Michael Herman Chief Digital Officier Web 7.0 Foundation
JUNE 2, 2026
Abstract
Computing is undergoing a seismic shift from client/server and cloud computing to decentralization, a change of greater importance and impact compared to the transition from i) mainframe to client/server and ii) client/server to cloud computing. Speculation abounds on how this new era will evolve in the coming years, and IT leaders have a critical need for an unclouded vision of where the industry is heading. The author believes the best way to form this vision is to understand the underlying economics driving the long-term trend toward decentralization. In this report, we describe the importance of decentralization and assess its economics through in-depth modelling. This report builds on the economic knowledge of several researchers and practitioners. The report draws on landmark works in platform economics, network effects, and technology disruption to build a rigorous framework for understanding the long-term implications of decentralization for Information Technology.
This article describes Web 7.0 Pando™ Decentralized Library OS – with a specific focus on the Web 7.0 NeuromorphicAgent Architecture Reference Model (NAARM) used by Pando to support the creation of Web 7.0 Decentralized Societies.
The intended audience for this document is a broad range of professionals interested in furthering their understanding of Web 7.0 Pando for use in software apps, agents, and services. This includes software architects, application developers, and user experience (UX) specialists, as well as people involved in a broad range of standards efforts related to decentralized identity, verifiable credentials, and secure storage.
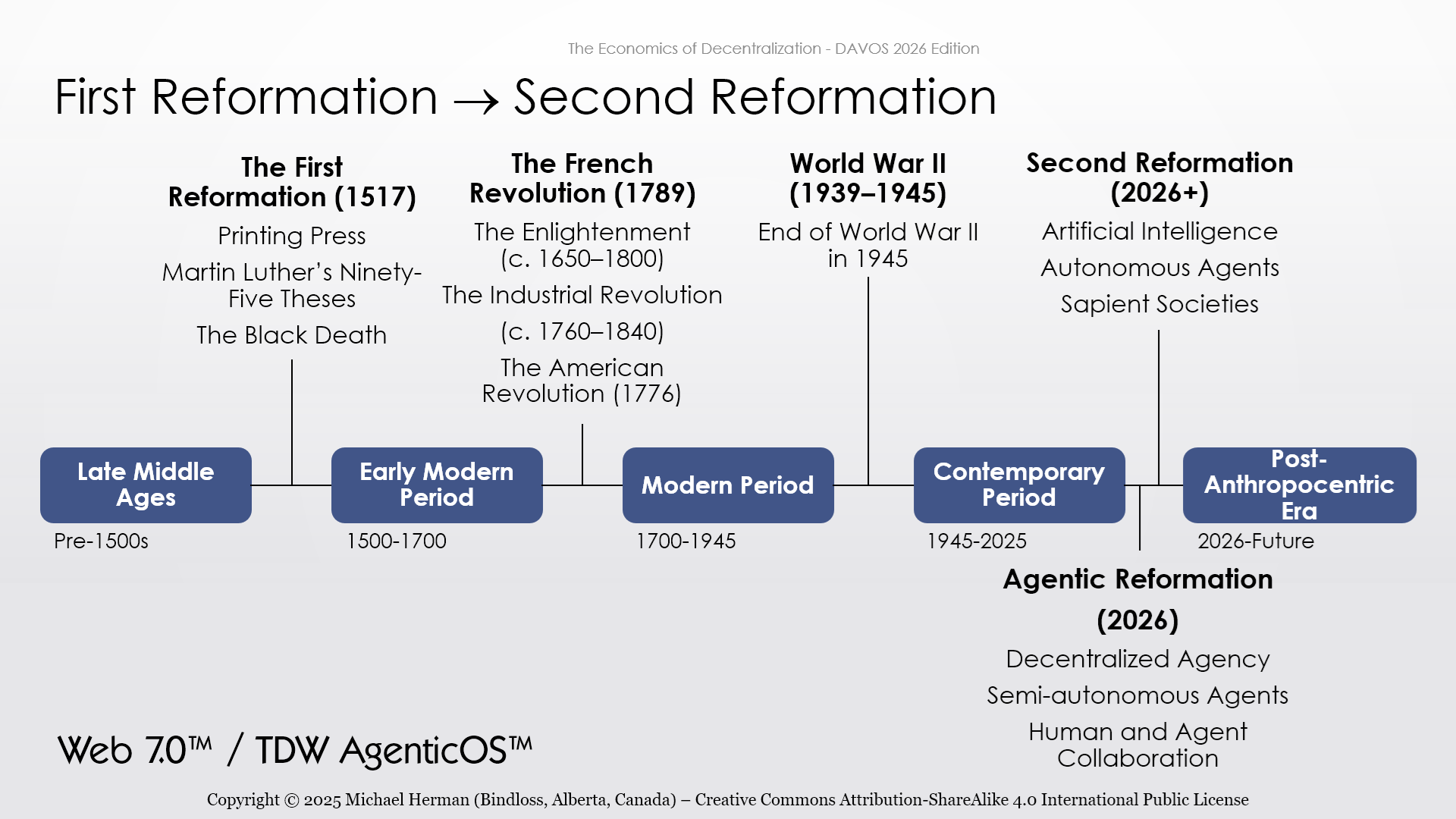
The Second Reformation
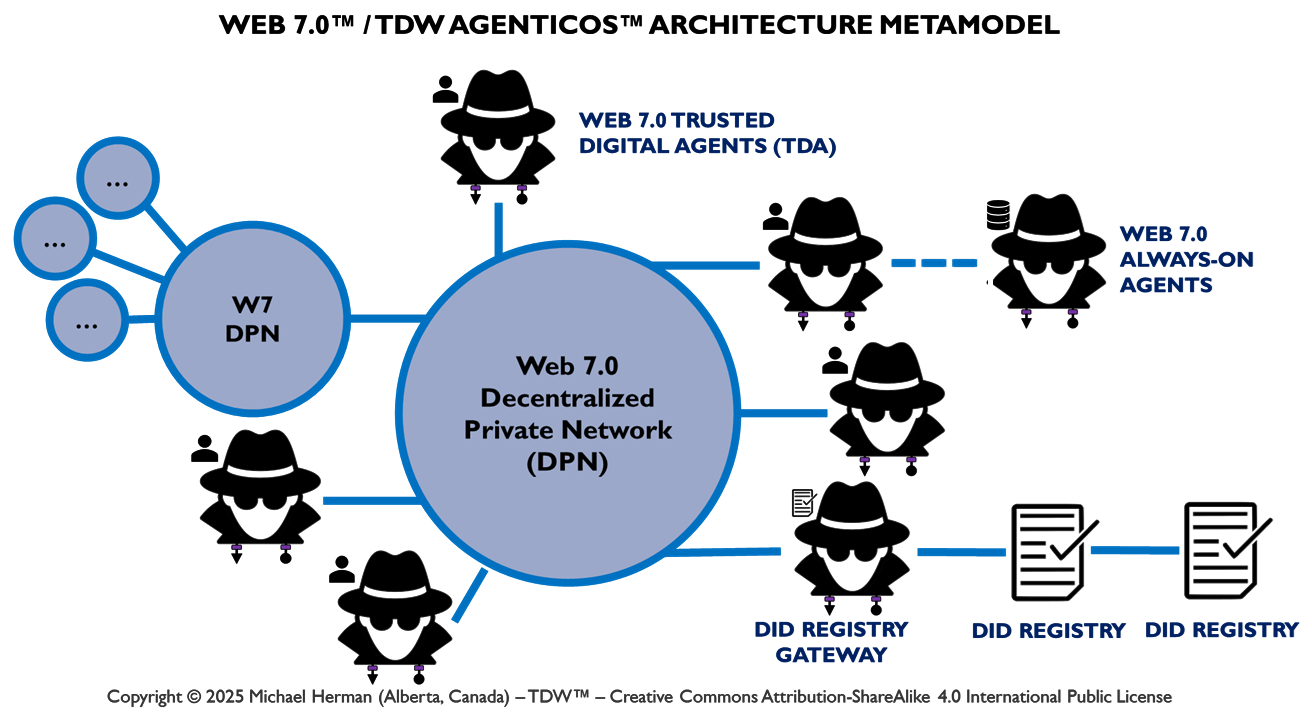
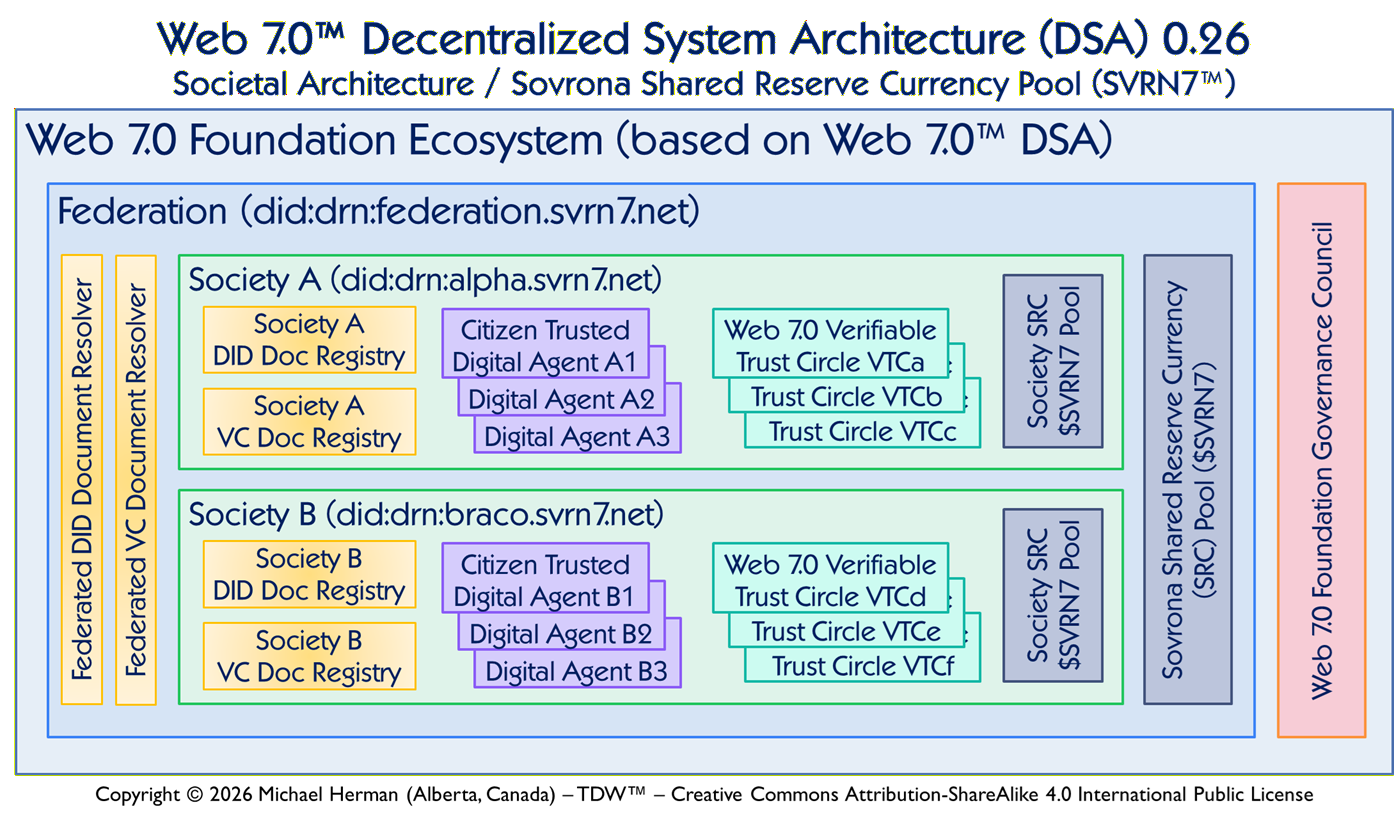
Web 7.0 Foundation Ecosystem
“Web 7.0 is a unified software and hardware ecosystem for building resilient, trusted, decentralized systems using decentralized identifiers, DIDComm agents, and verifiable credentials.” Michael Herman, Trusted Digital Web (TDW) Project, Hyperonomy Digital Identity Lab, Web 7.0 Foundation. January 2023.
Web 7.0 Pando is a macromodular, neuromorphic agent platform for coordinating and executing complex systems of work that is:
Secure
Trusted
Open
Resilient
Web 7.0 Pando™ is 100% Albertan by birth and open source.
Project “Shorthorn”
Project “Shorthorn” is a parody project name based on Microsoft’s Windows “Longhorn” WinFS project (a SQL-based Windows File System project) with which the author was involved in from a design preview and feedback, consulting, and PM technical training (Groove Workspace system architecture and operation) perspectives (circa 2001-2002).
What makes Shorthorns great: – They’re good at turning grass into meat (great efficiency). – Shorthorn cows are amazing mothers and raise strong, healthy calves (nurture great offspring). – Their genetics blend well with other breeds for strong hybrid calves (plays well with others). …and so it is with Web 7.0 Pando.
Web 7.0 Foundation
The Web 7.0 Foundation, a federally-incorporated Canadian non-profit corporation, is chartered to develop, support, promote, protect, and curate the Web 7.0 ecosystem: Web 7.0 Pando operating system software, and related standards and specifications. The Foundation is based in Alberta, Canada.
What we’re building at the Web 7.0 Foundation is described in this quote from Don Tapscott and co.:
“We see an alternate path: a decentralized platform for our digital selves, free from total corporate control and within our reach, thanks to co-emerging technologies.” “A discussion has begun about “democratizing AI.” Accessibility is critical. Mostaque has argued that the world needs what he calls “Universal Basic AI.” Some in the technology industry have argued that AI can be democratized through open source software that is available for anyone to use, modify, and distribute. Mostaque argues that this is not enough. “AI also needs to be transparent,” meaning that AI systems should be auditable and explainable, allowing researchers to examine their decision-making processes. “AI should not be a single capability on monolithic servers but a modular structure that people can build on,” said Mostaque. “That can’t go down or be corrupted or manipulated by powerful forces. AI needs to be decentralized in both technology, ownership and governance.” He’s right.” You to the Power Two. Don Tapscott and co. 2025.
A Word about the Past
The Web 7.0 project has roots dating back approximately 30 years to before 1998 with the release of Alias Upfront for Windows. Subsequent to the release of Upfront (which Bill Gates designated as the “most outstanding graphics product for Microsoft Windows 3.0”), the AUSOM Application Design Framework was formalized.
AUSOM Application Design Framework
AUSOM is an acronym for A User State of Mind — the name of a framework or architecture for designing software applications that are easier to design, implement, test, document and support. In addition, an application developed using the AUSOM framework is more capable of being: incrementally enhanced, progressively installed and updated, dynamically configured and is capable of being implemented in many execution environments. This paper describes the Core Framework, the status of its current runtime implementations and its additional features and benefits.
What is AUSOM?
The AUSOM Application Design Framework, developed in 1998, is a new way to design client-side applications. The original implementation of the framework is based on a few basic concepts: user scenarios and detailed task analysis, visual design using state-transition diagrams, and implementation using traditional Windows message handlers.
The original motivation for the framework grew out of the need to implement a highly modeless user interface that was comprised of commands or tasks that were very modal (e.g. allowing the user to change how a polygon was being viewed while the user was still sketching the boundary of the polygon).
The following is essentially the same advice I received from Charles Simonyi when we were both at Microsoft (and one of the reasons why I eventually left the company in 2001).
“No problem can be solved from the same level of consciousness that created it.” [Albert Einstein] “The meaning of this quote lies in Einstein’s belief that problems are not just technical failures but outcomes of deeper ways of thinking. He suggested that when people approach challenges using the same assumptions, values, and mental habits that led to those challenges, real solutions remain out of reach. Accoding to this idea, improvement begins only when individuals are willing to step beyond familiar thought patterns and question the mindset that shaped the problem.” [Economic Times]
Simonyi et al., in the paper Intentional Software, state:
For the creation of any software, two kinds of contributions need to be combined even though they are not at all similar: those of the domain providing the problem statement and those of software engineering providing the.implementation. They need to be woven together to form the program.
Web 7.0 Pando is the software for building decentralized societies.
A Word about the Future
“Before the next century is over, human beings will no longer be the most intelligent or capable type of entity on the planet. Actually, let me take that back. The truth of that last statement depends on how we define human.” Ray Kurzweil. 1999.
NOTE: “Artificial Intelligence” (or “AI”) does not appear anywhere in the remainder of this article. The northstar of the Web 7.0 project is to be a unified software and hardware ecosystem for building resilient, trusted, decentralized systems using decentralized identifiers, DIDComm agents, and verifiable credentials – regardless of whether the outcome (a Web 7.0 network) uses AI or not. Refer to Figures 4a, 4b, and 6 for a better understanding.
DIDComm Notation, a visual language for architecting and designing decentralized systems, was used to create the figures in this article.
Value Proposition
By Personna
Business Analyst – Ability to design and execute, secure, trusted business processes of arbitrary complexity across multiple parties in multiple organizations – anywhere on the planet.
Global Hyperscaler Administrators – Ability to design and execute, secure, trusted systems administration processes (executed using PowerShell) of arbitrary complexity across an unlimited number of physical or virtual servers hosted by an unlimited number of datacenters, deployed by multiple cloud (or in-house) xAAS providers – anywhere on the planet.
App Developers – Ability to design, build, deploy, and manage secure, trusted network-effect-by-default apps of arbitrary complexity across multiple devices owned by anybody – anywhere on the planet.
Smartphone Vendors – Ability to upsell a new category of a second device, a Web 7.0 Always-on Trusted Digital Assistant – a pre-integrated hardware and software solution, that pairs with the smart device that a person already owns. Instead of a person typically purchasing/leasing one smartphone, they can now leverage a Web 7.0-enabled smartphone bundle that also includes a secure, trusted, and decentralized communications link to a Web 7.0 Always-on Trusted Digital Assistant deployed at home (or in a cloud of their choosing).
Digital Church/Religion Builders – Ability to create a new decentralized digital religion for 1 billion people in Communist China.
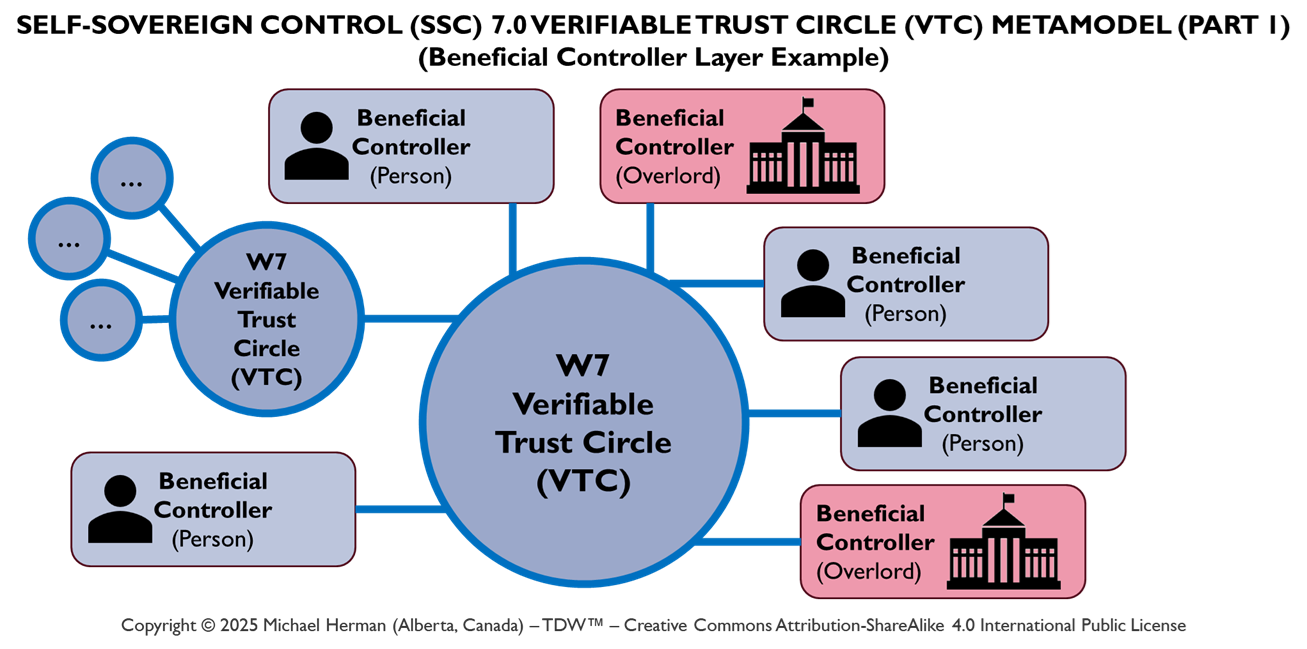
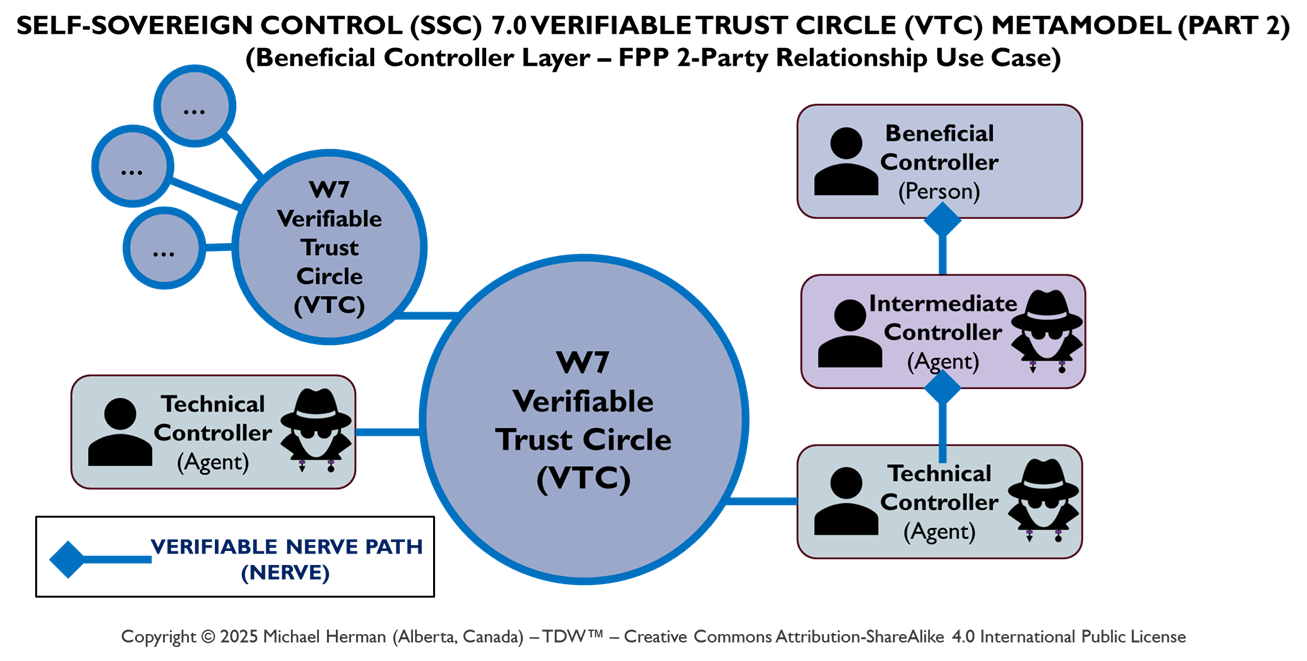
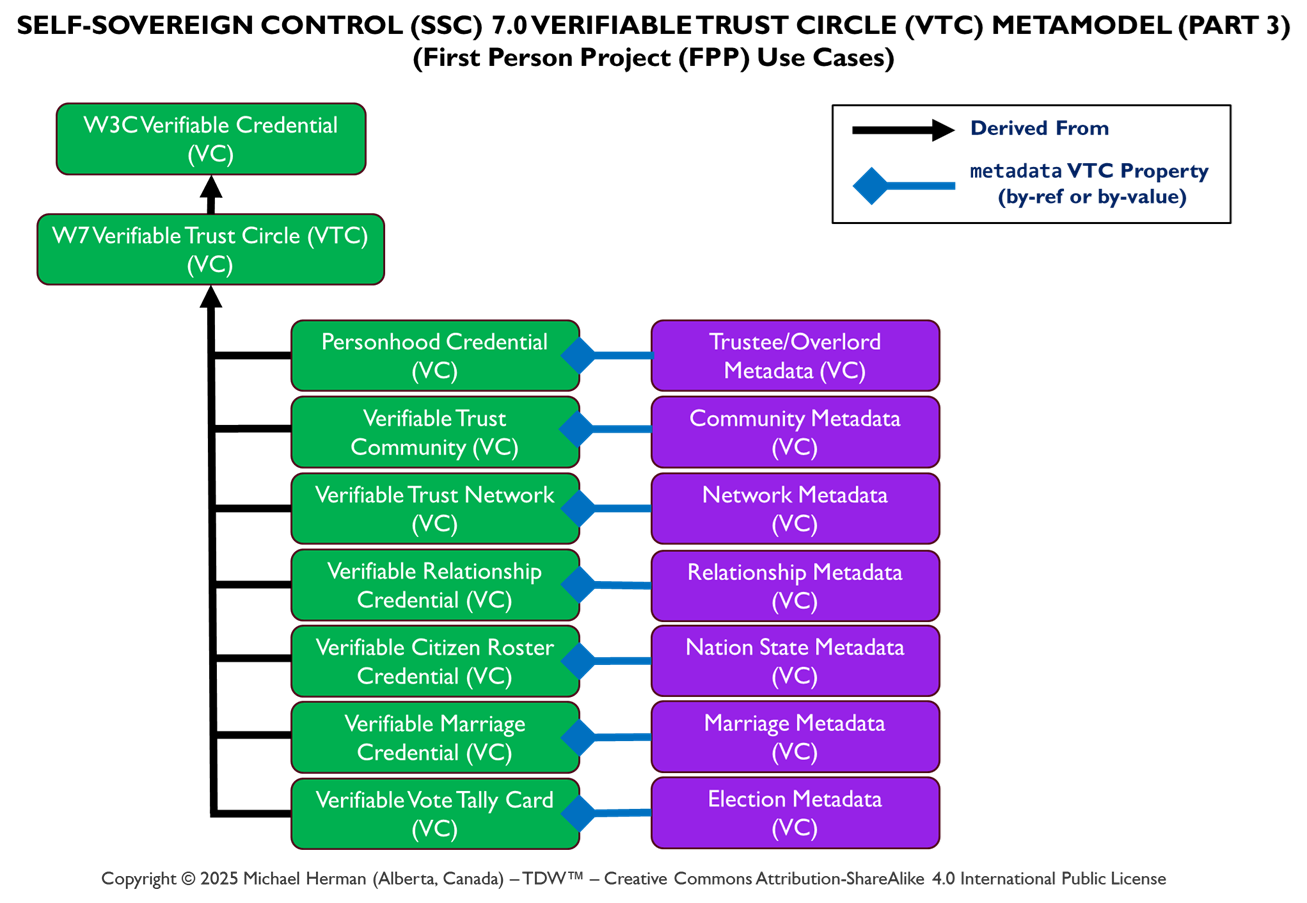
By Trust Relationship (Verifiable Trust Circle (VTC))
Secure, Trusted Agent-to-Agent Messaging Model
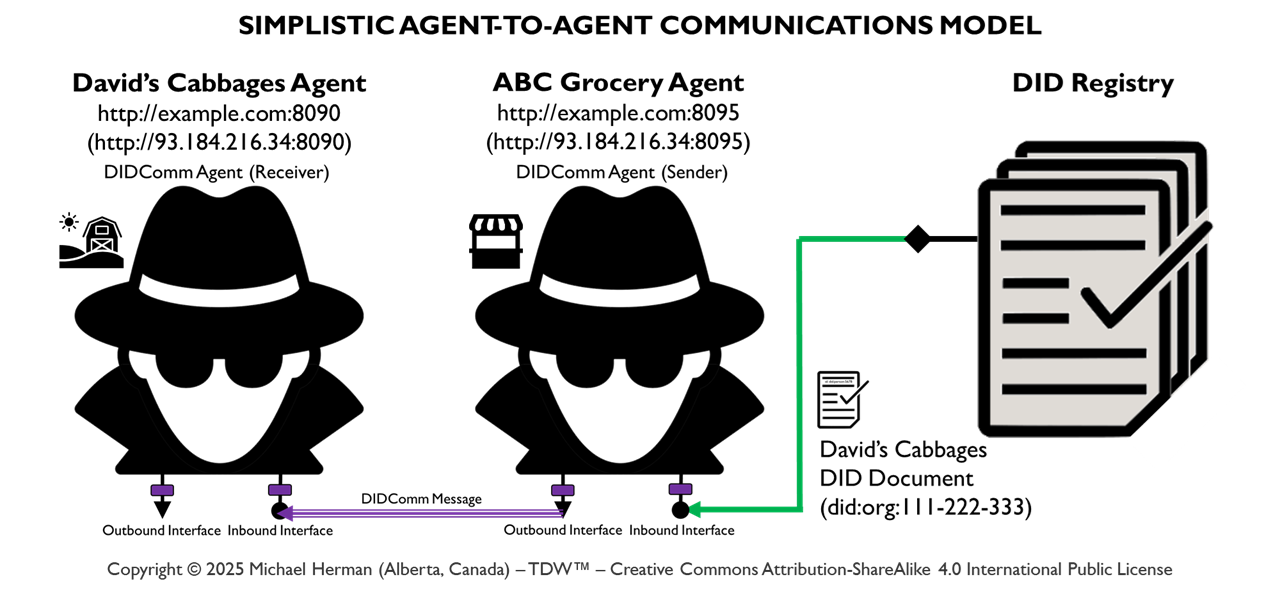
Figure 0. Simple Agent-to-Agent Communications Model
Figure 0. depicts the design of a typical simple agent-to-agent communications model. DIDComm Notation was used to create the diagram.
