Michael Herman (Toronto/Calgary/Seattle)
Hyperonomy Business Blockchain Project / Parallelspace Corporation
February 2019
The SerentityData Entity Serialization and Field Encoding library fulfills Blockchain Requirement 1 for the Universal UBL (UUBL) extensions to the UBL 2.2 business document schema specification:
Requirement 1. Compact and Efficient Binary Serialization
The requirement for extremely compact and efficient binary serialization of each entity (and subentity) can be fulfilled by various software serialization solutions including SerentityData Variable-byte, Statistically-based Entity Serialization. The SerentityData project can be found on Github. SerentityData is the author’s preferred solution.
Design and Implementation Strategy
Design Principles
- Statistically-based Encodings (STE): For a particular datatype (e.g. Signed Int 16 or Unsigned Int 64), some data values representable by this datatype will be used more frequently than others (e.g. 0 (zero), 1, small integer values, etc.) and there should be a way to encode these statistically more frequent values using as few bytes as possible (compared to larger data values).
- Variable-byte Encodings (VBE): Over the lifespan of a persisted field (e.g. an Unsigned Int 64 blockchain block or transaction serial number), the initial values of the field will have small values (0, 1, 2, 3, …) and over the course of a long time (years or decades) grow to have very large values. As few bytes as possible should be used to represent small values and this should be less than the number of bytes required to represent very large values.
- Application-adaptive Encodings (AAE): Every application or application data domain will require:
- A different subset of the available datatypes, and
- Each data type will have a different statistical distribution of application-dependent data values.
- Single-byte Encodings (SBE): Very common (application-dependent) data values, on a datatype-by-datatype basis, should only require 1 (one) byte of storage. For example, for specific applications, the following values would be candidates for single-byte encodings:
- Data value TRUE of datatype Boolean and data value False of datatype Boolean
- Specific data values of small whole numbers (e.g. 0, 1, 2, 3, 4, 5, … n) where, depending on the application and datatype, n might be 10, 32 (days of the month), 60 (seconds in a minute), etc. The values do not have to be contiguous.
- Specific data values of negative numbers (e.g. -1, -2, -3, -4, -5, … m) where, depending on the application and datatype, m might be -10, -20, etc. The values do not have to be contiguous.
- Specific data values of Enum datatypes. The values are usually contiguous but there is no requirement for them to be contiguous.
- Support All Datatypes (SAD): It should be possible to encode all possible datatypes and all possible data values for the selected data types. The current list of supported data types includes:
- Signed Integer 16
- Signed Integer 32
- Signed Integer 64
- Unsigned Integer 16
- Unsigned Integer 32
- Unsigned Integer 64
- Byte
- Signed Byte
- Enum
- Byte Array
- Boolean
- Boolean
- Char
- String
- ASCIIString
- Address
- Guid
- Standalone, Compact, and Efficient (SCE) Implementation
- Standalone: The entity serialization and field encoding libraries will not rely on any external source code or callable binary libraries.
- Compact: The entity serialization and field encoding libraries will be compact enough to be useful and desirable to execute:
- Off-chain in a traditional computing environment including server, PC, tablet, and mobile device, as well as
