Parchment Programming is an architecture-first software development methodology where a richly annotated visual diagram — the “parchment” — serves as the primary design document and intermediate representation (IR) that an AI coding assistant (like Claude) reads directly to generate correct, idiomatic code.
Rather than translating requirements through layers of prose specifications, the diagram itself encodes stereotypes, interface contracts, project boundaries, data models, and protocol annotations in a form that is simultaneously human-readable and AI-actionable — invented by Michael Herman, Chief Digital Officer, Web 7.0 Foundation. April 2026.
“Change is hard at first, messy in the middle, and gorgeous at the end.” Robin Sharma
The core claim
PPML asserts that a formal diagram is a sufficient specification for code generation — that if a diagram is conformant (every element has a unique label, belongs to exactly one Legend-defined type, and has a derivation rule), then an AI or human can produce the correct implementation from the diagram alone, without additional prose specification.
This is a stronger claim than “diagrams are useful.” It is a claim about sufficiency.
Implication 1: The specification artefact changes
In conventional software development, the specification is prose — a requirements document, a design document, an architecture decision record. The diagram is illustrative, supplementary, and frequently stale.
In PPML, the diagram is the specification. The prose documents (TDA Design, Whitepaper, IETF drafts) are derived from the diagram — they explain and justify it, but they do not override it. If the diagram and the prose conflict, the diagram wins.
This inverts the usual relationship. The implication is that diagram maintenance becomes the primary engineering discipline, not prose authoring. A diagram change is a specification change. An undocumented code change that has no corresponding diagram change violates tractability — it is, by definition, undocumented behaviour.
Implication 2: AI code generation becomes deterministic at the architecture level
The Gap Register and derivation rules give an AI generator a closed-world assumption: every artefact it produces must be traceable to a diagram element instance, and every diagram element instance must produce at least one artefact. There are no open-ended requests like “build me a messaging system.” There are only grounded requests like:
“Derive the artefact for element instance ‘DIDComm Message Switchboard’ of type Switchboard. Derivation rule: one router class, one protocol registry, one outbound queue.”
The AI cannot invent artefact names that do not appear in the diagram. It cannot silently add dependencies. It cannot reorganise the architecture. This is not a limitation — it is the point. Creativity is in the diagram; precision is in the derivation.
The practical implication is that AI code generation quality is bounded below by the quality of the diagram, not by the quality of the prompt. A well-formed PPML diagram produces consistent, reproducible results across AI sessions and across AI models. A poorly-formed diagram produces inconsistent results regardless of prompt quality.
Implication 3: The change process becomes explicit
Conventional development has no formal mechanism for distinguishing “we changed the architecture” from “we changed an implementation detail.” Both look like pull requests.
PPML enforces a distinction. Within an epoch, the Legend is frozen and element types cannot change. A new component requires a diagram change, which requires a version increment (DSA 0.19 → DSA 0.24), which requires a Gap Register update. Architectural changes are visible as diagram changes.
Implementation changes — refactoring within a derived artefact, performance tuning, bug fixes — do not require diagram changes. The boundary between architecture and implementation is drawn precisely at the diagram boundary.
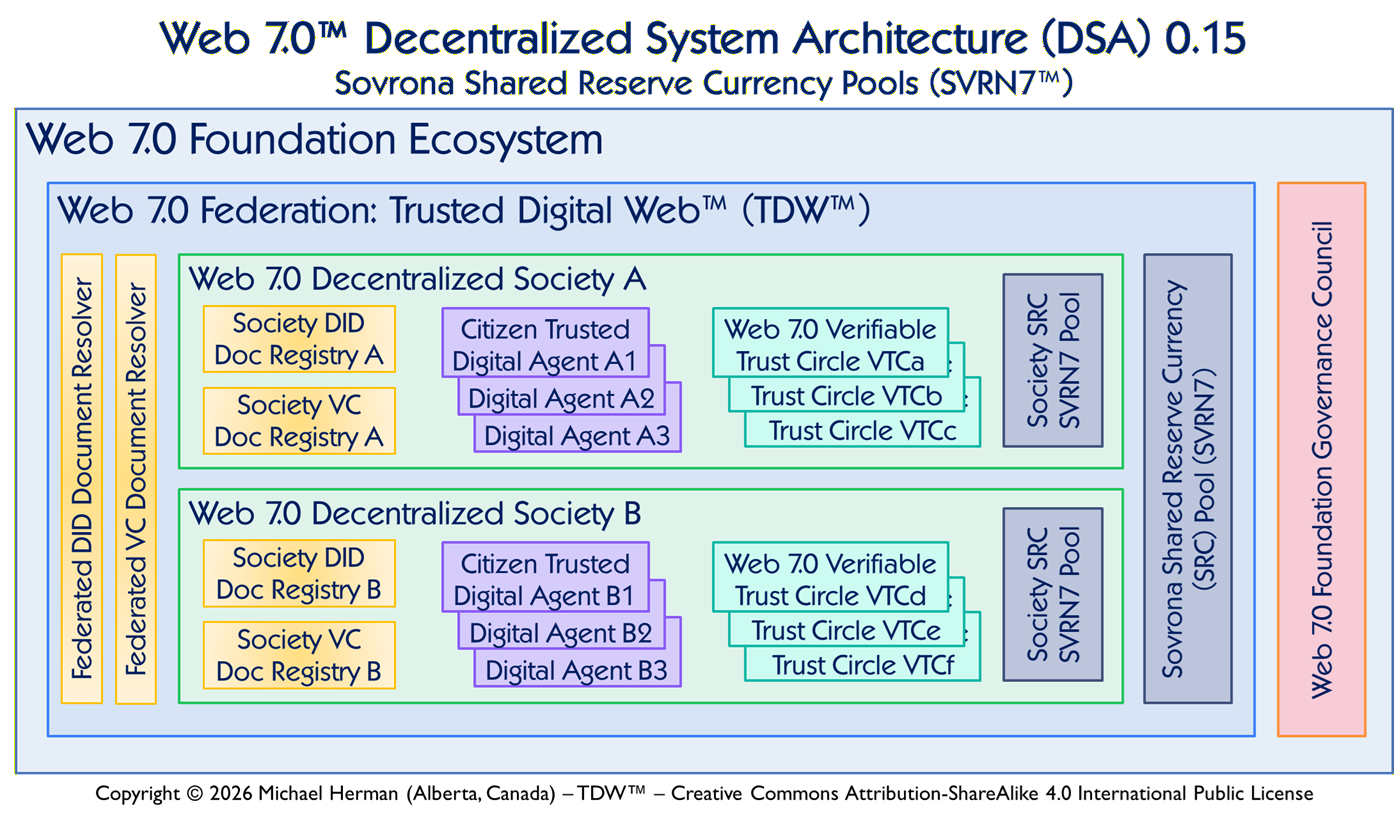
This has governance implications for a project like SVRN7: the diagram is the governance document. Epoch transitions are diagram changes. New protocol support is a LOBE addition to the diagram. The Foundation controls the diagram; contributors derive from it.
Implication 4: Testing becomes traceable to the diagram
Every test should be traceable to a diagram element instance, just as every artefact is. If a test has no corresponding diagram element, it is either testing an undocumented artefact (a tractability violation) or testing implementation detail that should not be exposed.
In practice this means the Gap Register can include test coverage as a property. “Element instance X has derivation artefact Y, test coverage Z.” Missing test coverage is a Gap Register entry, not a matter of developer discretion.
In conventional projects, diagrams go stale because they are maintained separately from code. PPML makes diagram staleness a first-class defect: if the diagram is stale, the Gap Register is wrong, and any AI-generated code derived from it will be wrong.
The practical discipline is: diagram first, always. Before writing any new C# class, PowerShell module, or LOBE descriptor, the diagram must already contain the corresponding element instance. This is why every source file in the SVRN7 solution carries a derivation trace comment:
That comment is not decorative — it is the traceability link. If that element instance no longer appears in the diagram, the file is either stale or the diagram is stale. One of them must change.
Implication 6: The methodology scales with AI capability
This is the forward-looking implication. In the current epoch, an AI (Claude, in this case) assists with derivation — producing C# from a diagram element description, writing PowerShell cmdlets from a LOBE derivation rule, generating IETF draft sections from an architectural decision. The human holds the diagram and reviews the derivations.
As AI capability increases, the human’s role shifts further toward diagram authorship and review. The diagram becomes the interface between human architectural intent and AI implementation. The better the diagram grammar (the PPML Legend), the more precisely an AI can translate intent into code.
The LOBE descriptor format — with its MCP-aligned inputSchema/outputSchema, compositionHints, and useCases — is an early instance of this. It is a machine-readable diagram-derived artefact that an AI can use to reason about composability without reading the PowerShell source. The diagram element (LOBE) produces both the code artefact (.psm1) and the AI legibility artefact (.lobe.json). Both are derived from the same diagram element. The AI consuming the .lobe.json is one step removed from reading the diagram directly.
The next step — which PPML explicitly anticipates but does not yet implement — is an AI that reads the diagram directly and performs the full derivation without a human intermediary for routine changes.
The honest limitation
PPML is most effective for component-level architecture — what components exist, how they relate, what they are responsible for. It is less effective for algorithmic detail. The 8-step transfer validator, the Merkle log construction, the DIDComm pack/unpack sequence — these require prose specification or pseudocode. The diagram says “TransferValidator exists and implements ITransferValidator.” It does not say how step 4 (nonce replay detection) works.
This is not a flaw in PPML — it is a boundary condition. PPML governs architecture. Algorithms require their own specification discipline (IETF drafts, pseudocode, formal methods). The two disciplines are complementary: PPML tells you what to build and how it connects; the algorithm specification tells you how each component behaves internally.
Summary
PPML’s implications reduce to one structural claim: the diagram is the primary engineering artefact, and all other artefacts are derived from it. The implications — specification inversion, deterministic AI generation, explicit change governance, traceable testing, structural documentation freshness, and scalability with AI capability — all follow from that single claim. Whether that claim is valuable depends entirely on whether the diagram can be kept accurate and complete, which is a discipline question, not a tool question.
