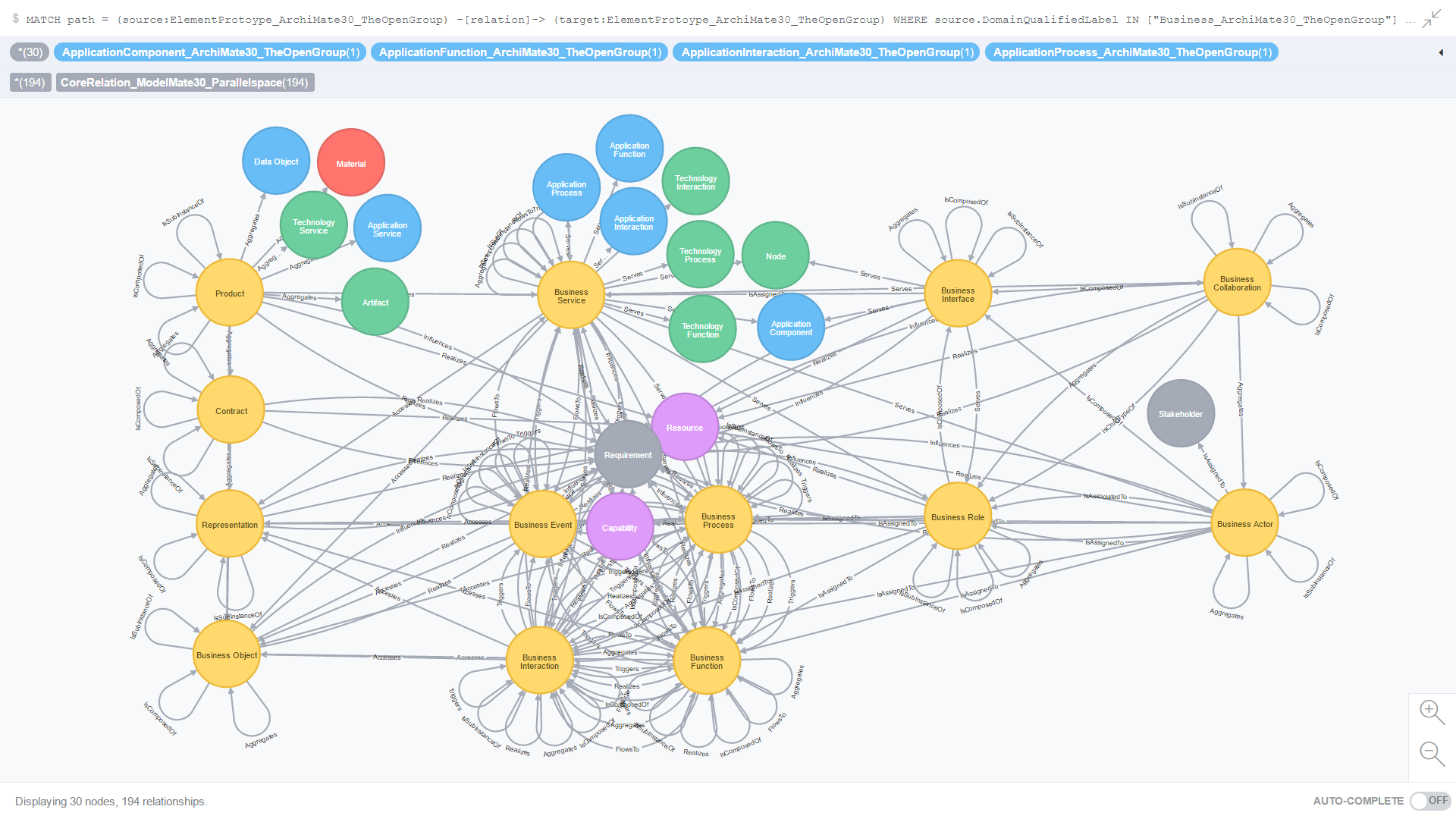
Figure 9. All Core relationships where the source element prototype is from the Business domain
Use Case 3: All Core relationships where the source and target element prototypes are from the Business domain
Figure 10. is the result of an ad-hoc CQL query against all Core relationships where both the source and target element prototypes are from the Business domain.
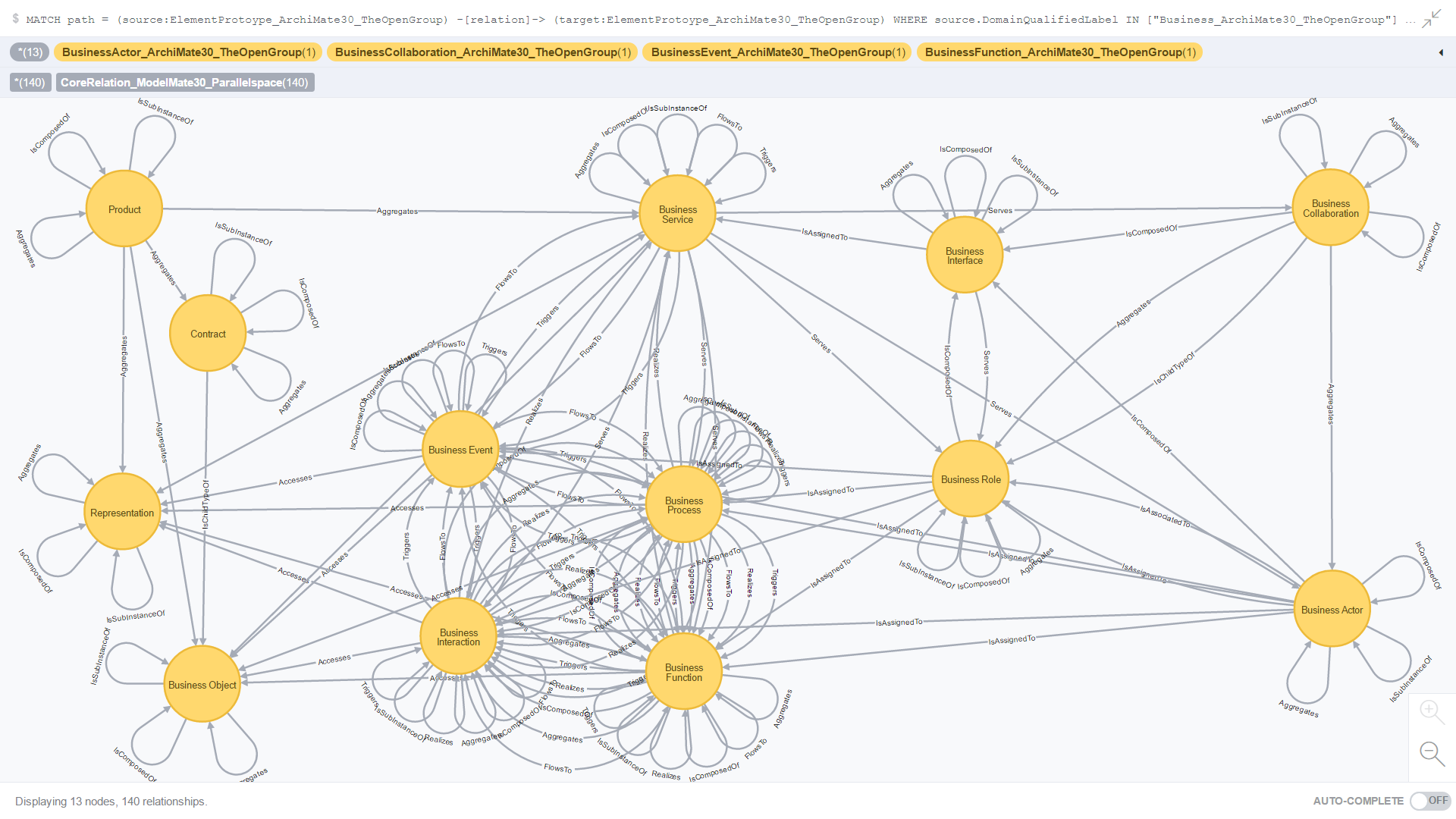
Figure 10. All Core relationships where the source element prototype is from the Business domain
Application Domain Use Case Results
Use Case 4: All Application domain source and target element prototypes and all related Core and Derived relationships
Figure 11. is the result of an ad-hoc CQL query against all element prototypes in the Application domain; more specifically, where both the source and target element prototypes are in the Application domain.
