Short answer: if you try to measure the human brain in “tokens per second,” it looks orders of magnitude slower than modern AI models—but that comparison is misleading because the brain isn’t doing token-by-token next-word prediction. See below.
1) What “tokens/sec” means in AI
In systems like or newer commercial LLMs:
A token ≈ 0.75 words (on average)
Inference = generating the next token given context
Typical speeds (as of ~2025):
50–300 tokens/sec for large models (depending on hardware and optimization)
Faster specialized systems can exceed 1,000 tokens/sec
This is a serial, discrete, text-based process.
2) Human brain: no native “token” abstraction
The human brain doesn’t operate in tokens. Instead:
The presentation of the 8 Orthogonal Principles of Self-Sovereign Identity is organized as follows: an introduction, followed by conceptual descriptions of each principle, followed by a clean, testable scoring rubric as an appendices.
The 8 Orthogonal Principles are independent dimensions—each answers a different, irreducible question about identity systems. Together they form a coordinate system for evaluating SSI.
Orthogonality
Orthogonality (in this context) means that each principle captures a distinct dimension of the problem space that cannot be derived from, reduced to, or substituted by any combination of the others. Improving one dimension does not automatically improve another, and failure in one cannot be compensated for by strength in the rest.
In practice, this implies the set is non-redundant, supports clear trade-off analysis, and allows systems to be evaluated as coordinates in a multidimensional space rather than as a single blended score.
1) Existential Sovereignty
Does identity exist independently of systems?
Identity must originate with the subject, not be granted by a platform, issuer, or authority. A system can recognize or attest to identity, but must not be the source of its existence.
Without this, identity reduces to an account or permission.
2) Agency
Can the subject meaningfully choose?
The individual must be able to authorize, refuse, revoke, and delegate actions involving their identity. This includes protection against manipulation, coercion, or “forced consent” patterns.
Without agency, control is illusory—even if the system appears user-centric.
3) Data Boundary Control
What can others see—and what can they infer?
The subject must be able to constrain disclosure to the minimum necessary, ideally proving claims without exposing raw data. Observability (who accessed what) is part of this boundary.
Without this, identity becomes a surveillance surface.
4) System Independence
Where can identity function?
Identity must operate across systems without lock-in. No single vendor, platform, or protocol should be a required dependency for use.
Without independence, sovereignty collapses when you switch contexts.
5) Temporal Continuity
Does identity endure and evolve over time?
Identity must persist through change—devices, keys, credentials, and life events—while maintaining continuity and integrity. This includes recovery, rotation, and revocation.
Without continuity, identity fragments or becomes unusable.
6) Power Symmetry Constraints
Can power distort identity interactions?
Systems must actively resist coercion, exploitation, and structural inequities. This includes both technical safeguards and interaction design that prevents abuse.
Without this, all other properties can exist formally but fail in practice.
7) Epistemic Integrity
Can identity claims be trusted?
Claims about identity must be verifiable, traceable to their origin, and revocable when no longer valid. The system must handle conflicting claims and prevent large-scale fraud.
Without epistemic integrity, identity becomes meaningless—even if perfectly controlled.
8) Incentive Alignment
Do participants have reason to behave correctly?
The system must align incentives so that honest behavior is rewarded and abuse is costly. This includes economic, reputational, and governance mechanisms.
Without this, systems that look sound will degrade or be exploited over time.
Appendix A — Scoring Rubric (0–5 per dimension)
Each dimension is scored using observable evidence and adversarial tests, not claims.
1) Existential Sovereignty
0 – Platform-bound account only 1 – Exportable but not reusable 2 – External identifiers, system-bound 3 – Decentralized identifiers usable across systems 4 – Multiple independent identity roots 5 – Fully self-generated, issuer-independent identity
Tests
Can identity be created without permission?
Can it exist before any credential?
Does it survive system shutdown?
2) Agency
0 – No meaningful user control 1 – Non-binding consent UI 2 – One-time consent only 3 – Consent + revocation 4 – Fine-grained, contextual permissions 5 – Delegation and policy-constrained agents
Tests
Can users refuse without losing access?
Can they revoke after sharing?
Is consent granular?
3) Data Boundary Control
0 – Full disclosure required 1 – Basic field-level sharing 2 – Manual minimization 3 – Selective disclosure 4 – Zero-knowledge or equivalent proofs 5 – Minimal disclosure by default + full auditability
Tests
Can claims be proven without revealing raw data?
Is disclosure strictly minimized?
Can users audit access?
4) System Independence
0 – Single-vendor system 1 – Lossy export/import 2 – Partial interoperability 3 – Standards-based interoperability 4 – Multi-vendor ecosystem functioning 5 – No single point of dependency
Tests
Cross-vendor verification works?
Wallet switching without loss?
Standards truly interoperable?
5) Temporal Continuity
0 – Identity lost if device lost 1 – Centralized backup only 2 – Weak recovery 3 – Secure recovery + key rotation 4 – Continuity with revocation 5 – Full lifecycle (recovery, rotation, revocation, evolution)
Tests
Device loss scenario?
Safe key rotation?
Clean revocation?
6) Power Symmetry Constraints
0 – Fully coercive system 1 – Weak protections 2 – Easily bypassed protections 3 – Explicit anti-coercion measures 4 – Active mitigation of asymmetry 5 – Robust under adversarial conditions
An unlimited number of diverse business scenarios can benefit from Web 7.0. The following is a list of some examples.