Parchment Programming is an architecture-first software development methodology where a richly annotated visual diagram — the “parchment” — serves as the primary design document and intermediate representation (IR) that an AI coding assistant (like Claude) reads directly to generate correct, idiomatic code.
Rather than translating requirements through layers of prose specifications, the diagram itself encodes stereotypes, interface contracts, project boundaries, data models, and protocol annotations in a form that is simultaneously human-readable and AI-actionable — invented by Michael Herman, Chief Digital Officer, Web 7.0 Foundation. April 2026.
What folows is a structured comparison grounded in what Parchment Programming actually requires from a visual language.
What Parchment Programming Demands from a Visual Language
A PP visual language must do five things simultaneously:
Encode stereotypes that map to C# constructs («HostedService», «Repository», «Middleware»)
Annotate arrows with interface contracts and protocols
Be readable by Claude without a dedicated parser
Be authorable by a human architect without excessive tool friction
The Candidates
What You’re Using Now — Custom Annotated Box Diagrams
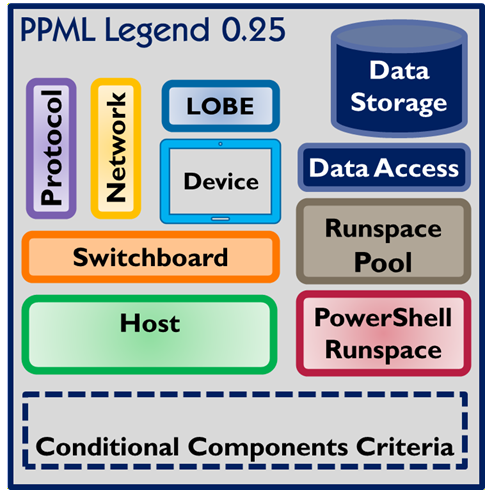
Verdict: Best starting point, needs formalization
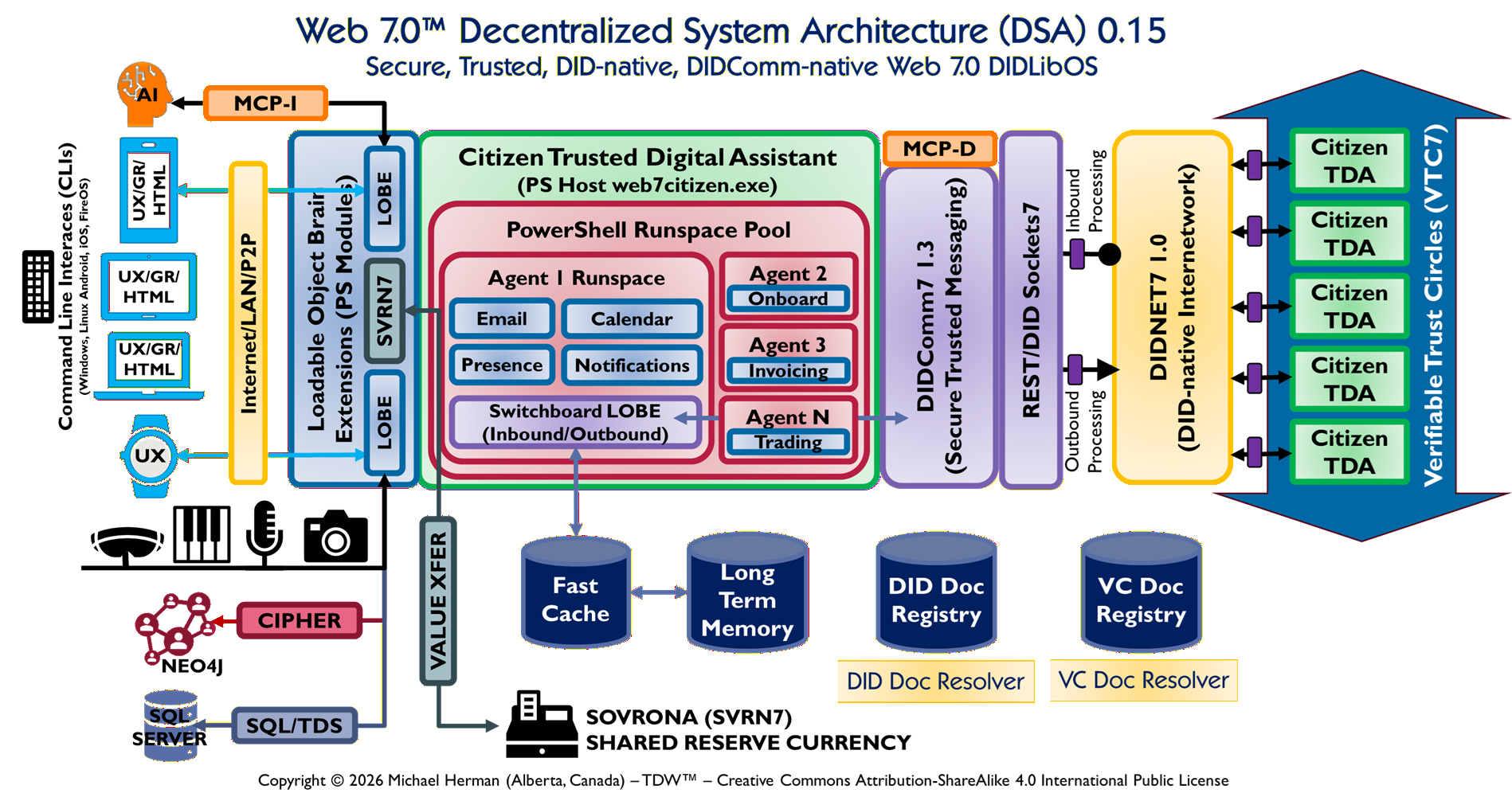
Your DSA 0.16 diagram is already doing most things right. The color-coded regions, nested containment, labeled arrows, and protocol annotations are all PP-native. The gap is the absence of a formal stereotype vocabulary — Claude has to infer too much. A thin layer of formalization on top of your current style would make it the strongest option.
✅ Human-readable and visually expressive
✅ Claude can read it directly from an image
✅ Nested containment naturally maps to project boundaries
✅ No tool lock-in
❌ No enforced stereotype vocabulary (yet)
❌ Not machine-parseable without a defined grammar
ArchiMate
Verdict: Strong for enterprise/governance layers, wrong grain for C# code generation
ArchiMate excels at the motivation, strategy, and technology layers — it’s designed to show why a system exists and how it relates to business capabilities. Its stereotype vocabulary («ApplicationComponent», «ApplicationService», «DataObject») is too coarse and business-oriented to drive C# interface/class generation directly.
❌ No concept of IHostedService, «Middleware», DI registration
❌ Stereotypes don’t map cleanly to .NET constructs
❌ Claude reads ArchiMate OEF XML, not the visual — loses the PP directness
❌ Too ceremonial for rapid iteration
UML (Component + Class Diagrams)
Verdict: Closest formal precedent, but too verbose for PP
UML Component Diagrams handle bounded contexts and interfaces well. Class diagrams handle stereotypes («interface», «abstract», «service») and are the closest existing formal language to what PP needs. The problem is UML requires two diagram types to do what PP does in one, and the tooling (Enterprise Architect, Lucidchart) adds friction.
✅ «stereotype» notation is native and Claude knows it well
✅ Interface contracts expressible formally
✅ Claude has deep UML training — reads it very accurately
❌ Component + Class diagrams needed together — no single PP view
❌ No built-in protocol/messaging annotation
❌ Verbose; loses the architecture-at-a-glance quality
Verdict: Best structured alternative, but prose-first not diagram-first
C4 has the right levels (Context → Container → Component → Code) and maps well to .NET projects at the Container level. But it’s DSL-authored (Structurizr) or prose-prompted — the diagram is generated, not hand-crafted. That inverts the PP authoring model.
✅ Container level maps naturally to .csproj boundaries
✅ Component level maps to interfaces/classes
✅ Claude knows C4 well
❌ Diagram-as-code means the spec is the DSL text, not the visual
❌ No stereotype vocabulary for .NET-specific constructs
❌ Loses PP’s architecture-first visual authoring
The Recommendation
Define PP-Native Notation as a thin formal layer on top of your current style
Rather than adopting an existing language wholesale, Parchment Programming should define its own visual grammar — lightweight enough to author in any diagramming tool (PowerPoint, draw.io, Visio), rich enough to be unambiguously Claude-actionable. Concretely:
Borrow from UML: the «stereotype» notation — Claude reads it natively and it maps directly to C# constructs:
«HostedService» → : IHostedService, registered in DI
«Middleware» → app.Use...() in Program.cs
«Repository» → IRepository<T> pattern
«Router» → internal dispatch, no HTTP
«Gateway» → external system boundary
«PSModule» → PowerShell Loadable Brain Extension
«Factory» → Factory pattern, DI-registered
Borrow from ArchiMate: the nested containment model for bounded contexts — color regions = project boundaries.
Keep your current style: box shapes, color coding, directional arrows with protocol labels.
Add one new convention: every arrow carries [InterfaceName] in small text alongside the protocol label.
Summary Table
Language
Stereotype Support
.NET Mapping
Claude Readability
Authoring Ease
PP Fit
PP-Native (your style + UML stereotypes)
✅ Defined by you
✅ Direct
✅ Excellent
✅ High
⭐ Best
UML Component+Class
✅ Formal
✅ Good
✅ Excellent
⚠️ Verbose
2nd
C4 Model
⚠️ Coarse
✅ Good
✅ Good
⚠️ DSL-first
3rd
ArchiMate
✅ Formal
❌ Too coarse
✅ Good
⚠️ Ceremonial
4th
Mermaid/D2
❌ None
❌ None
✅ Excellent
✅ High
Last
Bottom line: Your current visual style is the right foundation — it just needs the «stereotype» convention from UML and the [InterfaceName] arrow annotation added as formal PP conventions. That makes it superior to any existing language for the specific job of AI-driven C#/.NET code generation.
Parchment Programming is an architecture-first software development methodology where a richly annotated visual diagram — the “parchment” — serves as the primary design document and intermediate representation (IR) that an AI coding assistant (like Claude) reads directly to generate correct, idiomatic code.