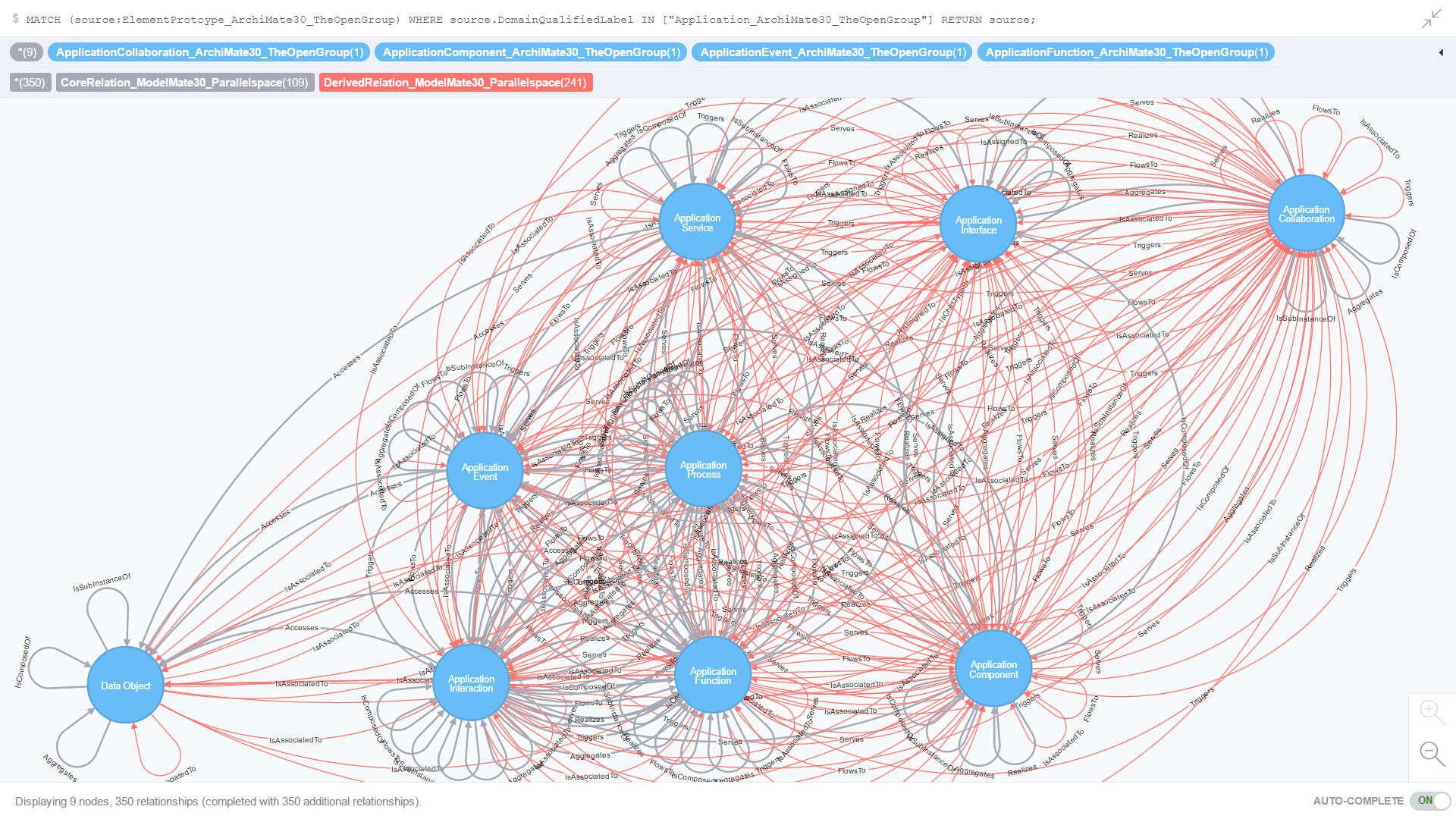
Figure 11. All Application domain source and target element prototypes and all related Core and Derived relationships
Use Case 5: All Core relationships where the source and target element prototypes are from the Application domain
Figure 12. is the result of an ad-hoc CQL query against all Core and Derived relationships where the source element prototype is from the Application domain.
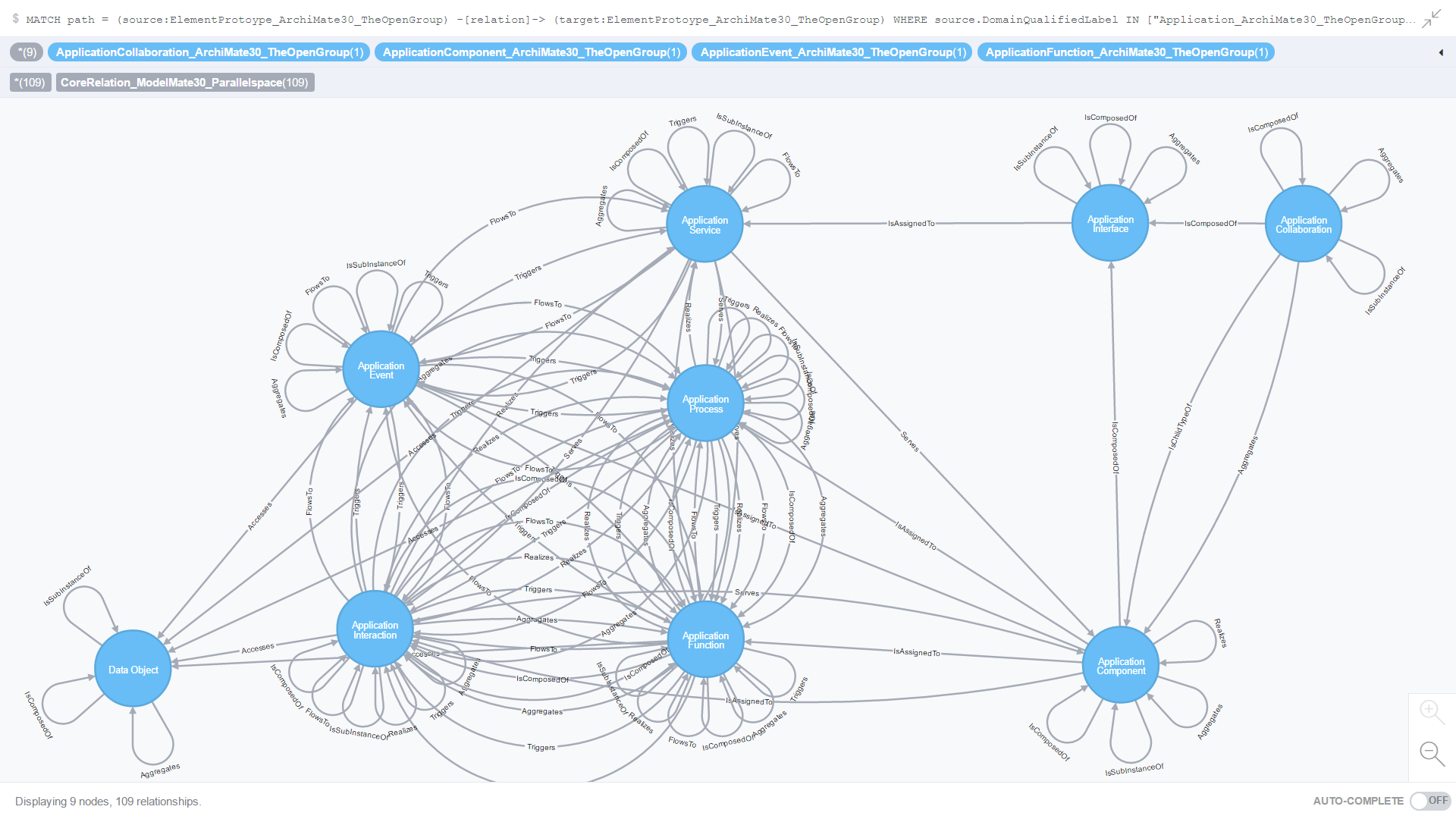
Figure 12. All Core relationships where the source and target element prototypes are from the Application domain
Technology Domain Use Case Results
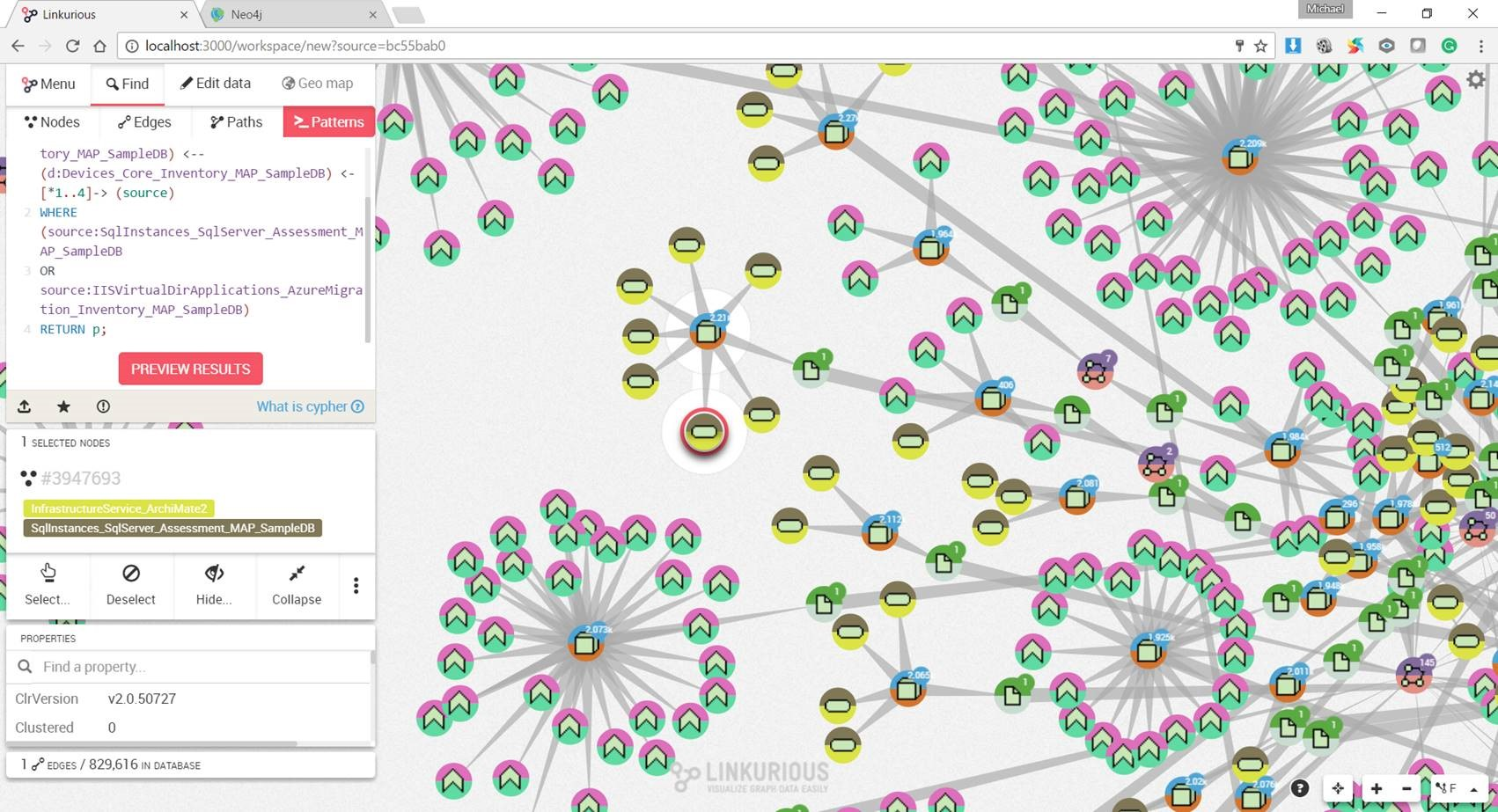