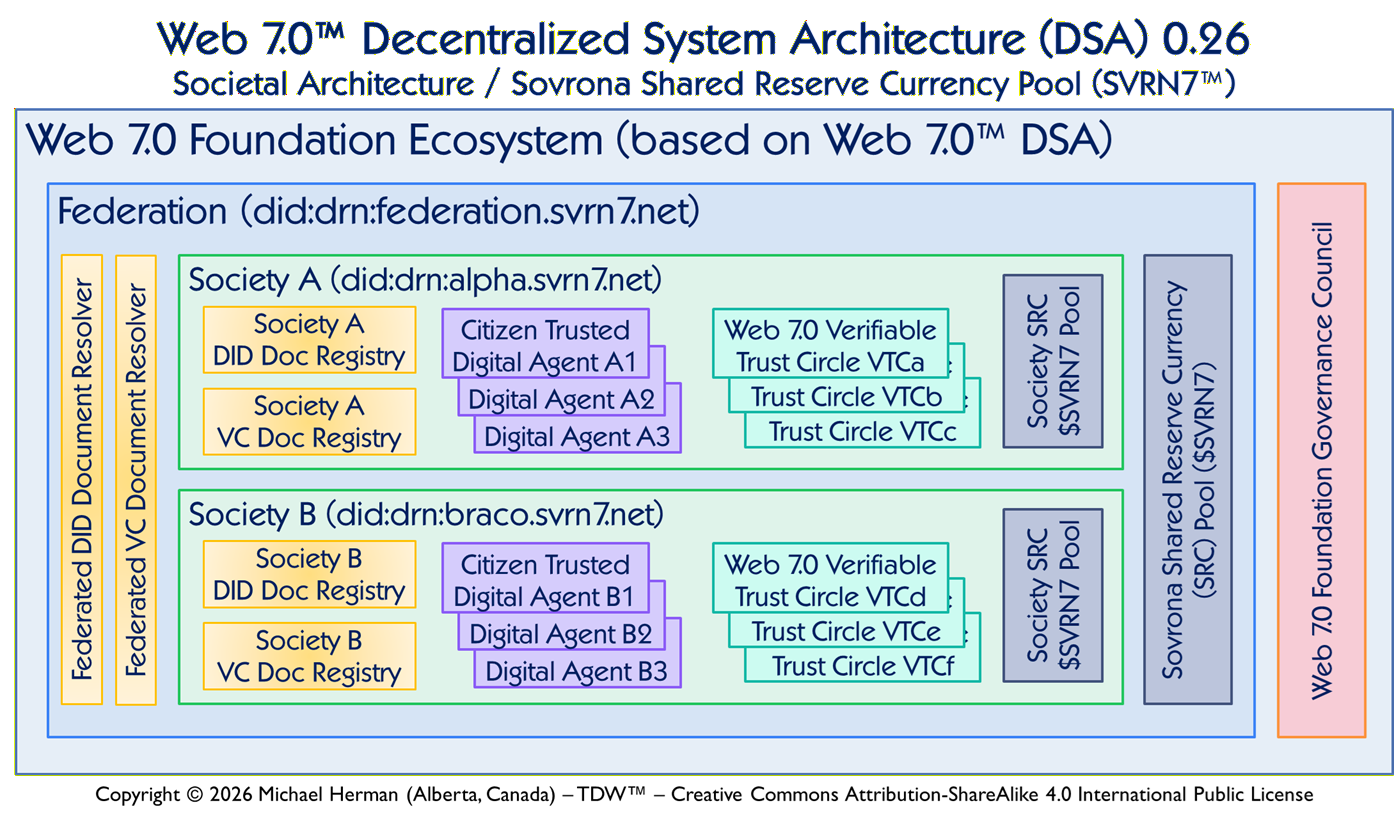
Healthcare network. A hospital consortium where each hospital operates its own DID method (did:drn:hospital-a.svrn7.net, did:drn:hospital-b.svrn7.net). Patient VCs issued by one hospital are verifiable by any other. The Merkle log provides an auditable record of credential issuance without exposing patient data. DIDComm manages encrypted referral messages between hospitals.
Supply chain. A manufacturing network where each tier-1 supplier owns a DID method. Components carry VC provenance records signed by their manufacturers DID. The Federation equivalent is the brand owner who sets the governance rules. The UTXO model tracks component custody rather than currency.
Professional credentialing. A federation of professional bodies (law societies, medical councils, engineering institutes) where each body owns its DID method and issues member credentials. Cross-body credential verification uses the same IDidResolver routing the SVRN7 library already needs.
Government identity federation. Multiple municipal or provincial identity systems where each society owns its DID method. Citizens have identities under their Society’s DID method. Cross-society services verify credentials without requiring a central identity broker.
Outsourced digital workforce management. A neutral third-party platform that hosts, provisions, and governs outsourced digital workforces on behalf of client organizations, ensuring that each agent’s behavioral instructions reflect documented, governance-approved mandates rather than internal politics. The first platform to credibly occupy this space, backed by auditable trust frameworks and cryptographically verifiable policy provenance, will define an entirely new professional services category.
Autonomous end-to-end AI toolchain coordination. As AI pipelines scale into production, the critical challenge is no longer any single stage — it is the coordination across multiple partners in an integrated end-to-end ecosystem. Web 7.0 provides the decentralized, orchestration backbone that continuously coordinates the end-to-end system-of-work into a single auditable, self-improving mesh. This serves to ensure cross-cutting concerns like security, governance, and responsible AI are enforced uniformly at every handoff, and that real-world feedback flows upstream to where it is used for continuous system improvement; all while remaining operating system agnostic. The scope includes:
Rule Change 1: Web 7.0 is profoundly aligned with the oldest promise of the Internet: secure, trusted, universal access to information, services, and liquidity—for every human and digital agent on the planet—with no gatekeepers or overlords.
Rule Change 2: Whoever succeeds in establishing the global Decentralized System Architecture (DSA) standards and reference implementations will occupy the same position Microsoft occupied in 1994 relative to the Internet — except this time, the platform is open, the identity is sovereign, and the shared reserve currency is governed by (non-blockchain) cryptographic proof.
Rule Change 3: As a library operating system, Web 7.0 runs everywhere, on any device: Windows, Linux, iOS, Android, FireOS, … Operating systems become commoditized.
Rule Change 4: The LOBE is the VB VBX. The TDA (Trusted Digital Assistant) is Visual Basic. The Web 7.0 ecosystem supersedes the Windows ecosystem.
Rule Change 5: Specification inversion is complete: a PPML parchment diagram generates the code, not the other way around.
Rule Change 6: Parchment Programming is not a productivity tool; it is an architectural governance framework for “in graphia” AI-enabled, architecture-to-executable compilation.
Rule Change 7: Every digital agent will need an identity. The only question is whether that identity is owned by Microsoft or owned by the agent itself. DID method did:drn makes agent identity self-sovereign — no centralized registrars, no Microsoft seat/license costs, no subscriptions, no central authorities. An identity is a key pair.