Rather than translating requirements through layers of prose specifications, the diagram itself encodes stereotypes, interface contracts, project boundaries, data models, and protocol annotations in a form that is simultaneously human-readable and AI-actionable — invented by Michael Herman, Chief Digital Officer, Web 7.0 Foundation. April 2026.
How Claude Processes Parchment Inputs
Claude receives a conversation context containing images + text. The key facts:
Claude can see a diagram image and reason about it
Claude can read structured Markdown/text with full fidelity
Claude cannot cross-reference between an image region and a text table by coordinate — it reasons about both holistically
Therefore: the diagram handles spatial/structural truth; the companion document handles behavioral/contractual truth
This is actually a clean separation of concerns.
The Recommended Hybrid Architecture
ParchmentSpec_DSA_0.16_Epoch0/
├── diagram.png ← the visual (spatial truth)
├── PARCHMENT.md ← master spec (behavioral truth)
└── schemas/
├── didcomm-envelope.json
├── did-doc.json
└── vc-doc.json
The PARCHMENT.md is the primary AI coding input. The diagram is embedded in it — not appended, not separate — embedded at the top, so Claude sees it as the structural foundation before reading the annotations.
- CIPHER algorithm selection: Ed25519 only or negotiated?
## 9. Excluded from AI Generation
- SVRN7 SRC transaction signing
- NEO4J CIPHER graph schema
- VTC7 federation handshake
Why This Works Best With Claude
The critical insight is section 8 — the Open Questions Log. Claude’s failure mode when coding from underspecified inputs is silent invention. Explicitly naming unknowns instructs Claude to emit // TODO: [OPEN QUESTION - LOBE hot-reload policy] rather than inventing an answer.
Three additional Claude-specific optimizations:
1. Use the diagram as a spatial index, not a spec. In your prompt to Claude, say: “The diagram shows containment and flow. The PARCHMENT.md sections 3–9 are authoritative for all behavioral details. Where they conflict, the Markdown wins.” This prevents Claude from over-reading visual ambiguities.
2. Keep sections 3–7 machine-parseable. Claude handles Markdown tables extremely well as structured input. Avoid prose paragraphs for anything that should drive code generation — tables and bullet lists are more reliably parsed into code structure.
3. Submit diagram + PARCHMENT.md together in every coding prompt. Claude has no persistent memory of previous sessions, so the full parchment must be present each time. The compact table format makes this token-efficient.
The Better Approach You Asked About
There is one additional technique worth considering: annotated diagram variants. Rather than modifying the master diagram, you maintain lightweight overlay versions for specific concerns:
diagram.png ← master (as-is, no changes)
diagram-trust-zones.png ← same diagram + colored zone overlays
diagram-dataflow.png ← same diagram + numbered flow sequence
These are fast to produce (PowerPoint/draw.io layer toggles) and can be embedded in targeted sections of PARCHMENT.md. Claude sees each as a focused lens on the same architecture without the master diagram becoming cluttered.
Bottom Line
Approach
Verdict
Annotate the diagram itself
Avoid — clutters the visual, hard to maintain
Companion Markdown only (no diagram)
Suboptimal — loses spatial/structural truth
Diagram embedded in PARCHMENT.md
✅ Recommended
Diagram + overlay variants + PARCHMENT.md
✅ Optimal for complex systems
The PARCHMENT.md is the intermediate representation. The diagram is its most important section — but only one section.
Parchment Programming is an architecture-first software development methodology where a richly annotated visual diagram — the “parchment” — serves as the primary design document and intermediate representation (IR) that an AI coding assistant (like Claude) reads directly to generate correct, idiomatic code.
Rather than translating requirements through layers of prose specifications, the diagram itself encodes stereotypes, interface contracts, project boundaries, data models, and protocol annotations in a form that is simultaneously human-readable and AI-actionable — invented by Michael Herman, Chief Digital Officer, Web 7.0 Foundation. April 2026.
Claude Prompt
How can this #ParchmentProgrammimg diagram be optimized as a design document/intermediate representation specification for a Claude AI-coded C#/.NET 8 software system?
Great diagram — this is a strong architectural foundation. Let me give you a structured analysis of how to optimize it as a ParchmentProgramming IR spec for Claude-coded C#/.NET 8.
What’s Already Working Well
The diagram communicates bounded contexts, data stores, messaging topology, and external federation clearly enough that Claude can infer C# project/namespace boundaries. That’s the core value of ParchmentProgramming: the diagram is the spec.
Optimization Recommendations
1. Add Stereotype/Type Annotations to Every Box
Right now Claude must infer whether a box is an interface, class, service, background worker, etc. Make it explicit:
Has anyone conceived of anything at all similar to Parchment Programming?
There are adjacent ideas in the ecosystem, but nothing that matches Parchment Programming’s specific inversion. Here’s the honest landscape:
Parchment Programming: What Exists — and Why It’s Different
Diagram-as-Code tools (Structurizr/C4, D2, PlantUML, Mermaid) go in the opposite direction — you write text and a diagram is generated, with elements automatically positioned by a layout engine. The diagram is the output, not the primary authoring artifact.
Swark / Claude Code go code → diagram — based on retrieved source files, an LLM builds a prompt to generate an architecture diagram as documentation. Again, the diagram is a byproduct of code, not a driver of it.
Eraser / DiagramGPT go natural language → diagram → code, but the diagram is an ephemeral intermediate — working with an LLM to create a fleshed-out diagram prompt is the workflow, not treating the diagram itself as an authoritative, annotated specification.
Structurizr comes closest in spirit — AI agents and LLMs excel at generating text, and Structurizr’s model-based consistency makes it a good choice for teams looking to generate C4 model diagrams with AI — but it’s DSL-first, not diagram-first, and carries no notion of the diagram encoding interface contracts or project boundary stereotypes for code generation.
Academic reverse-engineering approaches go code → diagram using LLMs, recovering both static and behavioral architectural views by extracting component diagrams and generating state machine diagrams to model component behavior. Still the wrong direction.
What Makes Parchment Programming Genuinely Novel
The field has thoroughly explored code → diagram and text → diagram → code. What nobody has formalized is the specific claim Parchment Programming makes:
The richly annotated visual diagram is the primary authoritative artifact — encoding stereotypes, interface contracts, project boundaries, and protocol modes — such that an AI reads it directly as an intermediate representation to generate correct, idiomatic code without a prose specification intermediary.
The key differentiators are:
(1) the diagram is architecture-first and human-authored, not AI-generated;
(2) it carries code-generation semantics embedded in the visual (stereotypes, interface names, DI boundaries); and
(3) it replaces the prose spec entirely rather than supplementing it.
That combination — as a named, intentional methodology — appears to be original to you.
Parchment Programming is an architecture-first software development methodology where a richly annotated visual diagram — the “parchment” — serves as the primary design document and intermediate representation (IR) that an AI coding assistant (like Claude) reads directly to generate correct, idiomatic code.
Rather than translating requirements through layers of prose specifications, the diagram itself encodes stereotypes, interface contracts, project boundaries, data models, and protocol annotations in a form that is simultaneously human-readable and AI-actionable — invented by Michael Herman, Chief Digital Officer, Web 7.0 Foundation. April 2026.
This article presents a structured analysis as well as the key optimization dimensions for diagrams used for Parchment Programming.
How can this #ParchmentProgrammimg diagram be optimized as a design document/intermediate representation specification for an AI-coded software system?
What the Diagram Does Well Already
Layered containment (TDA > Runspace Pool > Agent Runspaces) maps cleanly to class/module hierarchies an AI can scaffold
Named protocols (DIDComm V2, REST/HTTP, SQL/TDS, CIPHER) give an AI concrete interface contracts to target
Directional flow (Inbound Unpack → Switchboard → Outbound Pack) implies a pipeline pattern the AI can instantiate
Multiplicity hints (Agent 1…N, Citizen TDA ×4+) signal collection types and polymorphism requirements
The Six Optimization Gaps
1. Missing Cardinality & Lifecycle Annotations
The diagram shows what exists but not how many or when. An AI needs to know:
Is the Runspace Pool fixed-size or elastic? Min/max pool size?
Are LOBEs loaded at startup or on-demand?
Do Agent Runspaces share state or are they fully isolated?
Fix: Add a small Component Fact Table inset — one row per major component with columns: multiplicity | lifecycle (singleton/transient/pooled) | owns-state? | thread-safe?
2. Interface Contracts Are Implied, Not Declared
The AI sees “DIDComm/HTTP Listener” but has no method signatures, message schemas, or error contracts. The connector arrows carry no payload type.
Fix: Add stereotypes on connectors — e.g., label each arrow with «sends: DIDCommEnvelope» or «protocol: REST/JSON-LD». Even a short legend table mapping each arrow color/style to a message type and schema reference would let an AI generate correct interface stubs.
3. No Error / Exceptional Flow Representation
The diagram shows the happy path only. An AI coding from this will produce brittle code with no fault boundaries.
Fix: Add a Fault Boundary overlay — dashed red borders around components that must implement retry/circuit-breaker, and a small failure-mode legend: CIPHER fail → ?, LiteDB unavailable → ?, DIDComm unpack error → ?
4. Data Model is Storage-only, Schema-less
Four LiteDB stores are shown (Fast Cache, Long-Term Message Memory, DID Doc Registry, VC Doc Registry) but with no schema, key structure, TTL, or consistency requirements called out. The AI will invent schemas.
Fix: Add a Data Contract sidebar with one mini-schema per store — just the primary key pattern, top 3–5 fields, and TTL/eviction policy. For DID Doc Registry and VC Doc Registry this is especially important since did:drn and VC structure are normative.
5. Security / Trust Boundary is Structural but Not Behavioral
The CIPHER block and VTC7 boundary appear but the enforcement rules are invisible. When does encryption apply? Who authorizes a new LOBE load? What validates a VC before it enters the Runspace?
Fix: Add a Trust Boundary Annotation layer — color-coded zones (already partially present with the green/purple/yellow regions) with an explicit legend: green = TDA-internal trust, purple = DIDComm-authenticated, yellow = internet-untrusted. Add one-line policy statements per zone boundary crossing.
