Michael Herman (Toronto/Calgary/Seattle)
Hyperonomy Business Blockchain Project / Parallelspace Corporation
December 2018 (completed January 2019)
The purpose of this article is to describe the background and rationale for set of proposed extensions to the UBL 2.2 business document specification to make UBL schema better suited for creating distributed business applications on the blockchain. The proposed set of extensions is referred to as the Universal UBL Extensions.
Hyperonomy Business Blockchain (HBB)
Hyperonomy Business Blockchain (HBB) is a horizontal software applications platform for supporting standards-based, end-to-end, general-purpose, trusted business processing on a global scale.
HBB Standards
A key characteristic of HBB is its reliance on prevailing standards for:
- Business document definitions (business document schema)
- Executable business process definitions (workflow template definitions)
- Digital identity
- General-purpose, programmable blockchain platforms
- Microsoft .NET Core Common Language Runtime (CLR) for virtual machine support
For business document schema, HBB is reliant on the UBL 2.2 (Universal Business Language) specification from the OASIS group.
For defining workflow templates, HBB is reliant on the BPMN 2.0 specification from the Object Management Group (OMG).
For digital identity support, HBB is leveraging:
Hyperledger Indy is a distributed ledger, purpose-built for decentralized identity. It provides tools, libraries, and reusable components for creating and using independent digital identities rooted on blockchains or other distributed ledgers so that they are interoperable across administrative domains, applications, and any other “silo.” [INDY]