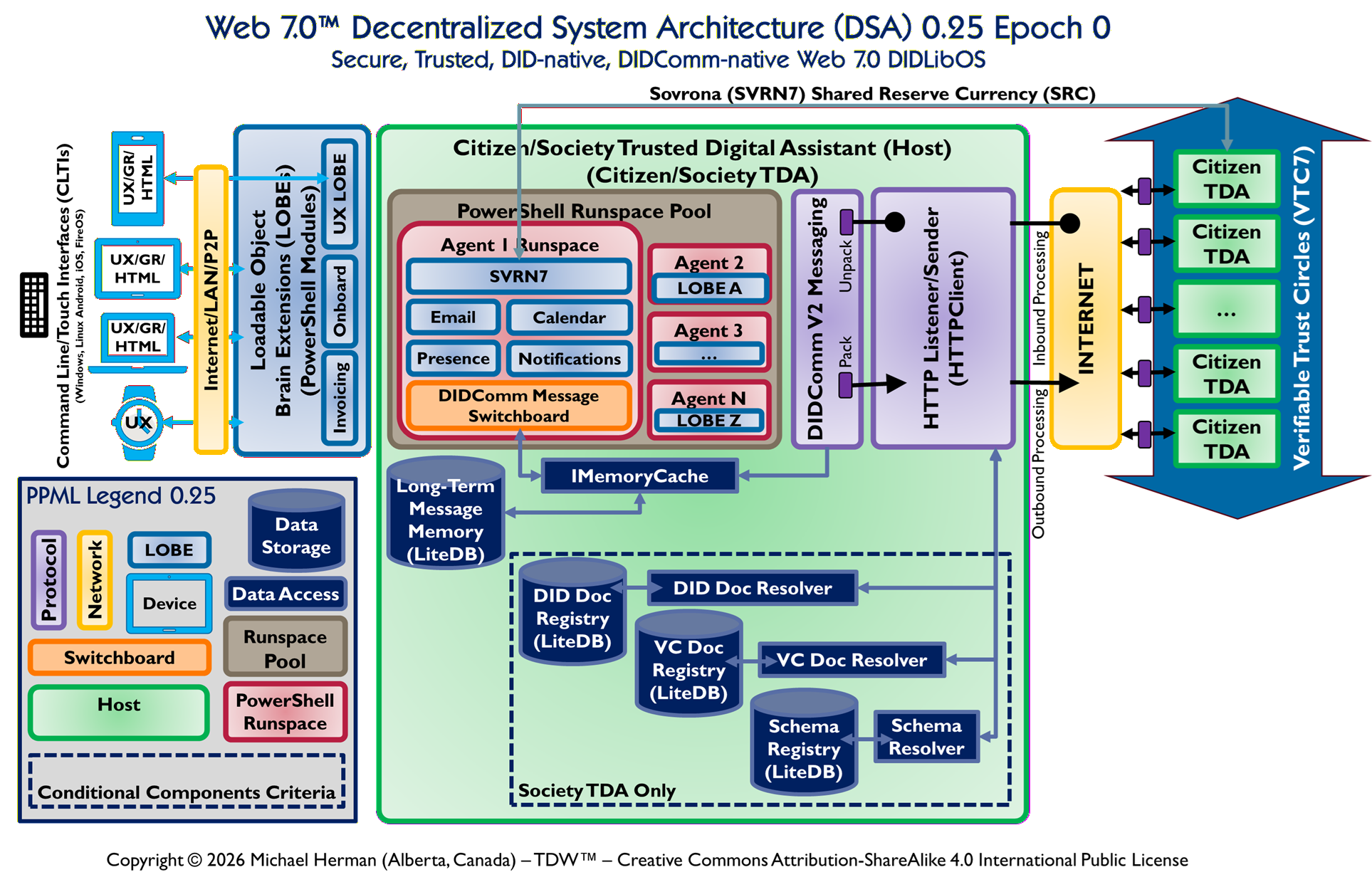
Web 7.0 Pando: Conceptual and Logical Architecture
The Web 7.0 architecture is illustrated in the following figure.
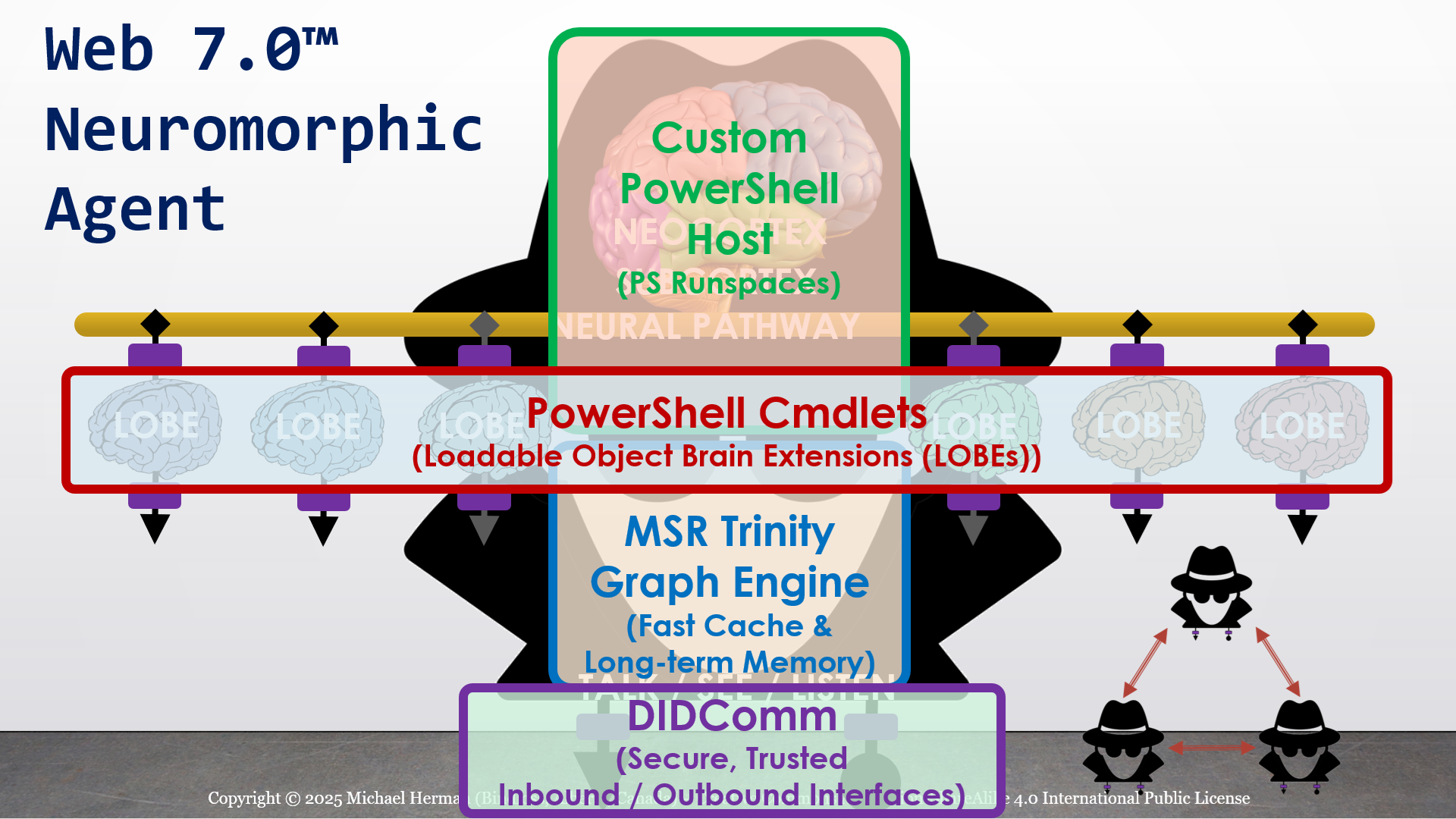
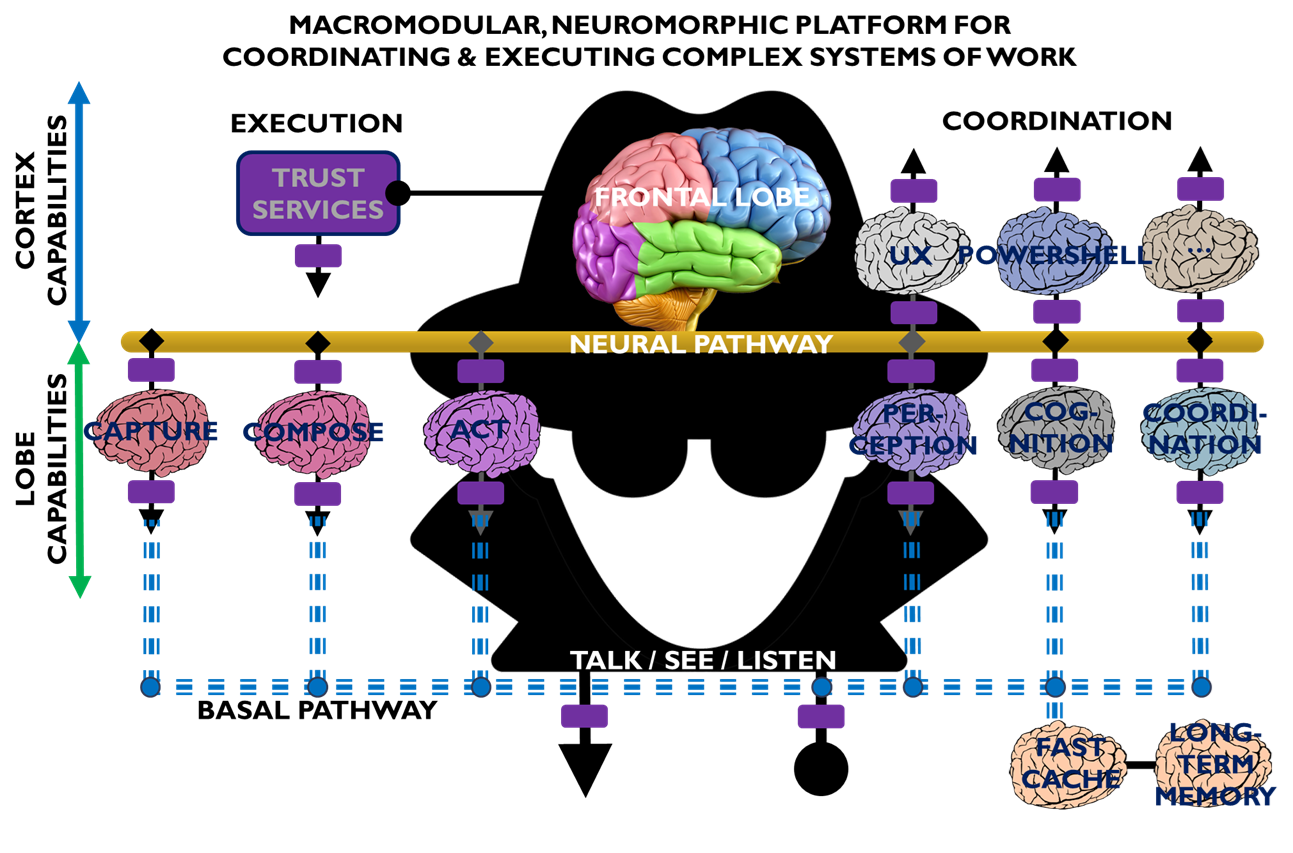
Figure 1. Web 7.0 Neuromorphic Agent
Figure 1 is an all-in illustration of the conceptual architecture of a Web 7.0 Neuromorphic Agent. A Web 7.0 Agent is comprised of a Frontal LOBE and the Neural Messaging pathway. An Agent communicates with the outside world (other Web 7.0 Agents) using its Outbound (Talking), Seeing, and Inbound (Listening) Interfaces. Agents can be grouped together into Neural Clusters to form secure and trusted multi-agent organisms. DIDComm/HTTP is the default secure digital communications protocol (see DIDComm Messages as the Steel Shipping Containers of Secure, Trusted Digital Communication). The Decentralized Identifiers (DIDs) specification is used to define the Identity layer in the Web 7.0 Messaging Superstack (see Figure 6 as well as Decentralized Identifiers (DIDs) as Barcodes for Secure, Trusted Digital Communication).
An agent remains dormant until it receives a message directed to it and returns to a dormant state when no more messages are remaining to be processed. An agent’s message processing can be paused without losing any incoming messages. When an agent is paused, messages are received, queued, and persisted in long-term memory. Message processing can be resumed at any time.
Additionally, an Agent can include a dynamically changing set of Coordination and Execution LOBEs. These LOBEs enable an Agent to capture events (incoming messages), compose responses (outgoing messages), and share these messages with one or more Agents (within a specific Neural Cluster or externally with the Beneficial Agent in other Neural Clusters (see Figure 5)).
What is a LOBE?
LOBE (Loadable Object Brain Extensions) is a macromodular, neuromorphic intelligence framework designed to let systems grow, adapt, and evolve by making it easy to add new capabilities at any time. Each LOBE is a dynamically Loadable Object — a self-contained cognitive module that extends the Frontal LOBE’s functionality, whether for perception, reasoning, coordination, or control (execution). Together, these LOBEs form a dynamic ecosystem of interoperable intelligence, enabling developers to construct distributed, updatable, and extensible minds that can continuously expand their understanding and abilities.
LOBEs lets intelligence and capability grow modularly. Add new lobes, extend cognition, and evolve systems that learn, adapt, and expand over time. Expand your brain. A brain that grows with every download.
What is a NeuroPlex?
A Web 7.0 Neuroplex (aka a Neuro) is a dynamically composed, decentralized, message-driven cognitive solution that spans one or more agents, each with its own dynamically configurable set of LOBEs (Loadable Object Brain Extensions). Each LOBE is specialized for a particular type of message. Agents automatically support extraordinarily efficient by-reference, in-memory, intra-agent message transfers. A Web 7.0 Neuroplex is not a traditional application or a client–server system, but an emergent, collaborative execution construct assembled from independent, socially-developed cognitive components (LOBEs) connected together by messages. Execution of a Neuroplex is initiated with a NeuroToken.
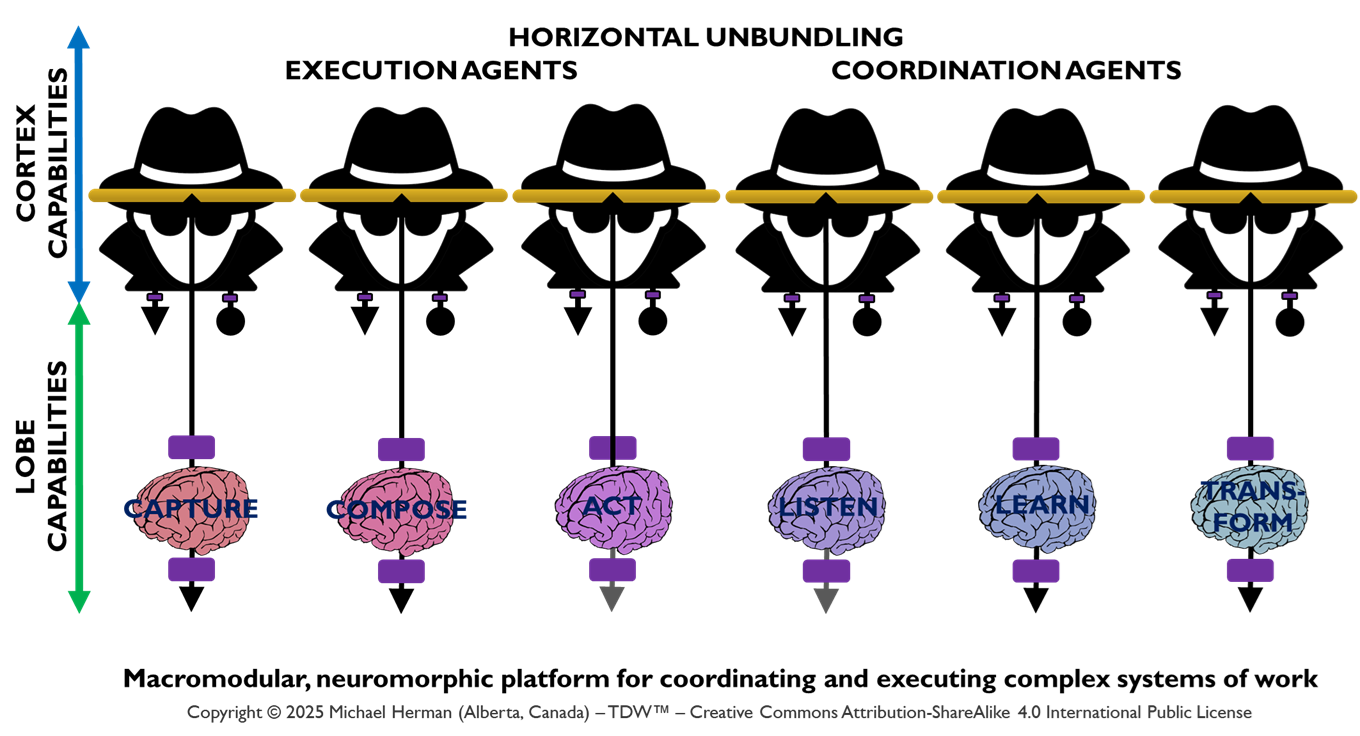
Horizontal Unbundling: Coordination and Execution Agents
Figure 2. Web 7.0 Pando: Agent Logical Architecture: Horizontal Unbundling
Figure 2 illustrates how the deployment of Coordination and Execution LOBEs can be horizontally unbundled – with each LOBE being assigned to a distinct Frontal LOBE. This is an extreme example designed to underscore the range of deployment options that are possible. Figure 3 is a more common pattern.
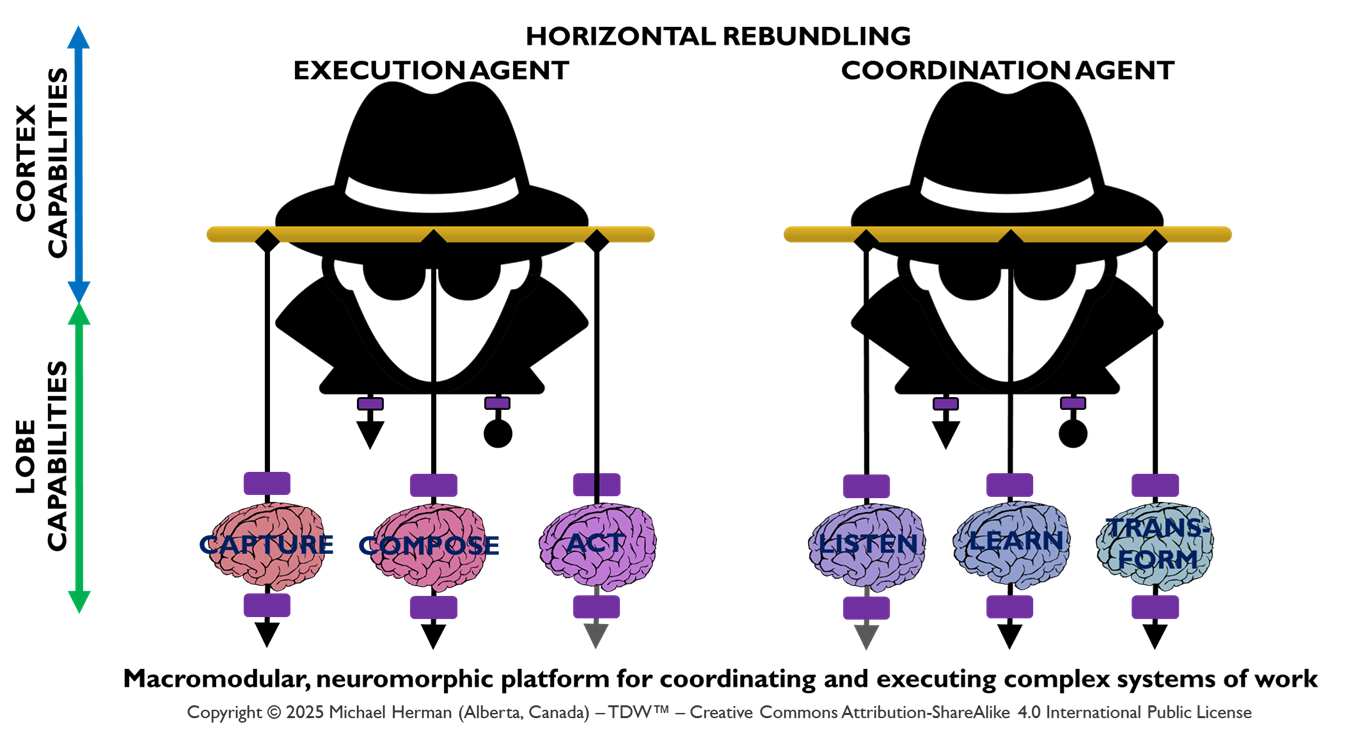
Horizontal Rebundling
Figure 3. Web 7.0 Pando: Agent Logical Architecture: Horizontal Rebundling
Figure 3 depicts a more common/conventional deployment pattern where, within a Neural Cluster, a small, reasonable number of Frontal LOBEs host any collection of Coordination and/or Execution LOBEs.