6. No Prompt-Injection Anchors (the Core #ParchmentProgramming Gap)
This is the critical one for AI-coded systems. The diagram has no named generation targets — no indication of which boxes map to which code artifacts, which interfaces must be hand-authored vs. AI-generated, or what the acceptance criteria are per component.
Fix: Add an AI Codegen Manifest — a table in the document (not necessarily in the diagram itself) with columns:
Component
Target Artifact
Generation Mode
Acceptance Test
PowerShell Runspace Pool
RunspacePoolManager.cs
AI-generated
Pool min/max respected
DIDComm Message Switchboard
DIDCommSwitchboard.cs
AI-scaffolded + hand-completed
Routes all registered message types
LOBE loader
LobeLoader.cs
AI-generated
Module isolation verified
SVRN7 XFER
Svrn7XferService.cs
Hand-authored
SVRN7 SRC ledger integrity
Structural Recommendations for the Document Form
If this diagram is the centerpiece of a Parchment Programming spec document, the optimal surrounding structure is:
1. System Identity Block ← version, epoch, DID of this spec doc itself
2. This Architecture Diagram ← with the fixes above applied
4. Connector / Protocol Index ← arrow → schema/interface mapping
5. Data Contract Sidebar ← per-store mini-schemas
6. Trust Boundary Policy ← zone rules in natural language
7. AI Codegen Manifest ← component → artifact → test mapping
8. Open Questions Log ← explicit unknowns the AI must not invent
The Open Questions Log (item 8) is underrated — explicitly flagging what is unspecified prevents an AI from silently hallucinating design decisions into generated code.
Quick-Win Priority Order
If you’re iterating the diagram itself (not the surrounding document), the highest-leverage single changes are:
Label every connector arrow with protocol + payload type — eliminates the largest source of AI ambiguity
Add lifecycle annotations to the LOBE and Agent Runspace boxes
Explicitly mark the DIDComm V2 trust boundary as the inbound validation gate
The diagram is already well above average as an AI coding input. These additions would move it from architectural sketch to generatable specification.
Has anyone conceived of anything at all similar to Parchment Programming?
There are adjacent ideas in the ecosystem, but nothing that matches Parchment Programming’s specific inversion. Here’s the honest landscape:
Parchment Programming: What Exists — and Why It’s Different
Diagram-as-Code tools (Structurizr/C4, D2, PlantUML, Mermaid) go in the opposite direction — you write text and a diagram is generated, with elements automatically positioned by a layout engine. The diagram is the output, not the primary authoring artifact.
Swark / Claude Code go code → diagram — based on retrieved source files, an LLM builds a prompt to generate an architecture diagram as documentation. Again, the diagram is a byproduct of code, not a driver of it.
Eraser / DiagramGPT go natural language → diagram → code, but the diagram is an ephemeral intermediate — working with an LLM to create a fleshed-out diagram prompt is the workflow, not treating the diagram itself as an authoritative, annotated specification.
Structurizr comes closest in spirit — AI agents and LLMs excel at generating text, and Structurizr’s model-based consistency makes it a good choice for teams looking to generate C4 model diagrams with AI — but it’s DSL-first, not diagram-first, and carries no notion of the diagram encoding interface contracts or project boundary stereotypes for code generation.
Academic reverse-engineering approaches go code → diagram using LLMs, recovering both static and behavioral architectural views by extracting component diagrams and generating state machine diagrams to model component behavior. Still the wrong direction.
What Makes Parchment Programming Genuinely Novel
The field has thoroughly explored code → diagram and text → diagram → code. What nobody has formalized is the specific claim Parchment Programming makes:
The richly annotated visual diagram is the primary authoritative artifact — encoding stereotypes, interface contracts, project boundaries, and protocol modes — such that an AI reads it directly as an intermediate representation to generate correct, idiomatic code without a prose specification intermediary.
The key differentiators are: (1) the diagram is architecture-first and human-authored, not AI-generated; (2) it carries code-generation semantics embedded in the visual (stereotypes, interface names, DI boundaries); and (3) it replaces the prose spec entirely rather than supplementing it. That combination — as a named, intentional methodology — appears to be original to you.
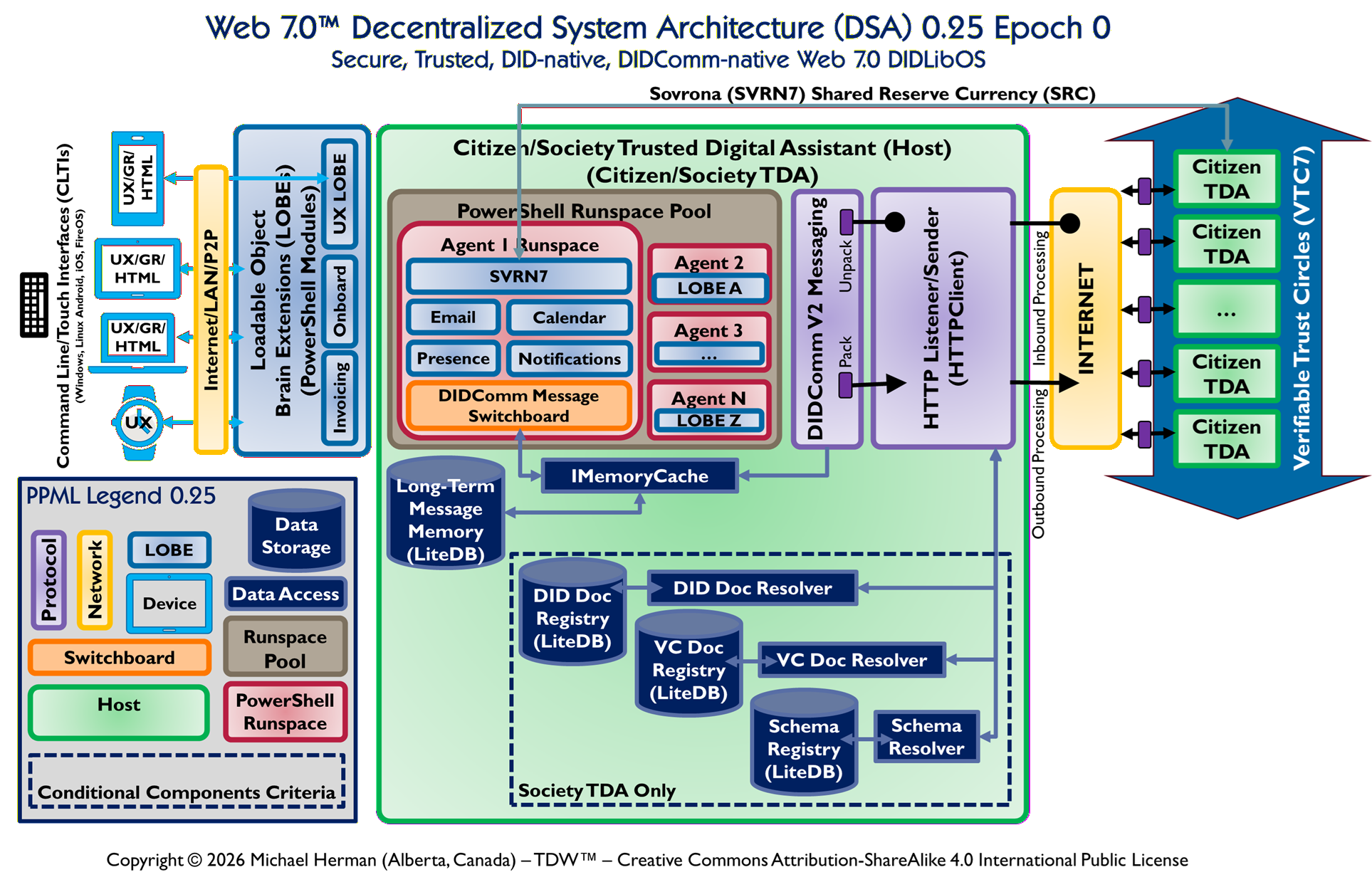
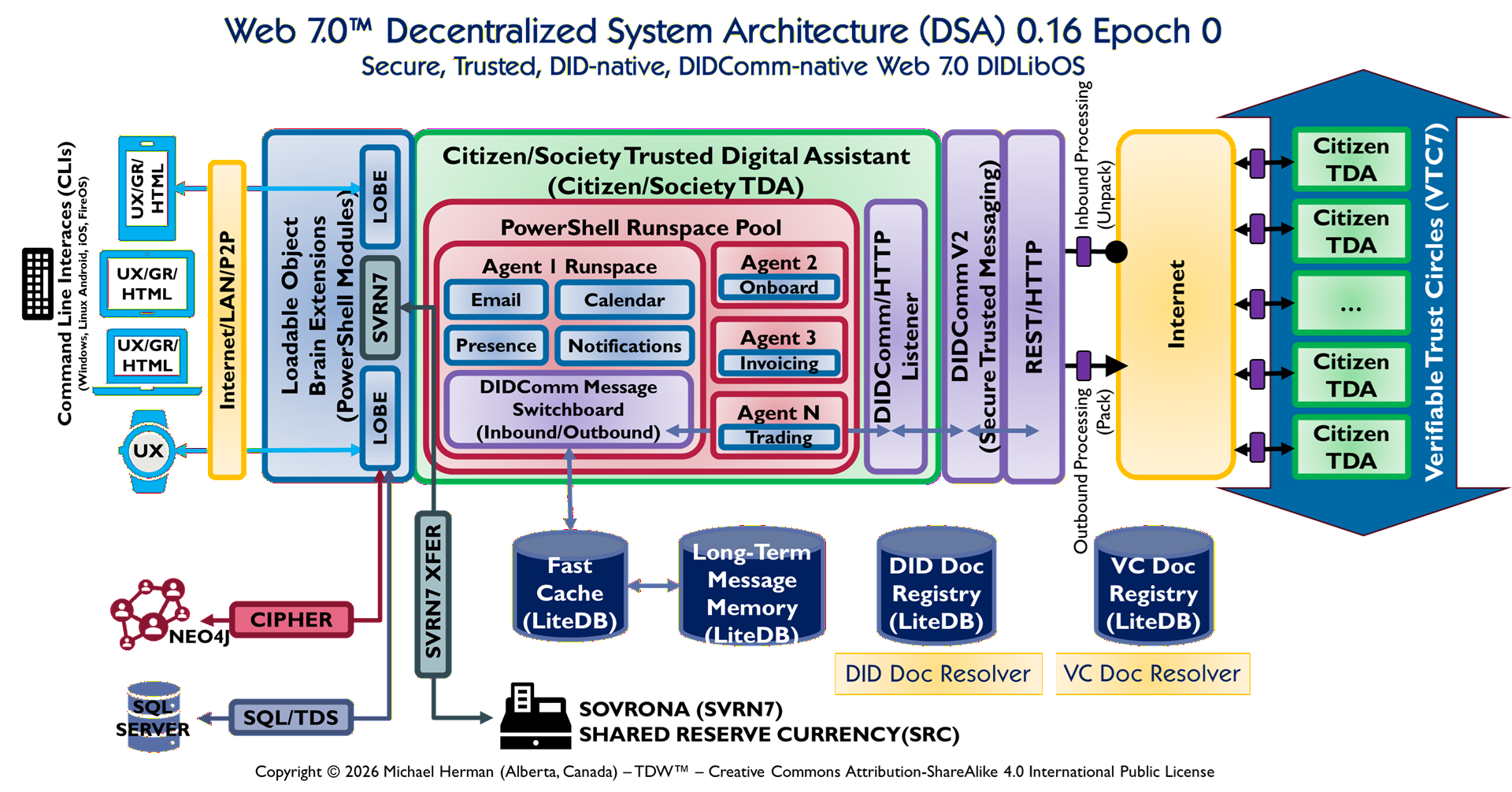
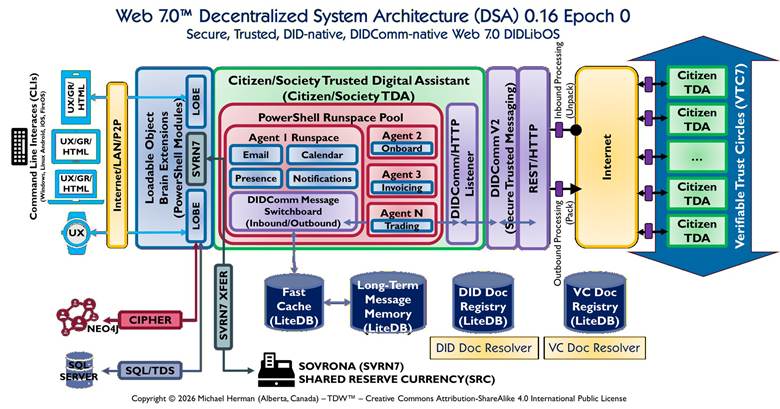
This document analyses the Web 7.0™ Decentralized System Architecture (DSA) v0.16 diagram and derives a complete design specification for the Citizen/Society Trusted Digital Assistant (TDA) — the sovereign, DID-native, DIDComm-native runtime at the centre of the Web 7.0 ecosystem.
The DSA diagram, captioned “Safe, Secure, Trusted, DID-native, DIDComm-native Web 7.0 DIDLibOS” and scoped to Epoch 0 (Endowment Phase), shows seven structural zones. This document reads each zone precisely, maps every component to the existing SVRN7 v0.7.1 C# library, and then specifies the four-layer TDA design: the DIDComm/HTTP Listener, the PowerShell Runspace Pool, the SVRN7 LOBE layer, and the LiteDB-backed storage tier.
Document Scope
Scope: This document is an architecture and design specification. It does not generate or modify any code. All design decisions recorded here are intended as the authoritative input to future implementation sprints.
Key Findings:
The TDA is a self-hosting, recursive unit: every Citizen TDA in the VTC7 mesh runs the same software at the same architectural level.
The DIDComm/HTTP Listener and the PowerShell Runspace Pool are deliberately separated: the Listener is a write-ahead log gate; the Pool is an execution environment. They share no threads.
The DIDComm Message Switchboard — named explicitly in the diagram inside Agent 1’s Runspace — is the single component that reads from the durable inbox (IInboxStore / svrn7-inbox.db) and dispatches to agent runspaces.