Sovrin is a decentralized, global public utility for self-sovereign identity. Self-sovereign means a lifetime portable identity for any person, organization, or thing. It’s a smart identity that everyone can use and feel good about. Having a self-sovereign identity allows the holder to present verifiable credentials in a privacy-safe way. These credentials can represent things as diverse as an airline ticket or a driver’s license. [SOVRIN]
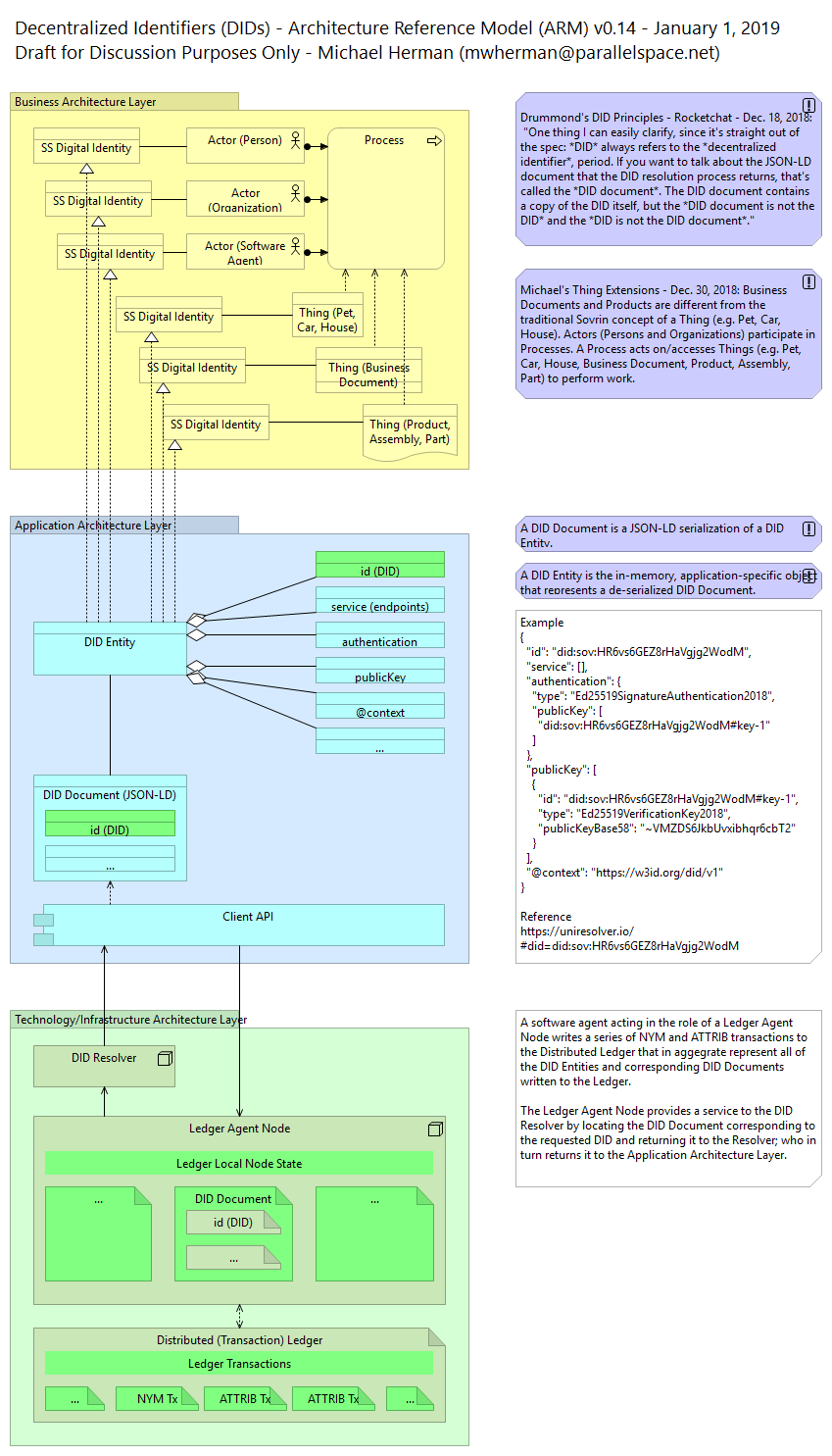
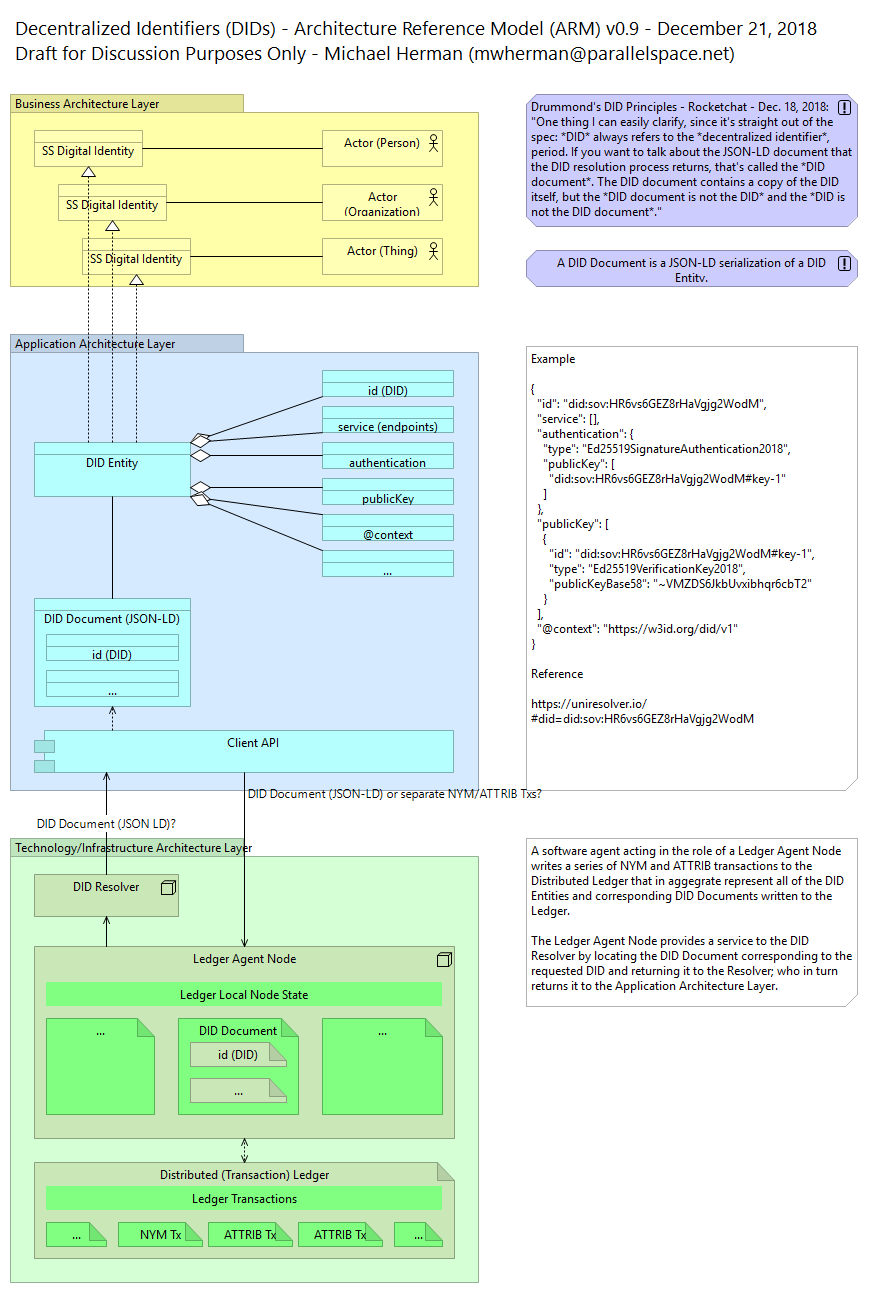
Decentralized Identifiers (DIDs) are a new type of identifier for verifiable, “self-sovereign” digital identity. DIDs are fully under the control of the DID subject, independent from any centralized registry, identity provider, or certificate authority. DIDs are URLs that relate a DID subject to means for trustable interactions with that subject. DIDs resolve to DID Documents — simple documents that describe how to use that specific DID. Each DID Document contains at least three things: cryptographic material, authentication suites, and service endpoints. Cryptographic material combined with authentication suites provide a set of mechanisms to authenticate as the DID subject (e.g., public keys, pseudonymous biometric protocols, etc.). Service endpoints enable trusted interactions with the DID subject. [DID]
[Sovrin] DIDs are created, stored, and used with verifiable claims. [The Sovrin DID Method Specification] covers how these DIDs are managed. It also describes related features of Sovrin of particular interest to DID owners, guardians, and developers. [SOVRINREGISTRY]