Use Case 6: All Core and Derived relationships where the source and target element prototypes are from the Technology/Infrastructure domain
Figure 13. is the result of an ad-hoc CQL query against all Core relationships where both the source and target element prototypes are from the Technology/Infrastructure domain.
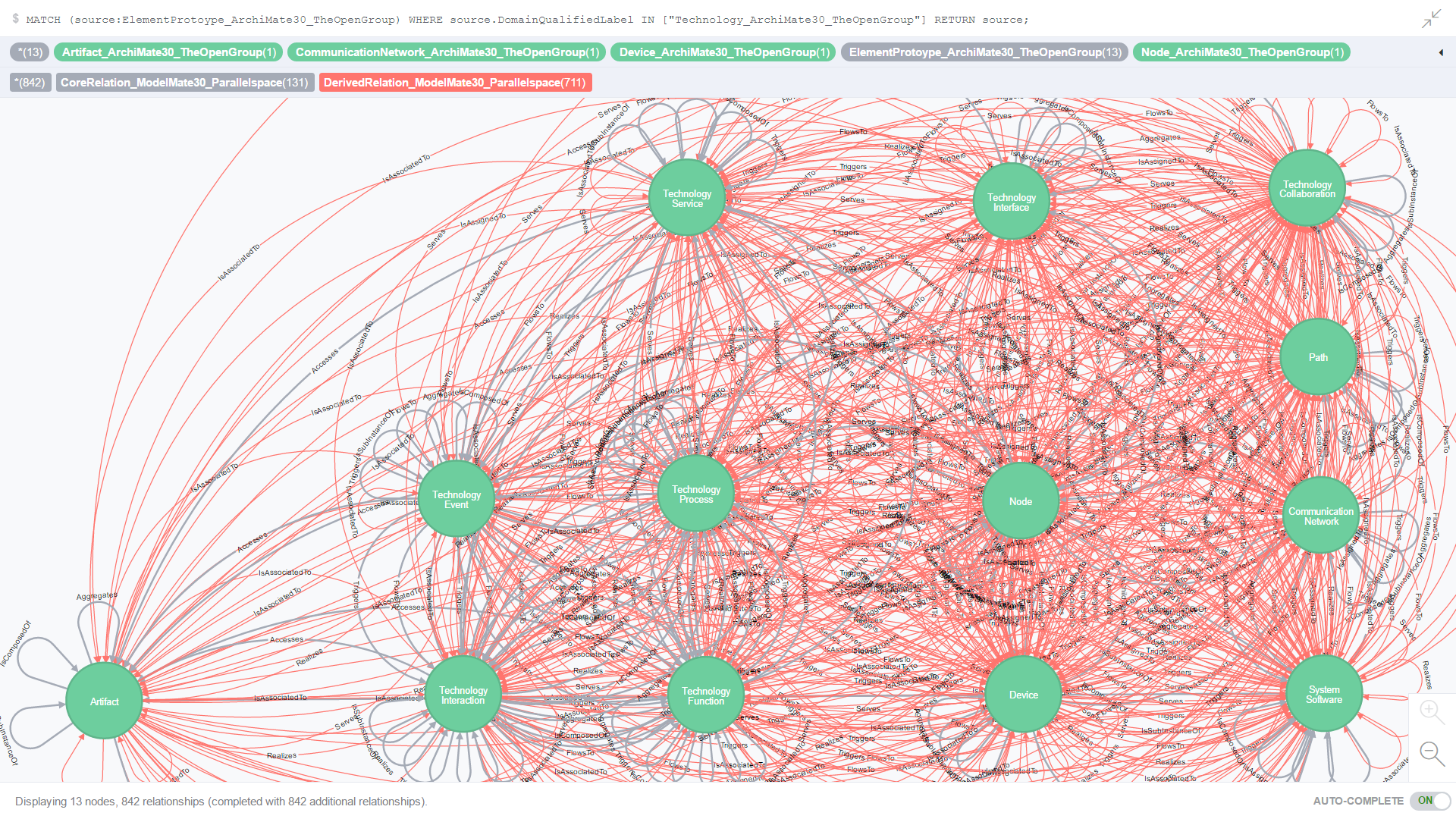
Figure 13. All Core and Derived relationships where the source and target element prototypes are from the Technology/Infrastructure domain
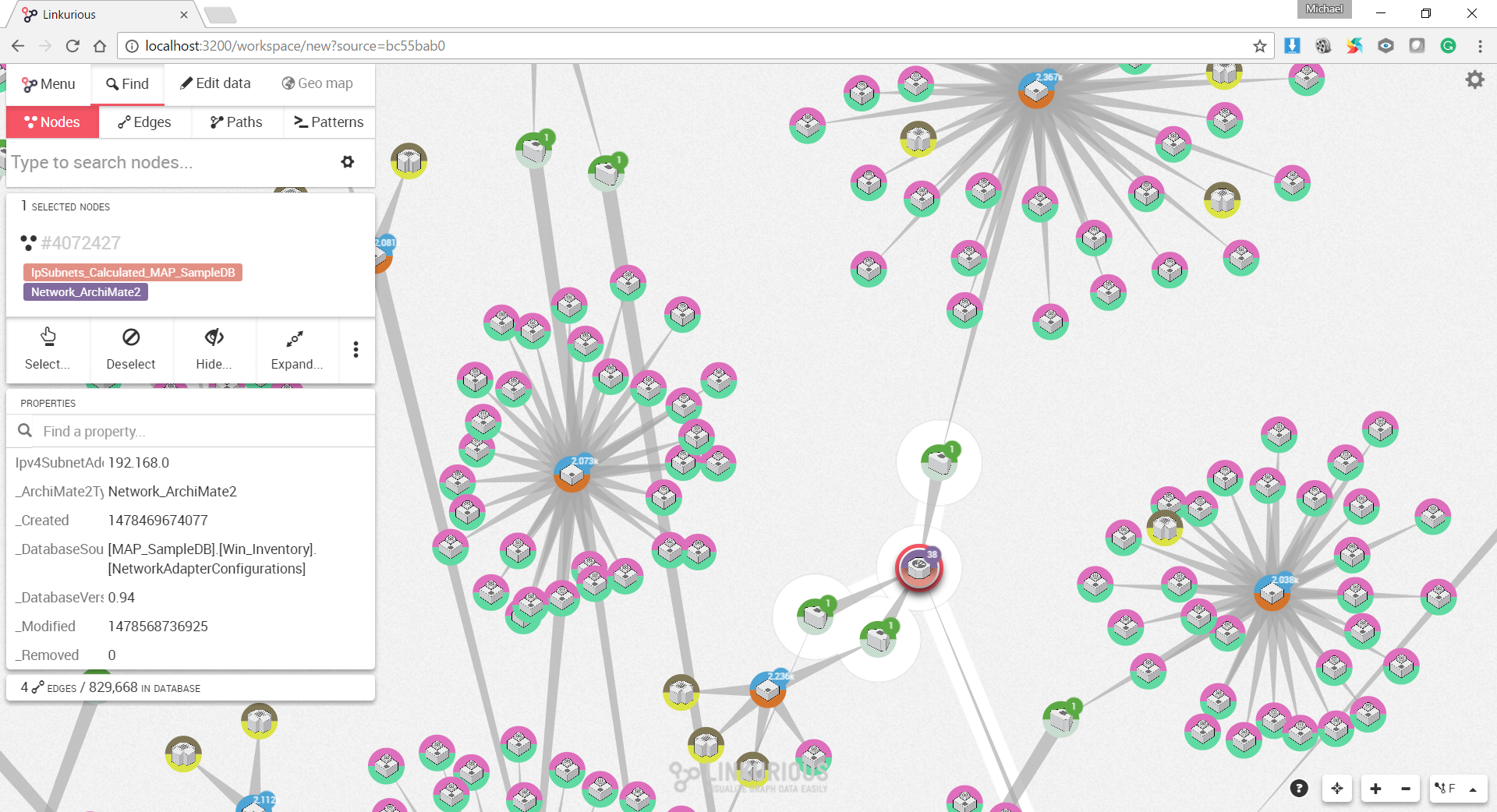
Use Case 7: All Core relationships where the source and target element prototypes are from the Technology domain