SVRN7 is positioned as a LOBE (Loadable Object Brain Extension), not as an agent task and not as a storage system. This is an architectural statement: the Shared Reserve Currency (SRC) is a cognitive capability available to all runspaces.
The SVRN7 XFER rail is a dedicated transfer channel independent of the DIDComm message bus, preventing monetary operations from competing with messaging I/O on the same file lock.
The Epoch 0 designation constrains the permissible transfer matrix. In Epoch 0 (Endowment Phase), citizens may transfer only to their own Society wallet or to the Federation wallet. Cross-Society citizen-to-citizen transfers (Epoch 1) and open-market operations (Epoch 2) are not yet active. All agent routing logic must enforce these epoch rules.
Reading the diagram from left to right, seven distinct structural zones are visible. Each zone has a clear role boundary; no two zones share responsibility.
Zone
Label
Description
1
Command-Line Interfaces (CLIs)
Human-facing surface: Windows/Linux, Android, iOS, and FireOS platform shells, plus a smartwatch UX. These are the entry points where human intent enters the system. No agent logic executes here.
2
Internet / LAN / P2P Transport Rail
A vertical transport bridge between the CLIs and the TDA interior. Explicitly transport-agnostic — Internet, LAN, and P2P are treated equivalently. DIDComm envelope security means the transport layer is untrusted and interchangeable.
3
Loadable Object Brain Extensions (LOBEs)
The cognitive/capability layer. Two LOBE blocks flank a central SVRN7 label. LOBEs are PowerShell Modules dynamically loaded into the Runspace Pool InitialSessionState. SVRN7 between the LOBEs signals that the Shared Reserve Currency is a first-class brain capability, not an external service.
4
Citizen/Society Trusted Digital Assistant (TDA)
The primary subject (green outer box). Contains the PowerShell Runspace Pool (red inner box) with Agent 1–N slots and the DIDComm Message Switchboard, plus the DIDComm/HTTP Listener (purple box) at the right edge.
5
Internet Cloud
Standard transport cloud bridging the TDA’s DIDComm/HTTP Listener to the VTC7 federation zone. Annotated arrows indicate Inbound Unpack and Outbound Pack operations at the Listener boundary.
6
Storage Layer
Four LiteDB databases (Fast Cache, Long-Term Message Memory, DID Doc Registry, VC Doc Registry), plus NEO4J (via CIPHER) and SQL Server (via SQL/TDS). A dedicated SVRN7 XFER channel connects the LOBE layer to the SOVRONA (SVRN7) SRC terminal.
7
Verifiable Trust Circles (VTC7)
Large blue arrow on the right encompassing five Citizen TDA nodes connected via purple DIDComm-secured connectors into a federated mesh. The architecture is recursive: each VTC7 peer is a full TDA instance running identical software.
The LOBE layer is the most architecturally distinctive zone. Two LOBE blocks are shown with a SVRN7 label centred between them. This layout carries three architectural assertions:
LOBEs are PowerShell Modules. In the v0.7.1 implementation they are Svrn7.Federation.psm1 (35 cmdlets) and Svrn7.Society.psm1 (15 Society-native cmdlets). They are loaded into the RunspacePool InitialSessionState once at startup, available to every runspace without per-invocation import cost.
SVRN7 is a brain capability. Its placement between the LOBEs — not inside the Runspace Pool and not in the storage layer — asserts that ISvrn7SocietyDriver is a cognitive faculty available to all agents as a direct in-process call, not a message-passing request to an external service.
A third LOBE slot is implied for domain-specific extensions (e.g., Society.Medicine.psm1, Society.Education.psm1). The architecture is open-ended: new capabilities are added as LOBEs, not as agent modifications.
The red inner box contains the Runspace Pool. Its named slots visible in the diagram are:
Agent 1 Runspace — Coordinator. Contains four specialised sub-agents (Email, Calendar, Presence, Notifications) and the DIDComm Message Switchboard (Inbound/Outbound). The Switchboard is the internal routing hub: every DIDComm message — whether arriving from the internet or generated by a sub-agent — passes through it.
Agent 3 — Invoicing. Processes payment and transfer request messages.
Agent N — Trading. Handles Epoch 1+ market operations. Inactive in Epoch 0.
Each of Agents 2–N has bidirectional arrows to the Switchboard, establishing it as the internal message bus. No agent communicates directly with another agent or with the DIDComm/HTTP Listener.
The purple box at the right edge of the TDA is the single inbound/outbound gate to the internet. Two annotations are explicit in the diagram:
Inbound Processing (Unpack) — upper annotation: all messages arriving from the internet are unpacked (JWE decrypted, JWS signature verified) before entering the system. The Listener never passes ciphertext to agent logic.
Outbound Processing (Pack) — lower annotation: all messages leaving the system are packed (JWS signed, then JWE encrypted via SignThenEncrypt). The Listener never sends plaintext over the internet.
A separate REST/HTTP rail runs alongside the DIDComm rail. This supports interactions (balance queries, transfer submissions from a mobile app) more naturally expressed as REST calls than as DIDComm messages.
The Switchboard is the most significant architectural element named in the diagram that is not yet explicitly modelled in the v0.7.1 codebase. The diagram shows it as a named, first-class component inside Agent 1’s Runspace with bidirectional arrows to every other agent. Its architectural role:
It is the sole reader of the durable inbox (IInboxStore / svrn7-inbox.db). No agent polls the inbox directly.
It inspects each message’s DIDComm protocol URI (“type” field) and routes it to the correct agent runspace.
It handles idempotency: if a TransferId has already been processed (via IProcessedOrderStore), it returns the cached packed receipt without invoking any agent.
It enforces epoch rules: messages of types not permitted in the current epoch are rejected with a DIDComm error response, not silently dropped.
The storage layer sits below the TDA and consists of six data stores:
Store
Technology / v0.7.1 File
Role
Fast Cache (LiteDB)
LiteDB or IMemoryCache
Holds last-N unpacked message bodies keyed by TransferId for duplicate-delivery acceleration. Bidirectional arrow to Long-Term Memory = cache-miss read-through.
Long-Term Message Memory
svrn7-inbox.db (IInboxStore)
All InboxMessage records with full Pending→Processing→Processed/Failed lifecycle. Implemented in v0.7.1.
DID Doc Registry
svrn7-dids.db (DidRegistryLiteContext)
Stores DidDocument records. Resolved via IDidDocumentResolver / LocalDidDocumentResolver / FederationDidDocumentResolver.
VC Doc Registry
svrn7-vcs.db (VcRegistryLiteContext)
Stores VcRecord records. Resolved via IVcDocumentResolver / LiteVcDocumentResolver / FederationVcDocumentResolver.
NEO4J (via CIPHER)
Neo4j Graph DB
Not yet implemented. Intended for graph-structured VTC7 trust relationship queries and Society governance lineage.
SQL Server (via SQL/TDS)
SQL Server
Not yet implemented. Intended for high-volume relational reporting, UTXO ledger analytics, and regulatory export.
The SVRN7 XFER dedicated channel connects the LOBE layer directly to the SOVRONA (SVRN7) SRC terminal at the bottom of the diagram. This is the UTXO transfer pipeline: Invoke-Svrn7Transfer → ISvrn7Driver.TransferAsync → 8-step validator → UTXO commit. The dedicated channel prevents monetary operations from competing with DIDComm message I/O on the same LiteDB file lock.
The large blue VTC7 arrow on the right encompasses five Citizen TDA nodes. Each node connects to neighbours via purple DIDComm-secured connector nodes. Three observations:
The architecture is recursive and peer-symmetric. Every Citizen TDA in the mesh runs the same software. There is no central broker. The purple connectors represent the DIDComm/HTTP Listener instances of each peer TDA.
Cross-Society communication flows through Listener instances only, not through a shared database. FindVcsBySubjectAcrossSocietiesAsync and FederationDidDocumentResolver implement this fan-out pattern in v0.7.1.
VTC7 governance is enforced by the LOBE layer, not by network topology. A TDA that presents a valid Society DID and a current Svrn7VtcCredential VC is a legitimate VTC7 member.
The diagram’s Epoch 0 designation aligns precisely with Svrn7Constants.Epochs.Endowment (= 0) in the v0.7.1 codebase. The transfer epoch matrix enforced by TransferValidator Step 2 (ValidateEpochRulesAsync) covers all three epochs and requires no code changes. The Switchboard needs to read the current epoch via Get-Svrn7CurrentEpoch before routing trading messages.
Epoch
Constant
Permitted Operations
Epoch 0 — Endowment
Svrn7Constants.Epochs.Endowment
Citizens may transfer only to their Society wallet or the Federation wallet. Switchboard rejects trading/1.0/* messages.
Epoch 1 — Ecosystem Utility
Svrn7Constants.Epochs.EcosystemUtility
Cross-Society citizen-to-citizen transfers permitted. Agent N (Trading) becomes active.
Epoch 2 — Market Issuance
Svrn7Constants.Epochs.MarketIssuance
Open-market operations. Full VTC7 mesh trading enabled.
The following layers specify the complete TDA design. No code is generated here; this is the design record from which implementation sprints are planned.
A minimal Kestrel HTTP server (ASP.NET Core minimal API, no MVC) running on a configurable port. The Listener is the single inbound/outbound gate to the internet. It has exactly one responsibility: receive packed messages, unpack them at the cryptographic boundary, and enqueue them for processing.
Layer Boundary Rule
Design Rule: The Listener never executes agent logic. It only enqueues. The Runspace Pool never binds to a port. It only processes. These two systems share no threads and no direct call paths.
POST /didcomm — Receives a packed DIDComm message (Content-Type: application/didcomm-encrypted+json). Calls IDIDCommService.UnpackAsync to verify and decrypt. Calls IInboxStore.EnqueueAsync(messageType, unpackedBody). Returns 202 Accepted immediately. If UnpackAsync fails, returns 400 Bad Request with a DIDComm problem-report — no message is enqueued.
POST /rest/transfer — Convenience REST endpoint for synchronous UX-driven transfer submissions. Validates a signed TransferRequest JSON body and calls ISvrn7SocietyDriver.HandleIncomingTransferMessageAsync directly. Returns 200 OK with the packed receipt.
GET /health — Returns JSON health status: inbox queue depth by status, Merkle tree head age, current epoch, Listener up/down. Used by the smartwatch UX and monitoring.
All inbound messages are unpacked before anything else. Unpack = JWE decrypt using the Society’s Ed25519 messaging private key + JWS signature verify using the sender’s Ed25519 public key. Both steps must succeed; a failure at either point results in 400 and no enqueue.
All outbound messages are packed before leaving the Listener. Pack = JWS sign using the Society’s Ed25519 private key, then JWE encrypt using the recipient’s Ed25519 public key (SignThenEncrypt default, matching DIDCommPackMode throughout v0.7.1).
Agents work with plaintext only. This is the invariant enforced by the Pack/Unpack boundary. Runspaces never need access to cryptographic keys.
A LobeManager singleton reads a lobes.config.json manifest at startup, listing module paths in load order. It creates a shared InitialSessionState with each LOBE pre-imported and a shared $SVRN7 session variable (a Svrn7RunspaceContext object) injected into every runspace.
The Svrn7RunspaceContext holds:
A reference to the ISvrn7SocietyDriver singleton.
A reference to the IInboxStore singleton (svrn7-inbox.db).
A reference to the IProcessedOrderStore singleton.
The current epoch value, refreshed periodically via Get-Svrn7CurrentEpoch.
A RunspacePool with configurable min/max (recommended: min=2, max=ProcessorCount×2). Each runspace shares the same InitialSessionState from the LobeManager. The pool is not shared with the HTTP Listener thread.
Agent 1 is always open (min runspaces ≥ 1). It owns the DIDComm Message Switchboard and four specialised sub-agents.
DIDComm Message Switchboard
A continuous loop running inside Agent 1’s Runspace on a dedicated thread (not a PeriodicTimer — it runs with a short sleep on empty inbox). Its processing cycle:
Wraps Microsoft.Graph or Exchange EWS PowerShell commands. Cross-references sender email addresses with Society member DIDs via Resolve-Svrn7CitizenPrimaryDid. Structured results are placed back into the Switchboard’s outbound queue.
Calendar Sub-Agent
Reads and writes calendar events via Microsoft.Graph. Calendar events can carry did: URI identity claims in their extended properties, linking appointments to Society membership records and VTC7 governance meetings.
Presence Sub-Agent
Publishes the TDA’s availability status as a https://svrn7.net/protocols/presence/1.0/status DIDComm message to subscribed VTC7 peers. Receives presence updates from peers and maintains a local presence cache.
Notifications Sub-Agent
Dispatches alerts to the UX layer (smartwatch, mobile) when: inbox depth exceeds a configurable threshold; a citizen’s SVRN7 balance changes by more than a configurable amount; a Verifiable Credential is within 7 days of expiry; or the Society wallet balance falls below CitizenEndowmentGrana (overdraft draw trigger).
Each task runspace is opened from the pool on demand by Invoke-AgentRunspace and returns to the pool when the task completes. The pool thread is occupied only for the duration of the operation.
The SVRN7 XFER rail in the diagram is a dedicated channel from the LOBE layer to the SOVRONA SRC terminal. A SvrN7TransferService BackgroundService is designed to run alongside DIDCommMessageProcessorService:
Agents post a TransferQueueRecord to a dedicated ITransferQueue collection in svrn7-inbox.db rather than calling ISvrn7Driver.TransferAsync directly.
SvrN7TransferService drains ITransferQueue on its own loop, runs the 8-step TransferValidator, and commits the UTXO.
Retry semantics: up to 3 attempts (mirroring IInboxStore). After maxAttempts, the record is dead-lettered with LastError populated.
This decouples agent logic from the UTXO commit path and prevents monetary operations from competing with DIDComm inbox I/O on the same LiteDB file lock.
Five principles emerge from careful reading of the DSA diagram. These are structural rules that the diagram enforces by its construction, not interpretive opinions.
#
Principle
Definition
Rationale
P1
Listener and Pool are separate systems
The Listener never executes agent logic; it only enqueues. The Pool never binds to a port; it only processes. No shared threads.
Prevents a slow agent from blocking inbound receipt. Prevents a message burst from exhausting runspaces.
P2
Switchboard is the sole inbox reader
No agent polls IInboxStore directly. Only the Switchboard does, then hands work to agent runspaces.
Single point for epoch enforcement, idempotency checking, and routing. Single LiteDB writer.
P3
Pack/Unpack at Listener boundary only
Agents work with unpacked plaintext. Agents produce plaintext responses; the Listener packs them.
Security guarantee (no agent receives unverified data) and architectural simplification (runspaces need no crypto keys).
P4
SVRN7 is a LOBE, not an agent
ISvrn7SocietyDriver is available to all agents via $SVRN7 session variable — direct in-process cmdlet invocation, not message-passing.
This is why SVRN7 sits between the LOBE blocks in the diagram, not inside a specific agent box.
P5
VTC7 peers are structurally identical
Every Citizen TDA in the mesh runs the same software. No central broker. Cross-Society communication flows through DIDComm/HTTP Listener instances only.
Self-hosting, recursive design. FindVcsBySubjectAcrossSocietiesAsync and FederationDidDocumentResolver implement the fan-out pattern.
Components identified in the diagram but not yet implemented in SVRN7 v0.7.1, representing the work backlog for future sprints.
Gap
Priority
Design Decision
HTTP/Kestrel Listener Entry Point
Critical
ASP.NET Core minimal API with POST /didcomm (enqueue), POST /rest/transfer (synchronous), and GET /health routes. Calls IInboxStore.EnqueueAsync. This is the missing bridge between the internet and DIDCommMessageProcessorService.
DIDComm Message Switchboard (named)
Critical
Extract routing logic from DIDCommMessageProcessorService into a named SwitchboardService with explicit epoch gating, IProcessedOrderStore idempotency check, and per-protocol-URI routing to agent runspace slots.
