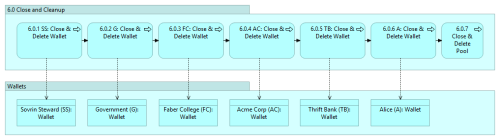
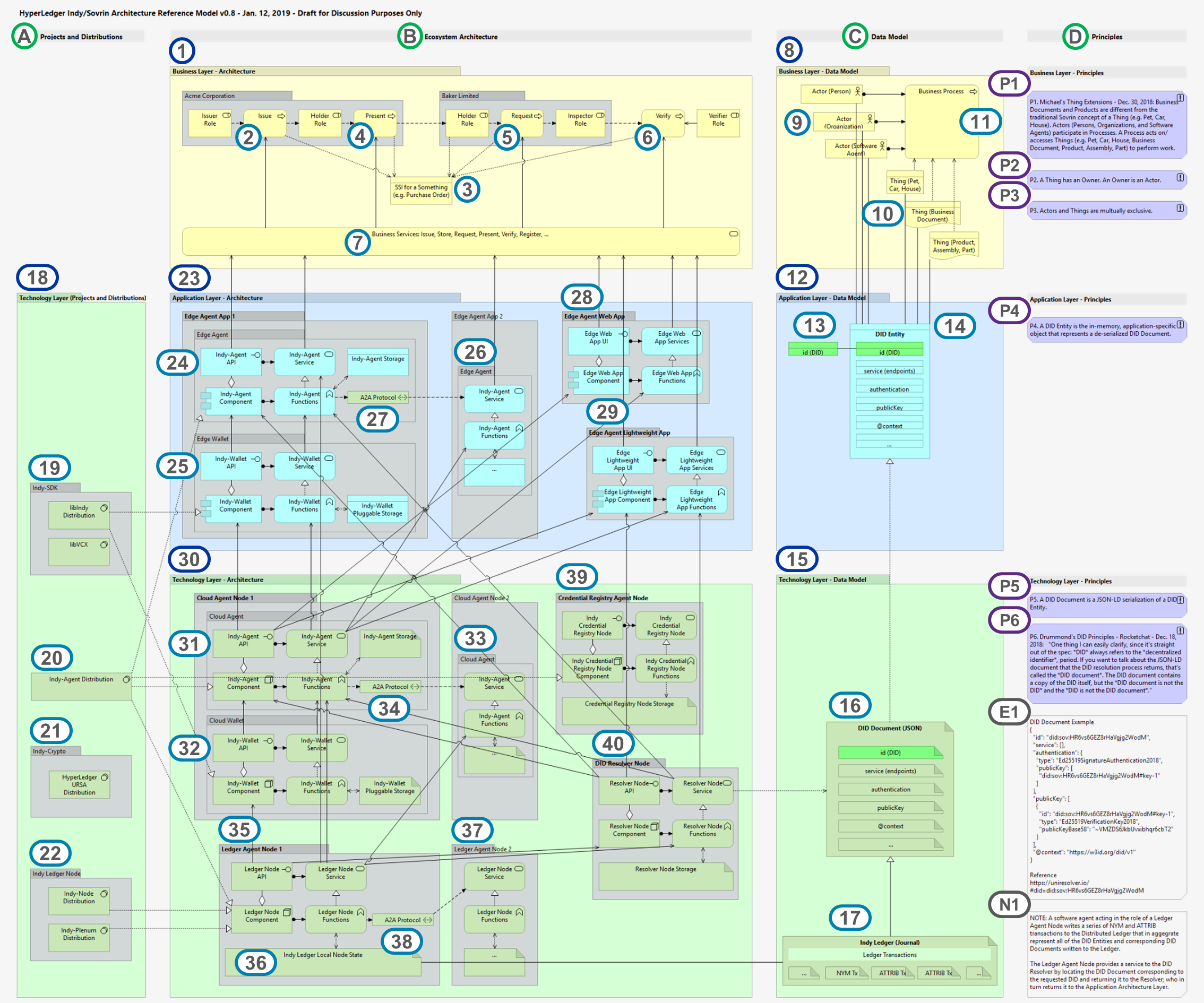
Copyright (c) 2019 Michael Herman (Alberta, Canada) – Creative Commons Attribution-ShareAlike 4.0 International Public License
https://creativecommons.org/licenses/by-sa/4.0/legalcode
How’s that for a confuding title? In a recent email discussion, a colleague compared the Decentralized Identifier framework to DNS …suggesting they were similar. I cautiously tended to agree but felt I had an overly simplistic understanding of DNS at a protocol level. That email discussion led me to learn more about the deeper details of how DNS actually works – and hence, this article.