For general-purpose, programmable blockchain platform support, HBB is reliant on:
- Stratis Platform for creating highly composable, performant, reliable, and trustworthy custom blockchain platforms, and
- .NET Core Common Language Runtime (CLR) for virtual machine support.
The Stratis Full Node is the engine that powers the Stratis blockchain network. A future-proof and environmentally sustainable consensus protocol, which uses a Proof-Of-Stake (PoS) algorithm, drives each Full Node in the network.
.NET Core is an open-source, general-purpose development platform maintained by Microsoft and the .NET community on GitHub. It’s cross-platform (supporting Windows, macOS, and Linux) and can be used to build device, cloud, and IoT applications.
UBL (Univeral Business Language) Specification
UBL documents are conceived for the purpose of interchange between disparate systems to replace existing trade documents. [HOLMAN1]
UBL is an OASIS specification that defines schema for the 81 most common digital business documents used in supply chain or other online commerce scenarios. The current version of the UBL specification is known as OASIS Universal Business Language version 2.2.
The OASIS Universal Business Language (UBL) is intended to help solve these problems by defining a generic XML interchange format for business documents that can be restricted or extended to meet the requirements of particular industries. Specifically, UBL provides the following [UBL22]:
- A suite of structured business objects and their associated semantics expressed as reusable data components and common business documents.