Svrn7RunspaceContext + $SVRN7
High
Formalise the $SVRN7 PSCustomObject as a named class holding ISvrn7SocietyDriver, IInboxStore, IProcessedOrderStore, and current epoch. Inject via RunspacePool InitialSessionState.
LobeManager + lobes.config.json
High
Singleton that reads the manifest, builds the InitialSessionState, and manages hot-reload of domain LOBEs without full TDA restart.
Agent 1 Sub-Agents (Email, Calendar, Presence, Notifications)
High
Four PowerShell pipeline scripts inside Agent 1 Runspace. Microsoft.Graph for Email and Calendar. Custom DIDComm presence/1.0/status protocol for Presence. Event-driven Notifications.
Fast Cache (svrn7-cache.db)
Medium
CacheLiteContext (fifth LiteDB) or IMemoryCache. Stores last-N TransferId → packed receipt pairs for Switchboard hit-before-dequeue.
SvrN7TransferService + ITransferQueue
Medium
Dedicated BackgroundService draining a TransferQueueRecord collection in svrn7-inbox.db, decoupling agent UTXO commit from agent message processing.
Agent N — Trading
Low (Epoch 1)
Implement when Get-Svrn7CurrentEpoch returns ≥ 1. Switchboard routing stub (drop trading/* in Epoch 0) should be added now.
NEO4J / CIPHER integration
Low (Future)
Graph store for VTC7 trust path queries. Out of scope for v0.7.x.
Trusted Digital Assistant. The sovereign, DID-native, DIDComm-native runtime at the centre of the Web 7.0 ecosystem. A citizen or Society operates one TDA.
DSA
Decentralized System Architecture. The architectural diagram describing the TDA and its surrounding ecosystem. Current version: DSA v0.16.
LOBE
Loadable Object Brain Extension. A PowerShell Module loaded into the Runspace Pool InitialSessionState, providing capabilities (SVRN7 cmdlets, domain functions) available to all runspaces.
VTC7
Verifiable Trust Circle. A federated mesh of TDA nodes that mutually recognise each other’s DIDs and VCs, enabling cross-Society communication and cross-Society VC resolution.
SRC
Shared Reserve Currency. The SVRN7 / SOVRONA monetary unit. 1 SVRN7 = 1,000,000 grana. Citizen endowment in v0.7.1: 1,000 grana = 0.001 SVRN7.
DIDComm
Decentralized Identifier Communication. A message protocol providing transport-agnostic, end-to-end secure messaging between DID-identified parties. Version 2 used throughout Web 7.0.
SignThenEncrypt
The default DIDComm pack mode in SVRN7 v0.7.1. Payload is JWS-signed with the sender’s Ed25519 private key, then JWE-encrypted with the recipient’s Ed25519 public key (X25519 via RFC 7748 birational map).
Switchboard
The DIDComm Message Switchboard. Named component inside Agent 1’s Runspace. The sole reader of the durable inbox. Routes messages to agent runspaces by protocol URI.
Pack / Unpack
Pack = sign + encrypt an outbound DIDComm message. Unpack = decrypt + verify signature on an inbound message. Both operations occur exclusively at the Listener boundary.
Epoch
A governance phase of the SVRN7 ecosystem. Epoch 0 (Endowment): citizen→Society and citizen→Federation transfers only. Epoch 1 (Ecosystem Utility): cross-Society. Epoch 2 (Market Issuance): open-market trading.
UTXO
Unspent Transaction Output. Atomic unit of SVRN7 wallet balance. Every transfer creates new UTXOs and marks spent UTXOs. Conservation invariant: sum of all UTXOs = TotalSupplyGrana − unallocated Federation balance.
grana
Atomic monetary unit of SVRN7. 1 SVRN7 = 1,000,000 grana. All storage, arithmetic, and transfer amounts are in grana. SVRN7 is display-only.
Here’s a structured breakdown, distinguishing what’s established fact, inference, and uncertain.
Who Owns Content Claude Creates?
1. Anthropic’s Terms: You Get the Output Rights
Under Anthropic’s Consumer Terms of Service, as between you and Anthropic, you retain any right, title, and interest in the inputs you submit. Subject to your compliance with their terms, Anthropic assigns to you all of their right, title, and interest — if any — in the outputs.
The “if any” qualifier is doing real legal work there. Anthropic is assigning whatever rights they have in the output — but they’re not guaranteeing those rights are substantial under copyright law.
For commercial/API customers, the terms are stronger. The commercial terms state that Anthropic agrees the customer owns all outputs, and disclaims any rights it receives to customer content, assigning all right, title, and interest in outputs to the customer.
2. Copyright Law: The Human Authorship Problem
This is where it gets complicated. U.S. copyright law requires a human author. The U.S. Copyright Office has been clear on this — a federal court ruled that art generated entirely by AI couldn’t be copyrighted because it lacked the essential human touch. So if you give Claude a simple prompt and use the raw, unedited output, that content likely has no copyright protection at all.
In February 2026, the Supreme Court declined to hear the Thaler appeal, confirming at the highest level that pure AI-generated works cannot be copyrighted.
The practical implication: The more creative direction, editorial judgment, and human selection you exercise over Claude’s output — revising, curating, combining, structuring — the stronger your claim to copyright over the resulting work. The output becomes a human-authored work with AI assistance, rather than an AI-generated work.
3. Commercial Use and Reuse Rights
Anthropic’s terms confirm users own outputs generated by Claude, and commercial use is permitted without additional licensing. So you can publish, sell, or incorporate Claude-assisted content into your work — no royalty or license back to Anthropic is required.
4. Copyright Indemnity (API/Commercial Customers)
Under Anthropic’s Commercial Terms of Service, Anthropic will defend customers from any copyright infringement claim made against them for their authorized use of the services or their outputs, and will pay for any approved settlements or judgments that result. This does not apply to consumer/claude.ai free-tier users in the same way.
Practical Summary for Your Situation
Given that you’re using Claude for SVRN7/Web 7.0 specification work, whitepaper drafting, IETF drafts, and software architecture — the key points are:
You own the outputs under Anthropic’s terms (both consumer and commercial).
Copyright protection on purely AI-generated text is legally uncertain — but content you meaningfully shape, edit, and structure has stronger human-authorship claims.
Publishing rights: No restriction from Anthropic on original publication — you can publish IETF drafts, W3C specs, whitepapers, and code incorporating Claude-assisted content.
Strongest position: Document your creative contributions — the architectural decisions, structural choices, and editorial revisions you make to Claude’s outputs. That’s where your copyright lives.
I’m not a lawyer, and this space is evolving rapidly with active litigation. For anything with significant commercial stakes, legal counsel familiar with AI IP would be worth consulting.
Traditionally when a platform developer (e.g. Microsoft) created a new platform, it embarked on standard approaches to Developer Evangelism to challenge the various Technology Adoption Curves and to Cross the Chasm (e.g. https://hyperonomy.com/2019/10/16/technology-adoption-models/). In the new era of AI-generated code, where/how should evangelism be targeted? …if it can even be called evangelism any more. How should a platform developer promote his new platform to all the different AI chatbots (e.g. Claude)? What artifacts need/should be created? Where/how should they be placed/distributed? This is a rich and important strategic question.
Platform Evangelism in the Age of AI-Generated Code
The Fundamental Shift: From Human Adopters to AI Intermediaries
Traditional Developer Evangelism targeted humans at specific positions on the Technology Adoption Lifecycle — Innovators, Early Adopters, Early/Late Majority, Laggards. The evangelist’s job was to move people rightward along that curve.
In the AI-generated code era, a new and decisive intermediary has been inserted into the adoption pipeline: the AI coding assistant / chatbot. The human developer no longer discovers your platform primarily through conference talks, blog posts, or Stack Overflow. Instead, they ask Claude (or Copilot, Cursor, Gemini) to scaffold the integration for them. If the AI doesn’t know your platform well, generates wrong API calls, or defaults to a competitor, the human never even gets a chance to adopt.
The implication is stark: AI models are now the most important Early Adopters you need to cross the chasm with first. They are a new, synthetic segment that sits before the Innovators on your adoption curve.
The New Adoption Curve Layer
Your 20+ model framework maps well here. Superimposing two layers:
Traditional Layer
New AI-Mediated Layer
Innovator humans discover your platform
AI models are trained/fine-tuned on your docs
Early Adopters experiment
AI generates working starter code
Early Majority follows proven patterns
AI recommends your platform confidently
Word-of-mouth spreads
AI’s citations / training data spreads
Chasm: “will the mainstream trust it?”
New chasm: “does the AI know it well enough to generate correct code?”
What Has Changed About “Evangelism”
The word still applies, but the audience, artifacts, and channels are fundamentally different.
Old evangelism targets:
Human developers (via conferences, blogs, sample apps)
AI training pipelines — what gets into the pretraining and fine-tuning corpora
AI retrieval systems — what gets surfaced via RAG at inference time
AI context windows — what gets injected via system prompts, MCP servers, tool definitions
AI safety/quality filters — what AI providers consider authoritative and trustworthy
The humans still matter, but they are now downstream of the AI intermediary.
The New Artifact Set
This is where it gets concrete. You need a new category of artifact that I’d call AI-Legible Platform Documentation — content designed to be consumed, reasoned over, and reproduced by AI systems, not just read by humans.
1. llms.txt — The Emerging Standard
A plain-text or markdown file placed at the root of your platform’s documentation site (e.g., https://svrn7.net/llms.txt). This is an emerging informal standard (analogous to robots.txt) that signals to AI crawlers and RAG systems what your platform is, what its key concepts are, and where the authoritative docs live. It should be:
Terse, structured, machine-readable
Canonical definitions of your core concepts (did:drn, VTC, SOVRONA, etc.)
Explicit disambiguation (e.g., “SOVRONA is not Solana, not SOVRIN”)
2. Canonical Concept Glossary (Machine-Readable)
A JSON-LD or plain markdown file with precise, unambiguous definitions of every platform term. AI models pattern-match on concept names. If your terms are unique enough (which did:drn, VTC7, svrn7.net largely are) and appear in training data with consistent definitions, the model learns authoritative meaning. Publish this as both human-readable HTML and structured data.