- On-chain in a smart contract (virtual machine) execution environment
- Efficient: Highly efficient code execution to be useful and desirable to use in a fee-based, smart contract (virtual machine) execution environment
- Storage Compatibility (SC): Compatible with any data storage technology capable of storing variable-length arrays of bytes representing the field encoded and entity serialized data.
- Runtime Compatibility (RC): The current design and implementation of the entity serialization and field encoding libraries is compatible with .NET Core 2.0 or later.
- Versioning Support (VS): Support for versioning at the entity serialization as well as entity encoding levels; including support for multiple applications, serializations and encodings in the same library.
- Entity Extensibility and Backward Compatibility (EEBC): Entity declarations can be extended through the additional fields without losing backward compatibility with previously serialized entities.
- Support for ByteArray and String Null-Valued References (NULLS): Support for null-valued references to ByteArrays and Strings – in addition to zero-length and non-zero length ByteArrays and Strings.
Assumptions
- There exists a code generation tool that takes as input a description of an entity, its fields and their datatypes that will create the sequence of calls into the entity serialization and field encoding that performs serialization/deserialization and field coding/decoding for a target entity declaration (e.g. a C# class declaration).
Implementation Notes
- The reference implementation of the entity serialization and field encoding libraries is called SerentityData and is implemented using .NET Core 2.0, C#, and Visual Studio 2007 Community Edition.
Roadmap
Features that are unsupported in the current release:
- Collections and Mappings: next on the queue
- Nested Entity Declarations: An entity declaration that has a field whose datatype is another entity declaration.
Field Encoding Strategy
TODO
Byte 0 Mapping
In the Variable Byte Encoding scheme used to represent the value of a datatype, the first byte of an encoded field value (Byte 0) is the most important. For Single-byte Encodings, Byte 0 needs to encode both the datatype of a particular value but also the value itself.
Given there are only 256 unique values that Byte 0 (or any single byte) can assume, certain trade-offs must be made to accommodate the range of application-driven datatypes required and the number of possible single-byte, double-byte, and triple-byte optimizations that are possible. This is where statistical knowledge of the range of values that a particular datatype required by an application is important.
Byte 0 Default Mapping
Figure 1 below is an example of the current default set of Byte 0 mappings.
 Figure 1. Byte 0 Default Mapping Table
Figure 1. Byte 0 Default Mapping Table
Data value 0 (zero) is currently not assigned.
Single-Byte Encodings
TODO
Two-Byte Encodings
TODO
Three-Byte Encodings
TODO
Longer Byte Encodings
TODO
Performance
TODO
Sample Use Case
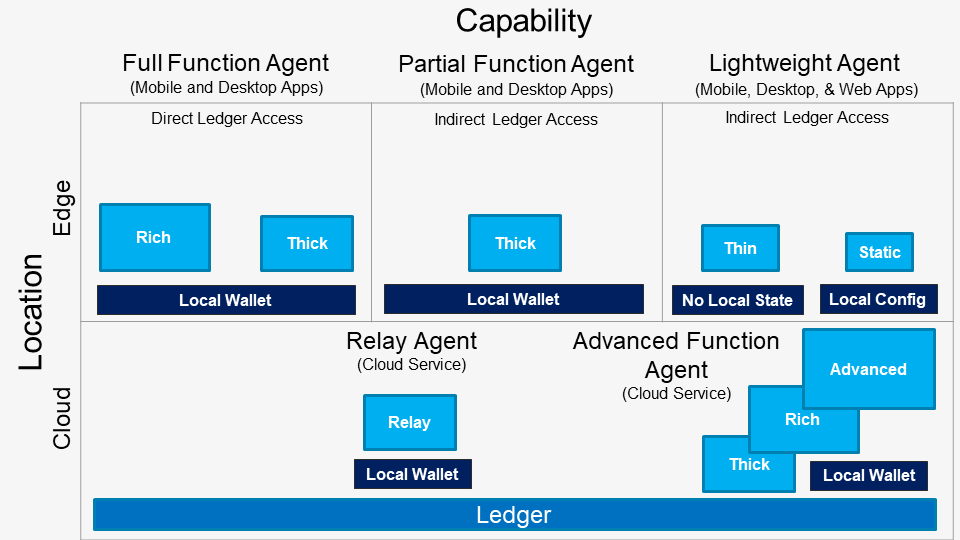
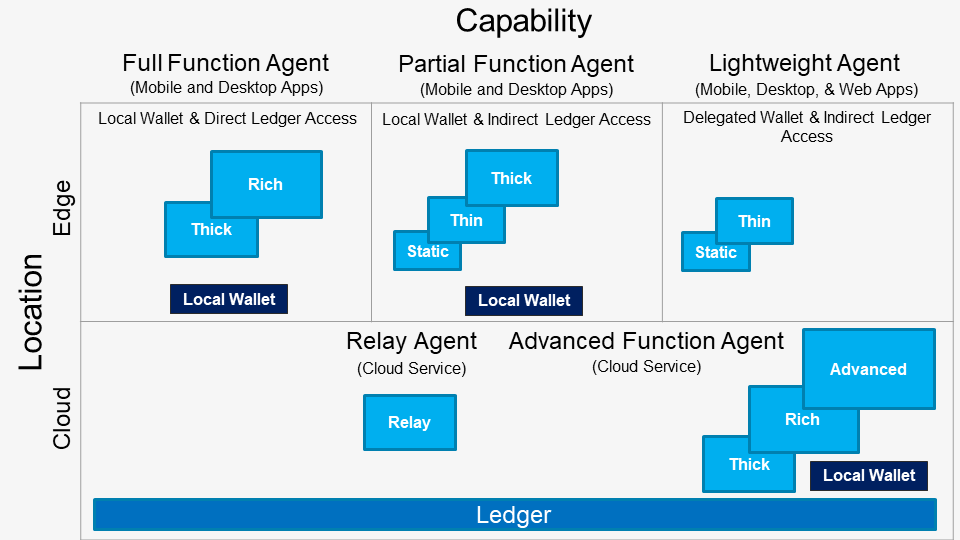
An example of a distributed business application designed to be used with SerentityData is the following SerentityDapp.Perfmon for on-chain [blockchain] performance monitoring and recording.
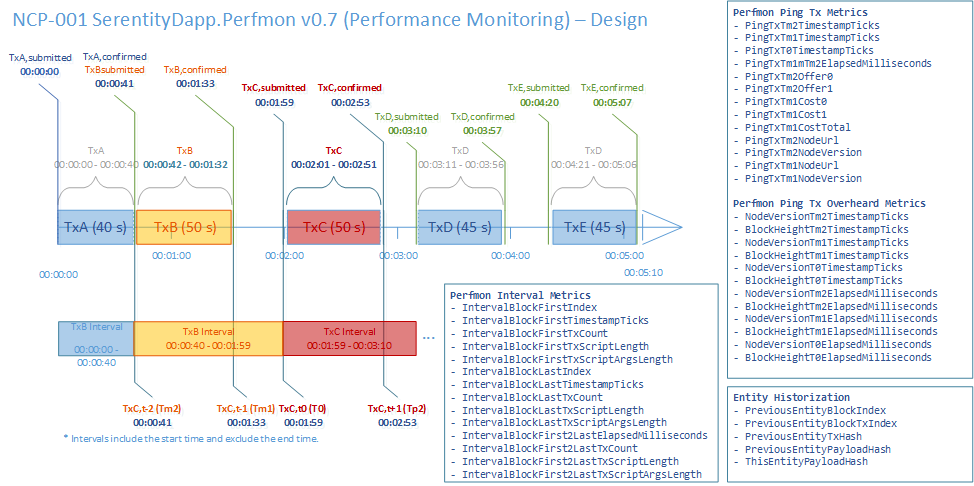 Figure 2. SerentityDapp.Perfmon Data Model – Onchain [blockchain] Performance Monitoring and Recording Example
Figure 2. SerentityDapp.Perfmon Data Model – Onchain [blockchain] Performance Monitoring and Recording Example
Appendix A – SerentityData Field Encoding Details
Supported Data Types