Figure 14. is the result of an ad-hoc CQL query against all Core relationships where both the source and target element prototypes are from the Technology domain.
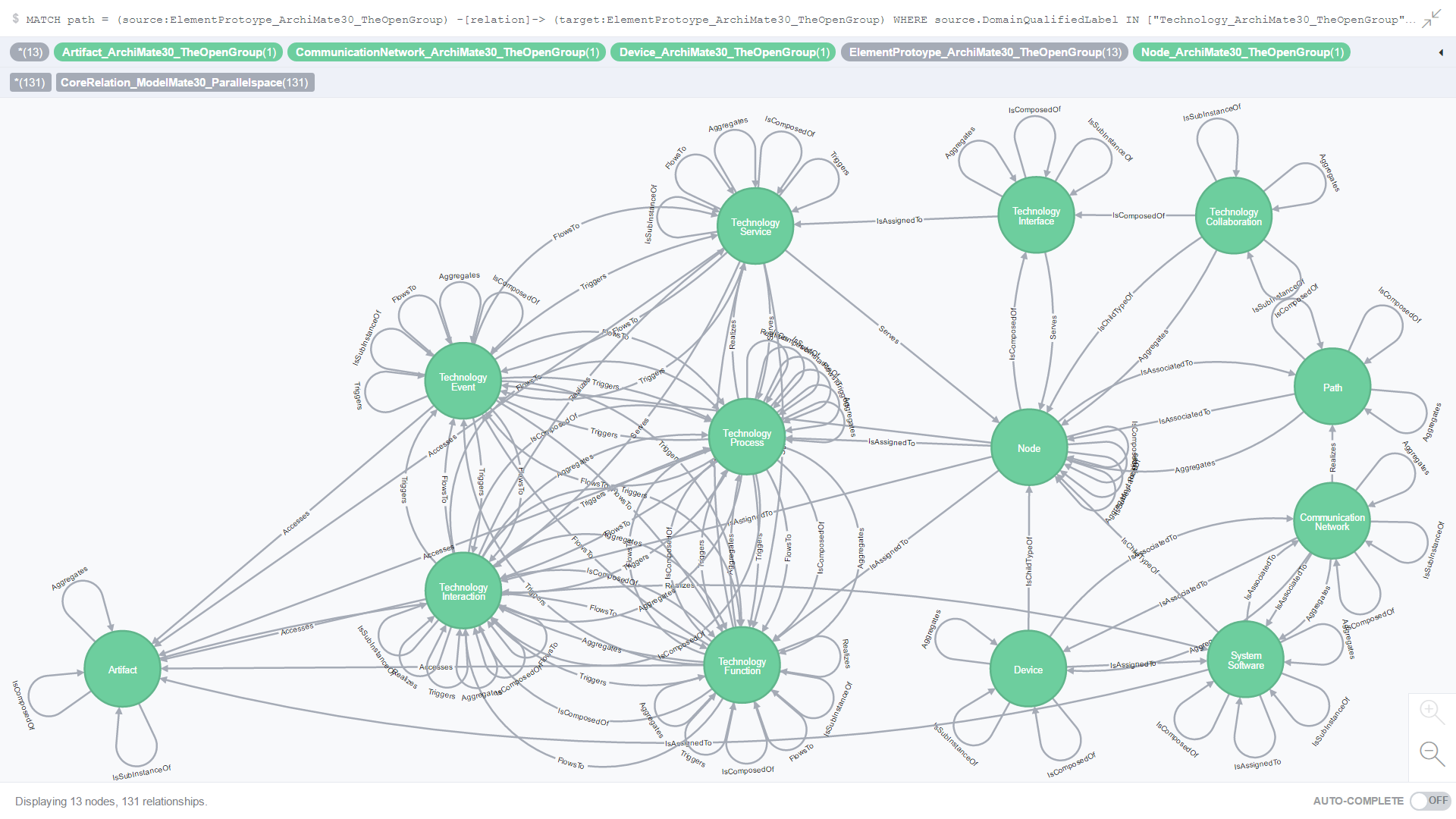
Figure 14. All Core relationships where the source and target element prototypes are from the Technology domain
Use Case 8: All Core relationships where the source and target element prototypes are from the Technology domain and are identical to each other
Figure 15. is the result of an ad-hoc CQL query against all Core relationships where both the source and target element prototypes are from the Technology domain and are identical to each other.