On the surface, most people understand DNS to be a service that you can pass a domain name to and have it resolved to an IP address (in the familiar nnn.ooo.ppp.qqq format).
domain name => nnn.ooo.ppp.qqq
Examples:
- If you click on Google DNS Query for microsoft.com, you’ll get a list of IP addresses associated with the Microsoft’s corporate domain name microsoft.com.
- If you click on Google DNS Query for www.microsoft.com, you’ll get a list of IP addresses associated with the Microsoft’s corporate web site www.microsoft.com.
NOTE: The Google DNS Query page returns the DNS results in JSON format. This isn’t particular or specific to DNS. It’s just how the Google DNS Query page chooses to format and display the query results.
DNS is actually much more than a domain name to IP address mapping. DNS is an extensible name resolution framework and set of protocols for performing lookups of any name mapping the name to a collection of any type of data – any collection of name-value pairs (aka a collection of claims). This (and the fact that DNS servers and protocols have been in every day use by billions of computers around the world for several decades) makes DNS exceedingly well suited for managing any type of credential data (collections of claims).
DNS Resource Records
There is more to the DNS Service database than these simple (default) IP addresses. The DNS database stores and is able to return many different types of data (in addition to service-specific IP addresses) for a particular domain name. These data records are called DNS Resource Records. Here’s a partial list of the most common resource record types from http://dns-record-viewer.online-domain-tools.com:
Most APIs only support the retrieval of one Resource Record type at a time (which may return multiple records (e.g. IP addresses) of that type). Some APIs default to returning A records; while some APIs will only return A records. Caveat emptor.
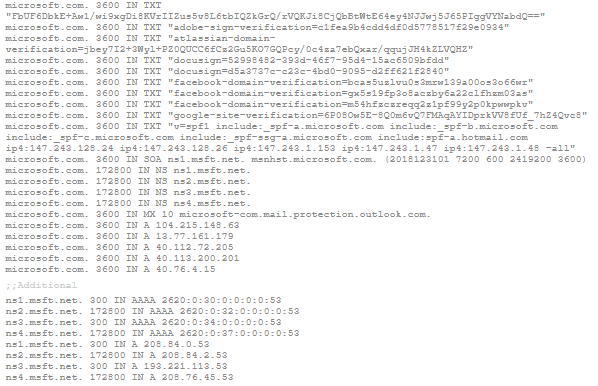
To see a complete set of DNS Resource Records for microsoft.com, click on DNSQuery.org query results for microsoft.com and scroll down to the bottom of the results page …to see the complete response (aka authoritative result). It will look something like this:
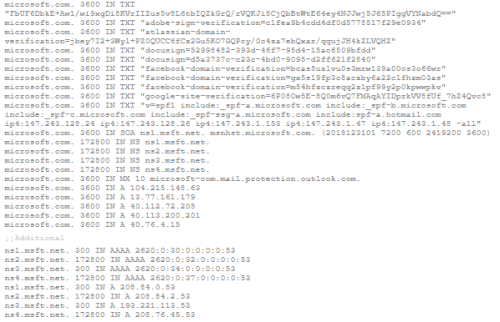
Figure 1. DNS Resource Records for microsoft.com: Authoritative Result
NOTE: The Resource Record type is listed in the fourth column: TXT, SOA, NS, MX, A, AAAA, etc.
UPDATE: The complete list of allowable value ranges for RR (resource record) types (QTYPEs) can be found here: IANA: Resource Record (RR) TYPEs.
DNS Protocol
The most interesting new information/learnings is about the DNS protocol itself. It’s request/response …nothing new here. It’s entirely binary …to be expected given its age and the state of technology at that time. Given how frequently DNS is used by every computer on the planet, the efficientcy of a binary protocol also makes sense. The IETF published the original specifications in RFC 882 and RFC 883 in November 1983.
The interesting part of the protocol is that a DNS client typically doesn’t “download” the entire authoritative set of DNS Resource Records all at once for a particular domain, the most common API approach is to request the list of relevant data (e.g. IP addresses) for a particular Resource Record type for a particular domain.