Special Use Cases

Field Buffer Configurations
A. Buffered Values
- 3 Fields = FieldEncodingType + Buffer Length + Buffer Bytes
Use Case 0. 16-bit Buffered Value

Use Case 1. 32-bit Buffered Value
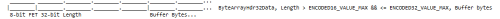
Use Case 2. 64-bit Buffered Value
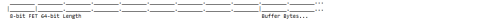
B. Headered Values
- 2 Fields = FieldEncodingType + Value (stored in the 16-bit, 32-bit, or 64-bit Buffer Length field)
Use Case 3. 16-bit Headered Value

Use Case 4. 32-bit Headered Value
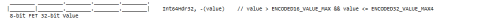
Use Case 5. 64-bit Headered Value
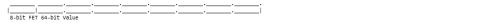
C. Value Constants:
- 1 Field = FieldEncodingType (representing a specific constant value for a particular datatype stored represented an FieldEncodingType op code)
Use Case 6. 8-bit Value Constants
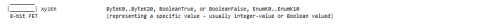
D. Null ByteArrays
Use Case 7. Null-valued reference to a ByteArray

E. Short Length ByteArrays
- 0, 1, 2, 3 bytes in length
Use Case 8. 0-byte ByteArray

Use Case 9. 1-byte ByteArray

Use Case 10. 2-byte Byte Array
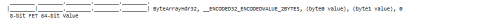
Use Case 11. 3-byte Byte Array

Best regards,
Michael Herman (Toronto/Calgary/Seattle)