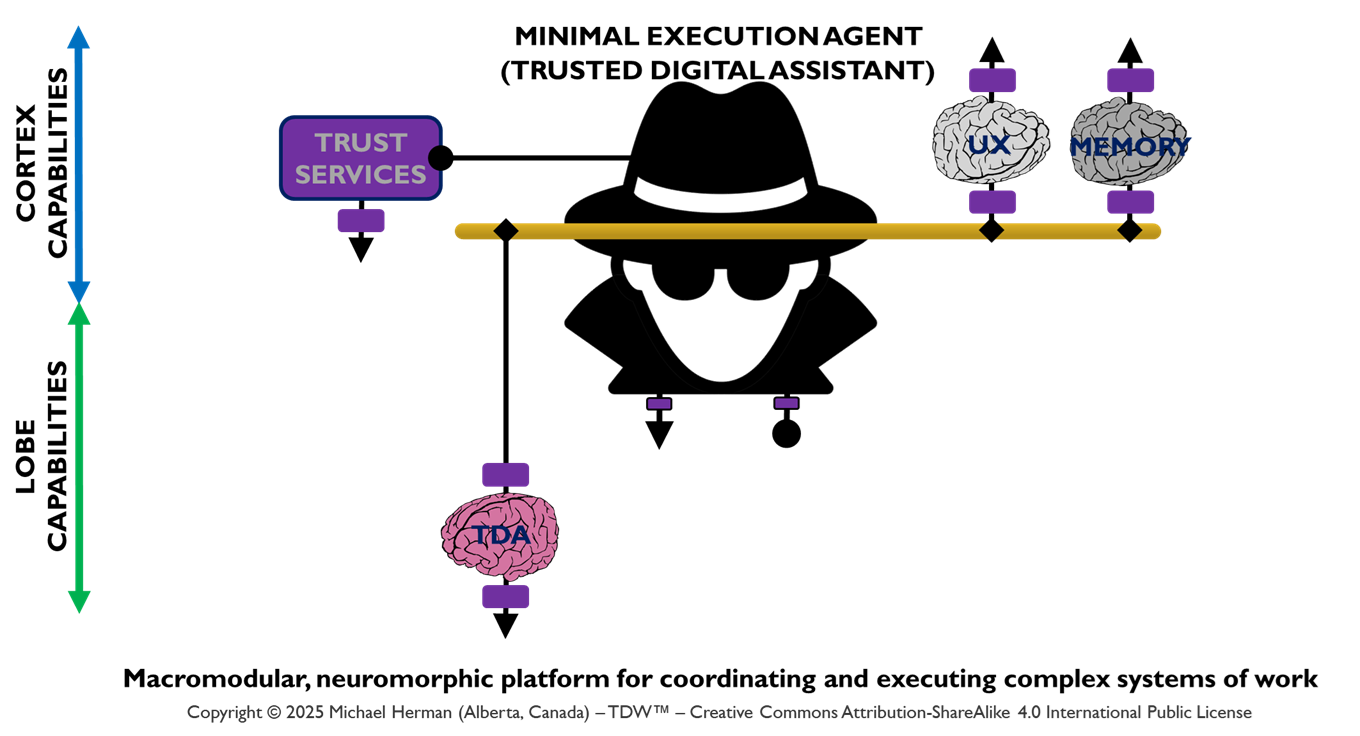
Minimal Execution Agent (Trusted Digital Assistant)
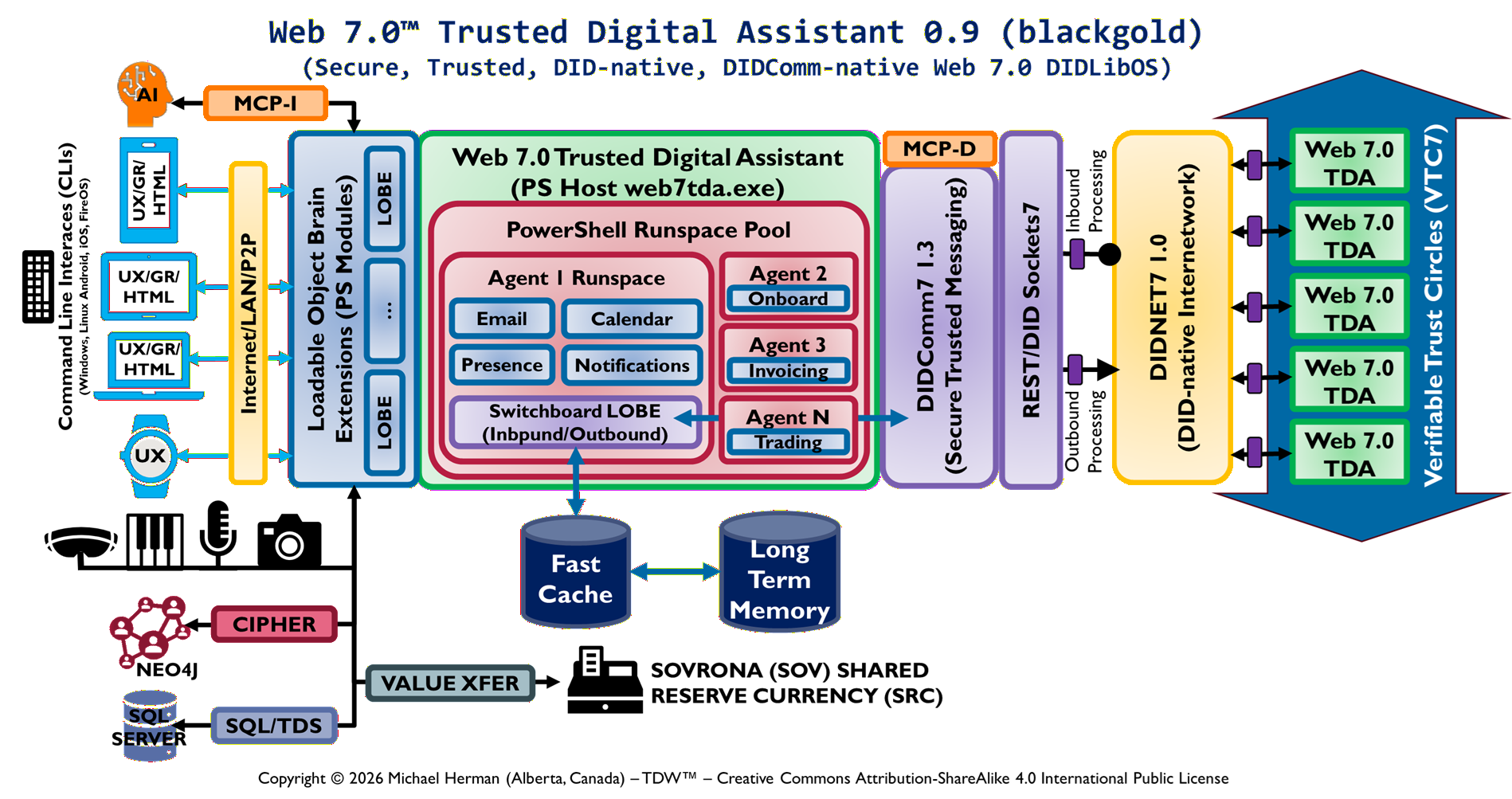
Figure 4a is an example of a minimal agent deployment pattern that hosts a single Trusted Digital Assistant (TDA) LOBE.
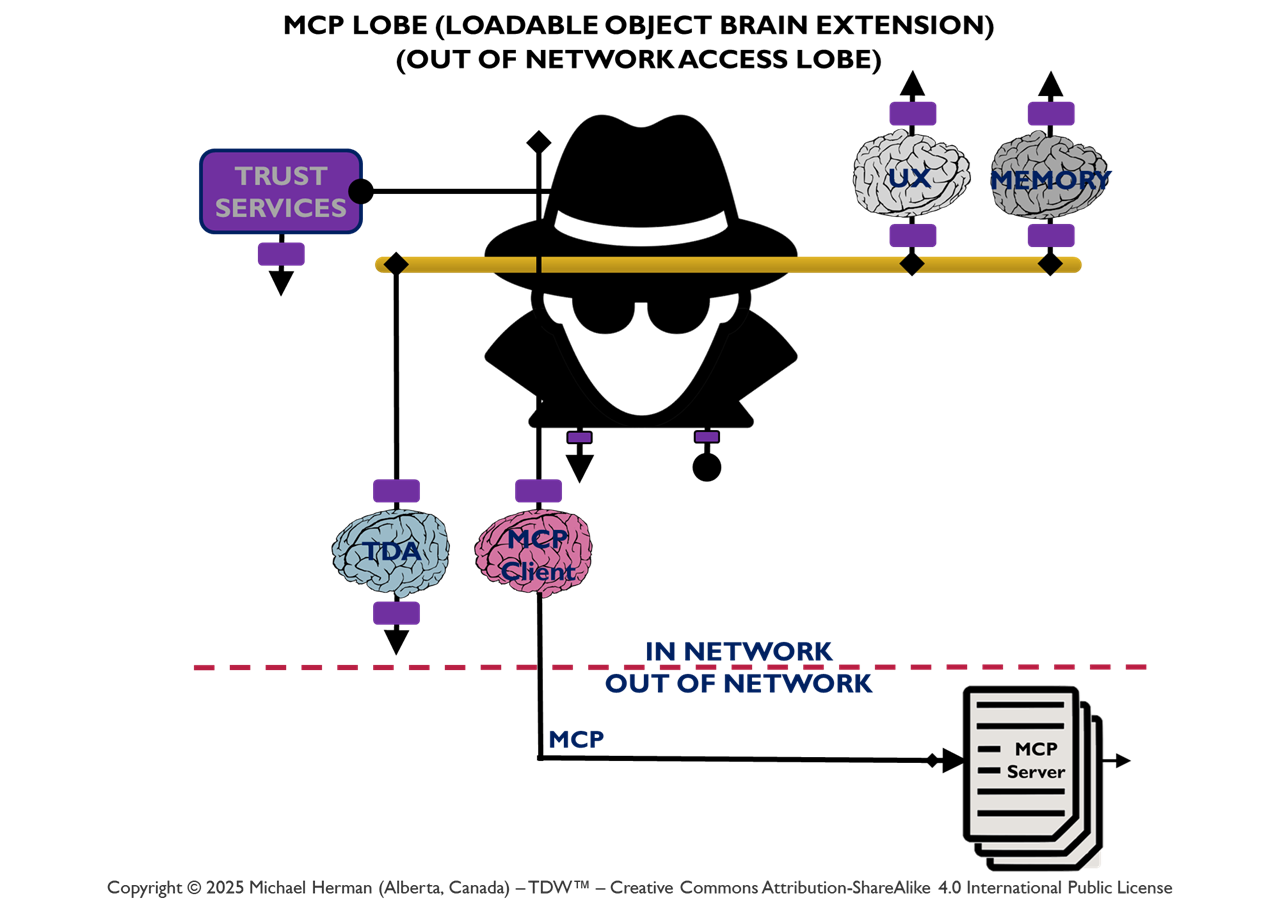
Figure 4b MCP-enabled Trusted Digital Assistant
Vertical Debundling: Web 7.0 Neural Clusters
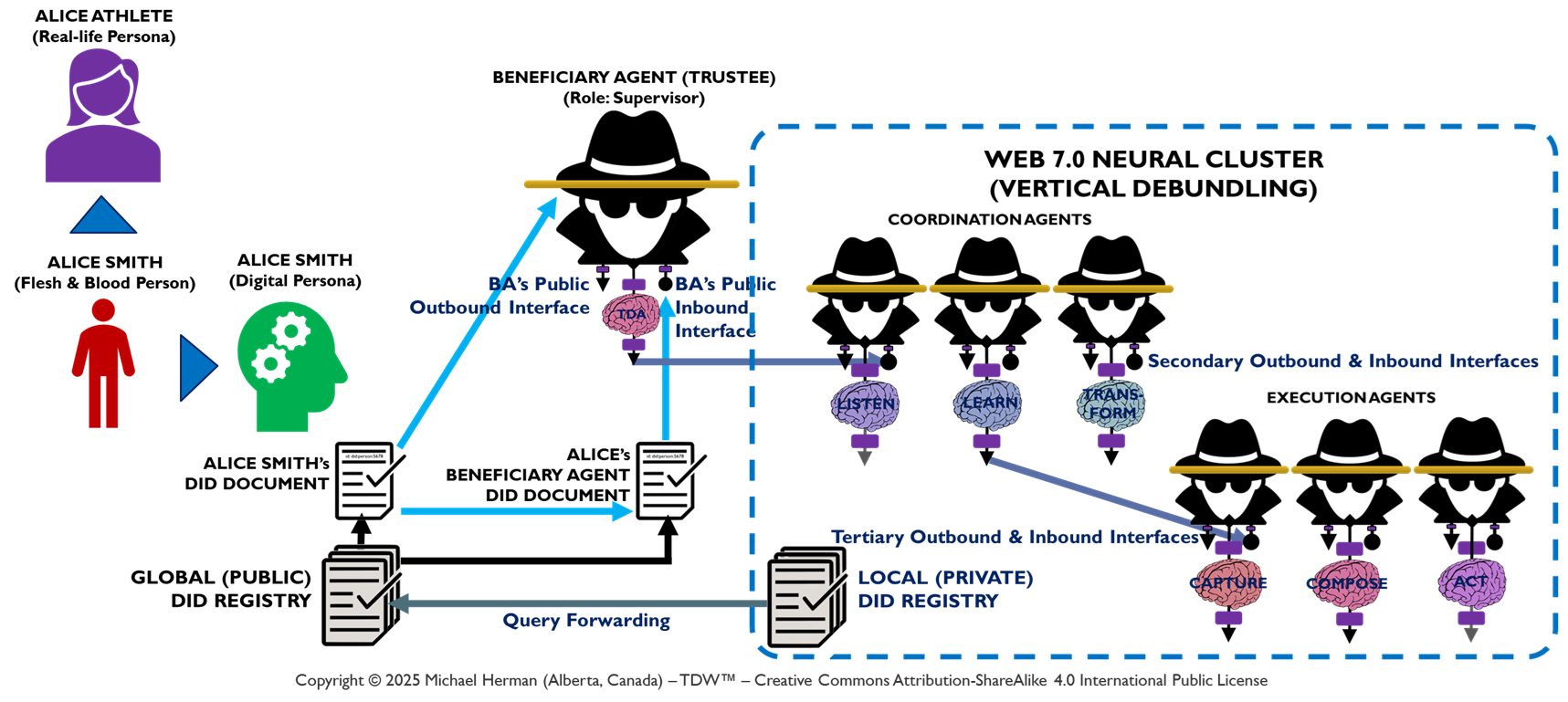
Figure 5. Web 7.0 Pando: Agent Logical Architecture: Neural Clusters and Beneficial Agents
Figure 5 depicts the deployment of a Web 7.0 Neural Cluster. Messages external to the Neural Cluster are only sent/received from the Beneficial Agent. Any additional messaging is limited to the Beneficial, Coordination, and Execution LOBEs deployed within the boundary of a Neural Cluster. A use case that illustrates the Neural Cluster model can be found in Appendix D – PWC Multi-Agent Customer Support Use Case.
DIDComm 7.0
Figure 6a. Web 7.0 Pando: Conceptual Architecture (All-in)
Figure 6a is an all-in illustration of the conceptual architecture of a Web 7.0 Neuromorphic Agent. DIDComm Messages can be piped from the Outbound Interface of the Sender agent to the Inbound Agent of of Receiver agent – supporting the composition of secure, trusted agent-to-agent pipelines similar (but superior) to: i) UNIX command pipes (based on text streams), and ii) PowerShell pipelines (based on a .NET object pump implemented by calling ProcessObject() in the subsequent cmdlet in the pipeline).
NOTE: PowerShell does not clone, serialize, or duplicate .NET objects when moving them through the pipeline (except in a few special cases). Instead, the same instance reference flows from one pipeline stage (cmdlet) to the next …neither does DIDComm 7.0 for DIDComm Messages.
Bringing this all together, a DIDComm Message (DIDMessage) can be passed, by reference, from LOBE (Agenlet) to LOBE (Agenlet), in-memory, without serialization/deserialization or physical transport over HTTP (or any other protocol).
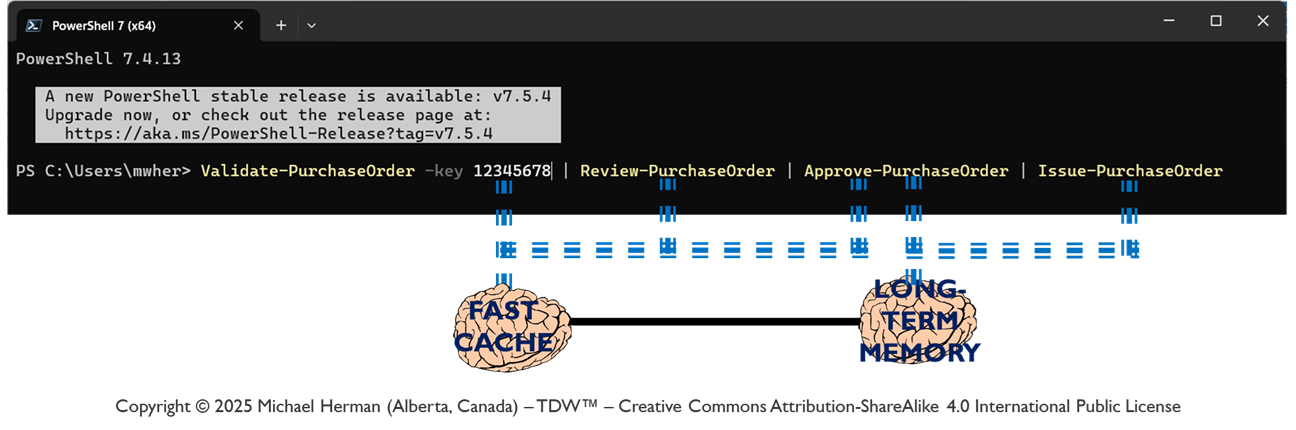
PowerShell
DIDComm 7.0
powershell.exe
tdwagent.exe
Cmdlet
LOBE (Loadable Object Brain Extension)
.NET Object
Verifiable Credential (VC)
PSObject (passed by reference)
DIDMessage (JWT) (passed by reference)
PowerShell Pipeline
Web 7.0 Verifiable Trust Circle (VTC)
Serial Routing (primarily)
Arbitrary Graph Routing (based on Receiver DID, Sender DID, and DID Message type)
Feedback from a reviewer: Passing DIDComm messages by reference like you’re describing is quite clever. A great optimization.
Coming to a TDW LOBE near you…
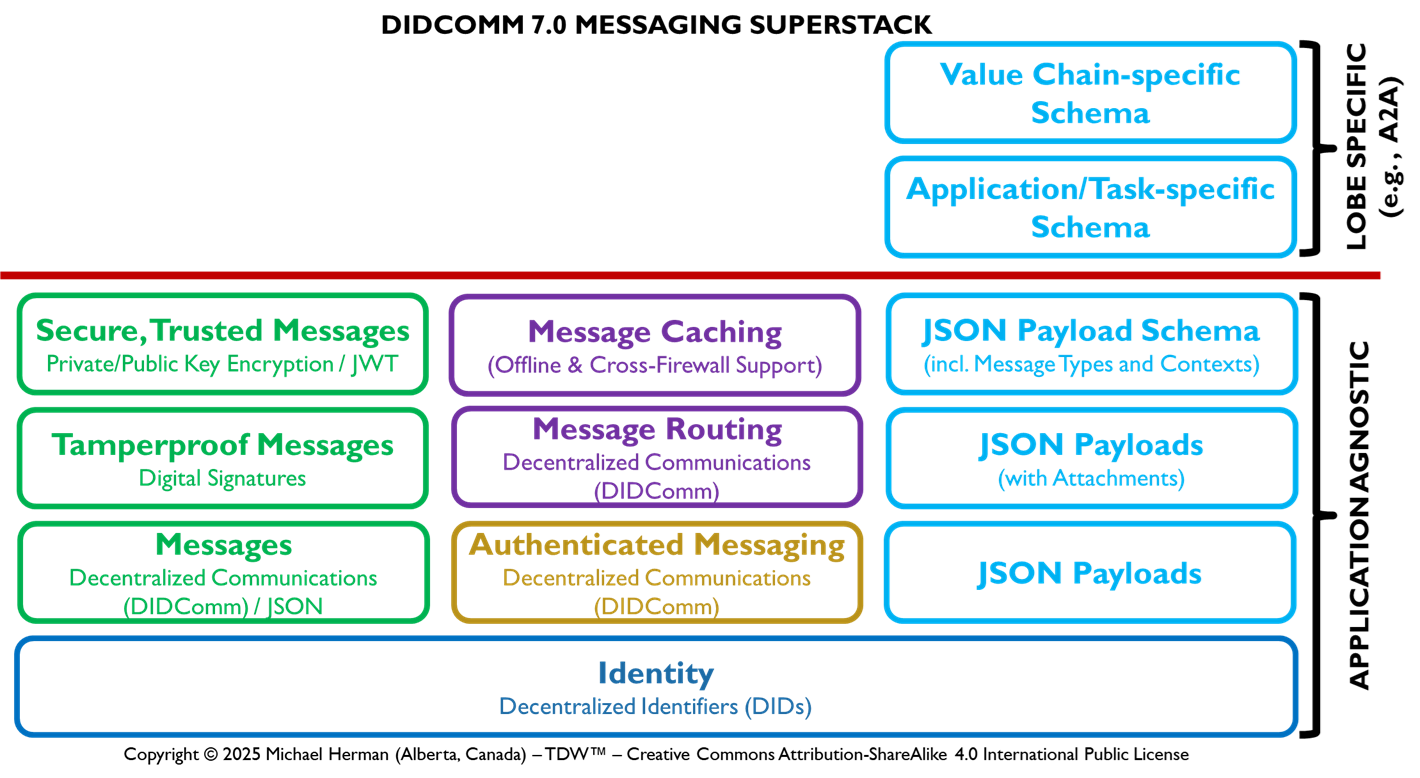
DIDComm 7.0 Superstack
Figure 6b. DIDComm 7.0 Messaging Superstack
Figure 6b illustrates the interdependencies of the multiple layers within the DIDComm 7.0 Superstack.
Technology Wheel of Reincarnation: Win32 generic.c
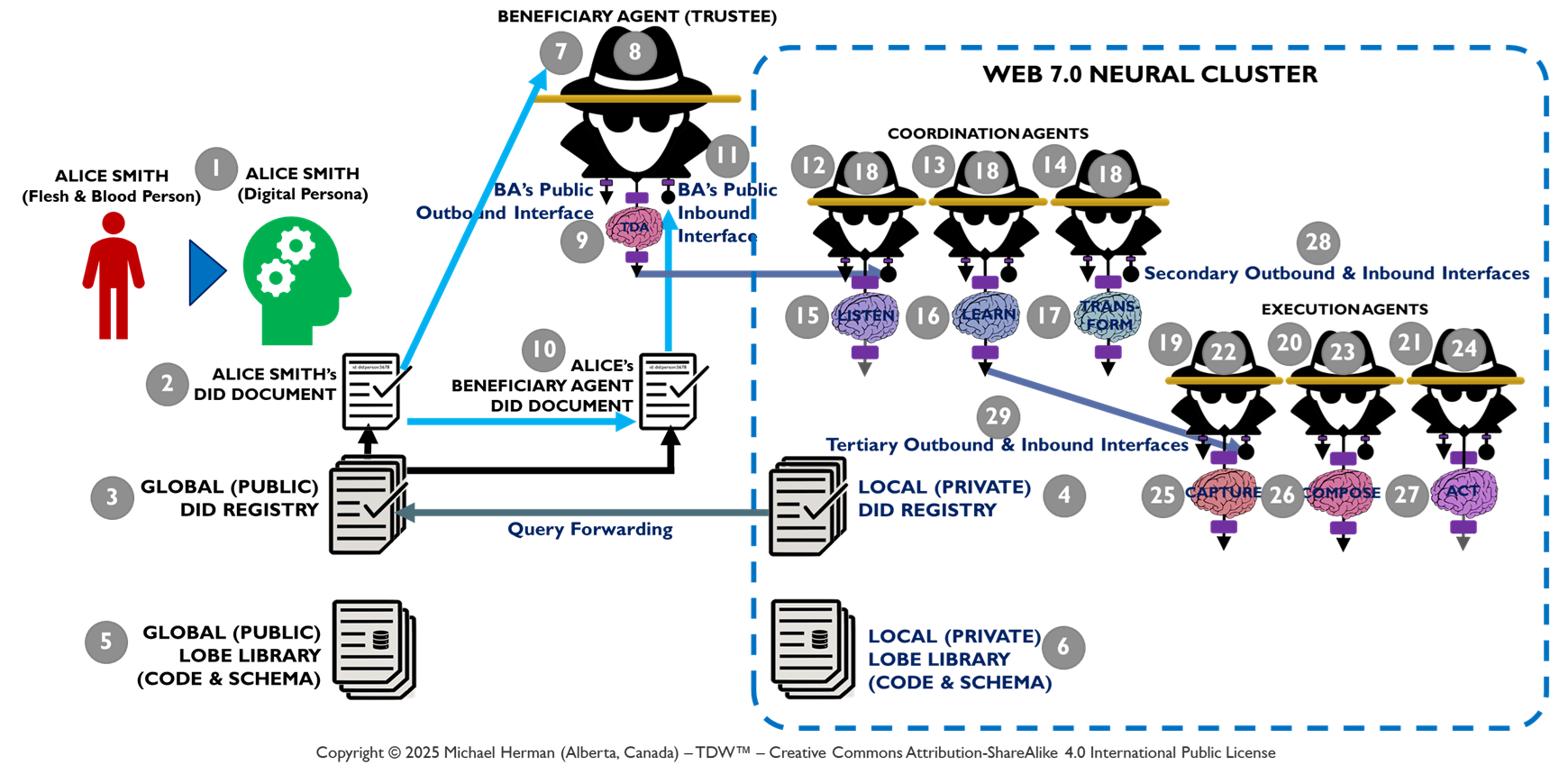
Figure 7. Web 7.0 Neuromorphic Agent Identity Model (NAIM)
The NAIM seeks to enumerate and identify all of the elements in the AARM that have or will need an identity (DID and DID Document). This is illustrated in Figure 7.