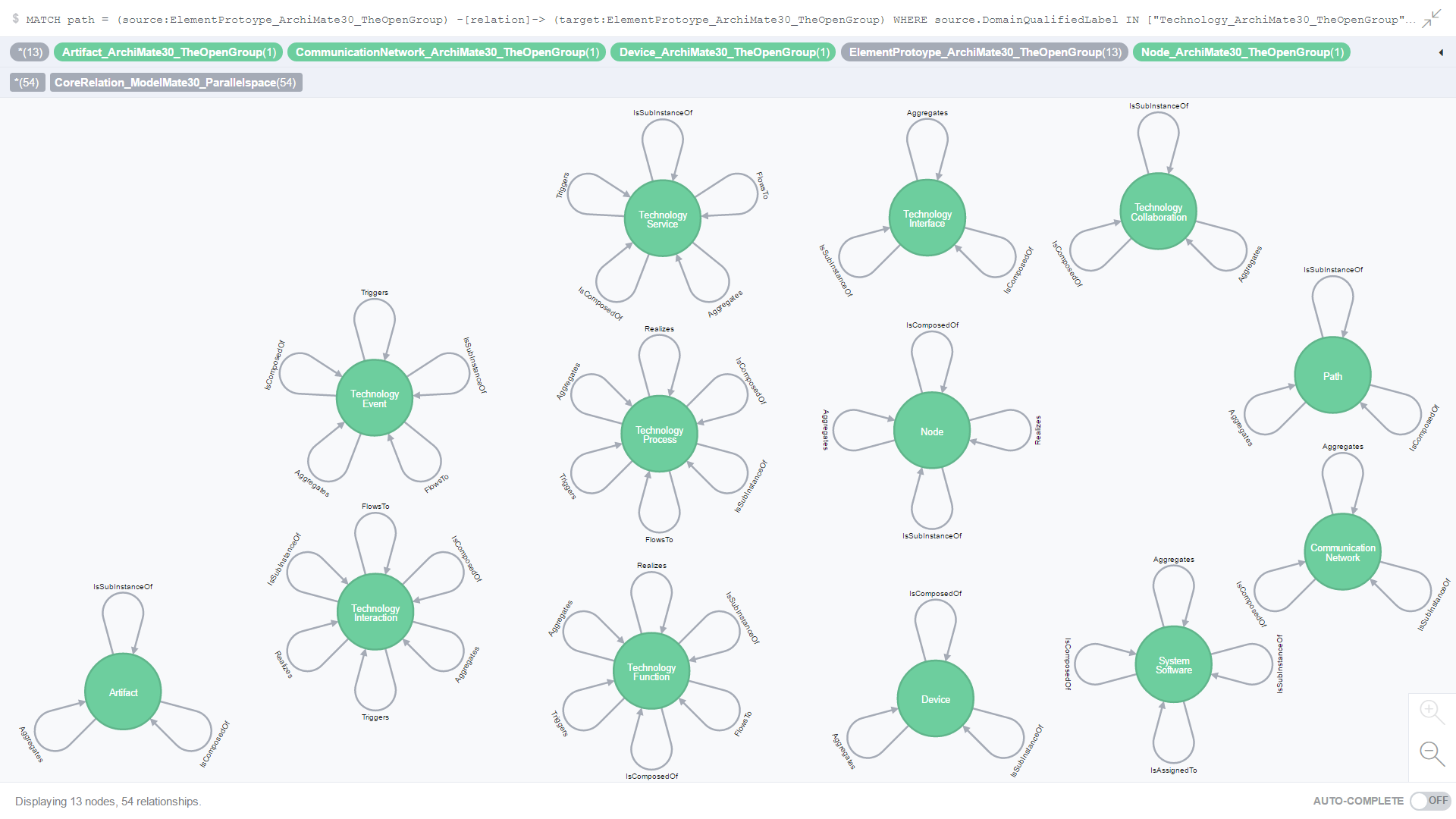
Figure 15. All Core relationships where the source and target element prototypes are from the Technology domain and identical to each other
Use Case 9: All Core relationships where the source and target element prototypes are from the Technology domain and are different from each other (non-self referencing)
Figure 16. is the result of an ad-hoc CQL query against all Core relationships where both the source and target element prototypes are from the Technology domain and are different from each other (non-self referencing).
