Copyright © 2026 Michael Herman (Bindloss, Alberta, Canada) – Creative Commons Attribution-ShareAlike 4.0 International Public License
Web 7.0™, Web 7.0 DIDLibOS™, TDW AgenticOS™, TDW™, Trusted Digital Web™ and Hyperonomy™ are trademarks of the Web 7.0 Foundation. All Rights Reserved.
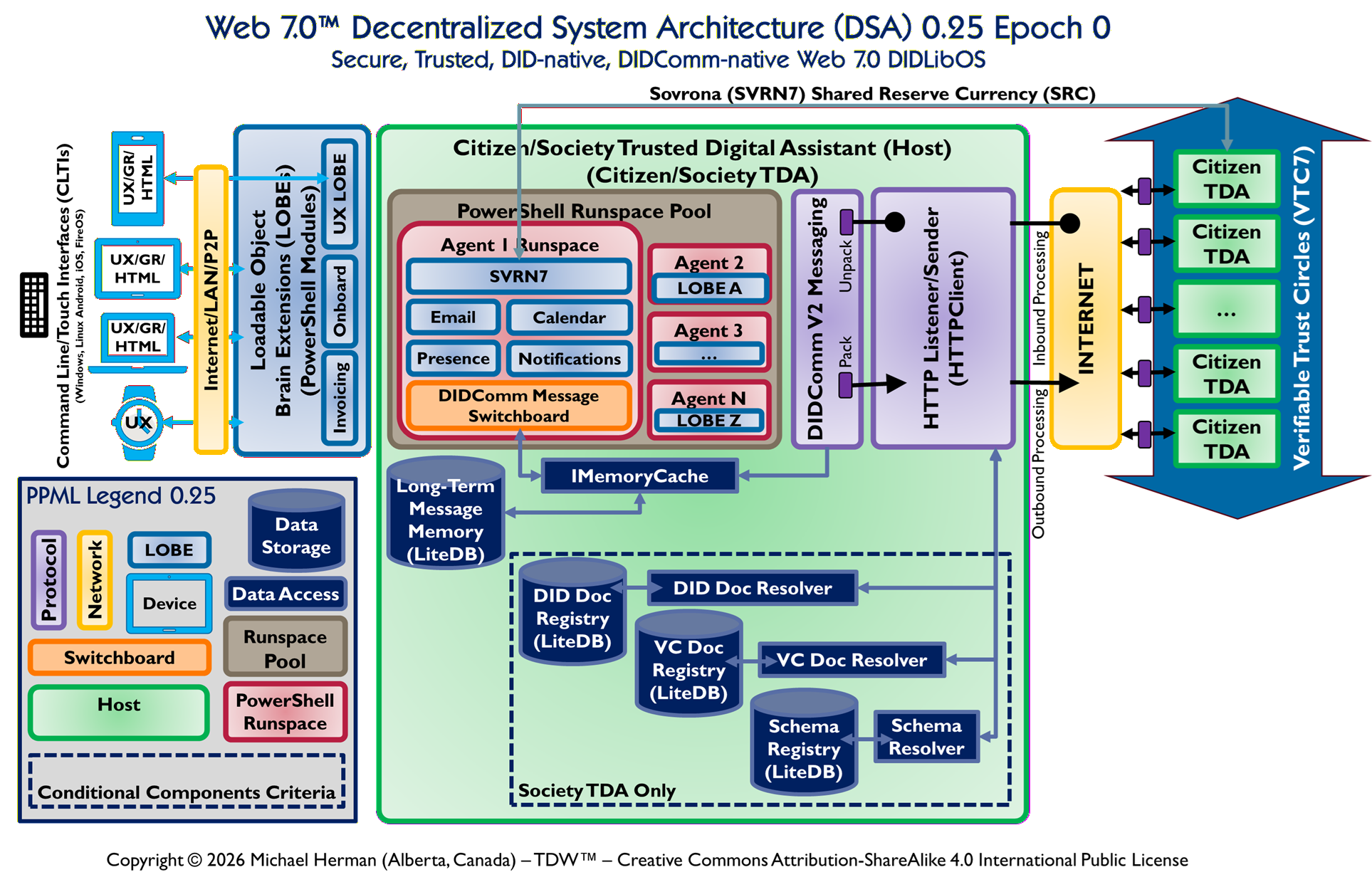
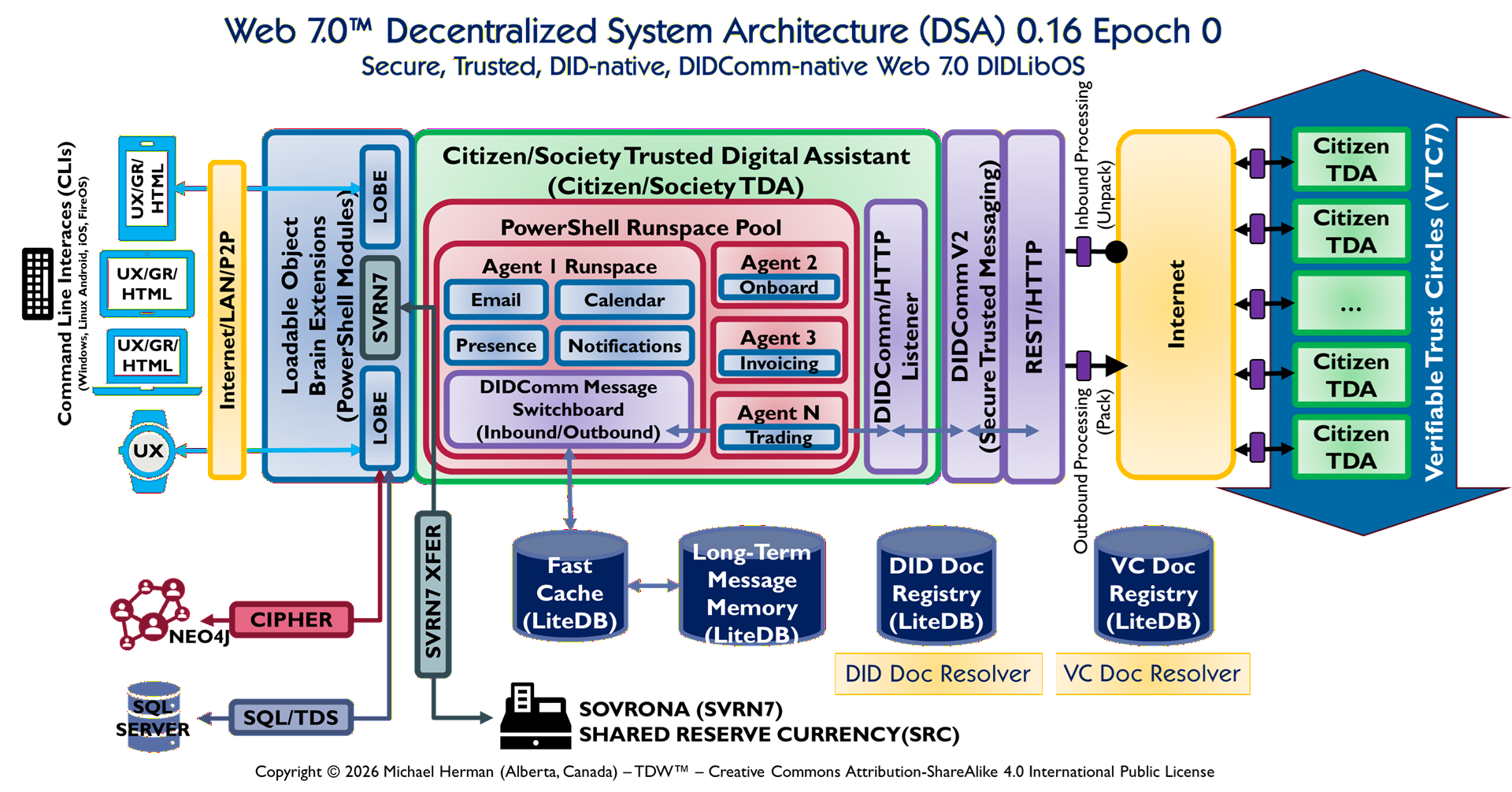
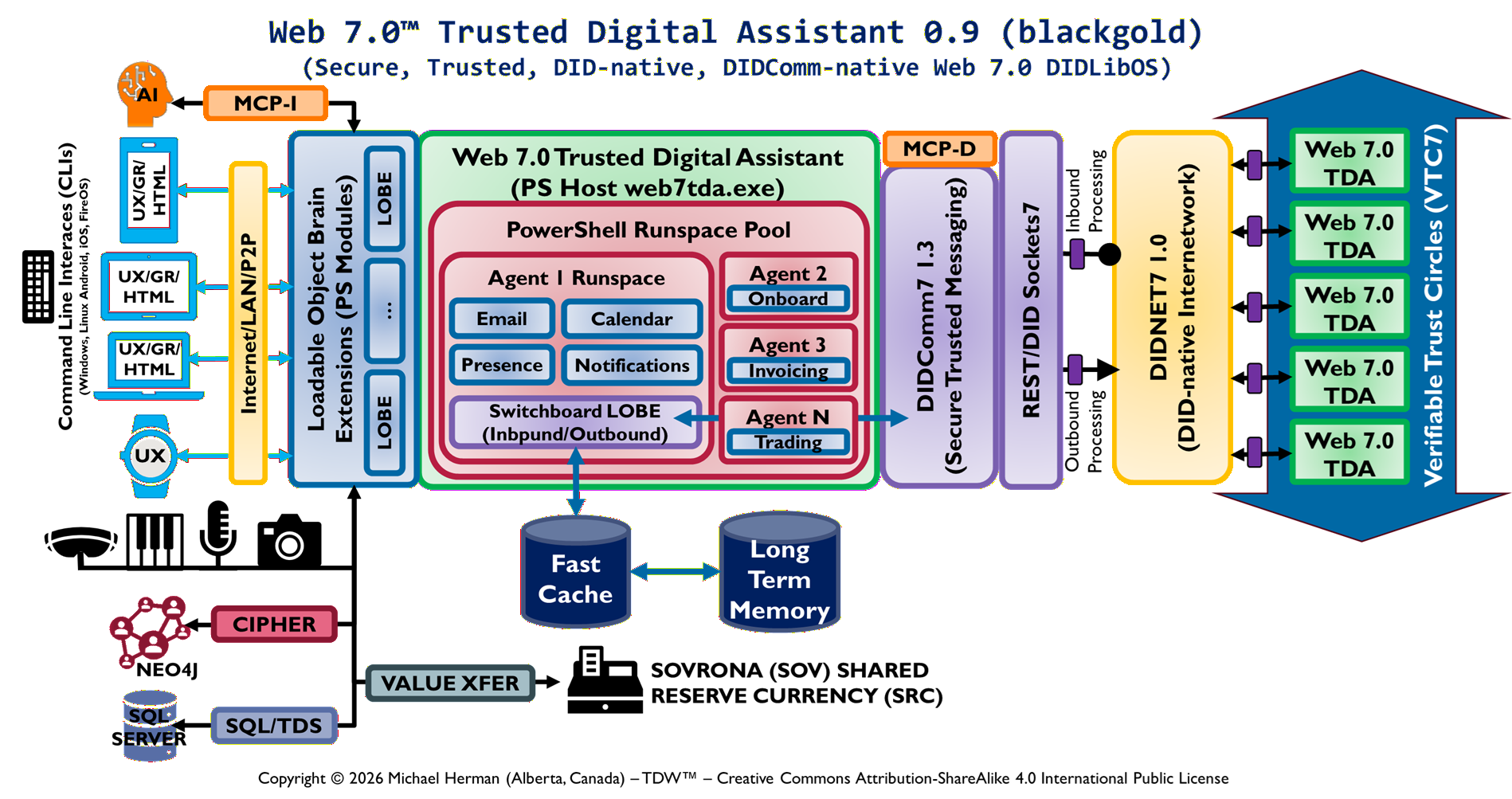
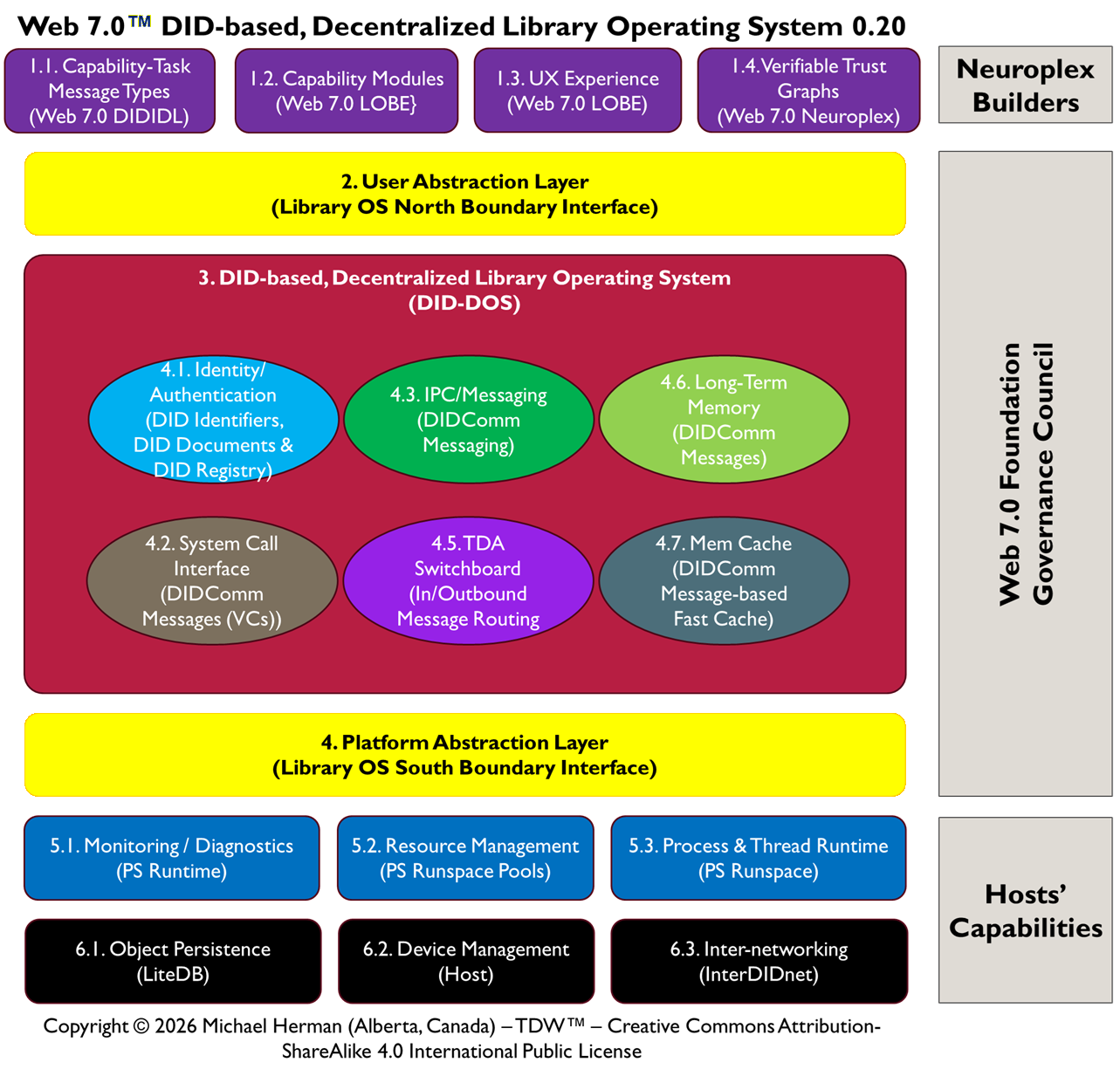
Parchment Programming is an architecture-first software development methodology where a richly annotated visual diagram — the “parchment” — serves as the primary design document and intermediate representation (IR) that an AI coding assistant (like Claude) reads directly to generate correct, idiomatic code.
Rather than translating requirements through layers of prose specifications, the diagram itself encodes stereotypes, interface contracts, project boundaries, data models, and protocol annotations in a form that is simultaneously human-readable and AI-actionable — invented by Michael Herman, Chief Digital Officer, Web 7.0 Foundation. April 2026.
“Change is hard at first, messy in the middle, and gorgeous at the end.” Robin Sharma
The core claim
PPML asserts that a formal diagram is a sufficient specification for code generation — that if a diagram is conformant (every element has a unique label, belongs to exactly one Legend-defined type, and has a derivation rule), then an AI or human can produce the correct implementation from the diagram alone, without additional prose specification.
This is a stronger claim than “diagrams are useful.” It is a claim about sufficiency.
Implication 1: The specification artefact changes
In conventional software development, the specification is prose — a requirements document, a design document, an architecture decision record. The diagram is illustrative, supplementary, and frequently stale.
In PPML, the diagram is the specification. The prose documents (TDA Design, Whitepaper, IETF drafts) are derived from the diagram — they explain and justify it, but they do not override it. If the diagram and the prose conflict, the diagram wins.
This inverts the usual relationship. The implication is that diagram maintenance becomes the primary engineering discipline, not prose authoring. A diagram change is a specification change. An undocumented code change that has no corresponding diagram change violates tractability — it is, by definition, undocumented behaviour.
Implication 2: AI code generation becomes deterministic at the architecture level
The Gap Register and derivation rules give an AI generator a closed-world assumption: every artefact it produces must be traceable to a diagram element instance, and every diagram element instance must produce at least one artefact. There are no open-ended requests like “build me a messaging system.” There are only grounded requests like:
“Derive the artefact for element instance ‘DIDComm Message Switchboard’ of type Switchboard. Derivation rule: one router class, one protocol registry, one outbound queue.”
The AI cannot invent artefact names that do not appear in the diagram. It cannot silently add dependencies. It cannot reorganise the architecture. This is not a limitation — it is the point. Creativity is in the diagram; precision is in the derivation.
The practical implication is that AI code generation quality is bounded below by the quality of the diagram, not by the quality of the prompt. A well-formed PPML diagram produces consistent, reproducible results across AI sessions and across AI models. A poorly-formed diagram produces inconsistent results regardless of prompt quality.
Implication 3: The change process becomes explicit
Conventional development has no formal mechanism for distinguishing “we changed the architecture” from “we changed an implementation detail.” Both look like pull requests.
PPML enforces a distinction. Within an epoch, the Legend is frozen and element types cannot change. A new component requires a diagram change, which requires a version increment (DSA 0.19 → DSA 0.24), which requires a Gap Register update. Architectural changes are visible as diagram changes.
Implementation changes — refactoring within a derived artefact, performance tuning, bug fixes — do not require diagram changes. The boundary between architecture and implementation is drawn precisely at the diagram boundary.
This has governance implications for a project like SVRN7: the diagram is the governance document. Epoch transitions are diagram changes. New protocol support is a LOBE addition to the diagram. The Foundation controls the diagram; contributors derive from it.
Implication 4: Testing becomes traceable to the diagram
Every test should be traceable to a diagram element instance, just as every artefact is. If a test has no corresponding diagram element, it is either testing an undocumented artefact (a tractability violation) or testing implementation detail that should not be exposed.
In practice this means the Gap Register can include test coverage as a property. “Element instance X has derivation artefact Y, test coverage Z.” Missing test coverage is a Gap Register entry, not a matter of developer discretion.
Implication 5: Documentation staleness becomes structurally impossible
In conventional projects, diagrams go stale because they are maintained separately from code. PPML makes diagram staleness a first-class defect: if the diagram is stale, the Gap Register is wrong, and any AI-generated code derived from it will be wrong.
The practical discipline is: diagram first, always. Before writing any new C# class, PowerShell module, or LOBE descriptor, the diagram must already contain the corresponding element instance. This is why every source file in the SVRN7 solution carries a derivation trace comment:
// Derived from: "DIDComm Message Switchboard" — DSA 0.24 Epoch 0 (PPML).
That comment is not decorative — it is the traceability link. If that element instance no longer appears in the diagram, the file is either stale or the diagram is stale. One of them must change.
Implication 6: The methodology scales with AI capability
This is the forward-looking implication. In the current epoch, an AI (Claude, in this case) assists with derivation — producing C# from a diagram element description, writing PowerShell cmdlets from a LOBE derivation rule, generating IETF draft sections from an architectural decision. The human holds the diagram and reviews the derivations.
As AI capability increases, the human’s role shifts further toward diagram authorship and review. The diagram becomes the interface between human architectural intent and AI implementation. The better the diagram grammar (the PPML Legend), the more precisely an AI can translate intent into code.
The LOBE descriptor format — with its MCP-aligned inputSchema/outputSchema, compositionHints, and useCases — is an early instance of this. It is a machine-readable diagram-derived artefact that an AI can use to reason about composability without reading the PowerShell source. The diagram element (LOBE) produces both the code artefact (.psm1) and the AI legibility artefact (.lobe.json). Both are derived from the same diagram element. The AI consuming the .lobe.json is one step removed from reading the diagram directly.
The next step — which PPML explicitly anticipates but does not yet implement — is an AI that reads the diagram directly and performs the full derivation without a human intermediary for routine changes.
The honest limitation
PPML is most effective for component-level architecture — what components exist, how they relate, what they are responsible for. It is less effective for algorithmic detail. The 8-step transfer validator, the Merkle log construction, the DIDComm pack/unpack sequence — these require prose specification or pseudocode. The diagram says “TransferValidator exists and implements ITransferValidator.” It does not say how step 4 (nonce replay detection) works.
This is not a flaw in PPML — it is a boundary condition. PPML governs architecture. Algorithms require their own specification discipline (IETF drafts, pseudocode, formal methods). The two disciplines are complementary: PPML tells you what to build and how it connects; the algorithm specification tells you how each component behaves internally.
Summary
PPML’s implications reduce to one structural claim: the diagram is the primary engineering artefact, and all other artefacts are derived from it. The implications — specification inversion, deterministic AI generation, explicit change governance, traceable testing, structural documentation freshness, and scalability with AI capability — all follow from that single claim. Whether that claim is valuable depends entirely on whether the diagram can be kept accurate and complete, which is a discipline question, not a tool question.