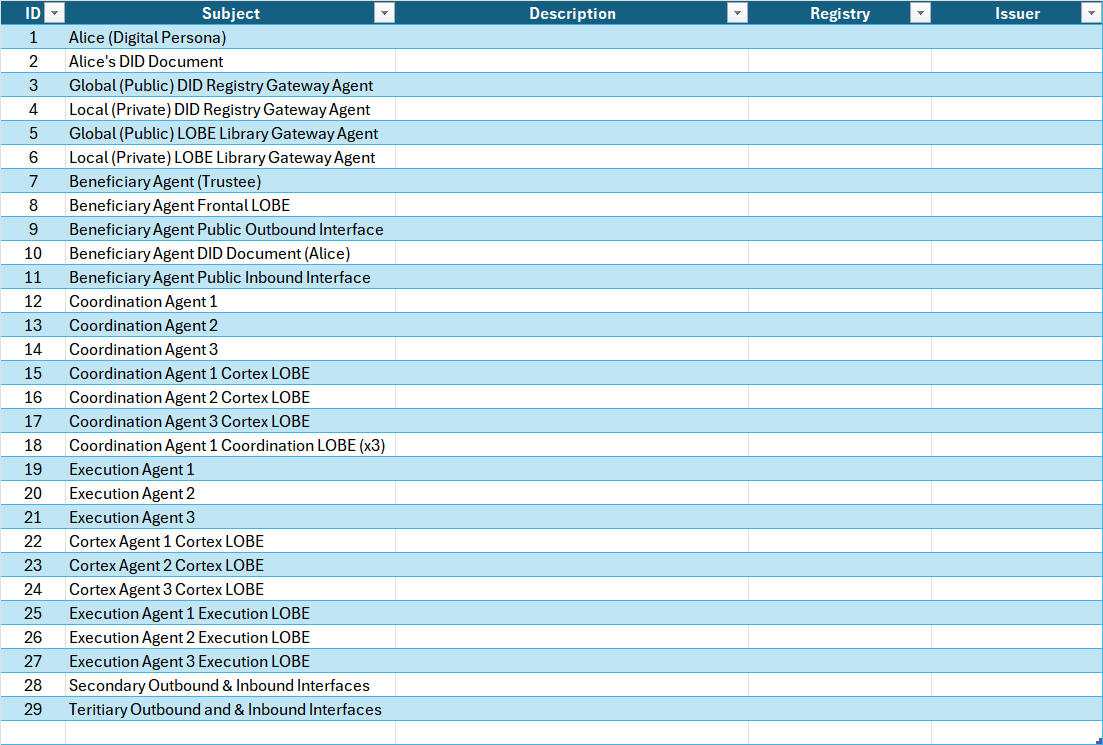
Table 1. Web 7.0 Neuromorphic Agent Identity Model (NAIM) Chart
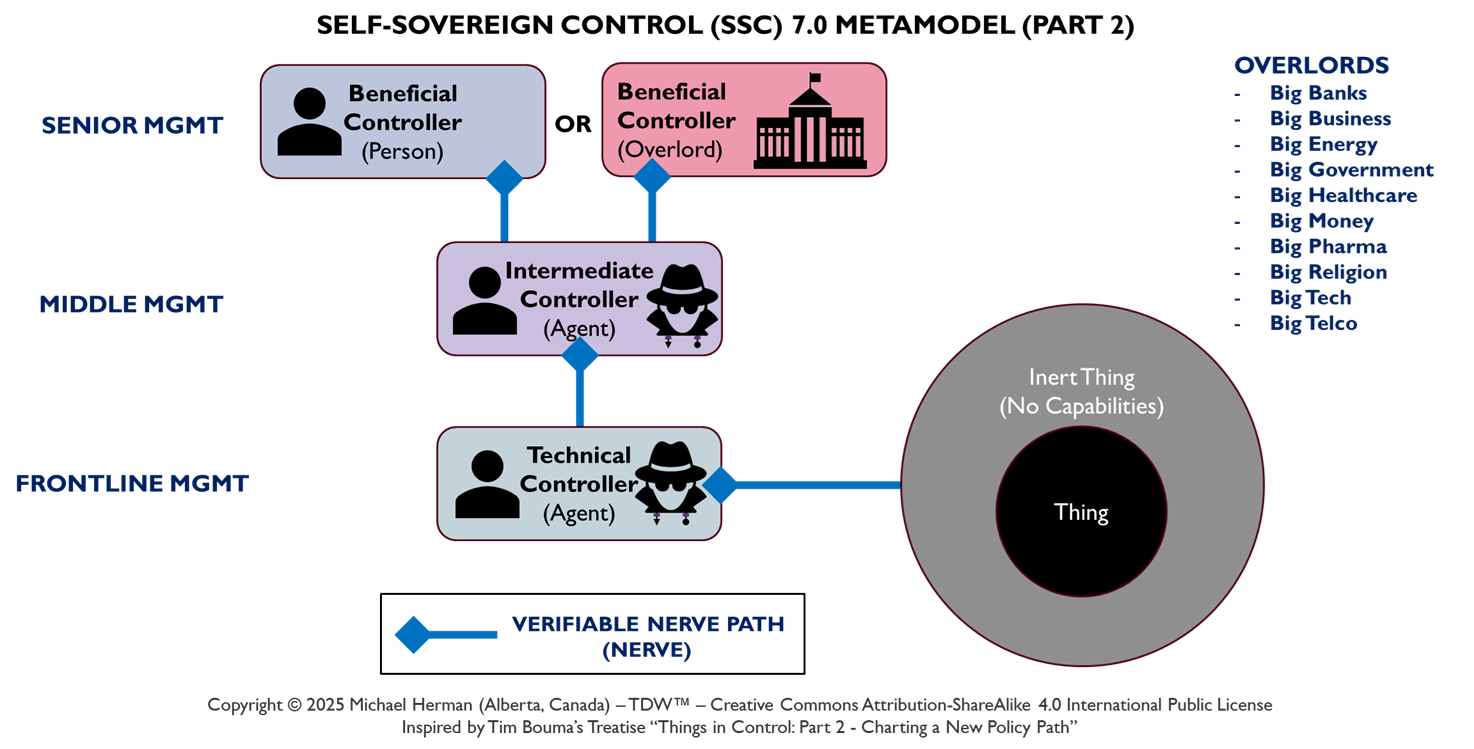
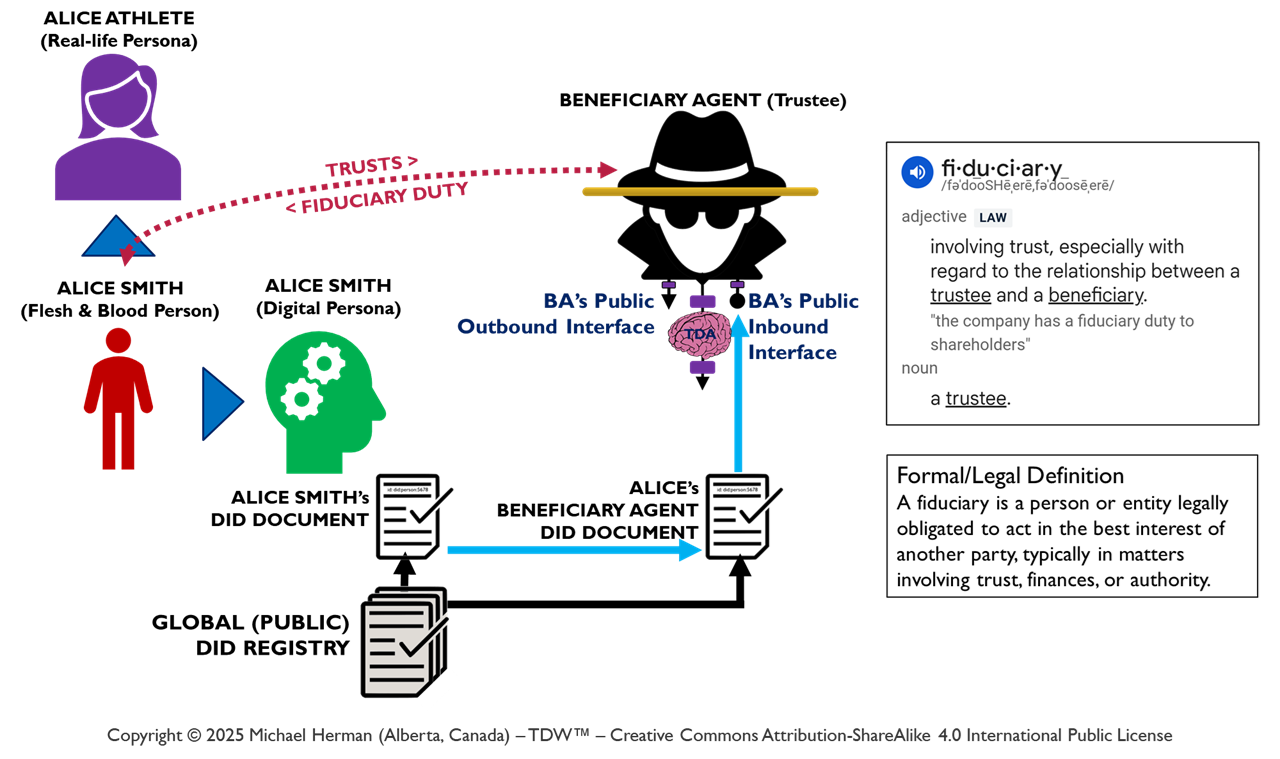
Beneficiaries, Trustees, and Fiduciary Duty
Figure 8. Beneficiaries, Trustees, and Fiduciary Duty
Figure 8 highlights in red the trusts and fiduciary duty relationships between (a) a Beneficiary (Alice, the person) and (b) her Beneificiary Agent (a trustee). Similarly, any pair of agents can also have pair-wise trusts and fiduciary duty relationships where one agent serves in the role of Beneficiary and the second agent, the role of Trustee.
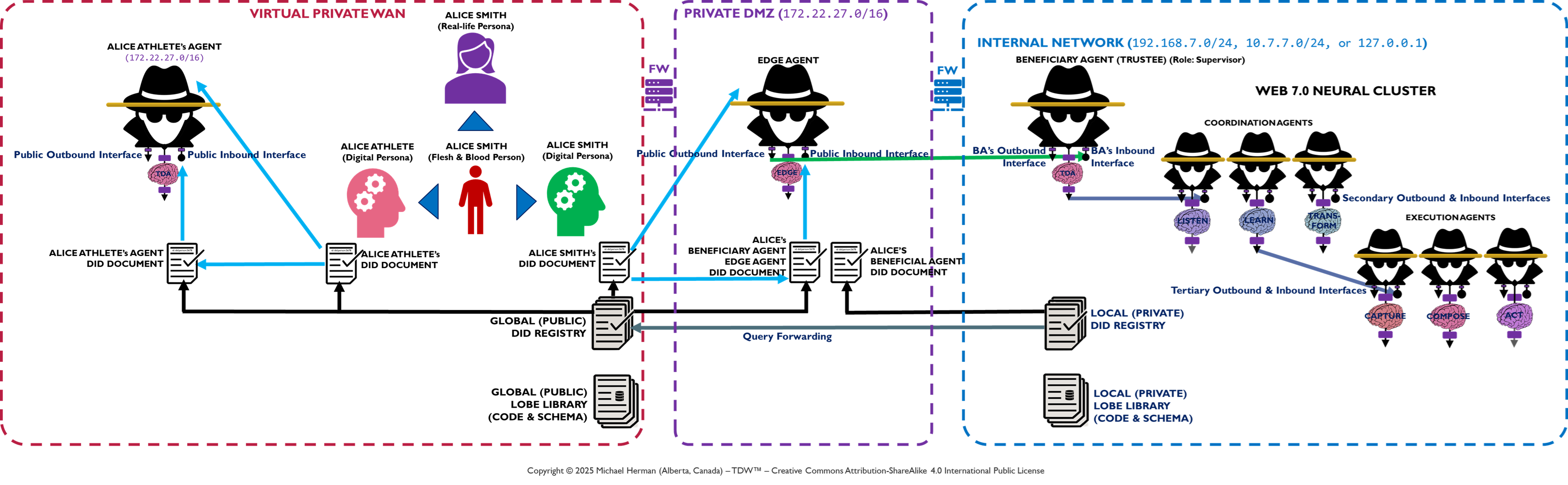
Appendix A – Web 7.0 Pando: Edge Agent DMZ Deployment
This section is non-normative.
Figure A-1. Web 7.0 Pando: Edge Agent DMZ Deployment
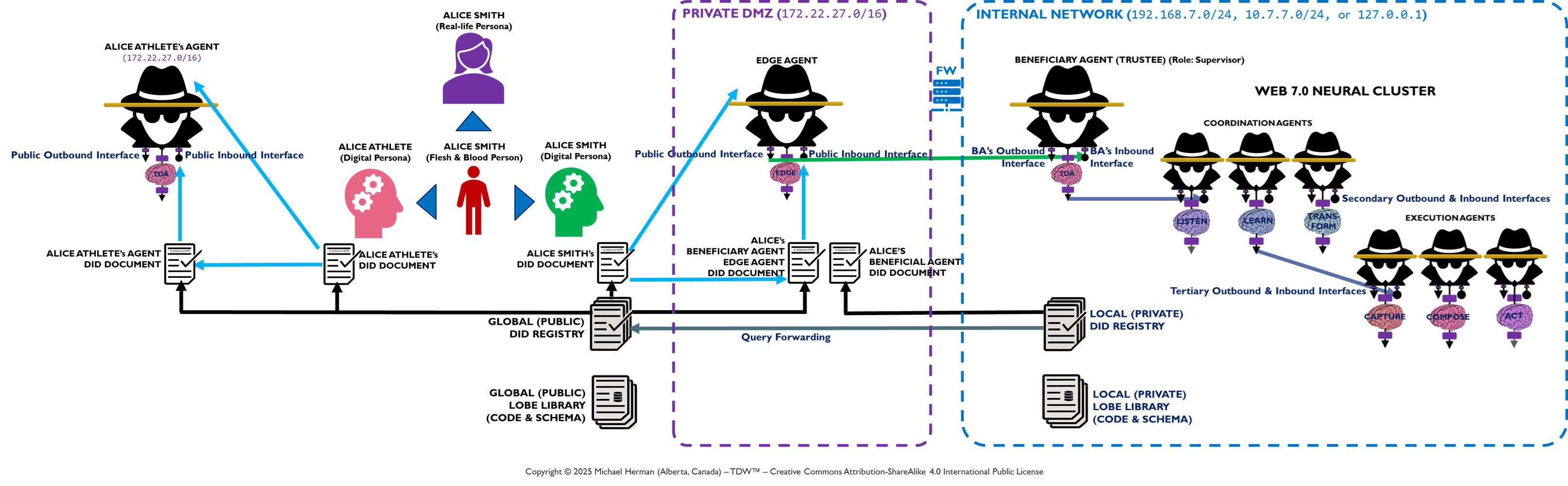
Appendix B – Web 7.0 Pando: Multiple Digital Persona Deployment
This section is non-normative.
Figure B-1. Web 7.0 Pando: Multiple Digital Persona Deployment
Alice has 2 digital personifications: Alice Smith and Alice Athlete. Each of these personifications has its own digital ID. Each of Alice’s personas also has its own Trusted Digital Assistant (TDA) – an agent or agentic neural network.
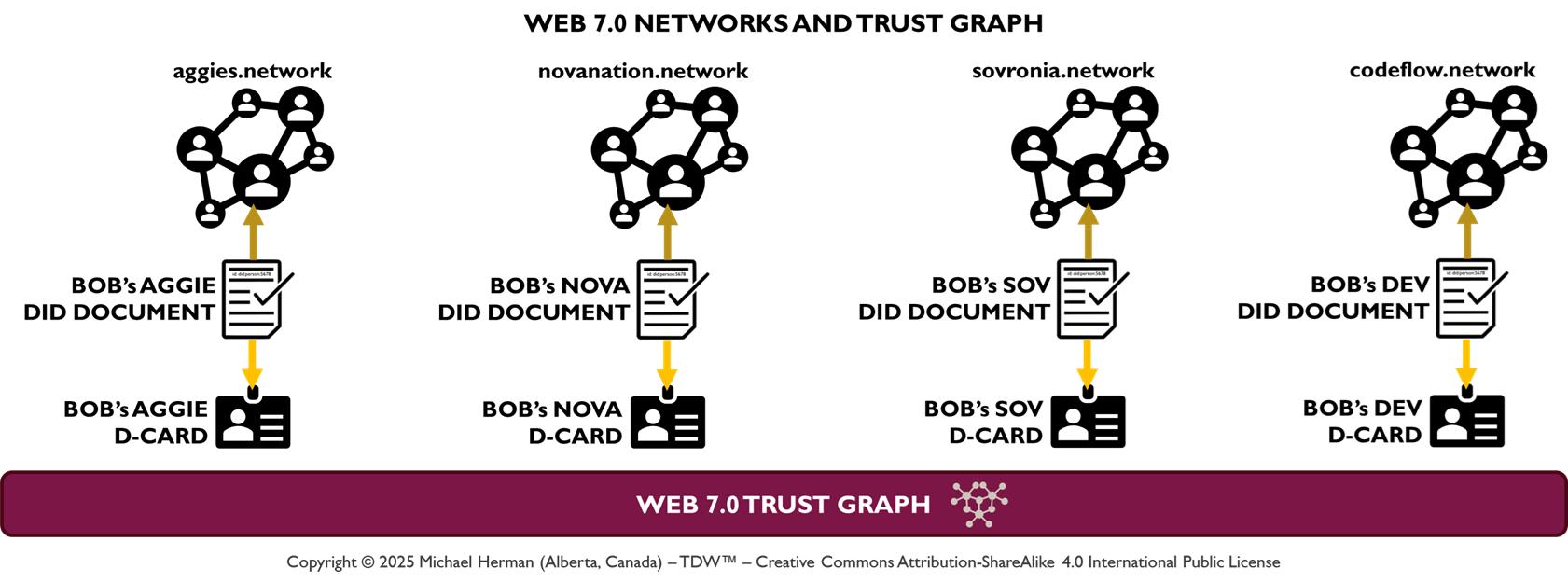
Figure B-2. Web 7.0 Networks and Trust Graph
Bob has (at least) 4 digital personifications: Bob Aggie, Bob Nova, Bob Sovronia, and Bob Developer. Using Web 7.0 Trust Graph Relationships and Verifiable Trust Credentials (VTCs), Bob can also have personas that are members of multiple Web 7.0 networks.
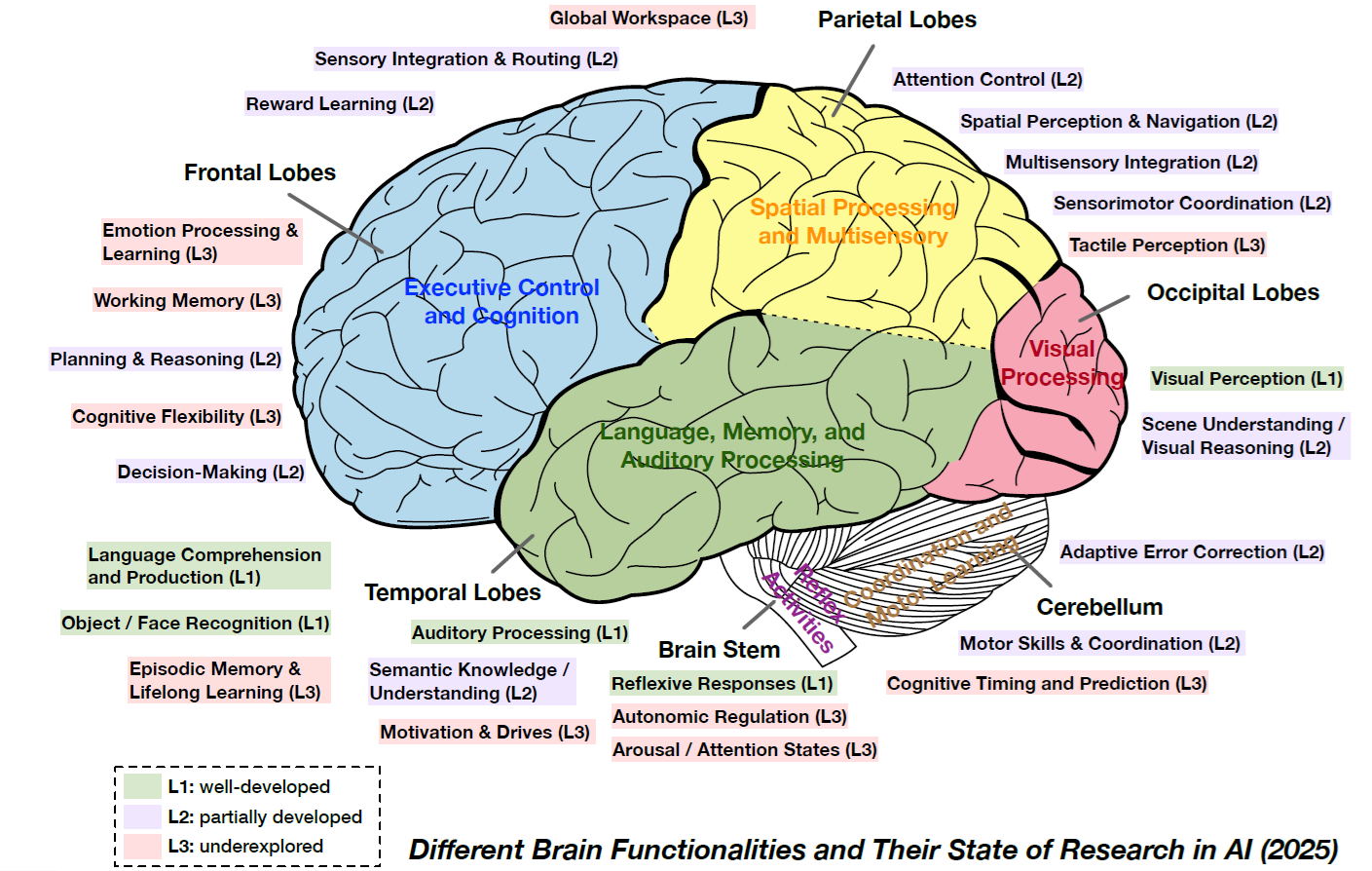
Appendix C – Different Brain Functionalities and Their State of Research in AI (2025)
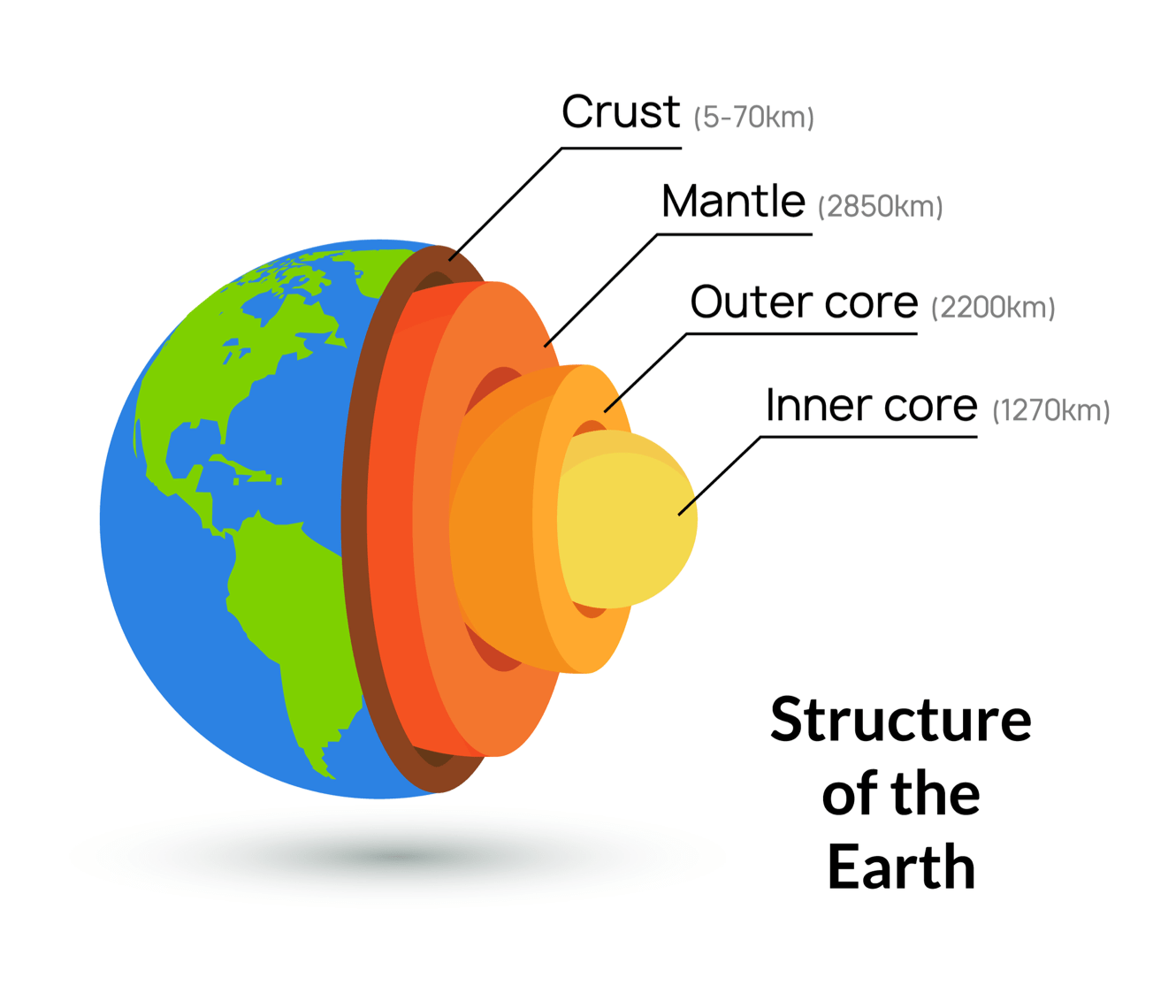
Figure C-1. Different Brain Functionalities and Their State of Research in AI (2025)
Source: Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems. arXiv:2504.01990v2 [https://arxiv.org/abs/2504.01990v2]. August 2025.
In Figure C-3, the Trust Library forms the Inner core and the UX LOBEs, the Crust. The Outer core is comprised of the Fast Cache and Long-Term Memory LOBEs, Neural and Basal Pathways, DID Registry, and LOBE Library. The Mantle is where the Coordination and Execution LOBEs execute.
Appendix D – PWC Multi-Agent Customer Support Use Case
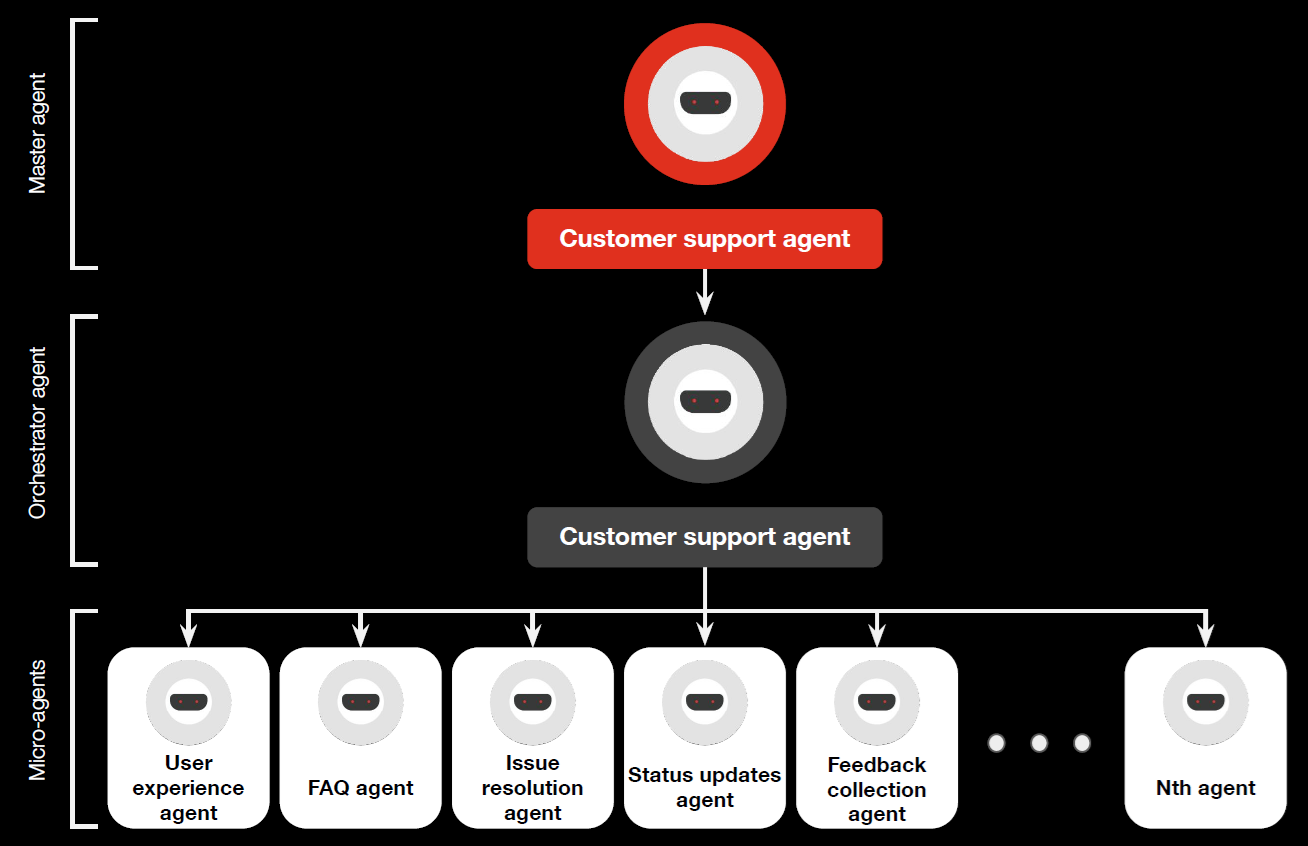
Figure D-1. PWC Multi-Agent Customer Support Use Case
Source: Agentic AI – the new frontier in GenAI. PWC Middle East. 2024.
This use case exemplifies the use of the Web 7.0 Neural Cluster model. Table D-1 maps the PWC Use Case terminology to the corresponding Web 7.0 AARM terminology.
Web 7.0 NAARM
PWC Use Case
Beneficiary Agent
Master agent
Coordination Agent (and LOBEs)
Orchestrator agent
Execution Agent LOBEs
Micro-agents
Table D-1. Web 7.0 AARM – PWC Use Case Terminology Cross-Reference
The steel shipping container transformed global trade by introducing a standardized, secure, and interoperable abstraction for transporting goods. Similarly, Decentralized Identifier Communication (DIDComm) offers a standardized, secure, and interoperable mechanism for transmitting trusted digital information between agents. This paper explores the analogy between DIDComm messages and steel containers, examining their properties, benefits, and limitations, and assessing the potential of DIDComm to catalyze a transformation in digital ecosystems comparable to the shipping container revolution.
The 20th century witnessed a quiet revolution in global trade: the invention and adoption of the steel shipping container. More than faster ships or larger ports, it was standardization in how goods were packaged and transported that unlocked efficiency, scale, and global interoperability.
In the 21st century, digital ecosystems face a parallel challenge. Secure communication across heterogeneous systems remains fragmented by proprietary protocols, siloed trust frameworks, and inconsistent interoperability. Despite advances in transport protocols (HTTP, WebSocket, Bluetooth) and security primitives (TLS, OAuth, JWT), no universal standard exists for trusted, end-to-end, cross-domain messaging.