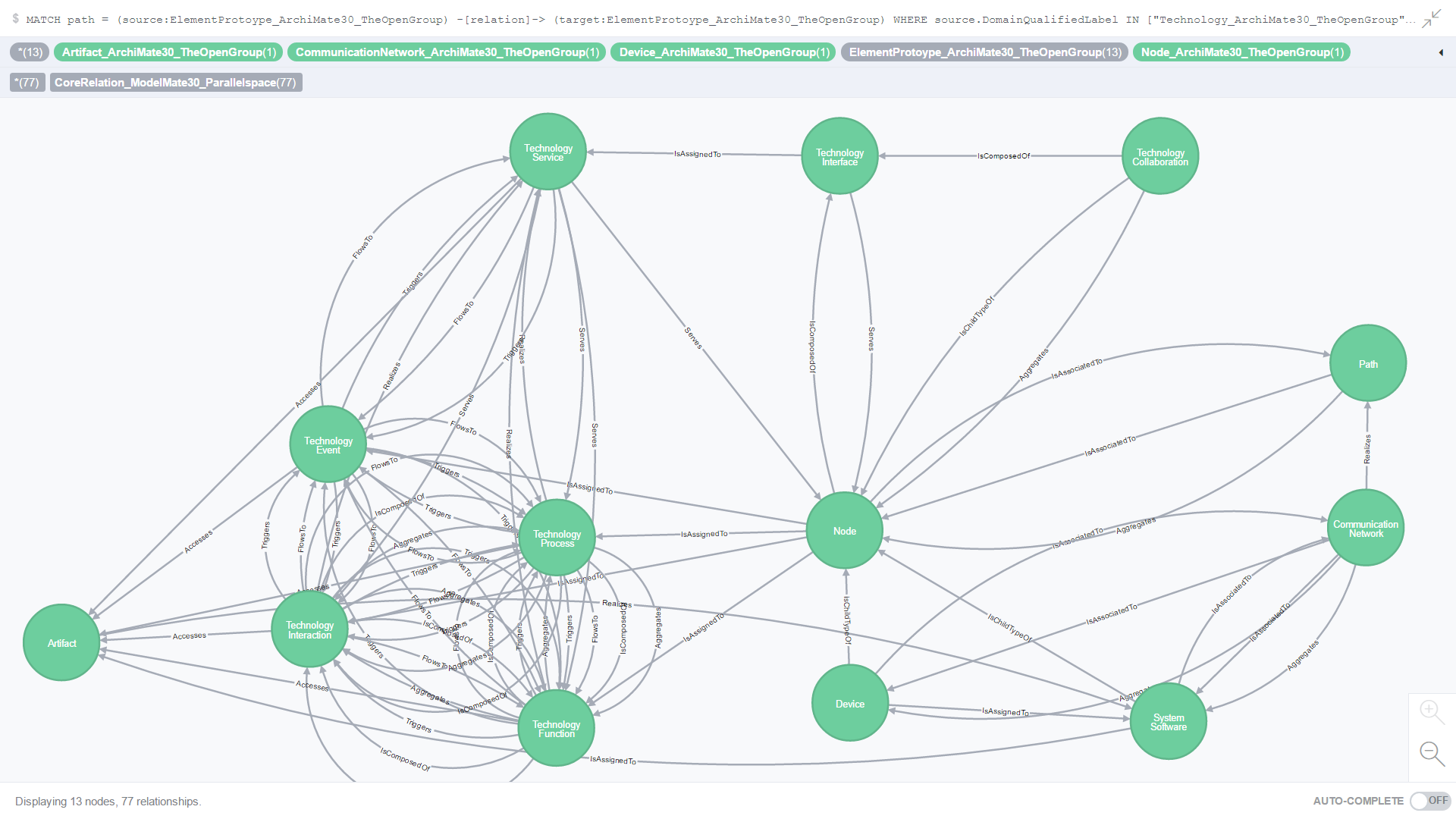
Figure 16. All Core relationships where the source and target element prototypes are from the Technology domain and different from each other (non-self referencing)
Use Case 10: All Core and Derived relationships where the source and target element prototypes are from the Technology domain and are different from each other (non-self referencing)
Figure 17. is the result of an ad-hoc CQL query against all Core and Derived relationships where both the source and target element prototypes are from the Technology domain and are different from each other (non-self referencing).
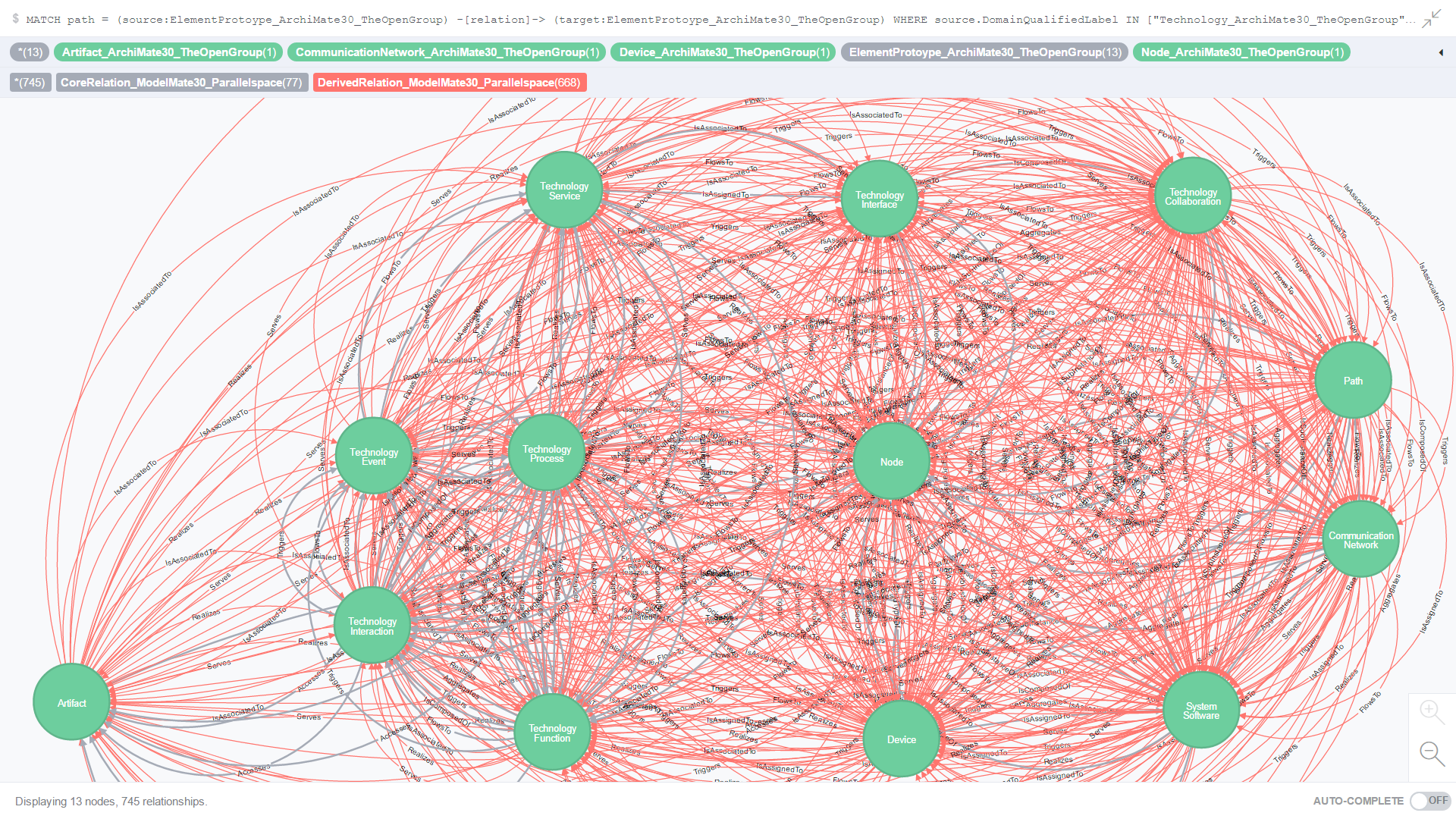
Figure 17. All Core and Derived relationships where the source and target element prototypes are from the Technology domain and are different from each other (non-self referencing)
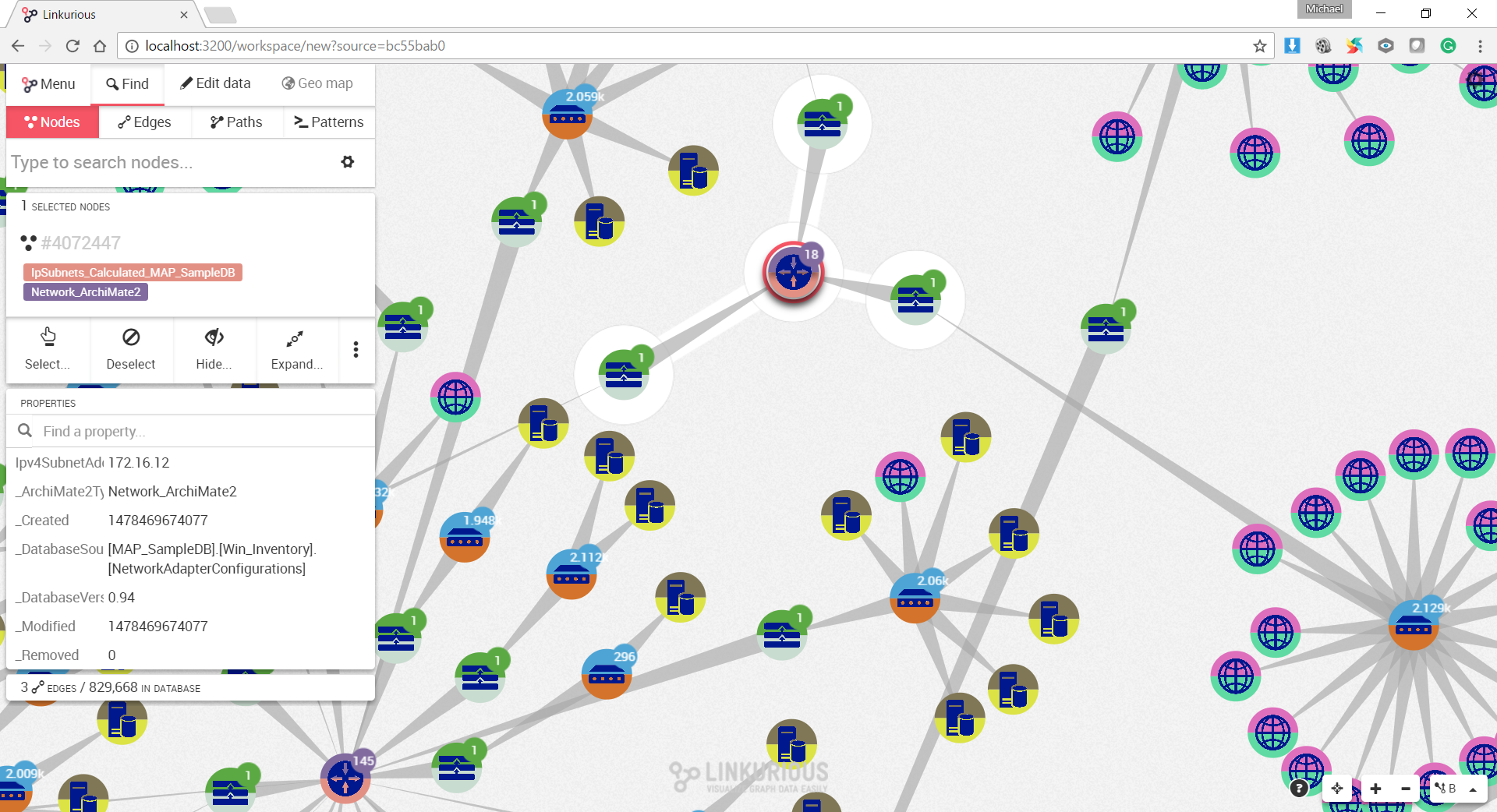
Use Case 11: All Core and Derived relationships where the source and target element prototypes are from the Technology domain and connected to the Node element prototype
Figure 18. is the result of an ad-hoc CQL query against all Core and Derived relationships where both the source and target element prototypes are from the Technology domain and are connected to the Node element prototype.
Figure 18. All Core and Derived relationships where the source and target element prototypes are from the Technology domain and connected to the Node element prototype
Aspects Use Case Results: Passive Structure, Active Structure, Behavior
Use Case 12: All Core relationships where the source and target element prototypes belong to the Passive Structure aspect
Figure 19. is the result of an ad-hoc CQL query against all Core relationships where the source and target element prototypes belong to the Passive Structure aspect.
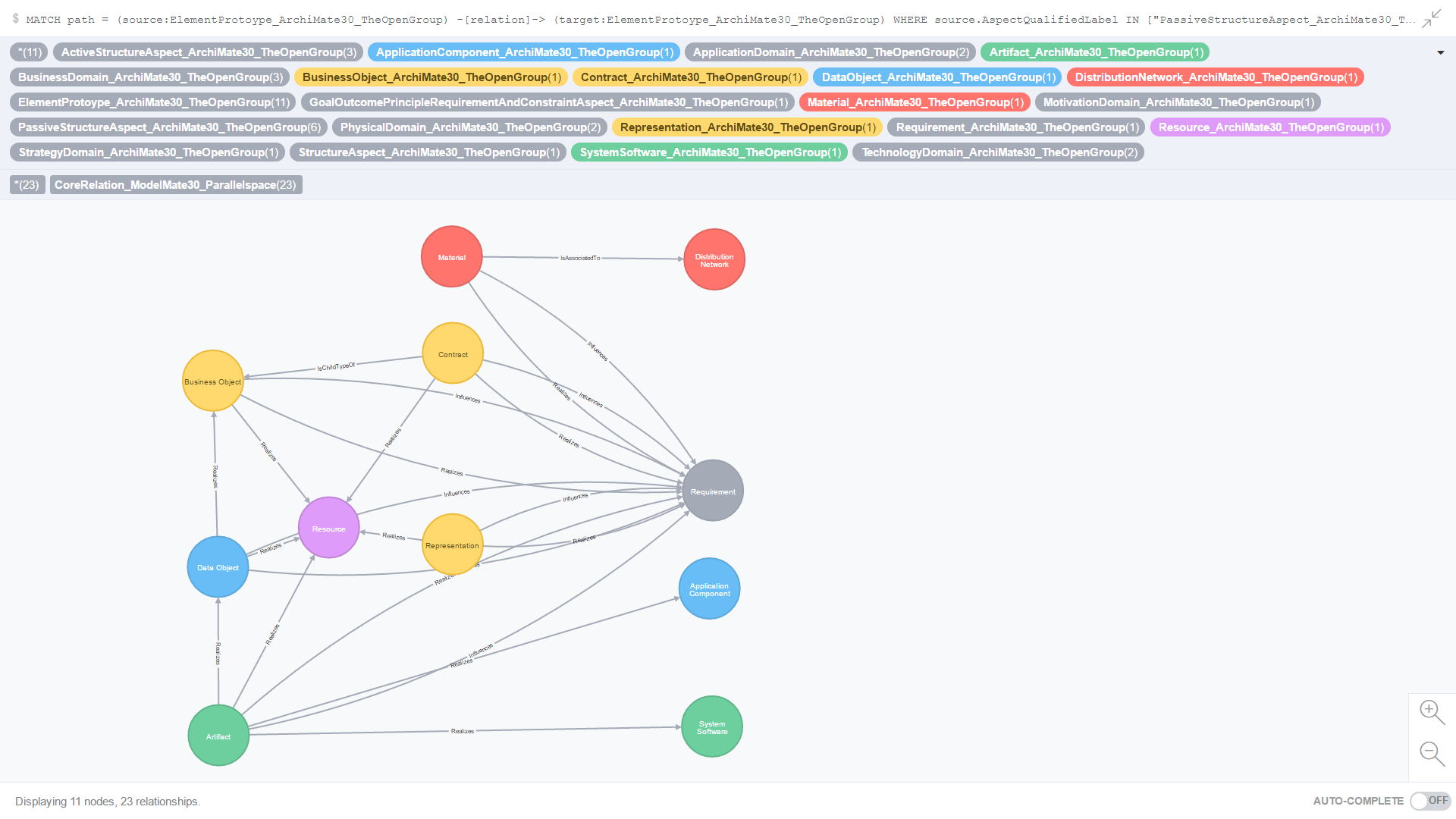
Figure 19. All Core relationships where the source and target element prototypes belong to the Passive Structure aspect
Use Case 13: All Core relationships where the source and target element prototypes belong to the Active Structure aspect
Figure 20. is the result of an ad-hoc CQL query against all Core relationships where the source and target element prototypes belong to the Active Structure aspect.