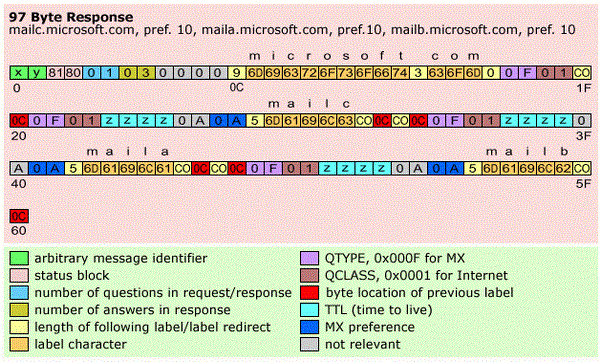
The format of a sample DNS request is illustrated in the following figure:
 Figure 2. Sample DNS Request [CODEPROJECT]
Figure 2. Sample DNS Request [CODEPROJECT]
It’s binary. The 16-bit QTYPE field (purple cells on the right side) defines the type of query. In this case 0x0F is a request for an MX record; hence, this is a request for the data that describes microsoft.com’s external email server interface.
NOTE: The fact that the QTYPE field is 16-bit implies that DNS is designed to support many more than the few dozen Resource Record types in current use.
NOTE: The “relevant data” isn’t always an IP address or a list of IP addresses. For example, response may include another domain name, subdomain name, or, in some cases, simply some unstructured text (as far as the DNS specification is concerned).
Here is a typical response for the above sample request:
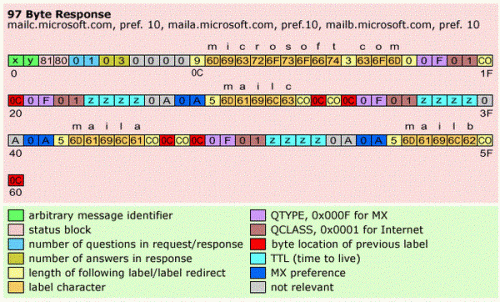 Figure 3. Sample DNS Response [CODEPROJECT]
Figure 3. Sample DNS Response [CODEPROJECT]
The response in turn is also binary. In this case, DNS has responded with 3 answers; that is, 3 subdomain names: mailc, maila, and mailb – each with a numerical preference (weight).
ANY Resource Record Type
There is also a “meta” Resource Record Type called ANY that, as you might guess, requests a collection of all of the different Resource Record type records for a specific domain. This is illustrated in Figure 1 above.
DNS Extensibility
DNS is also a general-purpose, extensible framework and existing, accepted, deployed software platform and network for creating, managing, finding, and retrieving what are, in effect, Credentials associated with a Universal Digital Identifiers (DID) (aka hierarchical domain name). A credential in turn is a set of Claims where a claim is a name-value pair associated with the particular DID. Here’s some examples.
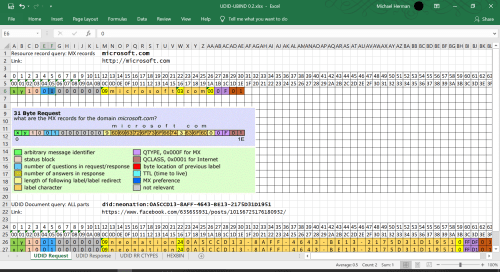
Figure 4. Universal Digital Identifier Example: DNS Binary Protocol
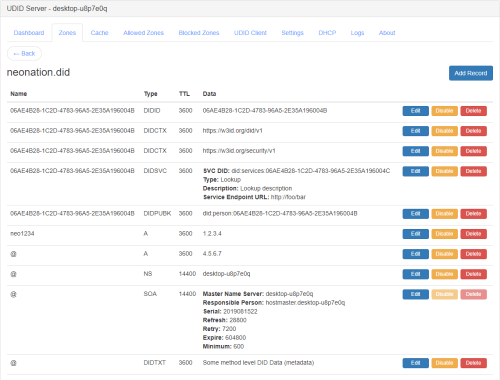
Figure 5. Universal Digital Identifier Example: UDID Credential (DID Document)

Figure 6. Universal Digital Identifier Example: DNS over HTTP Response (Credential/DID Document)
For more information on how DNS can be extended to support products like the Trusted Digital Web, checkout Trusted Digital Web: Whitepaper.
Best regards,
Michael Herman (Toronto/Calgary/Seattle)