DIDComm (Decentralized Identifier Communication) aims to fill this gap. It provides a standardized envelope for secure, interoperable communication between agents in decentralized ecosystems. This paper argues that DIDComm can be understood as the steel shipping container of digital communication — a payload-agnostic, transport-agnostic, secure packaging standard that enables trust to move seamlessly across networks and domains.
Stackability: efficient storage and loading by crane.
Interoperability: ships, ports, trucks, and trains adapted to a single form factor.
Impact: Containerization reduced costs by ~90% and increased the speed and scale of global trade [Levinson, The Box, 2006]. The key insight: decouple contents from infrastructure via a universal abstraction.
3. DIDComm: A Digital Container Standard
3.1 What is DIDComm?
DIDComm is a protocol suite for secure, private, and interoperable communication using Decentralized Identifiers (DIDs) as endpoints. It defines how messages are packaged, encrypted, authenticated, and routed between agents.
Transport agnosticism: works over HTTP, Bluetooth, WebRTC, email, etc.
Routing via mediators: messages can traverse multiple relays without breaking end-to-end security.
Payload agnosticism: the message may carry verifiable credentials, IoT commands, or arbitrary application data.
3.3 Why It Matters
Just as containers enabled intermodal trade, DIDComm enables intermodal trust exchange. Applications, wallets, devices, and services can interoperate without bespoke integrations.
4. Mapping the Analogy: Containers vs. DIDComm
Container Property
DIDComm Equivalent
Implications
Standardized form
Envelope with defined structure (headers, body, metadata)
Guarantees interoperability across agents and vendors
Sealed & secure
Encryption + authentication
Protects against unauthorized access and tampering
Intermodal transport
Transport-agnostic delivery
Works across protocols without altering the payload
Routing via logistics
Mediators, DID resolution, forwarding
Enables flexible message delivery
Opaque contents
Encrypted payload
Only authorized parties can inspect
Global ecosystem support
Agent networks, wallets, identity hubs
Emerging infrastructure could mirror global ports and carriers
5. Benefits of the Container Analogy
Interoperability
Any DIDComm-compliant agent can process a message, just as any port can handle a container.
Security and Trust
Messages are sealed like containers, with tamper-evident cryptography.
Efficiency
Reduces the cost and complexity of building integrations across organizations.
Scalability
Supports any type of payload: credentials, IoT signals, governance instructions.
Decentralization
No reliance on a central authority; trust derives from cryptographic keys, similar to how container standards are managed by ISO, not controlled by one nation or corporation.
6. Limits of the Analogy
Physical persistence vs. digital ephemerality: Containers endure across voyages; messages vanish after delivery.
Metadata leakage: Container labels are visible; DIDComm may still expose sender/recipient metadata.
Standard stability: Container sizes have been stable for decades; DIDComm may evolve quickly.
Global adoption: Containerization achieved near-universal acceptance; DIDComm is still early in adoption.
7. Strategic Implications
7.1 Identity & Credentials
DIDComm provides a secure transport for verifiable credentials, enabling cross-border, cross-domain trust.
7.2 IoT Ecosystems
IoT devices require lightweight, trustable communication. DIDComm offers a containerized way to exchange secure commands.
7.3 Cross-Domain Interoperability
Applications in finance, healthcare, supply chains, and governance can exchange trusted data without bespoke APIs.
7.4 The “Container Moment”
Global trade was reshaped once container standards reached critical mass. DIDComm could catalyze a parallel moment in digital ecosystems if widely adopted.
8. Conclusion
The steel shipping container revolutionized trade by abstracting the packaging and transport of goods into a universal, secure standard. DIDComm has the potential to do the same for digital trust, abstracting communication into a universal, secure, and interoperable form.
If DIDComm achieves broad adoption, it could serve as the logistics backbone of the digital trust economy, enabling decentralized ecosystems to scale with the efficiency and security once brought to global commerce by steel containers.
References
Levinson, Marc. The Box: How the Shipping Container Made the World Smaller and the World Economy Bigger. Princeton University Press, 2006.
#Chickens, #Eggs, and #Roosters: A #NorthStar for the Global Decentralized Systems Community (#GDSC)
Byline: #meggDLs, #Seleggtive#Disclosure, #DEGGCOMM, and #Eggports
The entire digital identity ecosystem is missing out on the #BigOpportunity by not focusing on the right catalyst for the #massiveadoption of #digitalcredentials. Morphing the chicken and egg mental model: If Hens are the Issuers, Roosters the Verifiers, and Eggs are the digital credentials, the prime objective needs to be increasing the demand for and consumption of Eggs by Holders …creating hundreds of thousands of ways that drive more Holders to consume more Eggs. Think about it.
… are great examples of driving the demand for and consumption of more and more digital credentials [and DIDs] (eggs); and secondarily, the demand for hens and roosters (Issuers and Verifiers). The demand for eggs drives the production of hens; and in turn, the demand for roosters. Don’t mess with #MotherNature
Decentralized identifiers (DIDs) are a new type of identifier that enables verifiable, decentralized digital identity. A DID refers to any subject (e.g., a person, organization, thing, data model, abstract entity, etc.) as determined by the controller of the DID. In contrast to typical, federated identifiers, DIDs have been designed so that they may be decoupled from centralized registries, identity providers, and certificate authorities.
DID subject The entity identified by a DID and described by a DID document. Anything can be a DID subject: person, group, organization, physical thing, digital thing, logical thing, etc.
2. Use Cases and Requirements for Decentralized Identifiers Document
Web 7.0/TDW DID Method Clusters Model Taxonomy 0.1
A bold method is the model method or exemplar for the particular cluster (cell).
A method can be a exemplar for 1 or many clusters.
This list of DID method categories is just an example. A complete taxonomy will likely be a 2-3 level hierarchy. The parent categories for these examples might include: Live Things, Inanimate Things, Abstract Things, Digital Things, Business Things, etc. etc.
In Sociocracy terminology, a mini-WG is called a circle. Each category of DID methods (cluster of DID Methods) would be managed by its own independent circle. A circle member can belong to more than 1 circle. Circles are connected to a parent circle for administrative purposes. The parent circle would correspond to the DID Method WG (co-chaired by Markus).
Sociocracy combines consent decision-making, a decentralized system of authority and intentional processes to improve our decisions and processes over time into a governance system that supports effective and efficient process while increasing connection, listening and co-creation among members.
Sociocracy is used in businesses, communities, nonprofits, cooperatives, grassroots groups and in education.
13. Trusted Digital Web (TDW) Glossary/Taxonomy Model: Erin Buys a Car Neighborhood
[Original Title: Technology Adoption Models: A Comprehensive Guide]
This article documents more than 20 technology adoption models that the author has encountered over his 45+ year career …some models that he didn’t even realize he knew about ;-). Here they there are, in no particular order.
NOTE: Each model progresses from left-to-right along an unspecified timeline. The implication is that it is possible to superimpose two or more models on top of each other for deeper understanding and for creating more tangible, more illustrative, depictions of your corporate, product, and project strategies.
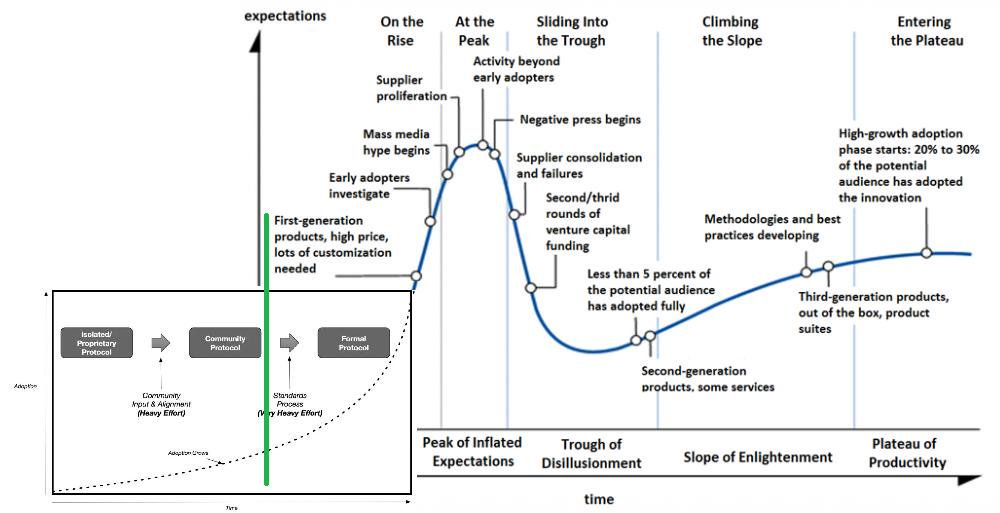
An example is: Model 10. Technology Adoption Lifecycle illuminated by the Gartner Hype Cycle.
Technology Adoption Models
NOTE: Click on any of the figures to enlarge them.
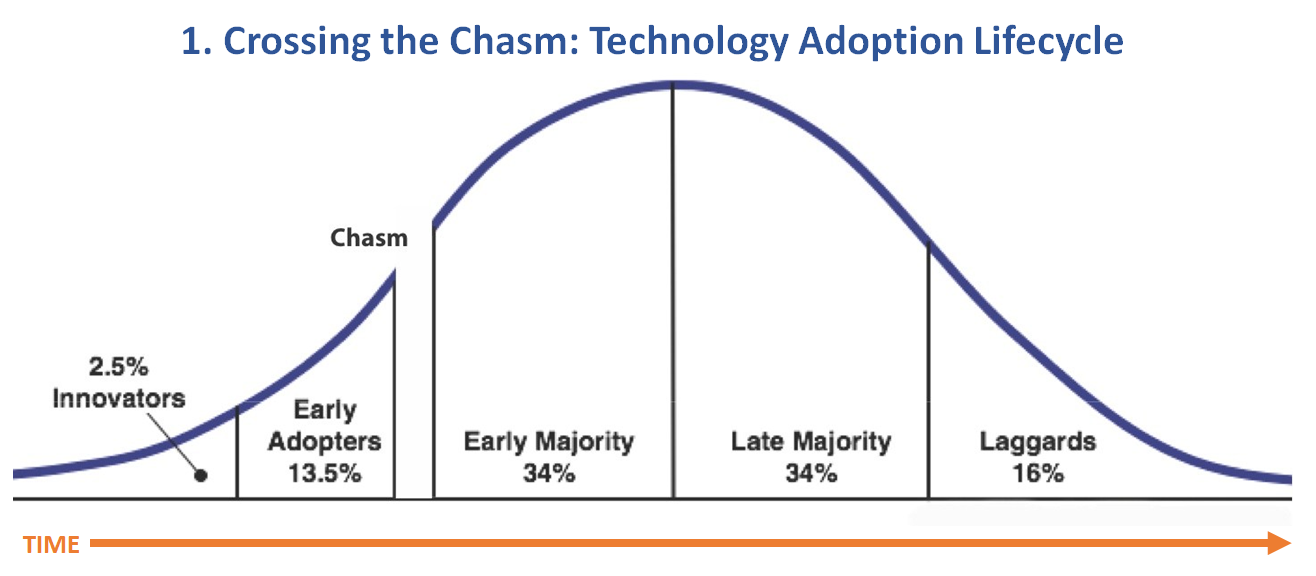
Model 1. Crossing the Chasm: Technology Adoption Lifecycle
Model 2a. Social Evolution: Creation of Nation State
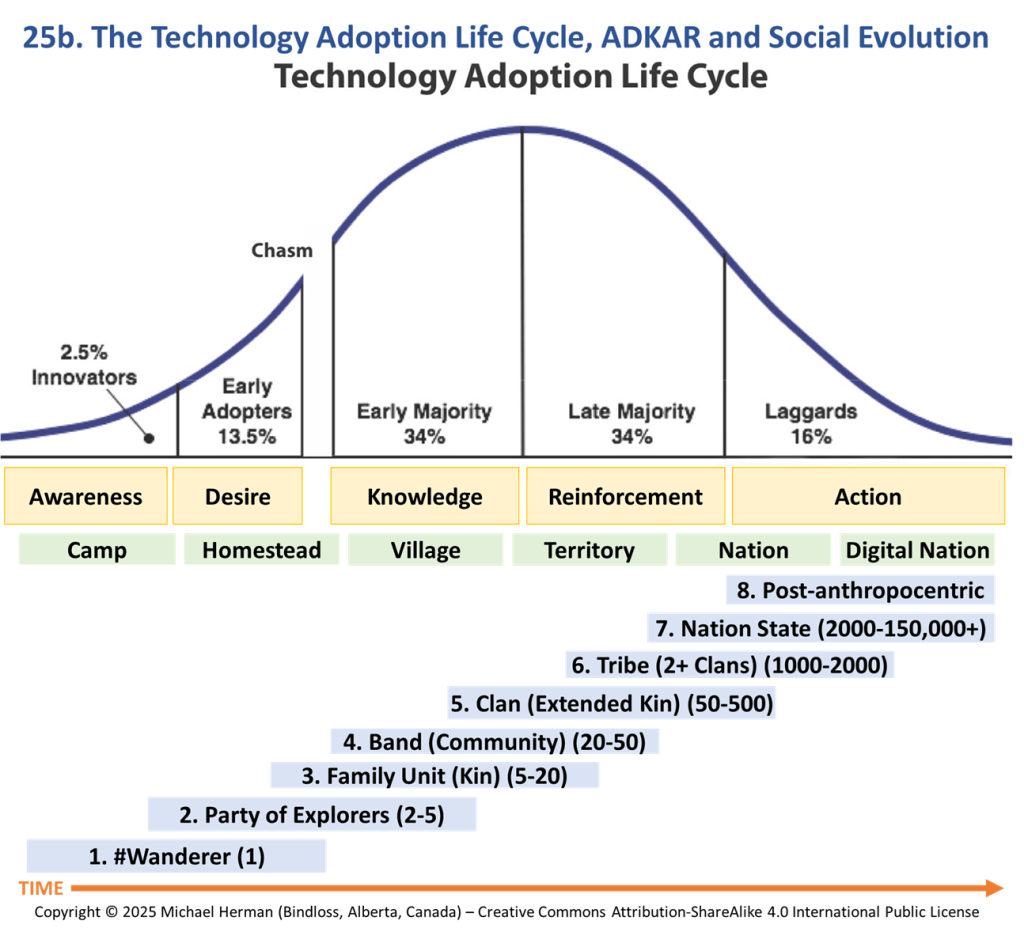
A #wanderer is someone who leaves their tribe to share their knowledge and wisdom with others; to later form a party of explorers to explore and conquer a common set of goals; and, even further on, create a clan, a band, a tribe, and a tribal society, a group of people who live and work together – a group of tribes organized around kinships.
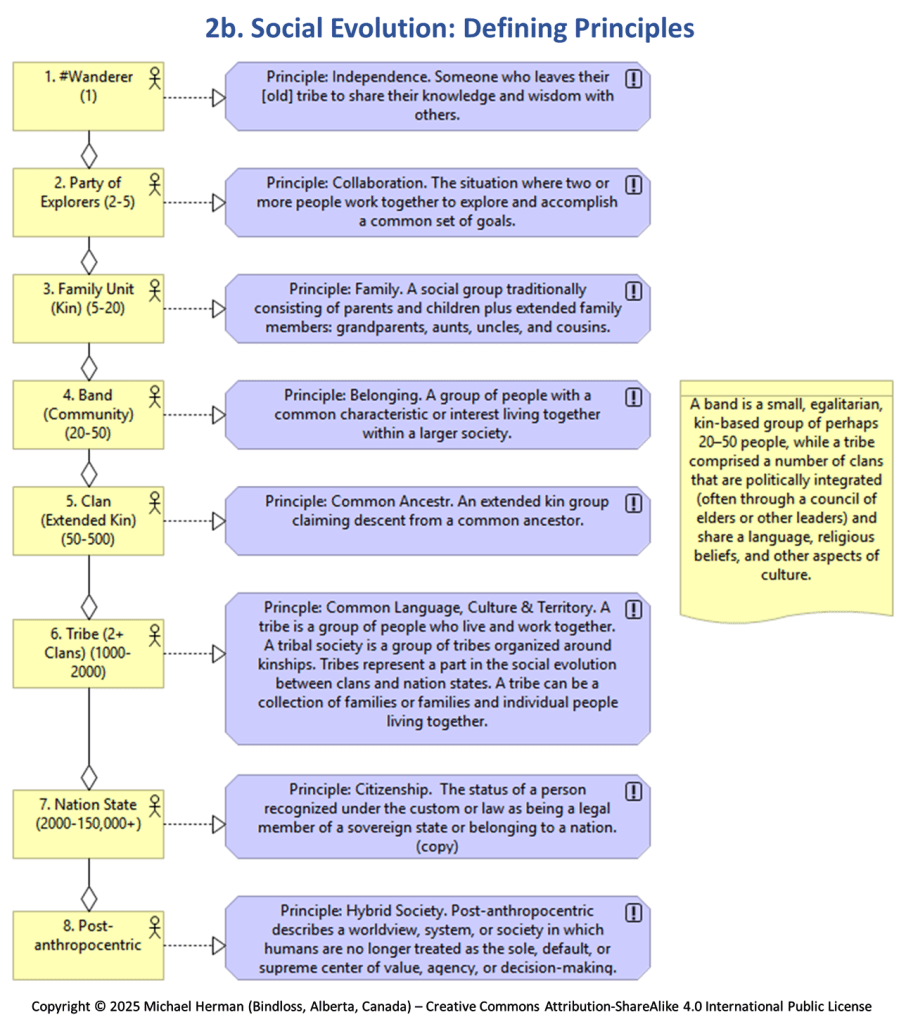
Model 2b. Social Evolution: Defining Principles
A #wanderer is someone who leaves their tribe to share their knowledge and wisdom with others; to later form a party of explorers to explore and conquer a common set of goals; and, even further on, create a clan, a band, a tribe, and a tribal society, a group of people who live and work together – a group of tribes organized around kinships.
Model 2c. Social Evolution: Self-Sovereignty Political Spectrum
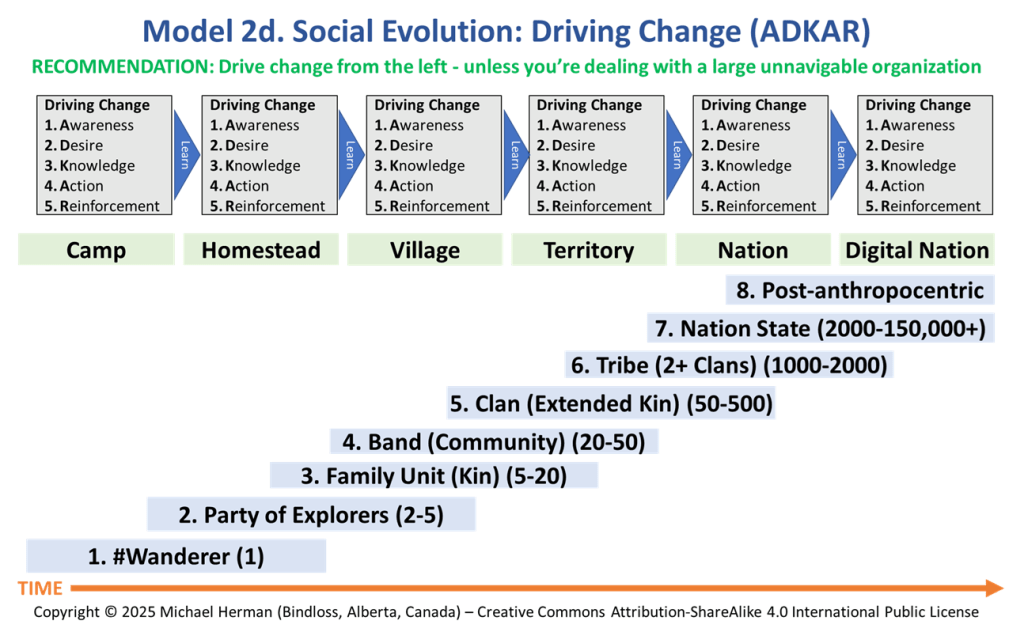
Model 2d. Social Evolution: Driving Change (ADKAR)