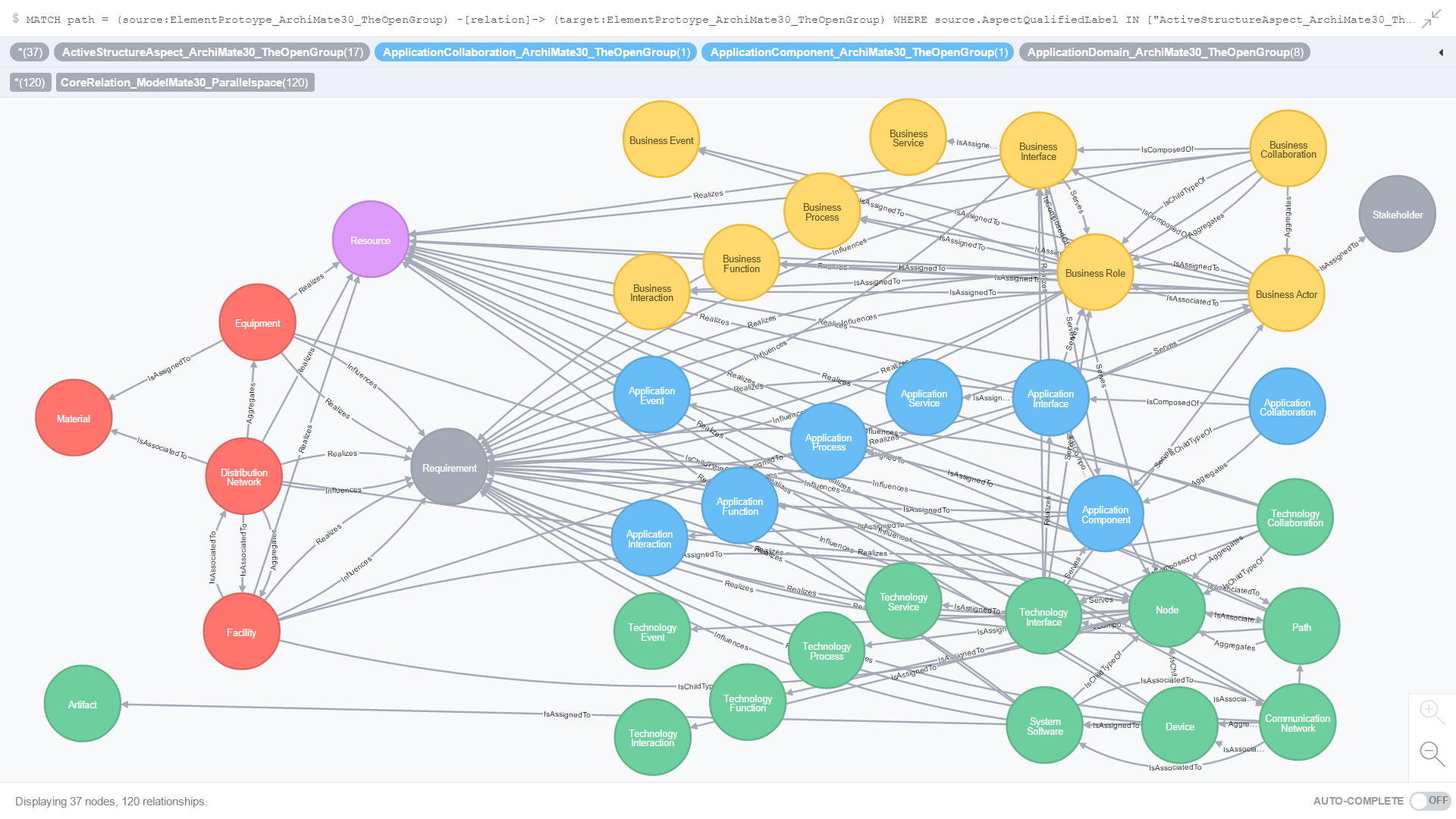
Figure 20. All Core relationships where the source and target element prototypes belong to the Active Structure aspect
Use Case 14: All Core relationships where the source and target element prototypes belong to the Behavior aspect
Figure 21. is the result of an ad-hoc CQL query against all Core relationships where the source and target element prototypes belong to the Behavior aspect.
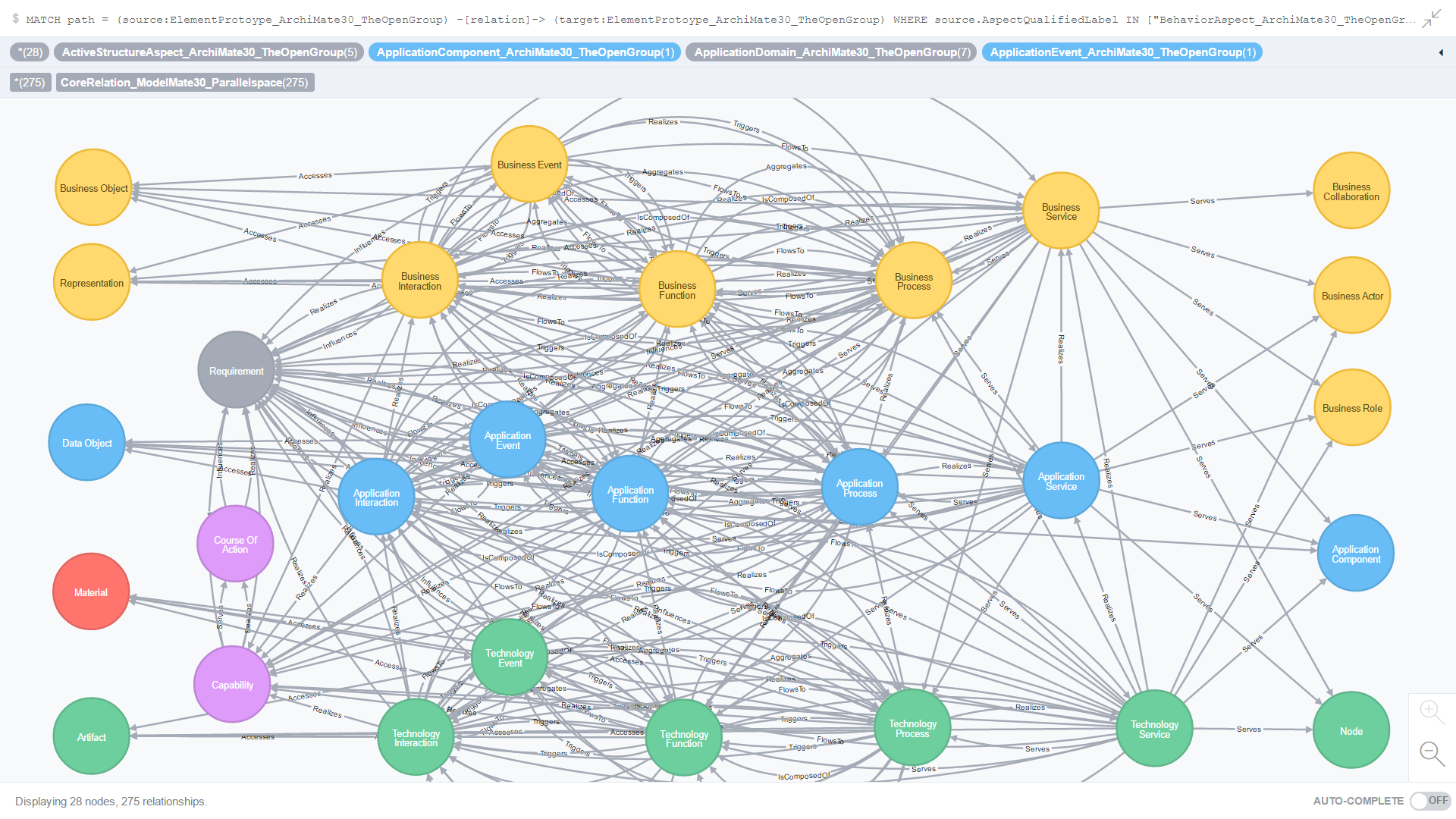
Figure 21. All Core relationships where the source and target element prototypes belong to the Behavior aspect
Feedback
Please add your comments and feedback to the end of this article.
Best regards,
Michael Herman (Toronto)
Parallelspace Corporation
mwherman@parallelspace.net
*ArchiMate is a registered trademark of The Open Group.




 Ray Dalio
Ray Dalio