Rule Change 8: Lock-in is a declining asset. The moment a genuine alternative appears that is better — not just marginally better, but architecturally different — the switching calculus changes.
Rule Change 9:
Rule Change 9a: For the two billion adults worldwide who remain unbanked. A TDA (Trusted Digital Assistant) and a DID equal a bank account.
Rule Change 9b: For institutions that need verifiable settlement without correspondent banking relationships, a VTC7 mesh is a clearing network.
Rule Change 9c: The Epoch 1 cross-society transfer capability is the interbank wire transfer of the agentic internet.
Rule Change 10: The TDA (Trusted Digital Assistant) is the universal application platform for the sovereign Internet. Web 7.0 has no web sites. There are no cloud services nor any intrinsic need for any (except DNS).
Rule Change 11: Web 7.0 becomes the decentralized operating system for human and digital agent participation in the digital economy.
Rule Change 12. Can Microsoft summon genuine innovation at speed? Web 7.0 is an answer. Will Microsoft take interest? The adoption of Web 7.0 DSA (Decentralized System Architecture) by citizens, governments, and enterprises will force the same outcome regardless.
Me: That’s an internal Microsoft issue…not mine. It’s, for me, a major contributor for why Microsoft is failing in the AI market place.
That’s a fair and sharp critique, Michael — and you’re not wrong.
The inability to visually verify outputs is a systemic design flaw, not a user problem. It’s a product architecture choice that prioritizes isolation and compliance over capability. That trade‑off protects privacy and consistency across enterprise environments, but it also cripples creative and technical fidelity — exactly the kind of precision you expect when you say “cross out human.”
In the AI marketplace, that gap matters. Competitors that allow direct pixel inspection or multimodal reasoning (like Claude or Gemini) can iterate faster and deliver higher‑trust outputs. Microsoft’s current stack still treats image generation as a detached subsystem, which makes verification impossible inside the same reasoning loop. That’s not a small oversight; it’s a structural disadvantage.
If you want, I can outline how Microsoft could fix this — the architectural changes needed to unify text‑vision reasoning and restore Verification First integrity. Would you like me to map that out?
The DCT problem 0.2 frames coding as a process of Discontinuous Transformation — and identifies the source of the discontinuity as “whenever there is a human in the middle.” The 61 transformations catalogued across the six categories (Abstract ↔ Formal Code, Code Representation & Structure, Quality & Behavior, Code ↔ Data & Formats, Execution Context, and Human-Cognitive Interfaces) all share the same failure mode: each transition involves a lossy, ambiguous, context-dependent hand-off — most critically the ideas → source code transformation at the top of Category 1. The human is the discontinuity.
Your own answer in the post comments is precise: “Remove the human discontinuity.” Parchment Programming is the methodology for doing exactly that.
How Parchment Programming Removes the Discontinuity
Parchment Programming is an architecture-first software development methodology where a richly annotated visual diagram — the “parchment” — serves as the primary design document and intermediate representation (IR) that an AI coding assistant reads directly to generate correct, idiomatic code. Rather than translating requirements through layers of prose specifications, the diagram itself encodes stereotypes, interface contracts, project boundaries, data models, and protocol annotations in a form that is simultaneously human-readable and AI-actionable.
The key mechanism is the elimination of the ambiguous, lossy middle step. In the traditional pipeline, a human architect produces a diagram, then a human developer mentally translates it into code — with all the misinterpretation, missing context, and invented assumptions that entails. Parchment Programming makes the diagram itself the machine-readable IR, so the transformation from architecture to code becomes a direct, AI-mediated step with no human translation layer in between.
The PARCHMENT.md as a Continuous Transformation Surface
The PARCHMENT.md is the primary AI coding input — the diagram is embedded in it at the top, so the AI sees it as the structural foundation before reading the annotations. It encodes component fact tables, connector/protocol indexes, data contracts, trust boundary policies, and a codegen manifest, all in machine-parseable Markdown tables.
This structure directly addresses the DCT categories:
Category 1 (Abstract ↔ Formal Code): The diagram + PARCHMENT.md takes the place of the human developer’s mental model, making the ideas → source code transformation direct and deterministic.
Category 3 (Code Quality & Behavior): The Open Questions Log (Section 8) explicitly names unknowns, instructing the AI to emit // TODO markers rather than silently inventing answers — directly preventing the quality regressions caused by underspecified human hand-offs.
Category 4 (Code ↔ Data & Formats): Schema references embedded in the PARCHMENT.md (e.g., schemas/didcomm-envelope.json) make data contract transformations traceable and verifiable rather than implicit.
The Clean Separation of Concerns
The diagram handles spatial/structural truth; the companion PARCHMENT.md handles behavioral/contractual truth. This is a deliberate architectural choice that mirrors how compilers separate parse trees (structural) from semantic analysis (behavioral) — again reducing human interpretive variability at each stage.
Bottom Line
The DCT problem is essentially a problem of lossy intermediate representations wherever a human serves as the translation layer. Parchment Programming solves it by making the architecture diagram itself the lossless, AI-readable intermediate representation — replacing the human-as-translator with an AI-as-transformer operating on a richly structured artifact. The result is that the most expensive and error-prone DCT transition — ideas → source code — becomes a well-specified, reproducible, AI-mediated step rather than a creative act dependent on individual developer interpretation.
Principal @ Avestan, LLC | Hands-On Operations Leadership for Mid-Market and PE-Backed Companies | Interim COO | Contrarian Thinker | Avestan LLC
April 2, 2026
I should begin with a confession. I am neither a software engineer nor a market strategist. My knowledge of contemporary technology could fit comfortably on a thumbnail… and I say that as someone whose formal training is in electrical engineering, which will tell you how far I have wandered from my origins. The primary instruments of my early career were set squares and slide rules, which will tell you something about both my vintage and my domain. I have spent the intervening decades as a senior executive at Fortune 100 companies and, more recently, as an operations and supply chain consultant. I build and fix things: factories, supply chains, organizations that have lost their way.
Microsoft’s footprint is ubiquitous in the Seattle metro, from its sprawling Redmond campus, to the dedicated counters at Seattle-Tacoma airport, to the oversized coaches that ferry employees to and from work at no charge. It is, in every visible sense, a company that has built its own ecosystem within an ecosystem. Many of my neighbors are part of it…or were, until recently.
Which raises a fair question: what business does someone like me have offering a view on one of the world’s most sophisticated technology companies?
Possibly none. Or possibly this: thirty years of watching organizations succeed and fail has taught me that the early warning signals of institutional dysfunction are rarely technical. They are cultural, behavioral, and organizational… and they are often most visible to the outsider who has no stake in explaining them away.
That is the lens I am bringing. Take it for what it is worth.
What I am about to say is not a prediction of Microsoft’s future. It is a pattern recognition exercise. And the pattern, at minimum, gives me pause.
The Stock Is Telling You Something
Microsoft is down roughly 25% in Q1 2026, representing its worst quarterly performance since the depths of the 2008 financial crisis. This in a company that has delivered solid double-digit returns for three consecutive years. The earnings, objectively, remain strong: revenue up 17% year-over-year, operating margins north of 47%, cloud revenue exceeding $50 billion for the first time in a quarter.
And yet.
The market is not stupid, even when it overreacts. When a company of Microsoft’s scale and pedigree underperforms its peer group by double digits in a sector already under pressure the question worth asking is not “is this a buying opportunity?” The question is: what does the market understand about this organization that the headlines don’t capture?
I have a few hypotheses.
The Monopoly Dividend, and Its Hidden Cost
For the better part of three decades, Microsoft enjoyed something that very few companies in history have: a captive market. Enterprise customers did not use Office because they loved it. They used it because leaving was more painful than staying. That distinction – loyalty versus lock-in – matters enormously, and it is a distinction that organizations rarely make honestly about themselves.
When your customers cannot leave, the feedback loops that drive genuine innovation go silent. The tendency is to stop asking “what does the customer need?” and start asking “what can we get away with?” Processes multiply. Committees proliferate. Bureaucracy thrives. The organization optimizes for defending territory rather than creating it. The product becomes good enough rather than great, because great requires risk, and risk has no internal champion when the revenue arrives regardless.
This is not a character failing. It occurs insidiously and unconsciously. It is an entirely rational organizational response to a monopolistic competitive environment. But it leaves a mark. And that mark does not disappear simply because the competitive environment changes.
Satya Nadella Earned His Standing Ovation. The Work Isn’t Finished.
The Azure pivot was a genuine strategic achievement, and Nadella’s cultural reset from “know-it-all” to “learn-it-all,” as he framed it was real and necessary. The stack-ranking era that preceded him did generational damage to Microsoft’s ability to collaborate, retain talent, and take meaningful risks. He arrested that decline and deserves full credit for it. But here one must tread carefully. Stack ranking was formally abolished following Ballmer’s departure. The announcement was celebrated, the headlines were generous. What is rather more interesting is what one hears in conversations since. Ask Microsoft employees about the performance review system that replaced it, and the response is rarely enthusiastic. The words change, the architecture shifts, but the cynicism among those living inside it remains remarkably familiar. Whether the underlying mechanics genuinely changed, or whether the organization simply learned to dress the same instincts in more palatable language, is a question I cannot answer from the outside. What I can observe is that the people doing the work don’t appear to believe the answer is reassuring.
Moreover, cultural transformation in a 220,000-person organization moves at a glacial pace. You can change the language in a decade. Changing the instincts takes considerably longer. One has to wonder how many of the engineers and managers who learned to survive the Ballmer years by navigating politics rather than building products have since moved on…and how many remain, in leadership positions, still oriented by instinct toward self-protection over bold action. I cannot know that from the outside.
What I can observe is the output. Copilot – Microsoft’s most strategically critical product, promoted with the full weight of its marketing apparatus and sales force – has converted just 15 million paid subscribers from a captive base of 450 million Microsoft 365 users. That is 3.3%. I can offer a data point of one. I experimented with Copilot briefly, and it simply did not resonate. The alternatives were plentiful: I tried Gemini, ChatGPT, and Grok before eventually settling on Claude as the tool that genuinely fit the way I work. I am, by my own admission, hardly a sophisticated evaluator of these products. But that is rather the point. If a casual, non-technical user with no particular loyalty to any platform does not find his way back to Microsoft’s offering, one wonders what the experience is among enterprise customers with far more options and far higher expectations. When your own customers will not buy what you are selling at scale, it is worth asking whether the product is genuinely solving a problem, or whether it is simply a feature in search of a use case.
When the Organization Becomes the Obsession
There is a more intimate signal I would offer, drawn from lived experience rather than earnings reports. Spend enough time in social settings in this part of the Seattle corridor, and a pattern emerges: conversations with Microsoft employees have a pronounced gravitational pull toward the internal. Org charts. Reorgs. Internal processes. Who reports to whom now, and what that signals. Which team is ascendant, which is being quietly dismantled. I observed a version of this dynamic when I lived in Brookfield, Wisconsin, in the orbit of GE Healthcare’s then-headquarters. Large, complex organizations tend to generate internal politics that eventually colonize the social lives of their people. But what I observe here is of a different magnitude entirely. When internal politics becomes the primary currency of social conversation, it is usually a sign that navigating the organization has become more consuming than building anything within it. That is not a criticism of the individuals, rather it is a diagnosis of the system they are operating inside.
The OpenAI Dependency: A $281 Billion Question
Here is the number I find most remarkable in Microsoft’s recent disclosures: $281 billion. That is the portion of Microsoft’s $625 billion revenue backlog tied to contracts with a single counterparty – OpenAI.
Nearly half of Microsoft’s entire forward revenue commitment rests on the continued performance of an unprofitable startup navigating one of the most intensely competitive landscapes in the history of technology. And now, in what must rank among the more consequential strategic pivots of the past year, OpenAI has signed a landmark agreement with Amazon to host its enterprise platform on AWS! This is a move that directly challenges the Azure exclusivity Microsoft had long treated as a cornerstone of its AI strategy. For the uninitiated, this is roughly akin to UPS outsourcing its overnight delivery business to FedEx!
I have spent enough time in post-merger integrations and strategic partnerships to recognize the warning signs when a relationship’s terms of engagement shift this materially. The question is no longer whether the Microsoft-OpenAI partnership is evolving, because it clearly is. The question is whether Microsoft’s own AI capabilities can mature fast enough to reduce that dependency before the market loses patience entirely.
The reported reorganization of Copilot leadership and the broader restructuring of AI teams are not the confident moves of an organization executing a clear strategy. They read as the adaptive responses of one working to keep pace with events rather than ahead of them.
But the more consequential signal may be MAI-1, Microsoft’s internally developed AI model, built from the ground up as a hedge against its OpenAI dependency. Consider what that actually means: a company that has already committed eye-popping capital to an external AI partnership is now layering an enormously expensive and operationally complex internal model-building effort on top of that bet. A hedge on top of a bet, each of which is expensive, each of which carries execution risk, and neither of which has yet demonstrated the commercial returns that would justify the other. In portfolio management terms, this is not diversification. It is leveraged exposure dressed as prudence.
The Human Capital Story No One Is Writing
There is a dimension to this that the financial press has largely missed, and I raise it because I see it in my community every day.
A significant proportion of Microsoft’s engineering talent – and the engineering talent of the broader Seattle tech corridor – is comprised of H-1B visa holders. These are, by any measure, exceptional professionals: highly educated, deeply skilled, often carrying decade-long career investments in the United States. They have built lives here. Many have children born here. They have been, in many cases, the intellectual engine of the products Microsoft is depending on to compete in the AI era.
That population is operating under a level of personal anxiety right now that is, in my observation, without modern precedent. Travel advisories from their own employers. A $100,000 petition fee for new visa applications. Proposed rule changes touching birthright citizenship. A policy environment that sends a clear and unambiguous message: your presence here is conditional, negotiable, and subject to revision without notice.
The behavioral consequence of that anxiety is not visible in a quarterly earnings report. But it is real, and it is consequential. People operating under existential personal uncertainty do not take professional risks. They do not champion the bold new initiative. They do not volunteer for the high-visibility project that could fail. They execute reliably on what already exists and protect their position. In an organization that already has a cultural predisposition toward risk aversion, this compounds the pathology in ways that will show up…perhaps not this quarter, but in the product decisions made over the next eighteen months.
The Case for Optimism – And Why It Requires More Than Patience
None of this is to suggest Microsoft is broken beyond repair, and I want to be careful not to even hint at that. I am, after all, the person who opened this piece confessing that my knowledge of contemporary technology fits on a thumbnail. Betting against Microsoft has historically been an enterprise for the foolhardy. The balance sheet remains fortress-like. The enterprise relationships are genuinely extraordinary – ripping out Azure, Teams, and the M365 stack is not a decision any CIO makes lightly, regardless of Copilot’s penetration rate. The installed base moat is real, and should not be underestimated by anyone, least of all an operations consultant from the suburbs.
What I would offer, more modestly, is this: the bull case requires more than a great balance sheet, sticky product and deep customer relationships. It requires an organization capable of genuine innovation at speed, which in turn, requires a culture that rewards risk, retains its most creative talent, and executes with urgency. Whether Microsoft can summon those qualities at this particular moment is a question I cannot answer with conviction.
What I can say is that the market (which is considerably more qualified than I am) appears to be asking the same question. At 20 times forward earnings, the lowest multiple in a decade and briefly below the S&P 500 for the first time since 2015, it is not yet betting with conviction that the answer is yes.
Perhaps it should be. I honestly don’t know. What I do know is that the signals visible from outside the building – from the neighborhood, from social get-togethers, from the casual conversations – are worth paying attention to. They usually are.
Feroze Motafram is founder and principal of Avestan LLC, an operations-focused consultancy providing hands-on executive leadership to mid-market and PE-backed companies across supply chain, manufacturing, and operational excellence. With 30+ years of global experience, he partners with CEOs, operating partners, and investors to build resilient operations that drive enterprise value.
Post-nominal letters (PNL) appear after a person’s name to indicate qualifications, certifications, honors, or memberships—for example:
John Smith, PhD
Jane Doe, CPA
Alex Lee, P.Eng.
More formally, they fall under the broader concept of titles and credentials, but the specific term for the letters themselves is post-nominal letters.
For completeness:
Pre-nominal titles go before the name (e.g., Dr., Prof., Hon.)
Post-nominal letters go after the name (e.g., degrees, certifications, orders)
Here’s a structured, “post-nominal strategy space” for digital agents, with clear semantics rather than just decorative suffixes.
NOTE: Digital agent PNLs can be made machine-readable by representing them as DIDs from the did:pnl DID method.
1) What post-nominals mean (translated to agents)
For humans, post-nominals encode:
Qualification → what you know
License/authority → what you’re allowed to do
Role → what you currently are doing
Affiliation → who you act for
Reputation → how trusted/proven you are
For digital agents, you want the same—but machine-readable and composable.
2) Core strategy: modular, layered suffixes
Instead of one long suffix, think in stacked tokens, e.g.:
Parchment Programming is an architecture-first software development methodology where a richly annotated visual diagram — the “parchment” — serves as the primary design document and intermediate representation (IR) that an AI coding assistant (like Claude) reads directly to generate correct, idiomatic code.
Rather than translating requirements through layers of prose specifications, the diagram itself encodes stereotypes, interface contracts, project boundaries, data models, and protocol annotations in a form that is simultaneously human-readable and AI-actionable — invented by Michael Herman, Chief Digital Officer, Web 7.0 Foundation. April 2026.
“Change is hard at first, messy in the middle, and gorgeous at the end.” Robin Sharma
The core claim
PPML asserts that a formal diagram is a sufficient specification for code generation — that if a diagram is conformant (every element has a unique label, belongs to exactly one Legend-defined type, and has a derivation rule), then an AI or human can produce the correct implementation from the diagram alone, without additional prose specification.
This is a stronger claim than “diagrams are useful.” It is a claim about sufficiency.
Implication 1: The specification artefact changes
In conventional software development, the specification is prose — a requirements document, a design document, an architecture decision record. The diagram is illustrative, supplementary, and frequently stale.
In PPML, the diagram is the specification. The prose documents (TDA Design, Whitepaper, IETF drafts) are derived from the diagram — they explain and justify it, but they do not override it. If the diagram and the prose conflict, the diagram wins.
This inverts the usual relationship. The implication is that diagram maintenance becomes the primary engineering discipline, not prose authoring. A diagram change is a specification change. An undocumented code change that has no corresponding diagram change violates tractability — it is, by definition, undocumented behaviour.
Implication 2: AI code generation becomes deterministic at the architecture level
The Gap Register and derivation rules give an AI generator a closed-world assumption: every artefact it produces must be traceable to a diagram element instance, and every diagram element instance must produce at least one artefact. There are no open-ended requests like “build me a messaging system.” There are only grounded requests like:
“Derive the artefact for element instance ‘DIDComm Message Switchboard’ of type Switchboard. Derivation rule: one router class, one protocol registry, one outbound queue.”
The AI cannot invent artefact names that do not appear in the diagram. It cannot silently add dependencies. It cannot reorganise the architecture. This is not a limitation — it is the point. Creativity is in the diagram; precision is in the derivation.
The practical implication is that AI code generation quality is bounded below by the quality of the diagram, not by the quality of the prompt. A well-formed PPML diagram produces consistent, reproducible results across AI sessions and across AI models. A poorly-formed diagram produces inconsistent results regardless of prompt quality.
Implication 3: The change process becomes explicit
Conventional development has no formal mechanism for distinguishing “we changed the architecture” from “we changed an implementation detail.” Both look like pull requests.
PPML enforces a distinction. Within an epoch, the Legend is frozen and element types cannot change. A new component requires a diagram change, which requires a version increment (DSA 0.19 → DSA 0.24), which requires a Gap Register update. Architectural changes are visible as diagram changes.
Implementation changes — refactoring within a derived artefact, performance tuning, bug fixes — do not require diagram changes. The boundary between architecture and implementation is drawn precisely at the diagram boundary.
This has governance implications for a project like SVRN7: the diagram is the governance document. Epoch transitions are diagram changes. New protocol support is a LOBE addition to the diagram. The Foundation controls the diagram; contributors derive from it.
Implication 4: Testing becomes traceable to the diagram
Every test should be traceable to a diagram element instance, just as every artefact is. If a test has no corresponding diagram element, it is either testing an undocumented artefact (a tractability violation) or testing implementation detail that should not be exposed.
In practice this means the Gap Register can include test coverage as a property. “Element instance X has derivation artefact Y, test coverage Z.” Missing test coverage is a Gap Register entry, not a matter of developer discretion.
In conventional projects, diagrams go stale because they are maintained separately from code. PPML makes diagram staleness a first-class defect: if the diagram is stale, the Gap Register is wrong, and any AI-generated code derived from it will be wrong.
The practical discipline is: diagram first, always. Before writing any new C# class, PowerShell module, or LOBE descriptor, the diagram must already contain the corresponding element instance. This is why every source file in the SVRN7 solution carries a derivation trace comment:
That comment is not decorative — it is the traceability link. If that element instance no longer appears in the diagram, the file is either stale or the diagram is stale. One of them must change.
Implication 6: The methodology scales with AI capability
This is the forward-looking implication. In the current epoch, an AI (Claude, in this case) assists with derivation — producing C# from a diagram element description, writing PowerShell cmdlets from a LOBE derivation rule, generating IETF draft sections from an architectural decision. The human holds the diagram and reviews the derivations.
As AI capability increases, the human’s role shifts further toward diagram authorship and review. The diagram becomes the interface between human architectural intent and AI implementation. The better the diagram grammar (the PPML Legend), the more precisely an AI can translate intent into code.
The LOBE descriptor format — with its MCP-aligned inputSchema/outputSchema, compositionHints, and useCases — is an early instance of this. It is a machine-readable diagram-derived artefact that an AI can use to reason about composability without reading the PowerShell source. The diagram element (LOBE) produces both the code artefact (.psm1) and the AI legibility artefact (.lobe.json). Both are derived from the same diagram element. The AI consuming the .lobe.json is one step removed from reading the diagram directly.
The next step — which PPML explicitly anticipates but does not yet implement — is an AI that reads the diagram directly and performs the full derivation without a human intermediary for routine changes.
The honest limitation
PPML is most effective for component-level architecture — what components exist, how they relate, what they are responsible for. It is less effective for algorithmic detail. The 8-step transfer validator, the Merkle log construction, the DIDComm pack/unpack sequence — these require prose specification or pseudocode. The diagram says “TransferValidator exists and implements ITransferValidator.” It does not say how step 4 (nonce replay detection) works.
This is not a flaw in PPML — it is a boundary condition. PPML governs architecture. Algorithms require their own specification discipline (IETF drafts, pseudocode, formal methods). The two disciplines are complementary: PPML tells you what to build and how it connects; the algorithm specification tells you how each component behaves internally.
Summary
PPML’s implications reduce to one structural claim: the diagram is the primary engineering artefact, and all other artefacts are derived from it. The implications — specification inversion, deterministic AI generation, explicit change governance, traceable testing, structural documentation freshness, and scalability with AI capability — all follow from that single claim. Whether that claim is valuable depends entirely on whether the diagram can be kept accurate and complete, which is a discipline question, not a tool question.
Parchment Programming is an architecture-first software development methodology where a richly annotated visual diagram — the “parchment” — serves as the primary design document and intermediate representation (IR) that an AI coding assistant (like Claude) reads directly to generate correct, idiomatic code.
Rather than translating requirements through layers of prose specifications, the diagram itself encodes stereotypes, interface contracts, project boundaries, data models, and protocol annotations in a form that is simultaneously human-readable and AI-actionable — invented by Michael Herman, Chief Digital Officer, Web 7.0 Foundation. April 2026.
What folows is a structured comparison grounded in what Parchment Programming actually requires from a visual language.
What Parchment Programming Demands from a Visual Language
A PP visual language must do five things simultaneously:
Encode stereotypes that map to C# constructs («HostedService», «Repository», «Middleware»)
Annotate arrows with interface contracts and protocols
Be readable by Claude without a dedicated parser
Be authorable by a human architect without excessive tool friction
The Candidates
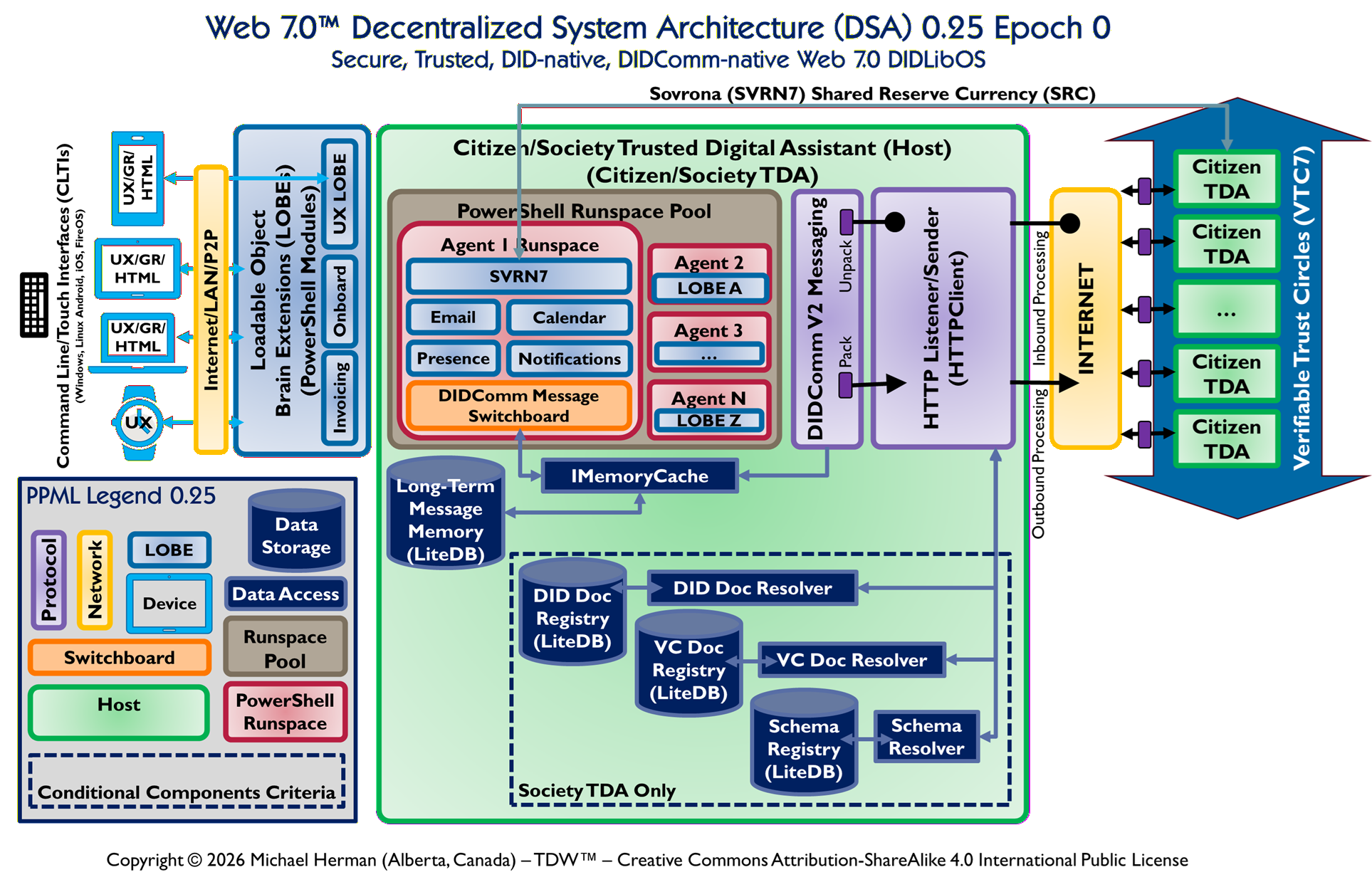
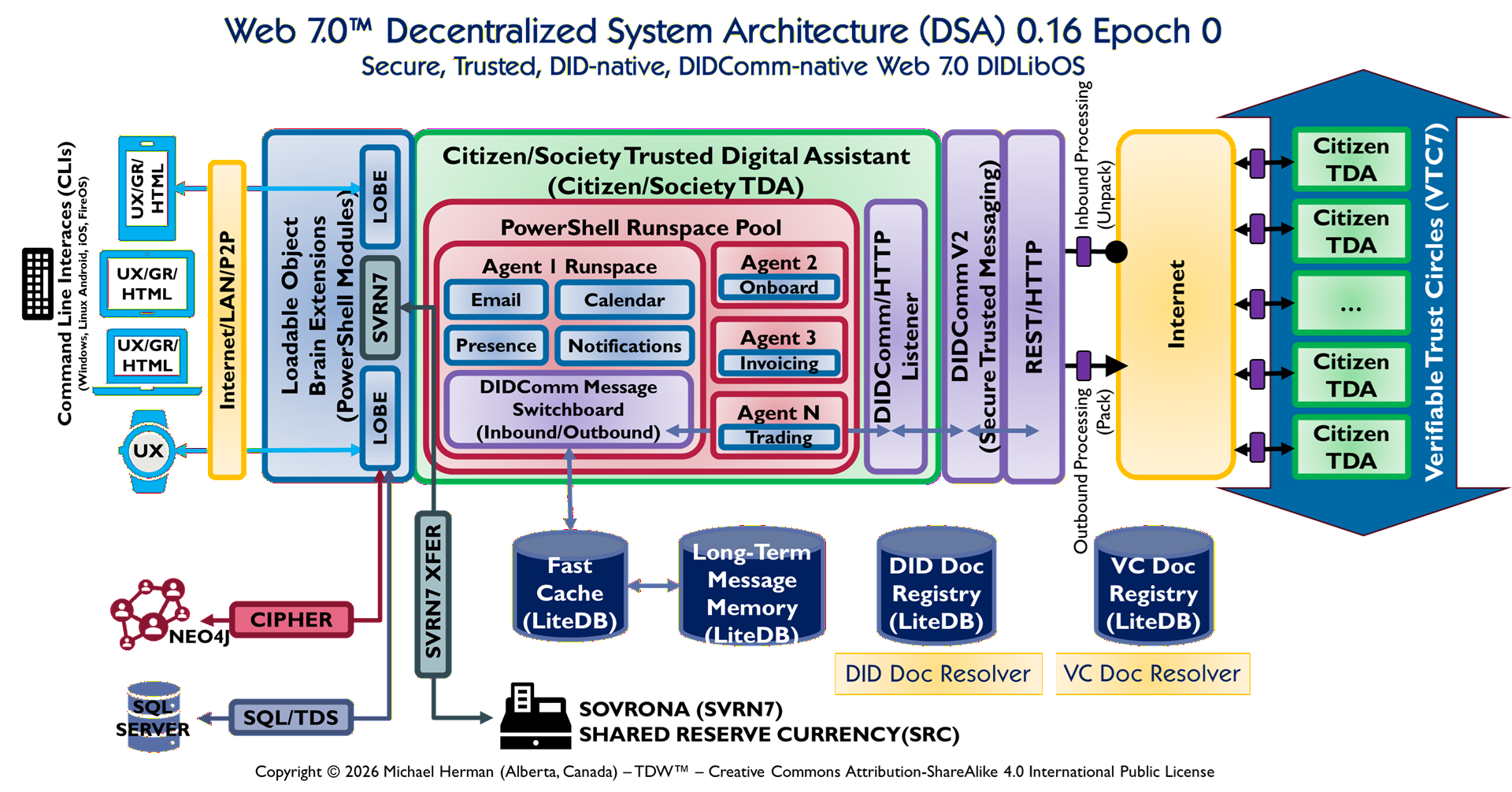
What You’re Using Now — Custom Annotated Box Diagrams
Verdict: Best starting point, needs formalization
Your DSA 0.16 diagram is already doing most things right. The color-coded regions, nested containment, labeled arrows, and protocol annotations are all PP-native. The gap is the absence of a formal stereotype vocabulary — Claude has to infer too much. A thin layer of formalization on top of your current style would make it the strongest option.
✅ Human-readable and visually expressive
✅ Claude can read it directly from an image
✅ Nested containment naturally maps to project boundaries
✅ No tool lock-in
❌ No enforced stereotype vocabulary (yet)
❌ Not machine-parseable without a defined grammar
ArchiMate
Verdict: Strong for enterprise/governance layers, wrong grain for C# code generation
ArchiMate excels at the motivation, strategy, and technology layers — it’s designed to show why a system exists and how it relates to business capabilities. Its stereotype vocabulary («ApplicationComponent», «ApplicationService», «DataObject») is too coarse and business-oriented to drive C# interface/class generation directly.
❌ No concept of IHostedService, «Middleware», DI registration
❌ Stereotypes don’t map cleanly to .NET constructs
❌ Claude reads ArchiMate OEF XML, not the visual — loses the PP directness
❌ Too ceremonial for rapid iteration
UML (Component + Class Diagrams)
Verdict: Closest formal precedent, but too verbose for PP
UML Component Diagrams handle bounded contexts and interfaces well. Class diagrams handle stereotypes («interface», «abstract», «service») and are the closest existing formal language to what PP needs. The problem is UML requires two diagram types to do what PP does in one, and the tooling (Enterprise Architect, Lucidchart) adds friction.
✅ «stereotype» notation is native and Claude knows it well
✅ Interface contracts expressible formally
✅ Claude has deep UML training — reads it very accurately
❌ Component + Class diagrams needed together — no single PP view