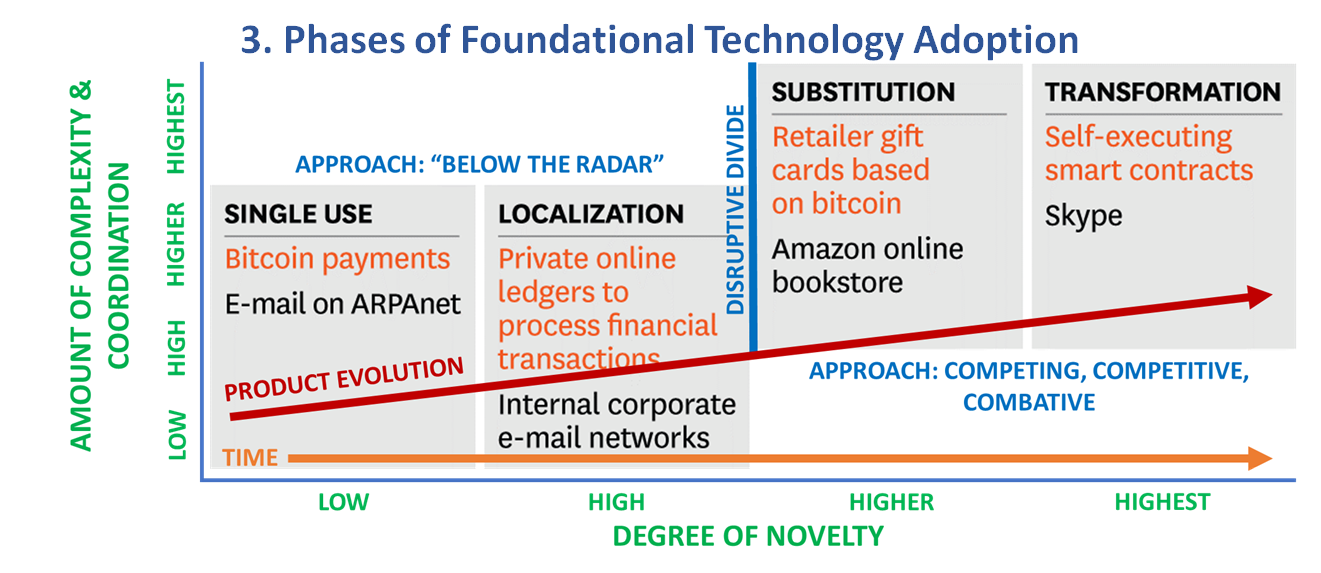
Model 3. Phases of Foundational Technology Adoption
Model 4. Phases of Desire and Action
Model 5. Phases of Understanding
Model 6. Classic Enterprise Solution Sales and Adoption Lifecycle
Model 7. ICRVA (I CRaVe A) Process
Model 8. Three-letter Words
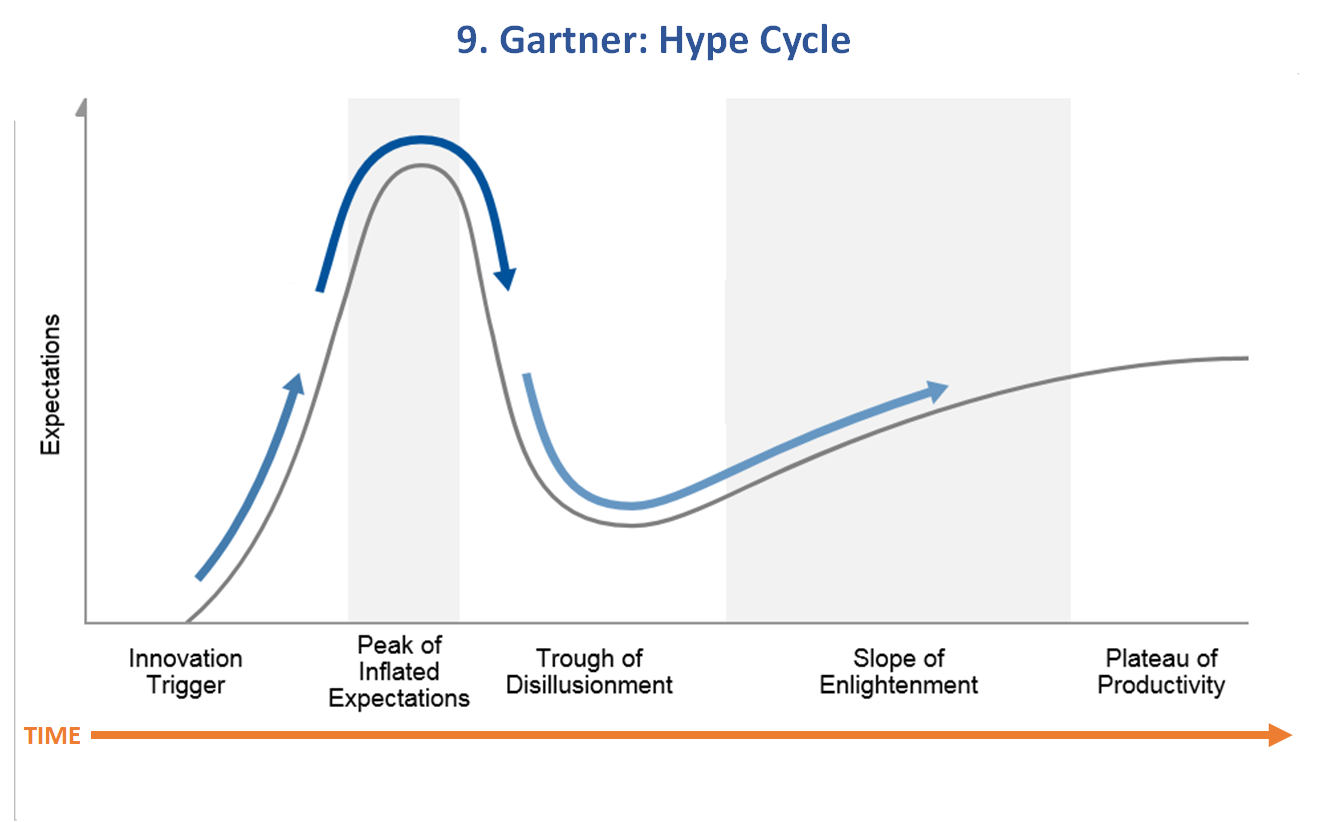
Model 9. Gartner Hype Cycle
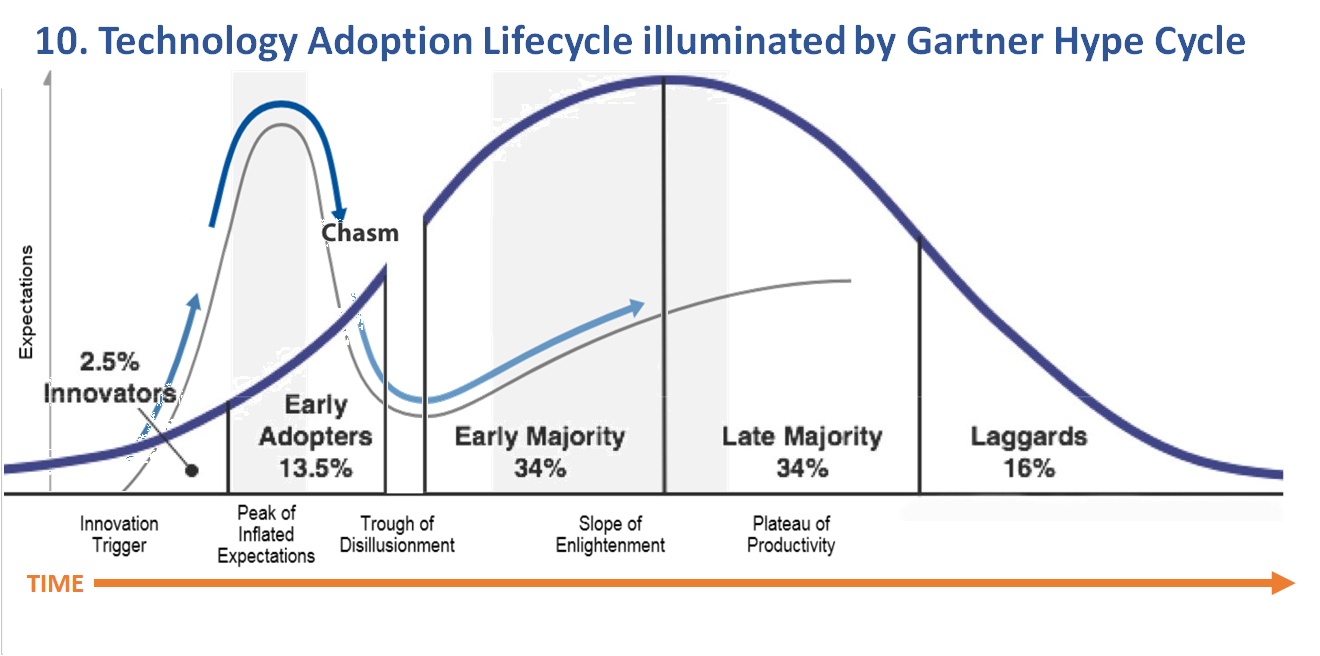
Model 10. Technology Adoption Lifecycle illuminated by the Gartner Hype Cycle
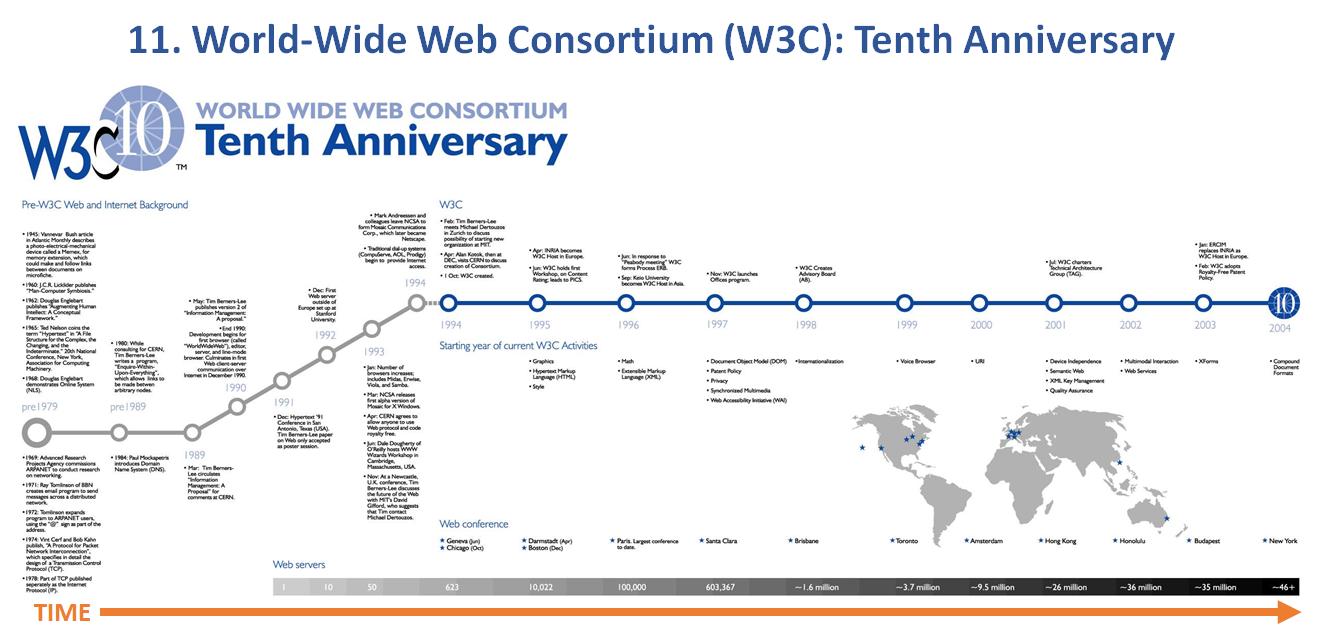
Model 11. World Wide Web Consortium (W3C): Tenth Anniversary
Model 12. Systems Co-existence and Migration
Model 13. Embrace, Extend, and Extinguish
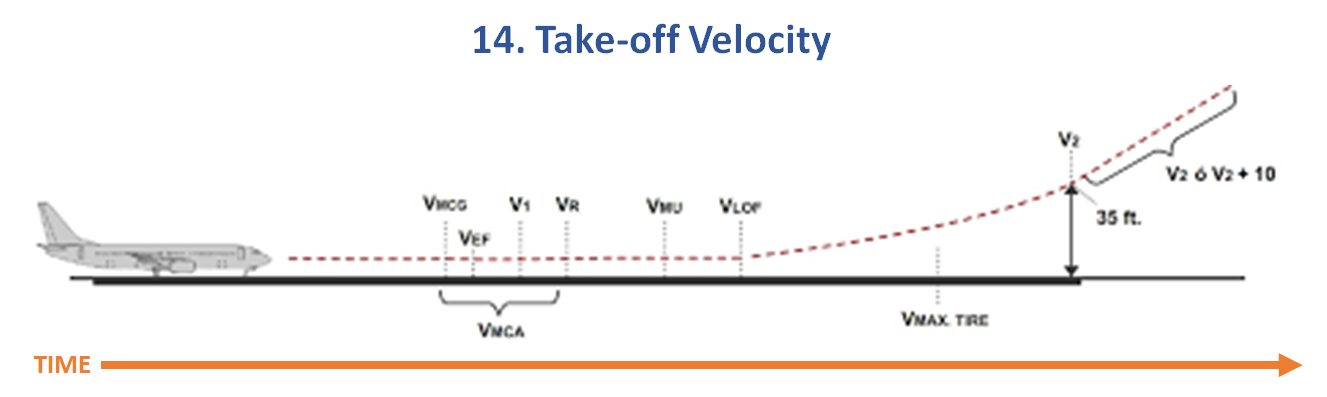
Model 14. Take-off Velocity (v2)
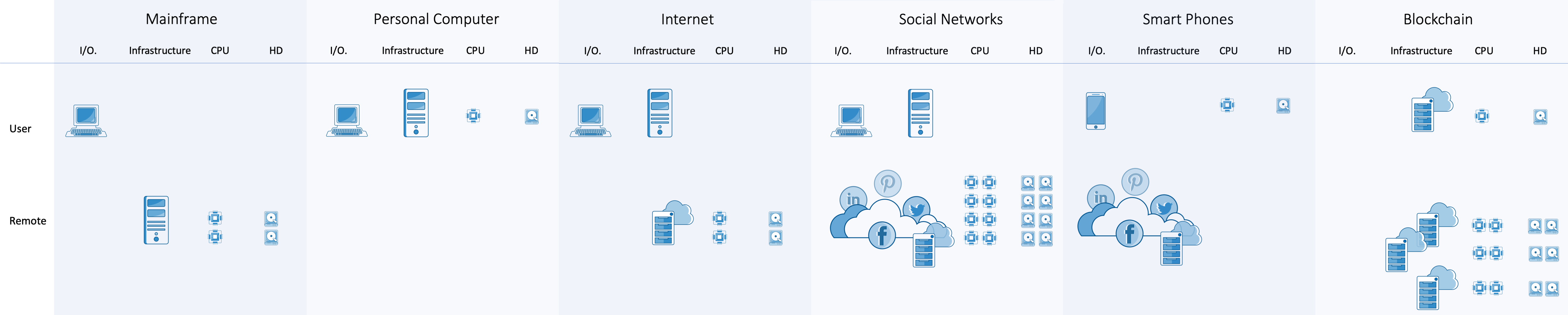
Model 15. From Mainframe to Blockchain
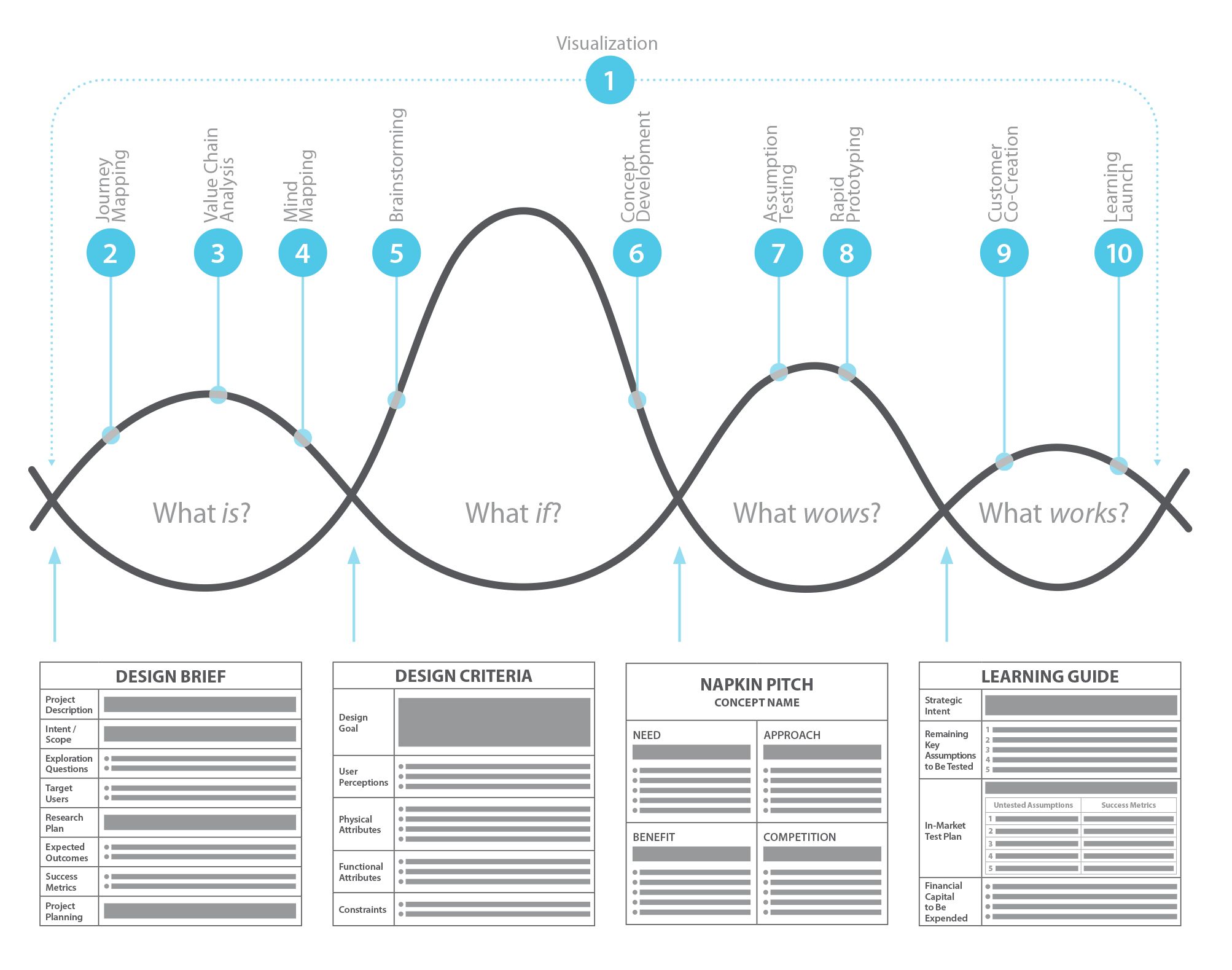
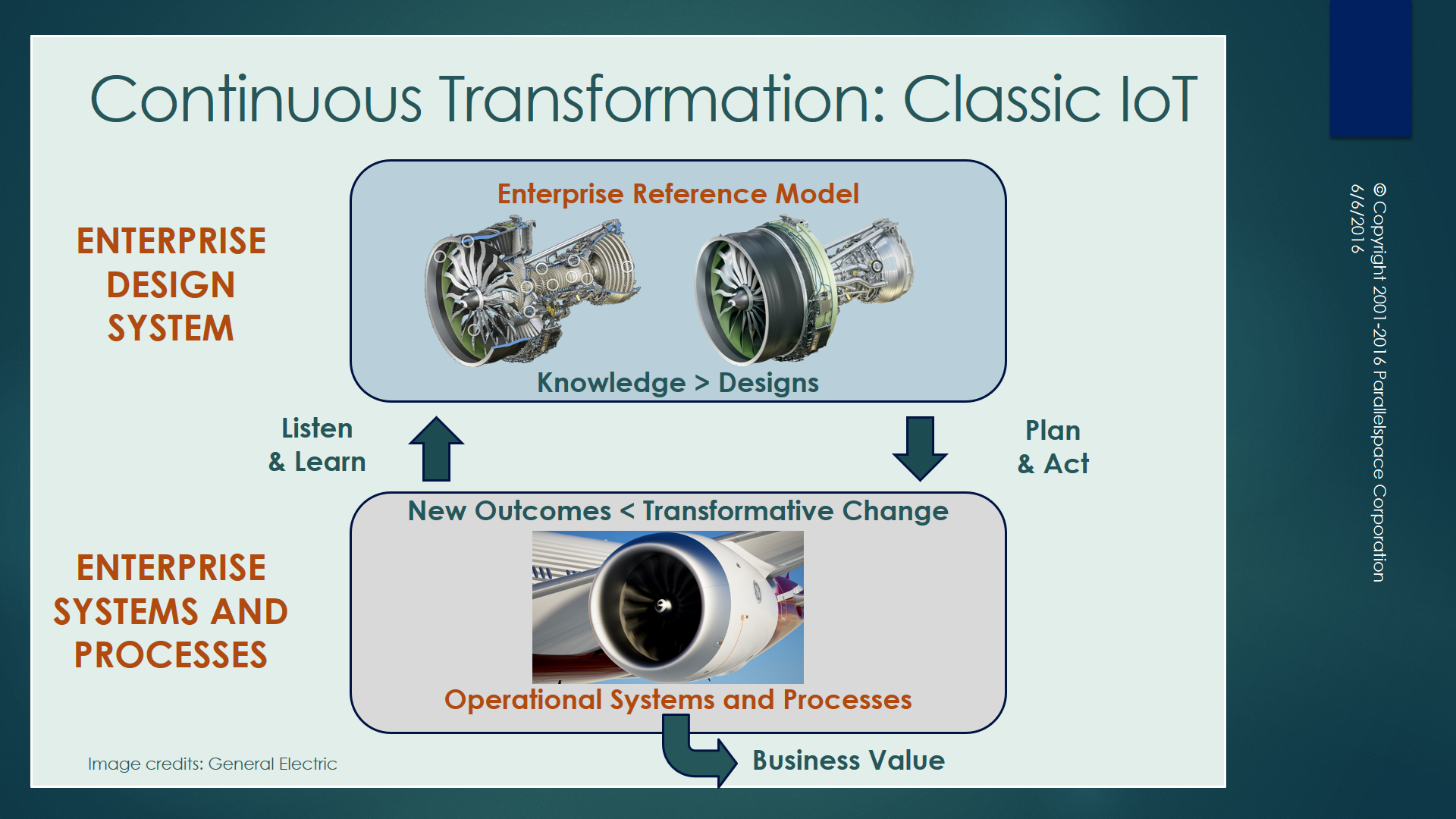
Model 16. Progressive Improvement through Continuous Transformation
Model 17. Liedtka-Ogilvie Design Thinking ModelModel 18. CB-Insights NExTT Framework
Model 19. O’Donnell Exponential Growth Model
Model 20. O’Donnell-Gartner Exponential Hype Cycle
Model 21. Technical Intensity (video)
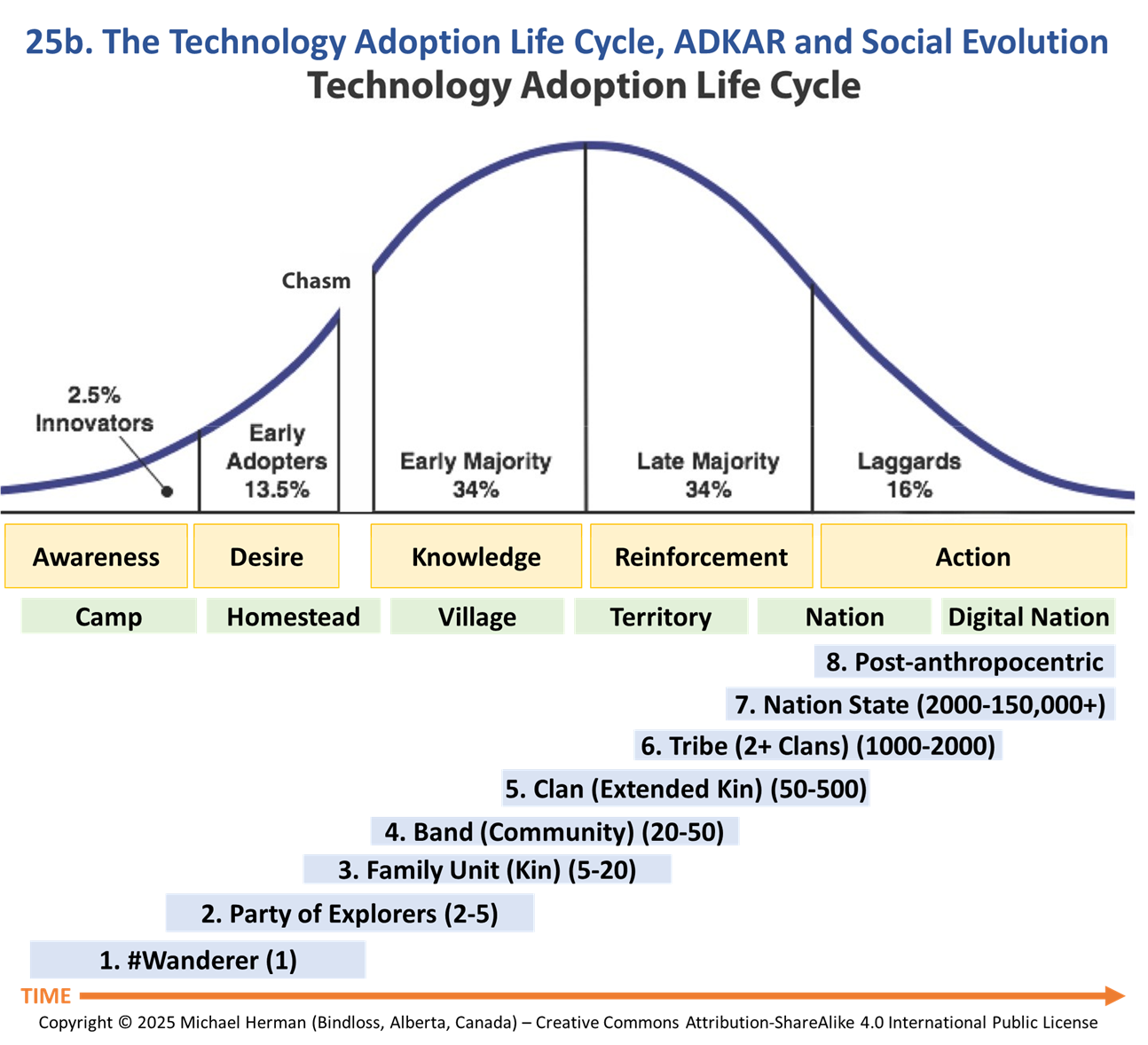
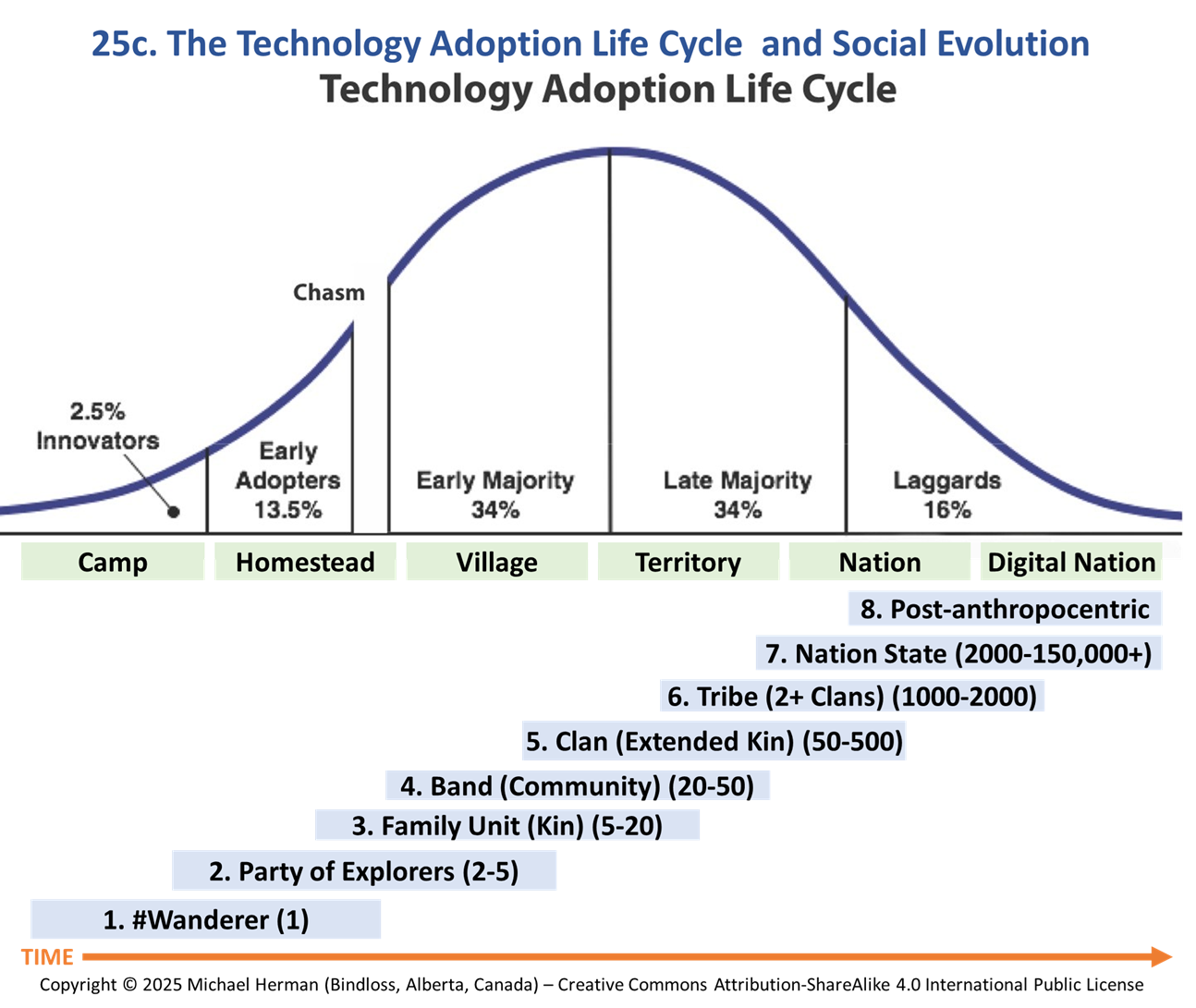
Model 22. Technology Adoption Curve plus Social Evolution Model
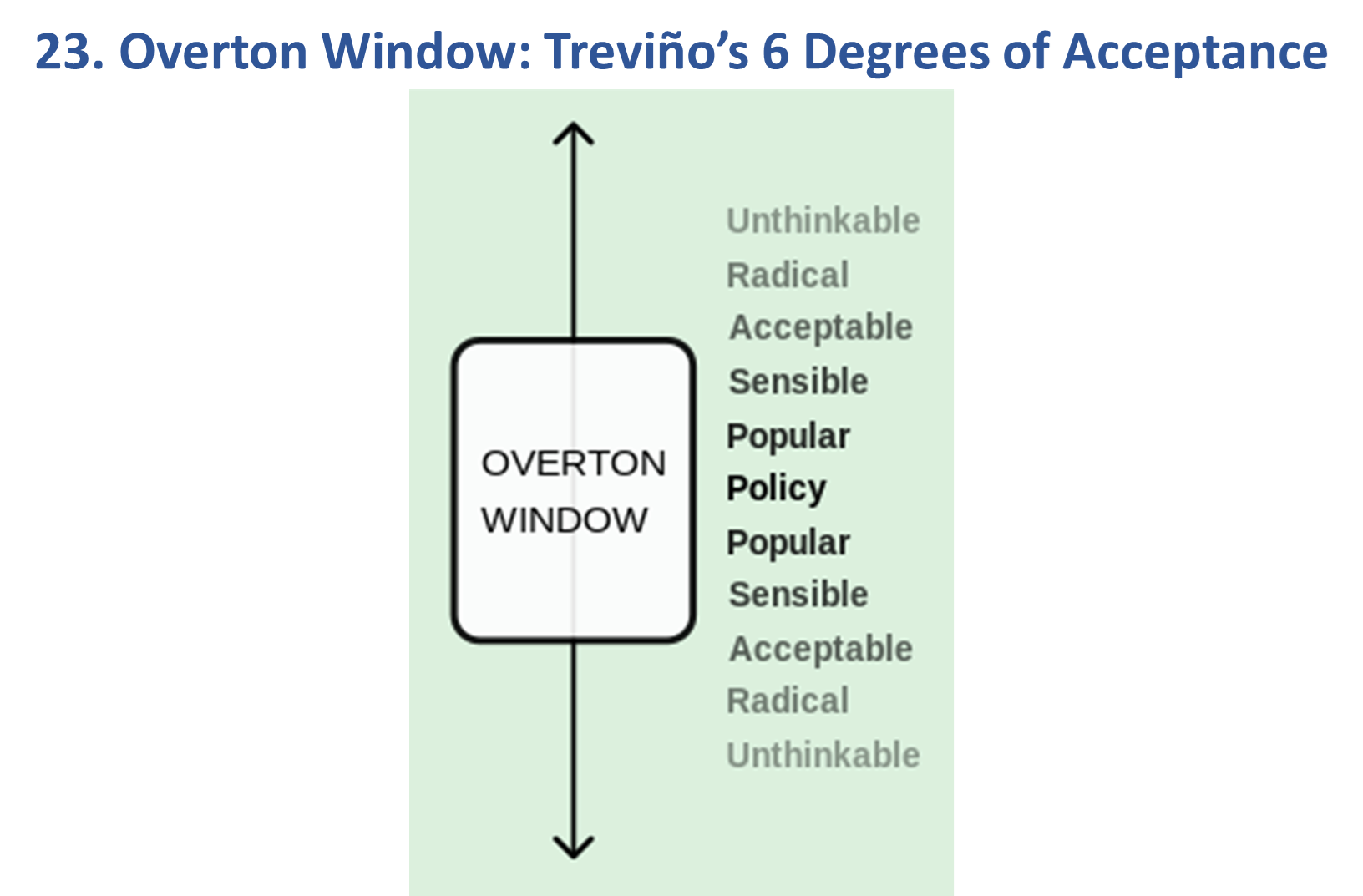
Model 23: Overton Window
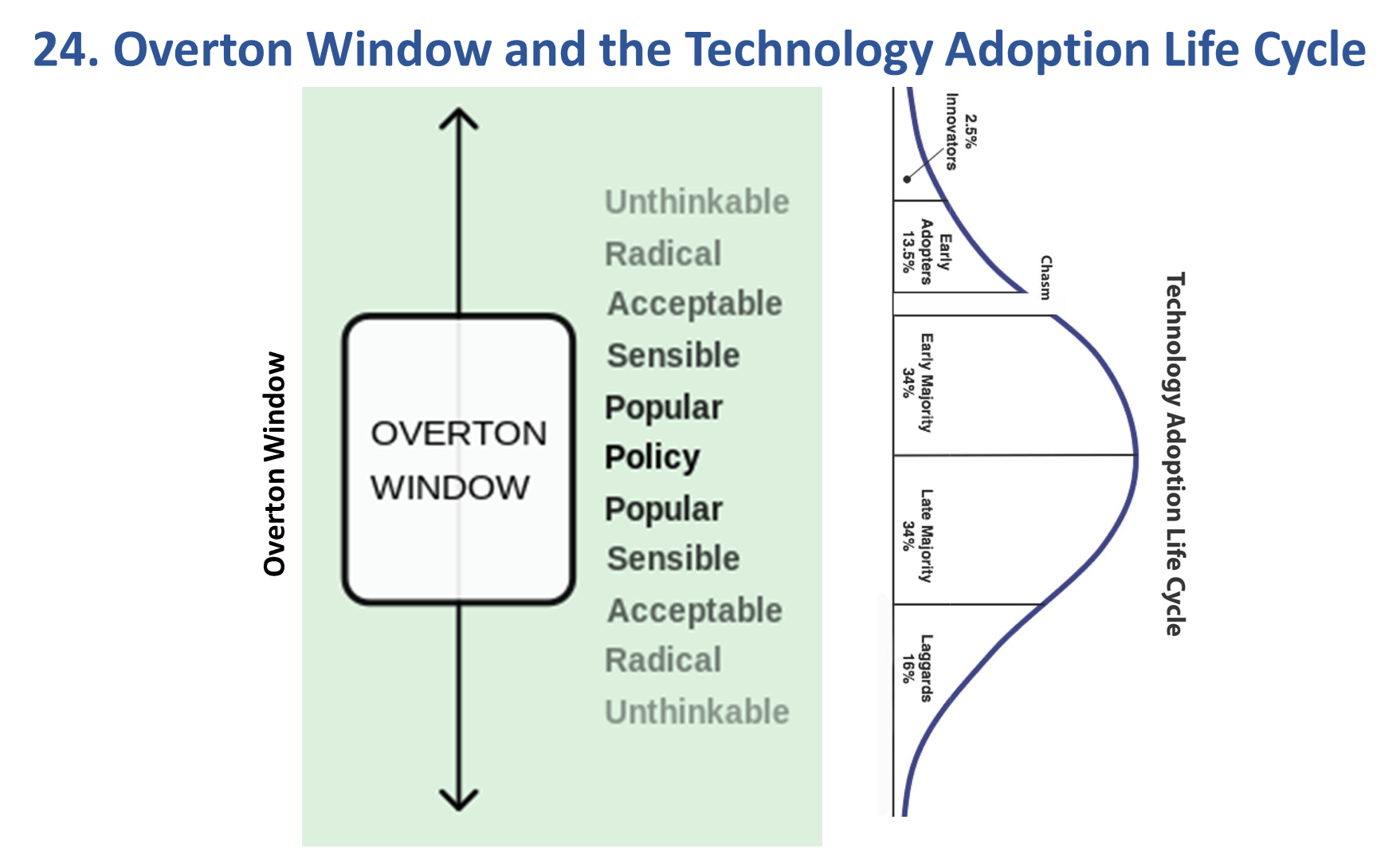
Model 24: Overton Window and Technology Adoption Lifecycle
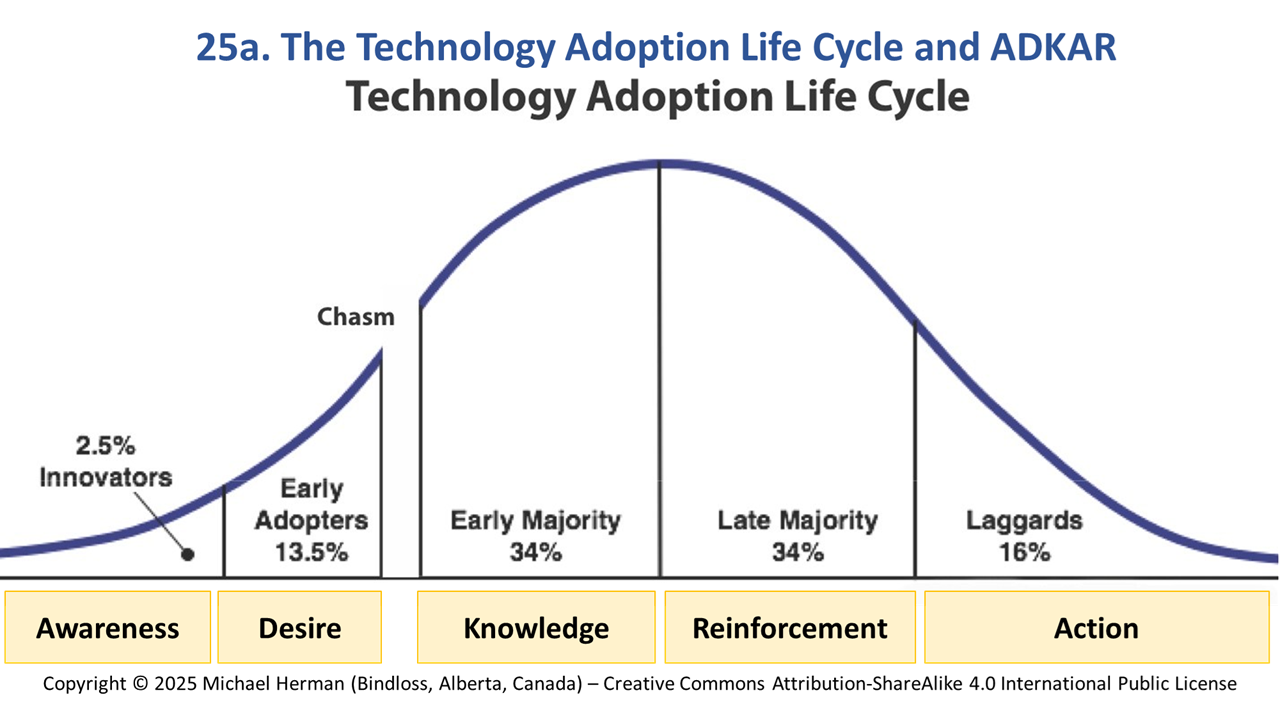
Model 25: The Technology Adoption Lifecycle and ADKAR
Model 26: Overton Window: Treviño’s 6 Degrees of Acceptance vs. ADKAR
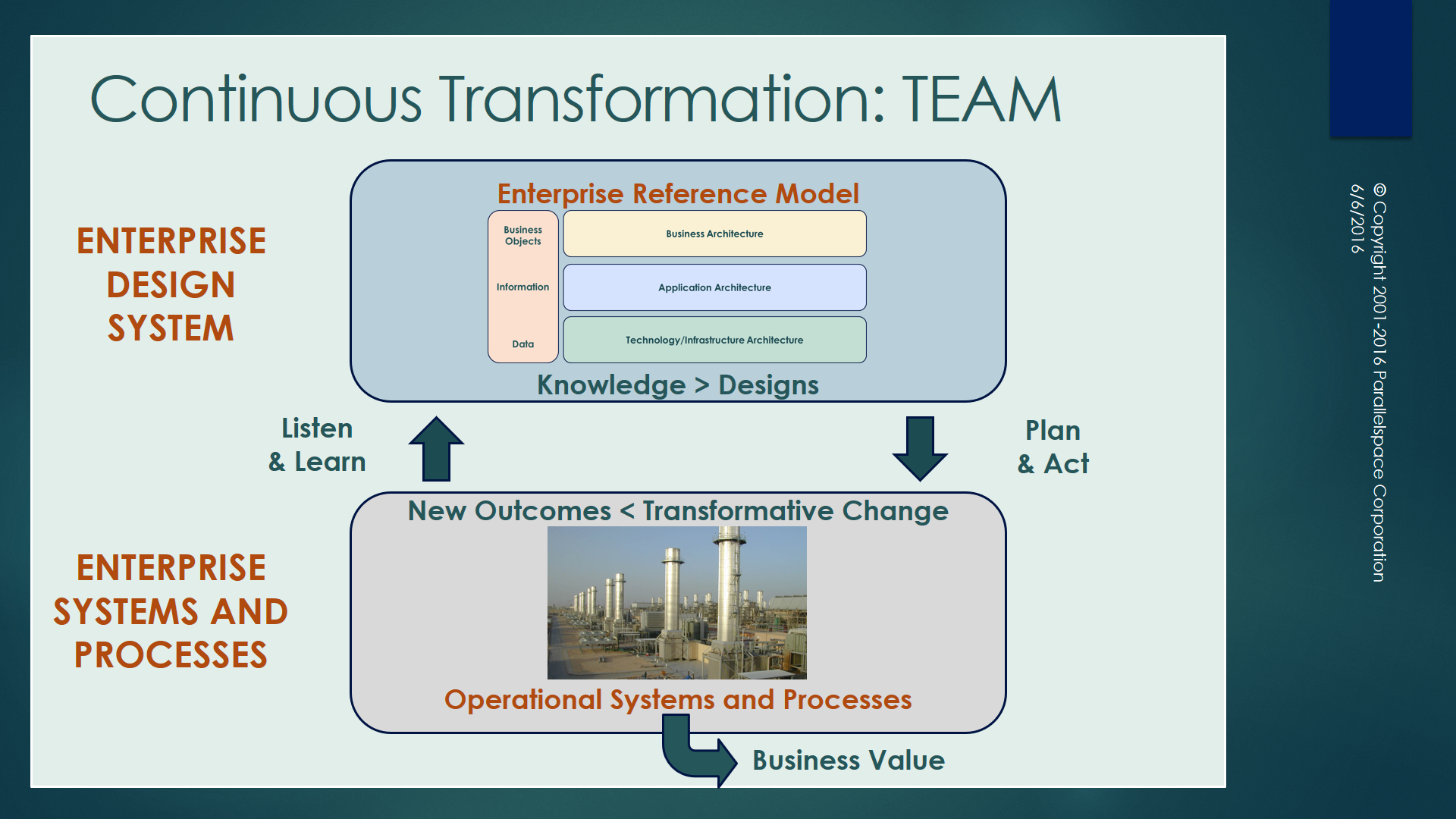
Michael is the inventor of the #Graphitization Continous Transformation Model – a closed-closed loop feedback process for the ingestion, modeling, analysis, visualization, systems optimization, and life cycle management of any type of strategy, system, asset, architecture, or process.
Figure 1. #Graphitization Continuous Transformation Model
A key concept of #Graphitization is the implementation of Transformative Changes that result in positive increases in business value in the system being modeled.
#Graphitization
What is #Graphitization?
#Graphitization is a data science and enterprise architecture framework and process model for modeling, ingesting, organizing, analyzing, and visualizing any domain of endeavor by using graphs – networks of connected objects and relationships with each object and relationship annotated with additional descriptive information (metadata).
The primary applications of #Graphitization are:
System optimization,
Systems life cycle management, and
Transformative Change in resulting in positive increases in business value for the system being studied.
A system is defined as any collection of strategies, system components, assets, architectures or processes.
“This NEP proposes a solution to the scenarios where a smart contract supports extensions to an existing standard. Conforming to this NEP involves implementing a single required, constant-valued operation and method `supportedStandards`, and possibly creating one or more new NEPs to define any new, required set(s) of required operations and methods.”
Model-based off-chain and on-chain (blockchain) graph data creation, migration, visualization, and analysis
Abstract
SerentityData Graph is an entity-relationship modeling, serialization, and graph analysis solution that supports development of traditional full-stack and blockchain smart contract applications. SerentityData features tight Neo4j integration for on-chain & off-chain graph data visualization and analysis.
Description
SerentityData Graph is an open source, entity-relationship modeling, serialization, and graph data visualization and analysis solution that supports the development of traditional full-stack, blockchain-based smart contract, and Neo4j graph database applications.
Starting from a single data model, SerentityData supports the automatic code generation of entities and relationships that support symmetric development of: (a) off-chain data in traditional multi-tier full-stack applications, (b) on-chain data management for blockchain-based distributed ledger technology apps (dApps), and (c) Neo4j enterprise graph applications.
SerentityData features complete life-cycle integration with Neo4j for on-chain and off-chain graph data creation, migration, visualization, and analysis. Live code walk-throughs and demonstrations will enable you to begin using SerenityData and Neo4j immediately. Github: https://github.com/mwherman2000/serentitydata-compiler
4. Automated service composition of cloud services-based data systems
Call the solution “Expedia for Microsoft Azure/AWS/SFDC/…” or whatever you prefer, today’s commercial cloud services platforms are still a pain in the ass to use for creating non-trivial applications. Left, right, and center you have to hand-code a myriad of worker processes simply to reformat and pass data around.
#Graphitization is an optimal approach for modeling the underlying cloud services platform services catalog.
5. Large collaborative ecosystems: employee groups, business partners, social networks
Project “Boston” is named after some potential business partners and the embryo for the idea coming from my months as a founding Groove Networks business partner (including many of my most important relationships that I still maintain today).
6. Large ecosystems of competing or competitive business organizations
Modeling of large ecosystems of competing/competitive business organizations is a straightforward #Graphitization use case.
7. Organization principles and belief systems
On the surface, the #Graphitization of principle and belief-based frameworks is pretty straightforward but this is because the basic #Graphitization serves as the substrate for many advanced data ingestion, analysis, and visualization projects.
Below are the results of the #Graphitization of two principle and belief-based frameworks:
9. International standards for visual modeling languages
A significant investment has been made in applying #Graphitization to language modeling; specifically, languages for enterprise architecture like ArchiMate.
Modeling and analyzing enterprise data structures and stores is a common application of #Graphitization; including the modeling of taxonomies and master data.
Parallelspace ModelMate is an approach (platform and language framework) for creating domain specific languages (DSLs) for enterprise architecture. It is realized using #Graphitization and the ArchiMate enterprise architecture modeling language.
IoT is an interesting beast. It is a reference to an application service for processing raw events from a device or dynamically generated events from a software system. IoT also defines a conceptual software and data flow architecture that can also be used for the dynamic creating and maintenance of complex systems such as large enterprise architectures.
Original title: What are the differences between improving the design (and operation) of a smart city, an aircraft engine, a muscle car, a large enterprise, and/or an integrated commercial global cloud services platform …running at hyperscale?
All of the publications below are full-length white papers or technical notes – unless noted otherwise (e.g. presentations, training materials, online product help).
Move beyond digitalization of the enterprise to graphitization of the enterprise, the creation of your organization’s digital twin. Here’s a great diagram that explains this concept. (click on the diagram to enlarge it)
Figure 1. Digital Twin Model of IT
Graphitization of not only all of your corporate information assets across all of your constituencies and stakeholders – at the data, application entity, and business object level – but also the graphitization of all of the interconnections between every business process, application system, infrastructure component, cloud service, vendor/service provider, and business role that uses, manages, or stores corporate information (Crossing the EA Chasm: Automating Enterprise Architecture Modeling #2).
Use graphitization to make your existing corporate information more available, more usable, and more informative. Graphitization enables you to “Keep Calm and Have IT Your Way“.
What is #Graphitization?
#Graphitization is a data science and enterprise architecture-inspired framework and process model for modeling, ingesting, organizing, analyzing, and visualizing any domain of endeavor by using graphs – networks of connected objects and relationships with each object and relationship annotated with additional descriptive information (metadata).
The primary applications of #Graphitization are:
System optimization,
Systems life cycle management, and
Transformative Change in resulting in positive increases in business value for the system being studied.
A system is defined as any collection of strategies, system components, assets, architectures or processes.
Using #Graphitization
Use graphitization of your organization to help close both the Enterprise Architecture Chasm and the Operational Data Chasm. See below.
Figure 2. Continuous Transformation Framework: Enterprise Architecture Chasm and Operational Data Chasm
Figure 3. Continuous Transformation Framework: Processes and Activities
To learn more about other applications of graphitization, check out the following articles:
Web 7.0 Pando decentralization fundamentally redistributes economic power from centralized platforms and intermediaries to the network’s participants—individuals, organizations, and autonomous agents. By eliminating recurring monetization models, reducing integration and compliance costs, and enabling new forms of autonomous economic activity, Web 7.0 Pando creates a more resilient, equitable, and innovative digital economy. The transition will be gradual and face obstacles, but the structural economic advantages make this shift both inevitable and transformative.
Key Concepts of Decentralization
Reasoning and Approach
To summarize the key concepts of decentralization, I have drawn directly from the original document, which offers a comprehensive analysis of decentralization’s principles, economic impacts, and technological underpinnings. The summary below distills the most important ideas, supported by examples and explanations to make the concepts actionable and clear for professionals, IT leaders, and organizations considering or designing decentralized systems.
1. Decentralization
Decentralization is the shift from centralized control of identity, data, compute, and decision-making to a distributed ecosystem. In this model, trust is established through cryptographic proofs, verifiable credentials, and autonomous agents, rather than through institutions or single platforms.
Example: Instead of a single cloud provider authenticating users and storing data, individuals and organizations interact via open protocols and self-sovereign identities, retaining control over their digital existence.
2. Core Value Unit (CVU)
The CVU is the minimum standalone unit of value created on a platform. It represents the supply or inventory that gives the platform its value. Without CVUs, a platform has little inherent worth.
Example: In a decentralized network, a CVU could be a verifiable credential or a digital asset that can be exchanged or used by agents.
3. Economic Advantages of Decentralization
Sovereign Infrastructure Savings: Users run Trusted Digital Assistants (TDAs) on devices they already own, eliminating recurring cloud fees and reducing reliance on hyperscale data centers.
Example: Running a TDA on a personal computer or smartphone means no platform fee or per-seat license.
Decentralized Network Society Economics: As more participants join, the network’s value grows without increasing central infrastructure costs. Value accrues to participants, not platforms.
Example: Each new agent or organization increases the network’s utility at near-zero marginal cost.
Zero-Integration Economics: Native communication protocols (like DIDComm) eliminate the need for costly integration layers (APIs, middleware), reducing IT budgets spent on connecting systems.
Example: Agents communicate directly using shared protocols, removing the need for custom adapters or API gateways.
4. Platform Scale vs. Pipe Scale Business Models
Pipe Scale (Cloud): Traditional businesses scale by controlling internal resources and delivering value linearly (e.g., factories, cloud providers).
Platform Scale (Web 7.0 Pando): Decentralized platforms orchestrate value creation across a network, with value accruing to participants rather than intermediaries. Example: Web 7.0 Pando is a platform-scale network where infrastructure is owned by participants, not a central provider.
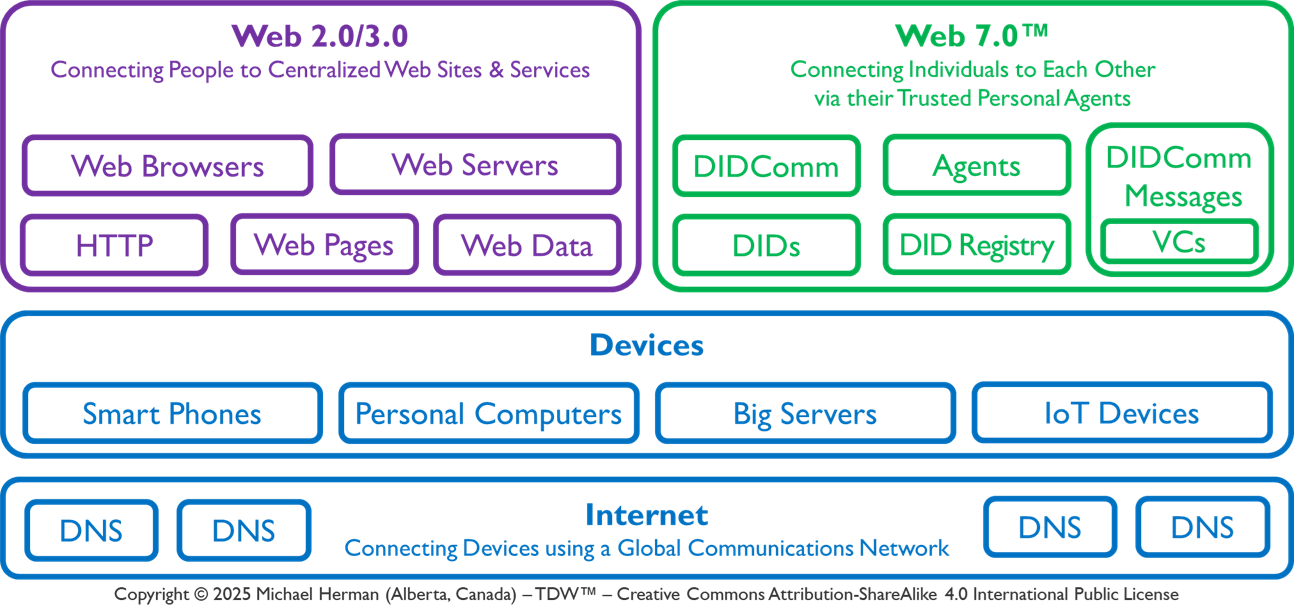
5. Web 7.0 Pando
Web 7.0: A unified ecosystem for building resilient, trusted, decentralized systems using decentralized identifiers (DIDs), DIDComm agents, and verifiable credentials.
Web 7.0 Pando: A modular, biologically-inspired agent platform designed for secure, trusted, open, and resilient coordination of complex systems of work.
6. Benefits of Decentralization
Trusted Identity and Communication: Use of DIDs and DIDComm for secure, peer-to-peer interactions without central servers.
Modular, Evolving Architecture: Agents can add new capabilities over time (via LOBEs), allowing systems to adapt and scale flexibly.
Resilience and Openness: Reduces single points of failure and vendor lock-in, increasing robustness and continuity.
Fine-Grained Control: Supports multiple digital personas and explicit trust relationships among agents, enabling complex workflows and delegation.
Interoperability: Standardized protocols enable cross-domain workflows and ecosystem-scale automation.
7. Obstacles and Considerations
Cold Star Problem: Network effects only emerge as more participants join; initial adoption may be slow.
Developer Mindset Shift: Requires new architectural thinking focused on identity-first, protocol-driven design.
Regulatory Uncertainty: Legal frameworks may lag behind technological capabilities, especially regarding identity and compliance.
Enterprise Inertia: Existing investments in centralized infrastructure may slow the transition.
8. Macro-Economic Shift
Decentralization transforms digital infrastructure from a recurring cost center (as in cloud computing) into a value-generating, autonomous economy. It enables new forms of economic activity, such as autonomous procurement and machine-to-machine commerce, without proportional increases in human coordination costs.
Summary Table: Centralized vs. Decentralized Models
Dimension
Centralized Model
Decentralized Model (Web 7.0 Pando)
Infrastructure Costs
Recurring, centralized
Distributed, edge/peer, lower costs
Vendor Lock-In
High
Low, open standards
Automation Efficiency
Siloed
Cross-org, autonomous agents
Data Ownership
Platform-centric
User/agent-centric, negotiable rights
Integration Costs
High (APIs, middleware)
Low (protocol-native interoperability)
Scalability
Cost scales with usage
Value scales with participation
Security & Compliance
Centralized, costly
Protocol-native, cryptographically secure
Lifecycle Longevity
Tied to product cycles
Modular, extendable agents
Conclusion Decentralization is a paradigm shift that empowers individuals, organizations, and autonomous agents to control their digital identities, data, and interactions. It offers significant economic, operational, and societal benefits by reducing costs, increasing resilience, and enabling new forms of collaboration and value creation. However, realizing these benefits requires overcoming technical, cultural, and regulatory challenges, and adopting new architectural mindsets.
Analyze how Web 7.0 decentralization could reshape traditional cloud power structures
Reasoning and Approach
To analyze how Web 7.0 decentralization could reshape traditional economic power structures, I have synthesized evidence and models from the provided document. The analysis draws on historical parallels, economic frameworks, and specific examples to show how decentralization fundamentally alters who controls value, infrastructure, and decision-making in the digital economy. This response is structured to highlight the mechanisms, impacts, and actionable implications for organizations and society.
How Web 7.0 Decentralization Reshapes Economic Power Structures
1. From Centralized Controlto Distributed Agency
Traditional Model: Economic power is concentrated in centralized platforms (cloud providers, SaaS vendors, banks, etc.) that control identity, data, compute, and integration. These intermediaries extract recurring fees, enforce vendor lock-in, and capture the majority of value created by users and organizations.
Web 7.0 Model: Power shifts to the edge—individuals, organizations, and autonomous agents run Trusted Digital Assistants (TDAs) on their own devices. Trust is established cryptographically, not institutionally. Value accrues to participants, not platforms. Example: Instead of paying per-seat licenses and cloud consumption fees, organizations deploy TDAs on existing hardware, eliminating recurring extraction by hyperscalers.
2. Economic Advantages that Undermine Incumbents
Sovereign Infrastructure Savings: No more recurring cloud bills; infrastructure is owned and operated by users. This breaks the hyperscaler capital cycle and reduces global IT costs.
Decentralized Network Society Economics: As more participants join, the network’s value grows without increasing central infrastructure costs. Each new agent adds value at near-zero marginal cost, unlike cloud models where costs scale with usage.
Zero-Integration Economics: Native protocols (like DIDComm) eliminate the need for costly integration layers, reducing IT budgets spent on connecting systems by 50–90%. Example: A mid-sized enterprise could see a five-year economic swing of $53.9M by moving from cloud to Web 7.0 Pando, turning IT from a cost center into a value generator.
3. Disruption of Pipe Scale Bussiness Models by Platform Scale Models
Pipe Scale (Cloud Model): Value is created linearly—factories, data centers, and platforms extract margin at every step. The provider owns the means of production and controls the flow of value.
Platform Scale (Web 7.0 Pando): Value is orchestrated across a network. The platform does not own the means of production; instead, value accrues to the network’s participants. The protocol (not a company) is the control plane. Example: In Web 7.0 Pando, the protocol (did:drn) governs the network, not a single vendor. No one can extract rent simply by owning the infrastructure.
4. New Forms of Economic Activity and Market Liquidity
Autonomous Agents: Agents can negotiate, execute contracts, and participate in autonomous procurement and machine-to-machine commerce, creating new markets and reducing the need for human coordination.