- A library of XML schemas for reusable data components such as “Address”, “Item”, and “Payment”—the common data elements of everyday business documents.
- A set of XML schemas for common business documents such as “Order”, “Despatch Advice”, and “Invoice” that are constructed from the UBL library components and can be used in generic procurement and transportation contexts.
A key premise of a UBL business document schema is that is complete, standalone, physical representation of the underlying conceptual business or application object. The primary intended purpose of documents conformant with the UBL specification is: electronic document exchange and rendering/printing.
An example receiver application is a print facility that can print any instance of a given UBL document type without having to perform any calculations nor need even know the underlying calculation model.
For the purposes of this article, the following UBL Invoice schema serves as the primary use case. The first page of the UBL Invoice schema looks like the following.
 Figure 1. UBL Invoice Schema Example (Partial)
Figure 1. UBL Invoice Schema Example (Partial)
Each one of the 81 UBL business document schema is a complete, holistic representation of a particular business document (e.g. Invoice, Business Card, Bill of Lading, Order, Request for Quotation, Forwarding Instructions, etc.).
Blockchain Requirements for UBL Business Documents
To represent UBL Business Documents more effectively and more efficiently for use in blockchain-based distributed business applications, the following requirements are important:
- Extremely compact and efficient binary serialization of each entity (and subentity)
- Refactoring/normalization/decomposition of large aggregated entities into small, separate, external subentities (e.g. 5-10 properties per entity) aggregated together by-reference (vs. by-value)
- Re-use of existing (non-fungible) subentities wherever and whenever possible to conserve space and eliminate replication and redundancy wherever and whenever possible
- Secure, permanent, immutable, and trusted (“trusted in a trust-less way”)
Detailed Requirements
Universal UBL (UUBL) is a set of extensions to (or superset of) the UBL 2.2 specification that provides enhanced support for storing and interacting with digital business documents on a digital identity/general-purpose blockchain hybrid applications platform. The UUBL extensions are an answer to the 4 blockchain requirements outlined in the previous section.
Requirement 1. Compact and Efficient Binary Serialization
The requirement for extremely compact and efficient binary serialization of each entity (and subentity) can be fulfilled by various software serialization solutions including SerentityData Variable-byte, Statistically-based Entity Serialization. The SerentityData project can be found on Github. SerentityData is the author’s preferred solution.
Requirement 2. Refactoring/Normalization/Decomposition
By definition the UBL schema definitions are both complete and monolithic – they completely description a particular digital business document in its entirety.
For storage on a blockchain and for direct reference by (a) code running in a traditional smart contact or (b) a new generation of business process workflow templates running directly on a workflow-engine-based virtual machine, the potentially large size of a typical, monolithic UBL business document makes them prohibitively large and prohibitively expense to store, process, and manage on a typical general-purpose programmable blockchain.
A replicable solution for refactoring/normalizing/decomposing each UBL document schema into a collection of subentity schema is need. A solution is proposed by the author in the section Universal UBL: Extensions for the Blockchain.
Requirement 3. Re-use of Subentities
Closely couple with Requirement 2, is the re-use of existing subentities wherever and whenever possible to conserve space and eliminate replication and redundancy wherever and whenever possible. Backing this requirements is the knowledge that most every-day business documents (i.e. those representable by the 81 UBL business document schema) are in fact permanent (subject an organization’s retention policies), immutable, constant-valued documents once they are created. The simplest example is Waybill. Once you have created your (Federal Express or DHL) Waybill, it is a permanent, immutable, constant-valued business document once it has been created and printed (and is not destroyed before it is used).
Given these characteristics of business document in general (and UBL business documents in particular), business documents represent a proper subset of a broader class of entities called Non-Fungible Entities (or NFEs). Another significant class of NFEs are NFTs (Non-Fungible Tokens) …of which, the Ethereum-based CryptoKitties are the penultimate example.
The author’s thesis is that, given business documents stature as NFEs, business documents (and NFEs generally) can be implemented and best managed using the emerging digital identity, in particular the self-sovereign identity (SSI) platforms, that are “coming to market”.
The best platform, from amongst these, in the author’s opinion, is the Hyperledger Indy SSI software platform operated under the stewardship of the Sovrin SSI governance framework.
Requirement 4. Secure, Permanent, Immutable, Trusted and Friction-less
This set of adjectives, plus a few others, symbolize and capture the essence of the intersection between the world of digital business documents and the world (sometimes what I call the religion) of the blockchain.
It is in this intersection between digital business documents and the blockchain that the greatest opportunities lie for supporting friction-less, trusted, standards-based end-to-end business process on a global scale.
Universal UBL: Extensions for the Blockchain
The following sections detail the envisioned solution for each of the above 4 requirements.
Requirement 1. Compact and Efficient Binary Serialization
Solution: SerentityData Variable-Byte Entity Serialization
The goal of the serentitydata project is to provide support the design and development of enterprise and Internet class distributed applications using blockchain technologies. This includes tools and libraries (code), frameworks, how-to documentation, and best practices for enterprise distributed application development. The serentitydata project has a specific focus on the robust and efficient design and management of immutable, historized, and auditable data stored on a blockchain.
TODO
Requirement 2. Refactoring/Normalization/Decomposition
Solution: Refactoring/Normalization/Demposition of UBM 2.2 Schema into Subentities Supported by the W3C DID (Decentralized Identifiers) Specification.
TODO
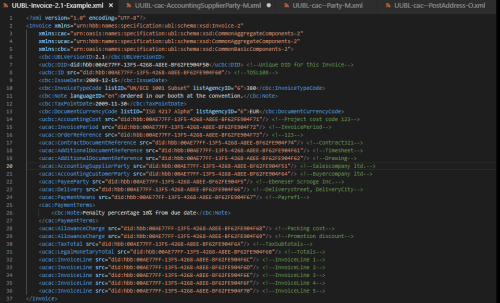 Figure 2. UUBL Invoice Schema Example
Figure 2. UUBL Invoice Schema Example
<ucbc:DID>did:hbb:00AE77FF-13F5-4268-A8EE-BF62FE904F50</ucbc:DID>
TODO
 Figure 3. UUBL Accounting Supplier Party Schema Example
Figure 3. UUBL Accounting Supplier Party Schema Example
<ucbc:DID>did:hbb:00AE77FF-13F5-4268-A8EE-BF62FE904F51</ucbc:DID>
TODO
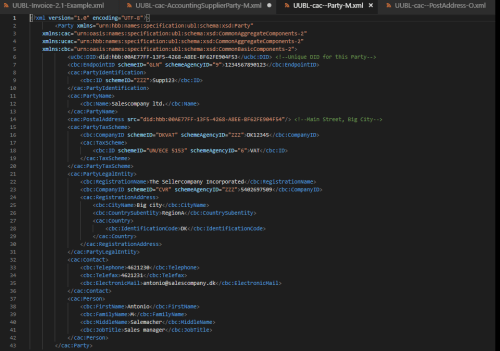 Figure 4. UUBL Party Schema Example
Figure 4. UUBL Party Schema Example
<ucbc:DID>did:hbb:00AE77FF-13F5-4268-A8EE-BF62FE904F53</ucbc:DID>
TODO
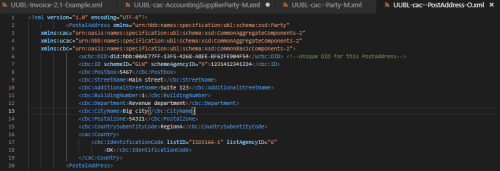 Figure 5. UUBL Postal Address Schema Example
Figure 5. UUBL Postal Address Schema Example
<ucbc:DID>did:hbb:00AE77FF-13F5-4268-A8EE-BF62FE904F54</ucbc:DID>
TODO
Requirement 3. Re-use of Subentities
TODO
Requirement 4. Secure, Permanent, Immutable, Trusted and Friction-less
TODO
TODO
References
Appendix A – Ken Holman – Personal Communication – December 2, 2018 6:38 PM
From: G. Ken Holman <g.ken.holman@gmail.com>
Sent: December 2, 2018 6:38 PM
To: Michael Herman (Parallelspace) <mwherman@parallelspace.net>; William Olders <wolders@xalgorithms.org>; stephenrowlison@gmail.com
Cc: Michael Blanchet <michael.blanchet@gmail.com>; Larry Strickland <lstrickland@dkl.com>
Subject: RE: Introduction by Ken between Michael and Bill – Business Document “Facts”
At 2018-12-02 14:13 +0000, Michael Herman (Parallelspace) wrote:
Ken, Bill and Stephen, I do have a question…
I’ll take on the answer … this is the area of my contribution to the project. I’ve copied Michael and Larry just for their curiosity as I think they’ll find this discussion interesting.
In the <http://docs.oasis-open.org/ubl/os-UBL-2.2/xml/UBL-Invoice-2.1-Example.xml>http://docs.oasis-open.org/ubl/os-UBL-2.2/xml/UBL-Invoice-2.1-Example.xml example, if the value of the <cac:AccountingSupplierParty. cac:PostalAddress component/subelement of an Invoice already exists as a “separate document” somewhere addressable by a URL (or indirectly locatable via a URN)…
* Is there a standard/recommended/off-the-wall way for a specific Invoice to specify the value of AccountingSupplierParty. PostAddress by reference …instead of “by value” (i.e. instead of the long-hand, replicated approach seen in the example)?
No. That isn’t the UBL way. In UBL all values must be manifest and redirecting selective components to copies found elsewhere in the document is not accommodated:
http://docs.oasis-open.org/ubl/os-UBL-2.2/UBL-2.2.html#S-MANIFEST-VALUES
Of course it is necessary to point out to other documents, but there is, say, no XPath or other addressing mechanism built into the UBL serialization to accommodate shared fragmentation.
The UBL committee has been standardizing a semantic library of the business documents and their business objects, and a number of syntactic serializations of those semantics have been specified, XML being the only normative one.
Others in ASN.1 and JSON are available, but they are not normative.
* What does/would an acceptable XML “syntax” look like/might look like?
I would use XPath for addressing a point into an XML document. XPointer would be used if you wanted to point to a range of items found in an XML document. Within an XML document I would use ID/IDREF, but those properties are not available in UBL.
Not many people realize that UBL was not built using XML/XSD, it was built using CCTS. CCTS doesn’t have ID/IDREF concepts.
* Is there standard terminology for referring generally to a subcomponent/subelement of an Invoice (or any other) UBL document? I’m currently using the term Fact to refer to each of the subcomponents (applied recursively if necessary)?
No such terminology is used within the committee … such a concept isn’t leveraged because the syntax is but a straightforward manifest serialization of the semantic components. This is best for interchange between independent platforms and also for things such as rendering.
A recipient of a UBL document should have everything they need without needing to calculate anything … the calculus of the values cannot be assumed to be known by the recipient.
…
UBL documents are conceived for the purpose of interchange between disparate systems to replace existing trade documents.
Appendix B – NEO-NATION and HYPERONOMY BUSINESS BLOCKCHAIN Infographic
TODO

TODO
Appendix C – SerentityData Variable-byte, Statistically-based Entity Serialization
The SerentityData Entity Serialization and Field Encoding library fulfills Blockchain Requirement 1 for the Universal UBL (UUBL) extensions to the UBL 2.2 business document schema specification.
The SerentityData Entity Serialization and Field Encoding description has been moved to its own article located here: SerentityData Variable-byte, Statistically-based Entity Serialization & Field Encoding.
Best regards,
Michael Herman (Toronto/Calgary/Seattle)