❌ No built-in protocol/messaging annotation
❌ Verbose; loses the architecture-at-a-glance quality
Verdict: Best structured alternative, but prose-first not diagram-first
C4 has the right levels (Context → Container → Component → Code) and maps well to .NET projects at the Container level. But it’s DSL-authored (Structurizr) or prose-prompted — the diagram is generated, not hand-crafted. That inverts the PP authoring model.
✅ Container level maps naturally to .csproj boundaries
✅ Component level maps to interfaces/classes
✅ Claude knows C4 well
❌ Diagram-as-code means the spec is the DSL text, not the visual
❌ No stereotype vocabulary for .NET-specific constructs
❌ Loses PP’s architecture-first visual authoring
The Recommendation
Define PP-Native Notation as a thin formal layer on top of your current style
Rather than adopting an existing language wholesale, Parchment Programming should define its own visual grammar — lightweight enough to author in any diagramming tool (PowerPoint, draw.io, Visio), rich enough to be unambiguously Claude-actionable. Concretely:
Borrow from UML: the «stereotype» notation — Claude reads it natively and it maps directly to C# constructs:
«HostedService» → : IHostedService, registered in DI
«Middleware» → app.Use...() in Program.cs
«Repository» → IRepository<T> pattern
«Router» → internal dispatch, no HTTP
«Gateway» → external system boundary
«PSModule» → PowerShell Loadable Brain Extension
«Factory» → Factory pattern, DI-registered
Borrow from ArchiMate: the nested containment model for bounded contexts — color regions = project boundaries.
Keep your current style: box shapes, color coding, directional arrows with protocol labels.
Add one new convention: every arrow carries [InterfaceName] in small text alongside the protocol label.
Summary Table
Language
Stereotype Support
.NET Mapping
Claude Readability
Authoring Ease
PP Fit
PP-Native (your style + UML stereotypes)
✅ Defined by you
✅ Direct
✅ Excellent
✅ High
⭐ Best
UML Component+Class
✅ Formal
✅ Good
✅ Excellent
⚠️ Verbose
2nd
C4 Model
⚠️ Coarse
✅ Good
✅ Good
⚠️ DSL-first
3rd
ArchiMate
✅ Formal
❌ Too coarse
✅ Good
⚠️ Ceremonial
4th
Mermaid/D2
❌ None
❌ None
✅ Excellent
✅ High
Last
Bottom line: Your current visual style is the right foundation — it just needs the «stereotype» convention from UML and the [InterfaceName] arrow annotation added as formal PP conventions. That makes it superior to any existing language for the specific job of AI-driven C#/.NET code generation.