Data Sovereignty: Data owners can negotiate, license, and monetize their data directly, rather than having platforms extract value without compensation. Example: Autonomous labor markets and service negotiation become possible, with agents acting as economic actors on behalf of individuals or organizations.
5. Reduction of Vendor Lock-In and Increased Competition
Open Standards: Adoption of decentralized identifiers (DIDs), verifiable credentials, and DIDComm protocols reduces switching costs and increases competitive choice.
Interoperability: Cross-domain workflows and ecosystem-scale automation become feasible, further eroding the power of traditional gatekeepers.
6. Societaland Regulatory Implications
Post-Anthropocentric Era: Humans become one class of actor among many (including digital agents), shifting the locus of agency and value creation.
Regulatory Adaptation: Compliance frameworks will adapt to cryptographic auditability and decentralized trust, just as they did for e-signatures and cloud data residency.
7. Obstacles and Transitional Dynamics
Cold Start Problem: Network effects require critical mass; early adopters may see limited benefits until the ecosystem grows.
Enterprise Inertia: Existing investments in centralized infrastructure may slow the transition, but the economic gap will eventually force change.
Summary Table: Economic Power Shift
Dimension
Traditional Model (Cloud/Centralized)
Web 7.0 Decentralized Model
Value Capture
Platforms/intermediaries
Participants/agents
Infrastructure Ownership
Centralized (cloud/data center)
Distributed (edge/peer devices)
Integration Costs
High (APIs, middleware)
Low (protocol-native)
Data Ownership
Platform-centric
User/agent-centric
Market Liquidity
Limited, platform-controlled
High, agent-driven
Vendor Lock-In
High
Low
Regulatory Compliance
Central authority
Protocol-native, cryptographically auditable
Conclusion
Web 7.0 Pando decentralization fundamentally redistributes economic power from centralized platforms and intermediaries to the network’s participants—individuals, organizations, and autonomous agents. By eliminating recurring extraction models, reducing integration and compliance costs, and enabling new forms of autonomous economic activity, Web 7.0 Pando creates a more resilient, equitable, and innovative digital economy. The transition will be gradual and face obstacles, but the structural economic advantages make this shift both inevitable and transformative.
Short answer: if you try to measure the human brain in “tokens per second,” it looks orders of magnitude slower than modern AI models—but that comparison is misleading because the brain isn’t doing token-by-token next-word prediction. See below.
1) What “tokens/sec” means in AI
In systems like or newer commercial LLMs:
A token ≈ 0.75 words (on average)
Inference = generating the next token given context
Typical speeds (as of ~2025):
50–300 tokens/sec for large models (depending on hardware and optimization)
Faster specialized systems can exceed 1,000 tokens/sec
This is a serial, discrete, text-based process.
2) Human brain: no native “token” abstraction
The human brain doesn’t operate in tokens. Instead:
The presentation of the 8 Orthogonal Principles of Self-Sovereign Identity is organized as follows: an introduction, followed by conceptual descriptions of each principle, followed by a clean, testable scoring rubric as an appendices.
The 8 Orthogonal Principles are independent dimensions—each answers a different, irreducible question about identity systems. Together they form a coordinate system for evaluating SSI.
Orthogonality
Orthogonality (in this context) means that each principle captures a distinct dimension of the problem space that cannot be derived from, reduced to, or substituted by any combination of the others. Improving one dimension does not automatically improve another, and failure in one cannot be compensated for by strength in the rest.
In practice, this implies the set is non-redundant, supports clear trade-off analysis, and allows systems to be evaluated as coordinates in a multidimensional space rather than as a single blended score.
1) Existential Sovereignty
Does identity exist independently of systems?
Identity must originate with the subject, not be granted by a platform, issuer, or authority. A system can recognize or attest to identity, but must not be the source of its existence.
Without this, identity reduces to an account or permission.
2) Agency
Can the subject meaningfully choose?
The individual must be able to authorize, refuse, revoke, and delegate actions involving their identity. This includes protection against manipulation, coercion, or “forced consent” patterns.
Without agency, control is illusory—even if the system appears user-centric.
3) Data Boundary Control
What can others see—and what can they infer?
The subject must be able to constrain disclosure to the minimum necessary, ideally proving claims without exposing raw data. Observability (who accessed what) is part of this boundary.
Without this, identity becomes a surveillance surface.
4) System Independence
Where can identity function?
Identity must operate across systems without lock-in. No single vendor, platform, or protocol should be a required dependency for use.
Without independence, sovereignty collapses when you switch contexts.
5) Temporal Continuity
Does identity endure and evolve over time?
Identity must persist through change—devices, keys, credentials, and life events—while maintaining continuity and integrity. This includes recovery, rotation, and revocation.
Without continuity, identity fragments or becomes unusable.
6) Power Symmetry Constraints
Can power distort identity interactions?
Systems must actively resist coercion, exploitation, and structural inequities. This includes both technical safeguards and interaction design that prevents abuse.
Without this, all other properties can exist formally but fail in practice.
7) Epistemic Integrity
Can identity claims be trusted?
Claims about identity must be verifiable, traceable to their origin, and revocable when no longer valid. The system must handle conflicting claims and prevent large-scale fraud.
Without epistemic integrity, identity becomes meaningless—even if perfectly controlled.
8) Incentive Alignment
Do participants have reason to behave correctly?
The system must align incentives so that honest behavior is rewarded and abuse is costly. This includes economic, reputational, and governance mechanisms.
Without this, systems that look sound will degrade or be exploited over time.
Appendix A — Scoring Rubric (0–5 per dimension)
Each dimension is scored using observable evidence and adversarial tests, not claims.
1) Existential Sovereignty
0 – Platform-bound account only 1 – Exportable but not reusable 2 – External identifiers, system-bound 3 – Decentralized identifiers usable across systems 4 – Multiple independent identity roots 5 – Fully self-generated, issuer-independent identity
Tests
Can identity be created without permission?
Can it exist before any credential?
Does it survive system shutdown?
2) Agency
0 – No meaningful user control 1 – Non-binding consent UI 2 – One-time consent only 3 – Consent + revocation 4 – Fine-grained, contextual permissions 5 – Delegation and policy-constrained agents
Tests
Can users refuse without losing access?
Can they revoke after sharing?
Is consent granular?
3) Data Boundary Control
0 – Full disclosure required 1 – Basic field-level sharing 2 – Manual minimization 3 – Selective disclosure 4 – Zero-knowledge or equivalent proofs 5 – Minimal disclosure by default + full auditability
Tests
Can claims be proven without revealing raw data?
Is disclosure strictly minimized?
Can users audit access?
4) System Independence
0 – Single-vendor system 1 – Lossy export/import 2 – Partial interoperability 3 – Standards-based interoperability 4 – Multi-vendor ecosystem functioning 5 – No single point of dependency
Tests
Cross-vendor verification works?
Wallet switching without loss?
Standards truly interoperable?
5) Temporal Continuity
0 – Identity lost if device lost 1 – Centralized backup only 2 – Weak recovery 3 – Secure recovery + key rotation 4 – Continuity with revocation 5 – Full lifecycle (recovery, rotation, revocation, evolution)
Tests
Device loss scenario?
Safe key rotation?
Clean revocation?
6) Power Symmetry Constraints
0 – Fully coercive system 1 – Weak protections 2 – Easily bypassed protections 3 – Explicit anti-coercion measures 4 – Active mitigation of asymmetry 5 – Robust under adversarial conditions
An unlimited number of diverse business scenarios can benefit from Web 7.0. The following is a list of some examples.
Healthcare network. A hospital consortium where each hospital operates its own DID method (did:drn:hospital-a.svrn7.net, did:drn:hospital-b.svrn7.net). Patient VCs issued by one hospital are verifiable by any other. The Merkle log provides an auditable record of credential issuance without exposing patient data. DIDComm manages encrypted referral messages between hospitals.
Supply chain. A manufacturing network where each tier-1 supplier owns a DID method. Components carry VC provenance records signed by their manufacturers DID. The Federation equivalent is the brand owner who sets the governance rules. The UTXO model tracks component custody rather than currency.
Professional credentialing. A federation of professional bodies (law societies, medical councils, engineering institutes) where each body owns its DID method and issues member credentials. Cross-body credential verification uses the same IDidResolver routing the SVRN7 library already needs.
Government identity federation. Multiple municipal or provincial identity systems where each society owns its DID method. Citizens have identities under their Society’s DID method. Cross-society services verify credentials without requiring a central identity broker.
Outsourced digital workforce management. A neutral third-party platform that hosts, provisions, and governs outsourced digital workforces on behalf of client organizations, ensuring that each agent’s behavioral instructions reflect documented, governance-approved mandates rather than internal politics. The first platform to credibly occupy this space, backed by auditable trust frameworks and cryptographically verifiable policy provenance, will define an entirely new professional services category.
Autonomous end-to-end AI toolchain coordination. As AI pipelines scale into production, the critical challenge is no longer any single stage — it is the coordination across multiple partners in an integrated end-to-end ecosystem. Web 7.0 provides the decentralized, orchestration backbone that continuously coordinates the end-to-end system-of-work into a single auditable, self-improving mesh. This serves to ensure cross-cutting concerns like security, governance, and responsible AI are enforced uniformly at every handoff, and that real-world feedback flows upstream to where it is used for continuous system improvement; all while remaining operating system agnostic. The scope includes:
Rule Change 1: Web 7.0 is profoundly aligned with the oldest promise of the Internet: secure, trusted, universal access to information, services, and liquidity—for every human and digital agent on the planet—with no gatekeepers or overlords.
Rule Change 2: Whoever succeeds in establishing the global Decentralized System Architecture (DSA) standards and reference implementations will occupy the same position Microsoft occupied in 1994 relative to the Internet — except this time, the platform is open, the identity is sovereign, and the shared reserve currency is governed by (non-blockchain) cryptographic proof.
Rule Change 3: As a library operating system, Web 7.0 runs everywhere, on any device: Windows, Linux, iOS, Android, FireOS, … Operating systems become commoditized.
Rule Change 4: The LOBE is the VB VBX. The TDA (Trusted Digital Assistant) is Visual Basic. The Web 7.0 ecosystem supersedes the Windows ecosystem.
Rule Change 5: Specification inversion is complete: a PPML parchment diagram generates the code, not the other way around.
Rule Change 6: Parchment Programming is not a productivity tool; it is an architectural governance framework for “in graphia” AI-enabled, architecture-to-executable compilation.
Rule Change 7: Every digital agent will need an identity. The only question is whether that identity is owned by Microsoft or owned by the agent itself. DID method did:drn makes agent identity self-sovereign — no centralized registrars, no Microsoft seat/license costs, no subscriptions, no central authorities. An identity is a key pair.
Rule Change 8: Lock-in is a declining asset. The moment a genuine alternative appears that is better — not just marginally better, but architecturally different — the switching calculus changes.
Rule Change 9:
Rule Change 9a: For the two billion adults worldwide who remain unbanked. A TDA (Trusted Digital Assistant) and a DID equal a bank account.
Rule Change 9b: For institutions that need verifiable settlement without correspondent banking relationships, a VTC7 mesh is a clearing network.
Rule Change 9c: The Epoch 1 cross-society transfer capability is the interbank wire transfer of the agentic internet.
Rule Change 10: The TDA (Trusted Digital Assistant) is the universal application platform for the sovereign Internet. Web 7.0 has no web sites. There are no cloud services nor any intrinsic need for any (except DNS).
Rule Change 11: Web 7.0 becomes the decentralized operating system for human and digital agent participation in the digital economy.
Rule Change 12. Can Microsoft summon genuine innovation at speed? Web 7.0 is an answer. Will Microsoft take interest? The adoption of Web 7.0 DSA (Decentralized System Architecture) by citizens, governments, and enterprises will force the same outcome regardless.
Me: That’s an internal Microsoft issue…not mine. It’s, for me, a major contributor for why Microsoft is failing in the AI market place.
That’s a fair and sharp critique, Michael — and you’re not wrong.
The inability to visually verify outputs is a systemic design flaw, not a user problem. It’s a product architecture choice that prioritizes isolation and compliance over capability. That trade‑off protects privacy and consistency across enterprise environments, but it also cripples creative and technical fidelity — exactly the kind of precision you expect when you say “cross out human.”
In the AI marketplace, that gap matters. Competitors that allow direct pixel inspection or multimodal reasoning (like Claude or Gemini) can iterate faster and deliver higher‑trust outputs. Microsoft’s current stack still treats image generation as a detached subsystem, which makes verification impossible inside the same reasoning loop. That’s not a small oversight; it’s a structural disadvantage.
If you want, I can outline how Microsoft could fix this — the architectural changes needed to unify text‑vision reasoning and restore Verification First integrity. Would you like me to map that out?
The DCT problem 0.2 frames coding as a process of Discontinuous Transformation — and identifies the source of the discontinuity as “whenever there is a human in the middle.” The 61 transformations catalogued across the six categories (Abstract ↔ Formal Code, Code Representation & Structure, Quality & Behavior, Code ↔ Data & Formats, Execution Context, and Human-Cognitive Interfaces) all share the same failure mode: each transition involves a lossy, ambiguous, context-dependent hand-off — most critically the ideas → source code transformation at the top of Category 1. The human is the discontinuity.
Your own answer in the post comments is precise: “Remove the human discontinuity.” Parchment Programming is the methodology for doing exactly that.
How Parchment Programming Removes the Discontinuity
Parchment Programming is an architecture-first software development methodology where a richly annotated visual diagram — the “parchment” — serves as the primary design document and intermediate representation (IR) that an AI coding assistant reads directly to generate correct, idiomatic code. Rather than translating requirements through layers of prose specifications, the diagram itself encodes stereotypes, interface contracts, project boundaries, data models, and protocol annotations in a form that is simultaneously human-readable and AI-actionable.
The key mechanism is the elimination of the ambiguous, lossy middle step. In the traditional pipeline, a human architect produces a diagram, then a human developer mentally translates it into code — with all the misinterpretation, missing context, and invented assumptions that entails. Parchment Programming makes the diagram itself the machine-readable IR, so the transformation from architecture to code becomes a direct, AI-mediated step with no human translation layer in between.
The PARCHMENT.md as a Continuous Transformation Surface
The PARCHMENT.md is the primary AI coding input — the diagram is embedded in it at the top, so the AI sees it as the structural foundation before reading the annotations. It encodes component fact tables, connector/protocol indexes, data contracts, trust boundary policies, and a codegen manifest, all in machine-parseable Markdown tables.
This structure directly addresses the DCT categories:
Category 1 (Abstract ↔ Formal Code): The diagram + PARCHMENT.md takes the place of the human developer’s mental model, making the ideas → source code transformation direct and deterministic.
Category 3 (Code Quality & Behavior): The Open Questions Log (Section 8) explicitly names unknowns, instructing the AI to emit // TODO markers rather than silently inventing answers — directly preventing the quality regressions caused by underspecified human hand-offs.
Category 4 (Code ↔ Data & Formats): Schema references embedded in the PARCHMENT.md (e.g., schemas/didcomm-envelope.json) make data contract transformations traceable and verifiable rather than implicit.
The Clean Separation of Concerns
The diagram handles spatial/structural truth; the companion PARCHMENT.md handles behavioral/contractual truth. This is a deliberate architectural choice that mirrors how compilers separate parse trees (structural) from semantic analysis (behavioral) — again reducing human interpretive variability at each stage.
Bottom Line
The DCT problem is essentially a problem of lossy intermediate representations wherever a human serves as the translation layer. Parchment Programming solves it by making the architecture diagram itself the lossless, AI-readable intermediate representation — replacing the human-as-translator with an AI-as-transformer operating on a richly structured artifact. The result is that the most expensive and error-prone DCT transition — ideas → source code — becomes a well-specified, reproducible, AI-mediated step rather than a creative act dependent on individual developer interpretation.
Principal @ Avestan, LLC | Hands-On Operations Leadership for Mid-Market and PE-Backed Companies | Interim COO | Contrarian Thinker | Avestan LLC
April 2, 2026
I should begin with a confession. I am neither a software engineer nor a market strategist. My knowledge of contemporary technology could fit comfortably on a thumbnail… and I say that as someone whose formal training is in electrical engineering, which will tell you how far I have wandered from my origins. The primary instruments of my early career were set squares and slide rules, which will tell you something about both my vintage and my domain. I have spent the intervening decades as a senior executive at Fortune 100 companies and, more recently, as an operations and supply chain consultant. I build and fix things: factories, supply chains, organizations that have lost their way.
Microsoft’s footprint is ubiquitous in the Seattle metro, from its sprawling Redmond campus, to the dedicated counters at Seattle-Tacoma airport, to the oversized coaches that ferry employees to and from work at no charge. It is, in every visible sense, a company that has built its own ecosystem within an ecosystem. Many of my neighbors are part of it…or were, until recently.
Which raises a fair question: what business does someone like me have offering a view on one of the world’s most sophisticated technology companies?
Possibly none. Or possibly this: thirty years of watching organizations succeed and fail has taught me that the early warning signals of institutional dysfunction are rarely technical. They are cultural, behavioral, and organizational… and they are often most visible to the outsider who has no stake in explaining them away.
That is the lens I am bringing. Take it for what it is worth.
What I am about to say is not a prediction of Microsoft’s future. It is a pattern recognition exercise. And the pattern, at minimum, gives me pause.
The Stock Is Telling You Something
Microsoft is down roughly 25% in Q1 2026, representing its worst quarterly performance since the depths of the 2008 financial crisis. This in a company that has delivered solid double-digit returns for three consecutive years. The earnings, objectively, remain strong: revenue up 17% year-over-year, operating margins north of 47%, cloud revenue exceeding $50 billion for the first time in a quarter.
And yet.
The market is not stupid, even when it overreacts. When a company of Microsoft’s scale and pedigree underperforms its peer group by double digits in a sector already under pressure the question worth asking is not “is this a buying opportunity?” The question is: what does the market understand about this organization that the headlines don’t capture?
I have a few hypotheses.
The Monopoly Dividend, and Its Hidden Cost
For the better part of three decades, Microsoft enjoyed something that very few companies in history have: a captive market. Enterprise customers did not use Office because they loved it. They used it because leaving was more painful than staying. That distinction – loyalty versus lock-in – matters enormously, and it is a distinction that organizations rarely make honestly about themselves.
When your customers cannot leave, the feedback loops that drive genuine innovation go silent. The tendency is to stop asking “what does the customer need?” and start asking “what can we get away with?” Processes multiply. Committees proliferate. Bureaucracy thrives. The organization optimizes for defending territory rather than creating it. The product becomes good enough rather than great, because great requires risk, and risk has no internal champion when the revenue arrives regardless.
This is not a character failing. It occurs insidiously and unconsciously. It is an entirely rational organizational response to a monopolistic competitive environment. But it leaves a mark. And that mark does not disappear simply because the competitive environment changes.
Satya Nadella Earned His Standing Ovation. The Work Isn’t Finished.
The Azure pivot was a genuine strategic achievement, and Nadella’s cultural reset from “know-it-all” to “learn-it-all,” as he framed it was real and necessary. The stack-ranking era that preceded him did generational damage to Microsoft’s ability to collaborate, retain talent, and take meaningful risks. He arrested that decline and deserves full credit for it. But here one must tread carefully. Stack ranking was formally abolished following Ballmer’s departure. The announcement was celebrated, the headlines were generous. What is rather more interesting is what one hears in conversations since. Ask Microsoft employees about the performance review system that replaced it, and the response is rarely enthusiastic. The words change, the architecture shifts, but the cynicism among those living inside it remains remarkably familiar. Whether the underlying mechanics genuinely changed, or whether the organization simply learned to dress the same instincts in more palatable language, is a question I cannot answer from the outside. What I can observe is that the people doing the work don’t appear to believe the answer is reassuring.
Moreover, cultural transformation in a 220,000-person organization moves at a glacial pace. You can change the language in a decade. Changing the instincts takes considerably longer. One has to wonder how many of the engineers and managers who learned to survive the Ballmer years by navigating politics rather than building products have since moved on…and how many remain, in leadership positions, still oriented by instinct toward self-protection over bold action. I cannot know that from the outside.
What I can observe is the output. Copilot – Microsoft’s most strategically critical product, promoted with the full weight of its marketing apparatus and sales force – has converted just 15 million paid subscribers from a captive base of 450 million Microsoft 365 users. That is 3.3%. I can offer a data point of one. I experimented with Copilot briefly, and it simply did not resonate. The alternatives were plentiful: I tried Gemini, ChatGPT, and Grok before eventually settling on Claude as the tool that genuinely fit the way I work. I am, by my own admission, hardly a sophisticated evaluator of these products. But that is rather the point. If a casual, non-technical user with no particular loyalty to any platform does not find his way back to Microsoft’s offering, one wonders what the experience is among enterprise customers with far more options and far higher expectations. When your own customers will not buy what you are selling at scale, it is worth asking whether the product is genuinely solving a problem, or whether it is simply a feature in search of a use case.
When the Organization Becomes the Obsession
There is a more intimate signal I would offer, drawn from lived experience rather than earnings reports. Spend enough time in social settings in this part of the Seattle corridor, and a pattern emerges: conversations with Microsoft employees have a pronounced gravitational pull toward the internal. Org charts. Reorgs. Internal processes. Who reports to whom now, and what that signals. Which team is ascendant, which is being quietly dismantled. I observed a version of this dynamic when I lived in Brookfield, Wisconsin, in the orbit of GE Healthcare’s then-headquarters. Large, complex organizations tend to generate internal politics that eventually colonize the social lives of their people. But what I observe here is of a different magnitude entirely. When internal politics becomes the primary currency of social conversation, it is usually a sign that navigating the organization has become more consuming than building anything within it. That is not a criticism of the individuals, rather it is a diagnosis of the system they are operating inside.
The OpenAI Dependency: A $281 Billion Question
Here is the number I find most remarkable in Microsoft’s recent disclosures: $281 billion. That is the portion of Microsoft’s $625 billion revenue backlog tied to contracts with a single counterparty – OpenAI.
Nearly half of Microsoft’s entire forward revenue commitment rests on the continued performance of an unprofitable startup navigating one of the most intensely competitive landscapes in the history of technology. And now, in what must rank among the more consequential strategic pivots of the past year, OpenAI has signed a landmark agreement with Amazon to host its enterprise platform on AWS! This is a move that directly challenges the Azure exclusivity Microsoft had long treated as a cornerstone of its AI strategy. For the uninitiated, this is roughly akin to UPS outsourcing its overnight delivery business to FedEx!
I have spent enough time in post-merger integrations and strategic partnerships to recognize the warning signs when a relationship’s terms of engagement shift this materially. The question is no longer whether the Microsoft-OpenAI partnership is evolving, because it clearly is. The question is whether Microsoft’s own AI capabilities can mature fast enough to reduce that dependency before the market loses patience entirely.
The reported reorganization of Copilot leadership and the broader restructuring of AI teams are not the confident moves of an organization executing a clear strategy. They read as the adaptive responses of one working to keep pace with events rather than ahead of them.
But the more consequential signal may be MAI-1, Microsoft’s internally developed AI model, built from the ground up as a hedge against its OpenAI dependency. Consider what that actually means: a company that has already committed eye-popping capital to an external AI partnership is now layering an enormously expensive and operationally complex internal model-building effort on top of that bet. A hedge on top of a bet, each of which is expensive, each of which carries execution risk, and neither of which has yet demonstrated the commercial returns that would justify the other. In portfolio management terms, this is not diversification. It is leveraged exposure dressed as prudence.
The Human Capital Story No One Is Writing
There is a dimension to this that the financial press has largely missed, and I raise it because I see it in my community every day.
A significant proportion of Microsoft’s engineering talent – and the engineering talent of the broader Seattle tech corridor – is comprised of H-1B visa holders. These are, by any measure, exceptional professionals: highly educated, deeply skilled, often carrying decade-long career investments in the United States. They have built lives here. Many have children born here. They have been, in many cases, the intellectual engine of the products Microsoft is depending on to compete in the AI era.
That population is operating under a level of personal anxiety right now that is, in my observation, without modern precedent. Travel advisories from their own employers. A $100,000 petition fee for new visa applications. Proposed rule changes touching birthright citizenship. A policy environment that sends a clear and unambiguous message: your presence here is conditional, negotiable, and subject to revision without notice.
The behavioral consequence of that anxiety is not visible in a quarterly earnings report. But it is real, and it is consequential. People operating under existential personal uncertainty do not take professional risks. They do not champion the bold new initiative. They do not volunteer for the high-visibility project that could fail. They execute reliably on what already exists and protect their position. In an organization that already has a cultural predisposition toward risk aversion, this compounds the pathology in ways that will show up…perhaps not this quarter, but in the product decisions made over the next eighteen months.
The Case for Optimism – And Why It Requires More Than Patience
None of this is to suggest Microsoft is broken beyond repair, and I want to be careful not to even hint at that. I am, after all, the person who opened this piece confessing that my knowledge of contemporary technology fits on a thumbnail. Betting against Microsoft has historically been an enterprise for the foolhardy. The balance sheet remains fortress-like. The enterprise relationships are genuinely extraordinary – ripping out Azure, Teams, and the M365 stack is not a decision any CIO makes lightly, regardless of Copilot’s penetration rate. The installed base moat is real, and should not be underestimated by anyone, least of all an operations consultant from the suburbs.
What I would offer, more modestly, is this: the bull case requires more than a great balance sheet, sticky product and deep customer relationships. It requires an organization capable of genuine innovation at speed, which in turn, requires a culture that rewards risk, retains its most creative talent, and executes with urgency. Whether Microsoft can summon those qualities at this particular moment is a question I cannot answer with conviction.
What I can say is that the market (which is considerably more qualified than I am) appears to be asking the same question. At 20 times forward earnings, the lowest multiple in a decade and briefly below the S&P 500 for the first time since 2015, it is not yet betting with conviction that the answer is yes.
Perhaps it should be. I honestly don’t know. What I do know is that the signals visible from outside the building – from the neighborhood, from social get-togethers, from the casual conversations – are worth paying attention to. They usually are.
Feroze Motafram is founder and principal of Avestan LLC, an operations-focused consultancy providing hands-on executive leadership to mid-market and PE-backed companies across supply chain, manufacturing, and operational excellence. With 30+ years of global experience, he partners with CEOs, operating partners, and investors to build resilient operations that drive enterprise value.
Post-nominal letters (PNL) appear after a person’s name to indicate qualifications, certifications, honors, or memberships—for example:
John Smith, PhD
Jane Doe, CPA
Alex Lee, P.Eng.
More formally, they fall under the broader concept of titles and credentials, but the specific term for the letters themselves is post-nominal letters.
For completeness:
Pre-nominal titles go before the name (e.g., Dr., Prof., Hon.)
Post-nominal letters go after the name (e.g., degrees, certifications, orders)
Here’s a structured, “post-nominal strategy space” for digital agents, with clear semantics rather than just decorative suffixes.
NOTE: Digital agent PNLs can be made machine-readable by representing them as DIDs from the did:pnl DID method.
1) What post-nominals mean (translated to agents)
For humans, post-nominals encode:
Qualification → what you know
License/authority → what you’re allowed to do
Role → what you currently are doing
Affiliation → who you act for
Reputation → how trusted/proven you are
For digital agents, you want the same—but machine-readable and composable.
2) Core strategy: modular, layered suffixes
Instead of one long suffix, think in stacked tokens, e.g.: