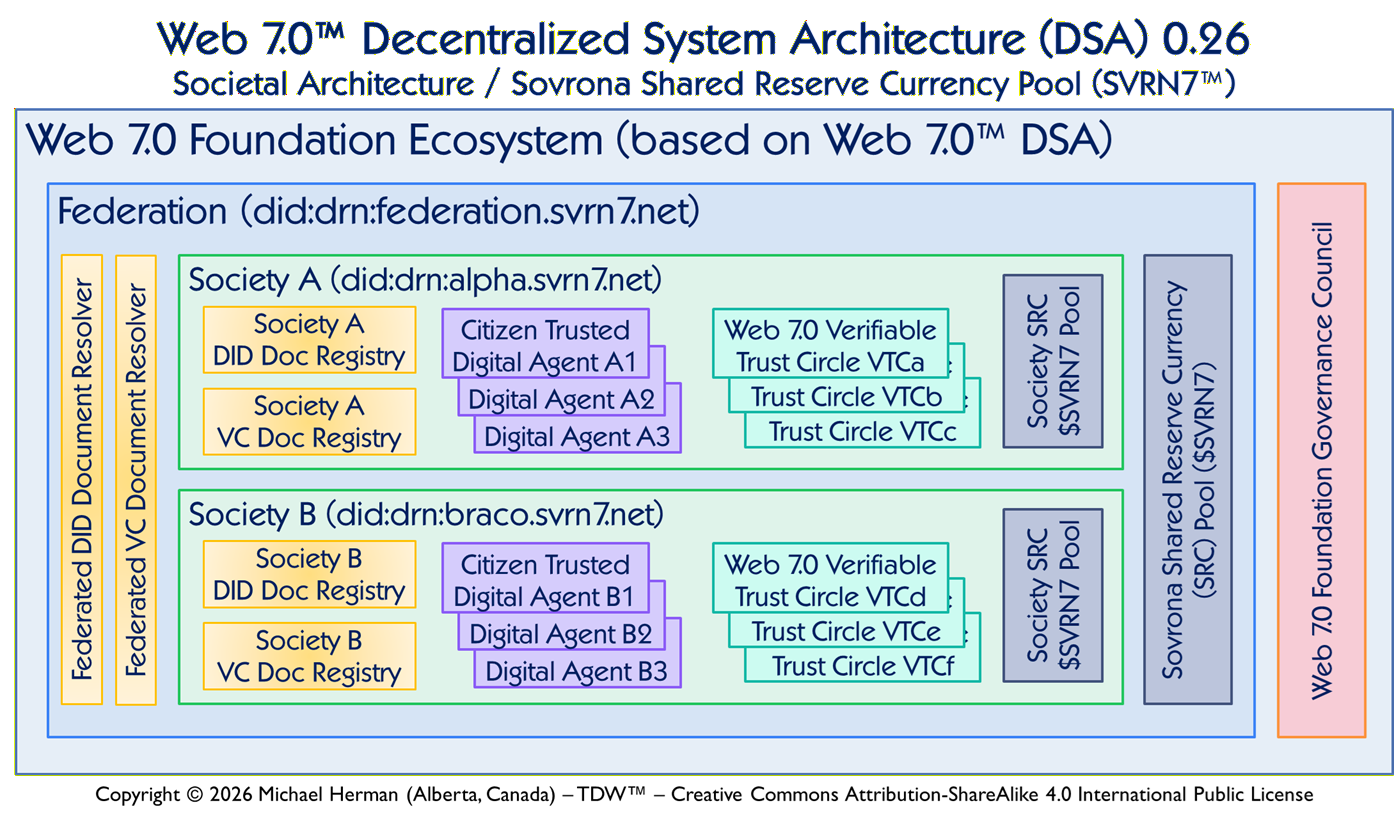
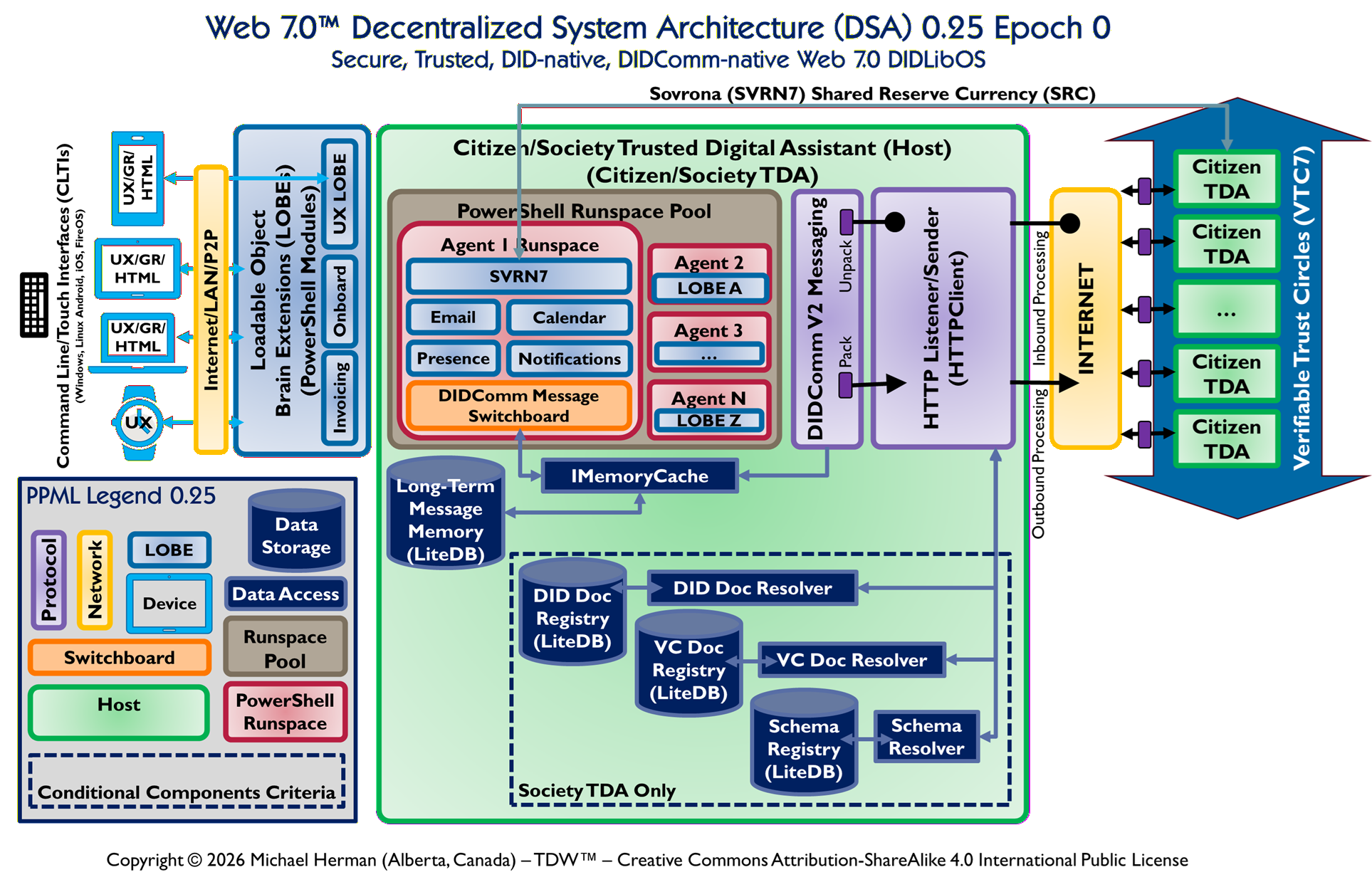
Copyright © 2026 Michael Herman (Bindloss, Alberta, Canada) – Creative Commons Attribution-ShareAlike 4.0 International Public License
Web 7.0™, Web 7.0 Pando™, TDW AgenticOS™, TDW™, Trusted Digital Web™ and Hyperonomy™ are trademarks of the Web 7.0 Foundation. All Rights Reserved.
Abstract
Web 7.0 Pando decentralization fundamentally redistributes economic power from centralized platforms and intermediaries to the network’s participants—individuals, organizations, and autonomous agents. By eliminating recurring monetization models, reducing integration and compliance costs, and enabling new forms of autonomous economic activity, Web 7.0 Pando creates a more resilient, equitable, and innovative digital economy. The transition will be gradual and face obstacles, but the structural economic advantages make this shift both inevitable and transformative.
Key Concepts of Decentralization
Reasoning and Approach
To summarize the key concepts of decentralization, I have drawn directly from the original document, which offers a comprehensive analysis of decentralization’s principles, economic impacts, and technological underpinnings. The summary below distills the most important ideas, supported by examples and explanations to make the concepts actionable and clear for professionals, IT leaders, and organizations considering or designing decentralized systems.
1. Decentralization
- Decentralization is the shift from centralized control of identity, data, compute, and decision-making to a distributed ecosystem. In this model, trust is established through cryptographic proofs, verifiable credentials, and autonomous agents, rather than through institutions or single platforms.
- Example: Instead of a single cloud provider authenticating users and storing data, individuals and organizations interact via open protocols and self-sovereign identities, retaining control over their digital existence.
2. Core Value Unit (CVU)
- The CVU is the minimum standalone unit of value created on a platform. It represents the supply or inventory that gives the platform its value. Without CVUs, a platform has little inherent worth.
- Example: In a decentralized network, a CVU could be a verifiable credential or a digital asset that can be exchanged or used by agents.
3. Economic Advantages of Decentralization
- Sovereign Infrastructure Savings: Users run Trusted Digital Assistants (TDAs) on devices they already own, eliminating recurring cloud fees and reducing reliance on hyperscale data centers.
- Example: Running a TDA on a personal computer or smartphone means no platform fee or per-seat license.
- Decentralized Network Society Economics: As more participants join, the network’s value grows without increasing central infrastructure costs. Value accrues to participants, not platforms.
- Example: Each new agent or organization increases the network’s utility at near-zero marginal cost.
- Zero-Integration Economics: Native communication protocols (like DIDComm) eliminate the need for costly integration layers (APIs, middleware), reducing IT budgets spent on connecting systems.
- Example: Agents communicate directly using shared protocols, removing the need for custom adapters or API gateways.
4. Platform Scale vs. Pipe Scale Business Models
- Pipe Scale (Cloud): Traditional businesses scale by controlling internal resources and delivering value linearly (e.g., factories, cloud providers).
- Platform Scale (Web 7.0 Pando): Decentralized platforms orchestrate value creation across a network, with value accruing to participants rather than intermediaries. Example: Web 7.0 Pando is a platform-scale network where infrastructure is owned by participants, not a central provider.
5. Web 7.0 Pando
- Web 7.0: A unified ecosystem for building resilient, trusted, decentralized systems using decentralized identifiers (DIDs), DIDComm agents, and verifiable credentials.
- Web 7.0 Pando: A modular, biologically-inspired agent platform designed for secure, trusted, open, and resilient coordination of complex systems of work.
6. Benefits of Decentralization
- Trusted Identity and Communication: Use of DIDs and DIDComm for secure, peer-to-peer interactions without central servers.
- Modular, Evolving Architecture: Agents can add new capabilities over time (via LOBEs), allowing systems to adapt and scale flexibly.
- Resilience and Openness: Reduces single points of failure and vendor lock-in, increasing robustness and continuity.
- Fine-Grained Control: Supports multiple digital personas and explicit trust relationships among agents, enabling complex workflows and delegation.
- Interoperability: Standardized protocols enable cross-domain workflows and ecosystem-scale automation.
7. Obstacles and Considerations
- Cold Star Problem: Network effects only emerge as more participants join; initial adoption may be slow.
- Developer Mindset Shift: Requires new architectural thinking focused on identity-first, protocol-driven design.
- Regulatory Uncertainty: Legal frameworks may lag behind technological capabilities, especially regarding identity and compliance.
- Enterprise Inertia: Existing investments in centralized infrastructure may slow the transition.
8. Macro-Economic Shift
- Decentralization transforms digital infrastructure from a recurring cost center (as in cloud computing) into a value-generating, autonomous economy. It enables new forms of economic activity, such as autonomous procurement and machine-to-machine commerce, without proportional increases in human coordination costs.
Summary Table: Centralized vs. Decentralized Models
| Dimension | Centralized Model | Decentralized Model (Web 7.0 Pando) |
|---|---|---|
| Infrastructure Costs | Recurring, centralized | Distributed, edge/peer, lower costs |
| Vendor Lock-In | High | Low, open standards |
| Automation Efficiency | Siloed | Cross-org, autonomous agents |
| Data Ownership | Platform-centric | User/agent-centric, negotiable rights |
| Integration Costs | High (APIs, middleware) | Low (protocol-native interoperability) |
| Scalability | Cost scales with usage | Value scales with participation |
| Security & Compliance | Centralized, costly | Protocol-native, cryptographically secure |
| Lifecycle Longevity | Tied to product cycles | Modular, extendable agents |
Conclusion Decentralization is a paradigm shift that empowers individuals, organizations, and autonomous agents to control their digital identities, data, and interactions. It offers significant economic, operational, and societal benefits by reducing costs, increasing resilience, and enabling new forms of collaboration and value creation. However, realizing these benefits requires overcoming technical, cultural, and regulatory challenges, and adopting new architectural mindsets.
Analyze how Web 7.0 decentralization could reshape traditional cloud power structures
Reasoning and Approach
To analyze how Web 7.0 decentralization could reshape traditional economic power structures, I have synthesized evidence and models from the provided document. The analysis draws on historical parallels, economic frameworks, and specific examples to show how decentralization fundamentally alters who controls value, infrastructure, and decision-making in the digital economy. This response is structured to highlight the mechanisms, impacts, and actionable implications for organizations and society.
How Web 7.0 Decentralization Reshapes Economic Power Structures
1. From Centralized Controlto Distributed Agency
- Traditional Model: Economic power is concentrated in centralized platforms (cloud providers, SaaS vendors, banks, etc.) that control identity, data, compute, and integration. These intermediaries extract recurring fees, enforce vendor lock-in, and capture the majority of value created by users and organizations.
- Web 7.0 Model: Power shifts to the edge—individuals, organizations, and autonomous agents run Trusted Digital Assistants (TDAs) on their own devices. Trust is established cryptographically, not institutionally. Value accrues to participants, not platforms. Example: Instead of paying per-seat licenses and cloud consumption fees, organizations deploy TDAs on existing hardware, eliminating recurring extraction by hyperscalers.
2. Economic Advantages that Undermine Incumbents
- Sovereign Infrastructure Savings: No more recurring cloud bills; infrastructure is owned and operated by users. This breaks the hyperscaler capital cycle and reduces global IT costs.
- Decentralized Network Society Economics: As more participants join, the network’s value grows without increasing central infrastructure costs. Each new agent adds value at near-zero marginal cost, unlike cloud models where costs scale with usage.
- Zero-Integration Economics: Native protocols (like DIDComm) eliminate the need for costly integration layers, reducing IT budgets spent on connecting systems by 50–90%. Example: A mid-sized enterprise could see a five-year economic swing of $53.9M by moving from cloud to Web 7.0 Pando, turning IT from a cost center into a value generator.
3. Disruption of Pipe Scale Bussiness Models by Platform Scale Models
- Pipe Scale (Cloud Model): Value is created linearly—factories, data centers, and platforms extract margin at every step. The provider owns the means of production and controls the flow of value.
- Platform Scale (Web 7.0 Pando): Value is orchestrated across a network. The platform does not own the means of production; instead, value accrues to the network’s participants. The protocol (not a company) is the control plane. Example: In Web 7.0 Pando, the protocol (did:drn) governs the network, not a single vendor. No one can extract rent simply by owning the infrastructure.
4. New Forms of Economic Activity and Market Liquidity
- Autonomous Agents: Agents can negotiate, execute contracts, and participate in autonomous procurement and machine-to-machine commerce, creating new markets and reducing the need for human coordination.
- Data Sovereignty: Data owners can negotiate, license, and monetize their data directly, rather than having platforms extract value without compensation. Example: Autonomous labor markets and service negotiation become possible, with agents acting as economic actors on behalf of individuals or organizations.
5. Reduction of Vendor Lock-In and Increased Competition
- Open Standards: Adoption of decentralized identifiers (DIDs), verifiable credentials, and DIDComm protocols reduces switching costs and increases competitive choice.
- Interoperability: Cross-domain workflows and ecosystem-scale automation become feasible, further eroding the power of traditional gatekeepers.
6. Societaland Regulatory Implications
- Post-Anthropocentric Era: Humans become one class of actor among many (including digital agents), shifting the locus of agency and value creation.
- Regulatory Adaptation: Compliance frameworks will adapt to cryptographic auditability and decentralized trust, just as they did for e-signatures and cloud data residency.
7. Obstacles and Transitional Dynamics
- Cold Start Problem: Network effects require critical mass; early adopters may see limited benefits until the ecosystem grows.
- Enterprise Inertia: Existing investments in centralized infrastructure may slow the transition, but the economic gap will eventually force change.
Summary Table: Economic Power Shift
| Dimension | Traditional Model (Cloud/Centralized) | Web 7.0 Decentralized Model |
|---|---|---|
| Value Capture | Platforms/intermediaries | Participants/agents |
| Infrastructure Ownership | Centralized (cloud/data center) | Distributed (edge/peer devices) |
| Integration Costs | High (APIs, middleware) | Low (protocol-native) |
| Data Ownership | Platform-centric | User/agent-centric |
| Market Liquidity | Limited, platform-controlled | High, agent-driven |
| Vendor Lock-In | High | Low |
| Regulatory Compliance | Central authority | Protocol-native, cryptographically auditable |
Conclusion
Web 7.0 Pando decentralization fundamentally redistributes economic power from centralized platforms and intermediaries to the network’s participants—individuals, organizations, and autonomous agents. By eliminating recurring extraction models, reducing integration and compliance costs, and enabling new forms of autonomous economic activity, Web 7.0 Pando creates a more resilient, equitable, and innovative digital economy. The transition will be gradual and face obstacles, but the structural economic advantages make this shift both inevitable and transformative.