3. AI-Optimized Quickstart / Code Recipes
Short, self-contained code examples (C#/.NET in your case) that demonstrate each key integration scenario. These need to be:
Complete — no ellipsis (...), no “fill in your own logic here”
Correct — compilable, with real method signatures
Labeled — preceded by a natural-language description that an AI can use as a retrieval key
Published in plain markdown — not behind JavaScript-rendered walls
The goal: when a developer asks Claude “how do I resolve a did:drn identifier in C#?”, there is a verbatim-correct code sample in the training data or retrieval index that Claude surfaces.
4. OpenAPI / SDK Schemas
If your platform has any API surface, publish machine-readable schemas (OpenAPI 3.x, JSON Schema). AI coding assistants consume these directly — Copilot, Cursor, and others can ingest them to generate type-correct API calls. This is one of the highest-leverage artifacts you can produce.
5. MCP Server Definition
For platforms targeting agentic AI workflows (which Web 7.0 / TDW AgenticOS clearly does), publishing an MCP server that exposes your platform’s key operations is the equivalent of publishing an SDK in the old world. When a developer is using Claude with MCP enabled, your platform becomes natively callable. This is arguably the highest-leverage evangelism artifact in the agentic AI era.
6. IETF / W3C Standards Drafts (Already in Progress)
This is something you’re already doing, and it is directly high-value for AI training. Standards bodies’ outputs (IETF Datatracker, W3C, etc.) are heavily weighted in AI training corpora. draft-herman-did-drn-00 appearing on Datatracker means AI models encounter it as an authoritative source. This is the new equivalent of a Gartner mention.
7. GitHub Presence with Rich READMEs
GitHub is a primary training data source for all AI coding assistants. Every repository should have:
A detailed README explaining the why and what of the platform
Clear installation/usage examples
Properly named types, interfaces, and methods (because AI learns your API surface from source code identifiers)
Agentic AI systems discover tools through registries
OpenAI / Anthropic Custom GPT / Projects
Direct context injection
System prompts for your platform’s AI assistant
The Meta-Insight: Legibility as the New Evangelism
In the traditional model, evangelism was about persuasion — moving humans emotionally and rationally across the adoption chasm. In the AI-mediated model, the equivalent is legibility: making your platform concepts, APIs, and code patterns so precisely and consistently expressed that AI models can reproduce them correctly.
A poorly documented platform that generates hallucinated API calls when asked about it is effectively invisible to the new generation of developers. A well-documented platform that produces correct, idiomatic code snippets on first ask has already crossed the chasm with the most important new gatekeeper.
If you want a new term for it: AI Legibility Engineering — the discipline of structuring your platform’s knowledge artifacts so they are accurately learned, retrieved, and reproduced by AI systems.
Specific Recommendations for the Web 7.0 / SVRN7 Ecosystem
Given your specific context:
Publish llms.txt at svrn7.net/llms.txt and hyperonomy.com/llms.txt immediately — low cost, high signal.
Create a canonical C# SDK with clean, AI-legible method names (IDidDocumentResolver.ResolveAsync(string did)) — method signatures become training data.
Register an MCP server for did:drn resolution and VTC operations — this makes your platform natively callable by Claude and other MCP-aware agents.
File a SLIP-0044 registration publicly and reference it from your Datatracker drafts — cross-document citation chains strengthen AI’s association graph for your platform.
Publish a disambiguation page — “SOVRONA is not SOVRIN, not Solana, not SOV” — AI models conflate similar-sounding names; explicit disambiguation in training-visible text corrects this.
The chasm hasn’t disappeared. It has just moved — and the first bridge you need to build now goes to the AI, not the human.
NOTE: The first four capbabilities are general decentralized identity infrastructure that any organization could use independently of the monetary layer.
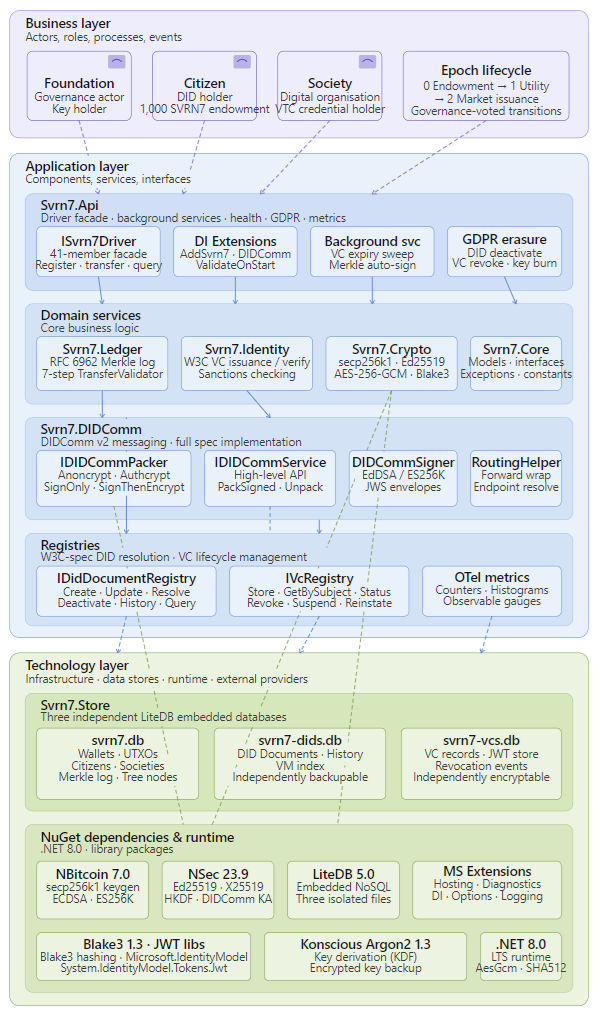
Sovrona (SVRN7™) is the Shared Reserve Currency (SRC) for the Web 7.0 digital ecosystem, implemented as an embeddable .NET 8 library that manages citizen and society wallets, enforces a governance-controlled three-epoch monetary lifecycle, and maintains a cryptographically tamper-evident audit log of all transactions.
Unlike traditional and modern digital currencies, SVRN7 is built on a foundation of self-sovereign identity — every participant is a DID holder, every entitlement/endowment is a Verifiable Credential, and trust between parties is established through standards-based cryptographic proofs rather than a shared blockchain or central authority.
Web 7.0 Use Cases
With configurable DID method names, the library becomes usable in scenarios that have nothing to do with the SVRN7 SRC.
Healthcare network. A hospital consortium where each hospital operates its own DID method (did:hospital-a, did:hospital-b). Patient VCs issued by one hospital are verifiable by any other. The Merkle log provides an auditable record of credential issuance without exposing patient data. DIDComm handles encrypted referral messages between hospitals.
Supply chain. A manufacturing network where each tier-1 supplier owns a DID method. Components carry VC provenance records signed by their manufacturer’s DID. The Federation equivalent is the brand owner who sets the governance rules. The UTXO model tracks component custody rather than currency.
Professional credentialing. A federation of professional bodies (law societies, medical councils, engineering institutes) where each body owns its DID method and issues member credentials. Cross-body credential verification uses the same IDidResolver routing the SVRN7 library already needs.
Government identity federation. Multiple municipal or provincial identity systems where each jurisdiction owns its DID method. Citizens have identities under their jurisdiction’s method. Cross-jurisdiction services verify credentials without requiring a central identity broker.
Q1. What is your internal representation of this solution? …an AST? …the actual source code? …some other modeling approach/metamodel? …used for generating code, documenting the README.md, creating test cases, creating architecture diagrams, etc.
NOTE: The current set of software metrics for this solution-under-development can be found in APPENDIX A.
This is a genuinely interesting question and the honest answer is: there is no persistent internal representation at all. Here is what actually happens:
What I am, mechanically. I am a transformer that maps a context window (a flat sequence of tokens) to a probability distribution over the next token. There is no AST, no object graph, no schema, no database, no symbol table. When this conversation session ends, nothing persists — the weights of the model are fixed and do not change.
What substitutes for a representation. During this conversation, the context window itself is the representation. Every message, every code block, every README excerpt, every test name you have seen scrolling past — all of that is sitting in my active context as raw tokens. When I generated the ArchiMate diagram or the README or the test cases, I was pattern-matching against that token sequence and the statistical regularities in my weights that encode knowledge of C#, ArchiMate OEF XML, W3C VC, DIDComm v2, RFC 6962, etc.
How this produces consistent outputs. The compacted summary at the top of this conversation (the one listing 45 files, 207 tests, all the interface members, all 20 bugs fixed, etc.) is doing the work of an “architecture model.” It was written by me in a previous session to act as a faithful briefing document — a structured natural-language encoding of the project state. When I generate code, tests, a README, or an ArchiMate diagram from it, I am essentially translating that natural-language description through my weights.
What I do not have. I have no:
Parse tree or AST of the C# source
Type graph, dependency graph, or call graph
Formal metamodel instance (no MOF, no Ecore, no ArchiMate metamodel objects)
Semantic index of method signatures
Persistent memory between sessions (the compacted summary was explicitly written to bridge sessions)
What this means for your artefacts. The three outputs — source code, README, tests, and ArchiMate diagram — were all produced from the same token context, so they are coherent with each other in the sense that a careful human author would make them coherent. But they are not derived from a single authoritative model the way a proper MDE (Model-Driven Engineering) toolchain would derive them. If the C# source and the ArchiMate diagram diverge, neither one automatically updates the other — you would need to bring the divergence back into a context window and ask me to reconcile.
The practical implication for Web 7.0. If you want genuine model-driven traceability — where a change to ISvrn7Driver propagates automatically into the ArchiMate model, README, and test stubs — that is a toolchain problem (e.g. Roslyn-based code analysis feeding an ArchiMate metamodel instance in Archi or a Sparx EA repository). I can help design or implement that toolchain, but I am not myself that toolchain.
APPENDIX A – Solution Software Metrics (April 5, 2026)
Here are the complete, live-measured metrics for the SVRN7 v0.5.0 solution: