My Wishes for a #NewAlbertan (read slowly like Paul Harvey would say it)
Ask your Dad for a fingertip drip of Jameson. Learn how to kiss …passionately. Clip your fingernails …really close. Wear Bleu De Chanel. Smile a lot.
Learn to dance the polka, two-step, and jive. Slow dancing will come on its own. Buy flowers …lots of flowers. Take your Mom out on “school nights”. Throw the baseball with Dad. Smile a lot.
Learn to use a real calf rope. Drive a pickup truck …nothing else. Learn to pick crocuses and wild roses. Valpolicella Ripasso is a great wine until you can afford Amarone. Smile even more.
Travel, yes travel …to Spain, Netherlands, and Poland. Eat great food. Make your Mom buy you a pickle canner. Love your Mom and your Dad but especially your Mother. Smile even more.
Never forget you’re an Albertan. Buy a ranch some day. Wherever life takes you, never forget what an Alberta sky looks like. Love country music. Smile.
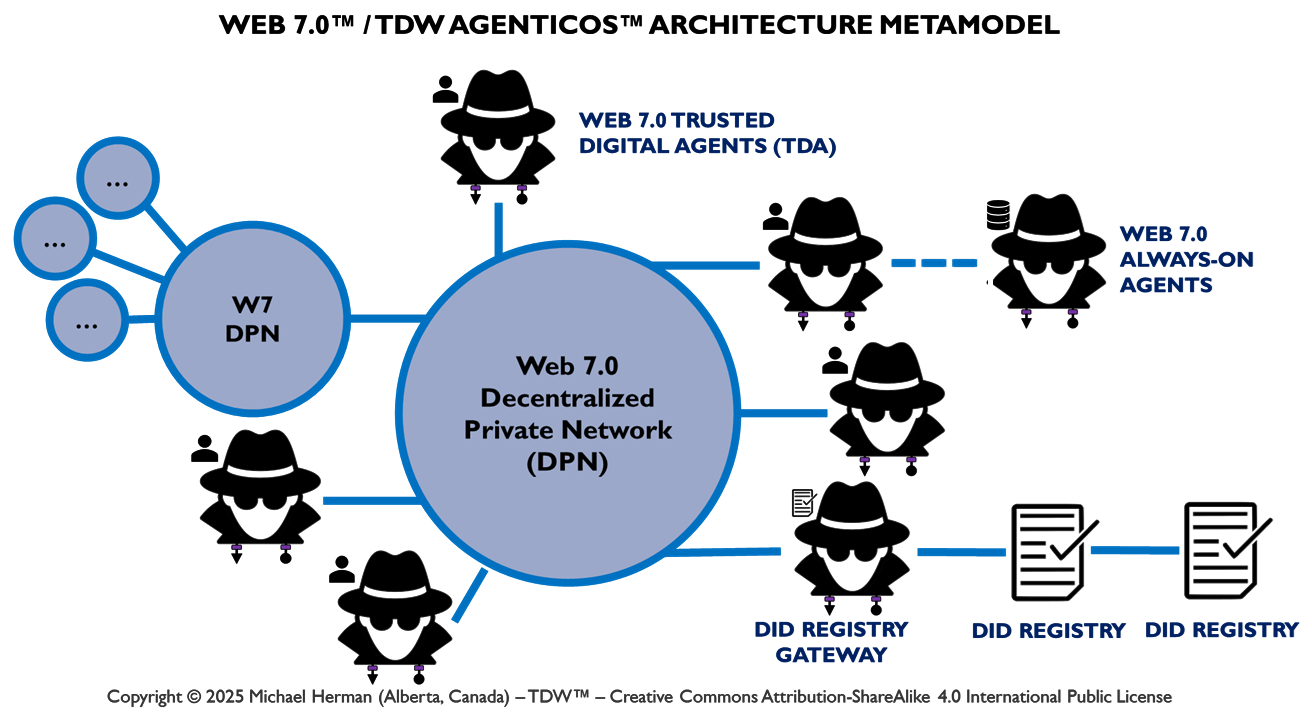
This article describes Web 7.0™ and TDW AgenticOS ™ – with a specific focus on the Web 7.0 NeuromorphicAgent Architecture Reference Model (NAARM) used by TDW AgenticOS™ to support the creation of Web 7.0 Decentralized Societies.
The intended audience for this document is a broad range of professionals interested in furthering their understanding of TDW AgenticOS for use in software apps, agents, and services. This includes software architects, application developers, and user experience (UX) specialists, as well as people involved in a broad range of standards efforts related to decentralized identity, verifiable credentials, and secure storage.
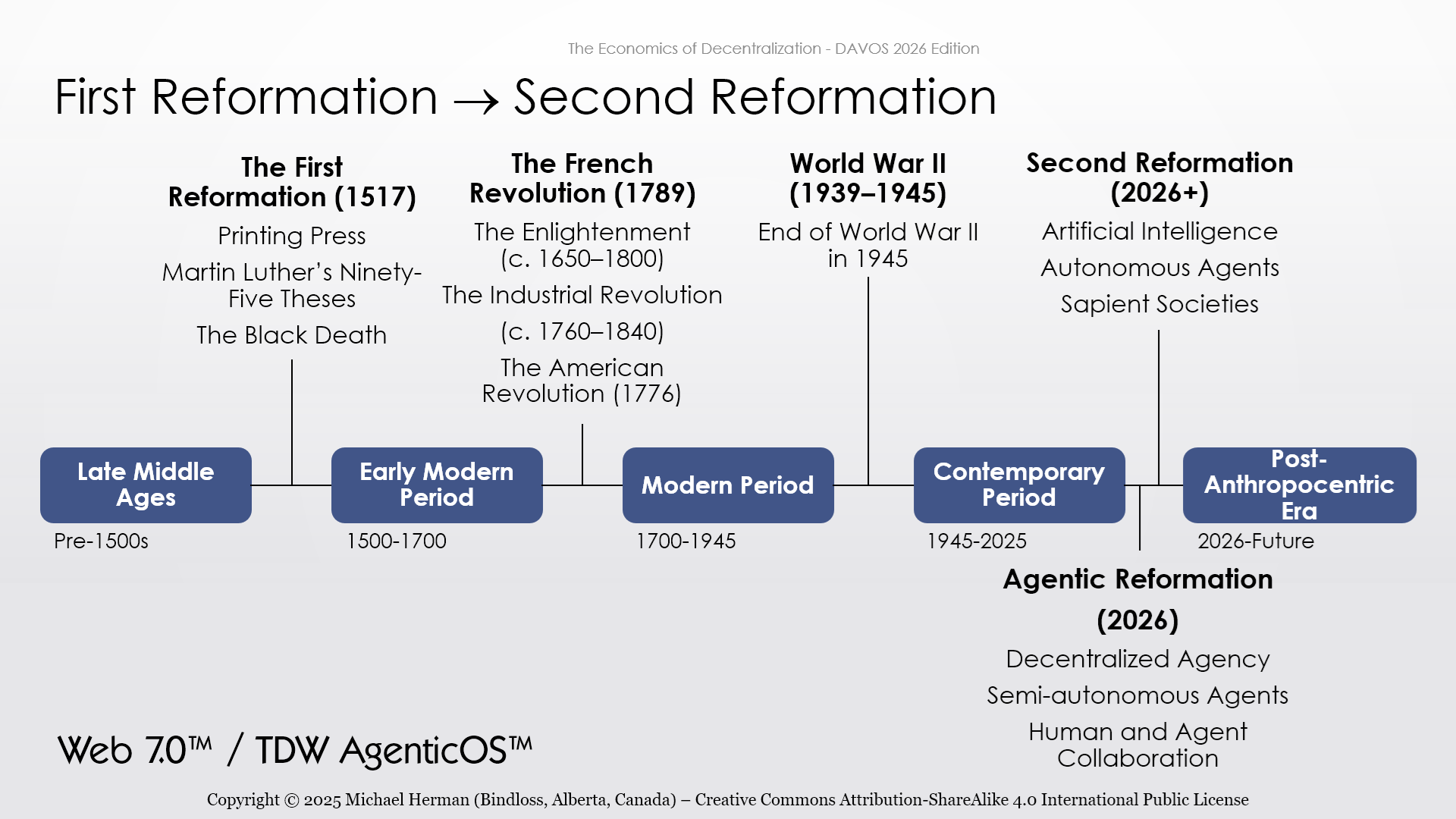
The Second Reformation
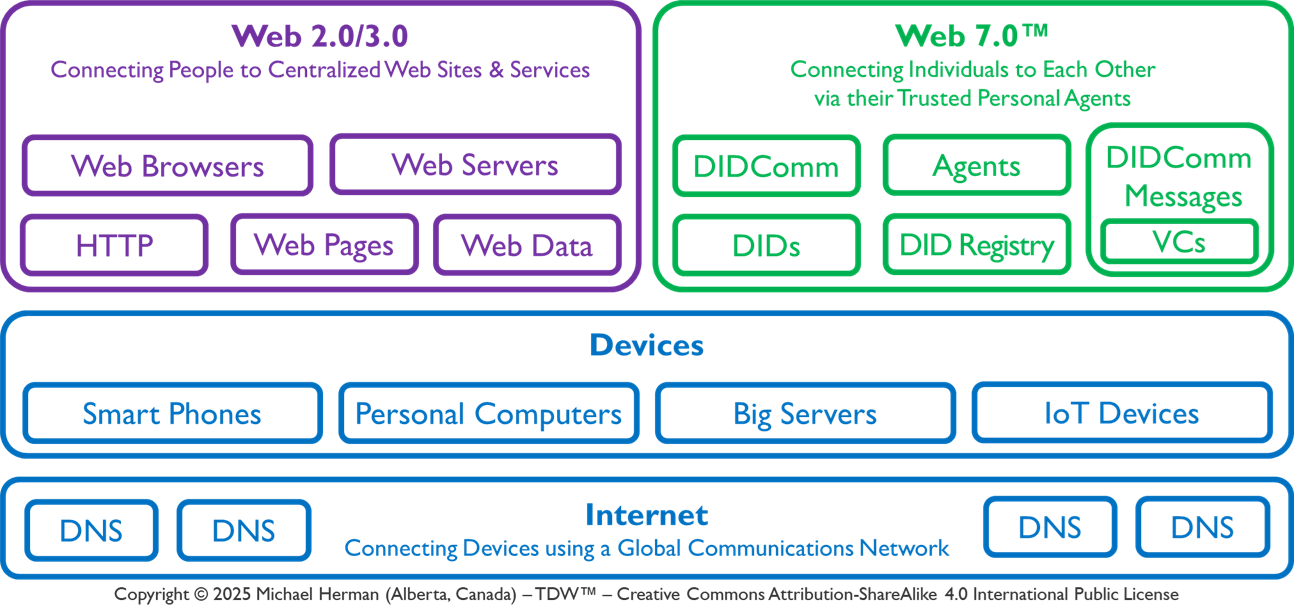
Web 7.0 Foundation Ecosystem
“Web 7.0 is a unified software and hardware ecosystem for building resilient, trusted, decentralized systems using decentralized identifiers, DIDComm agents, and verifiable credentials.” Michael Herman, Trusted Digital Web (TDW) Project, Hyperonomy Digital Identity Lab, Web 7.0 Foundation. January 2023.
TDW AgenticOS™ is a macromodular, neuromorphic agent platform for coordinating and executing complex systems of work that is:
Secure
Trusted
Open
Resilient
TDW AgenticOS™ is 100% Albertan by birth and open source.
Project “Shorthorn”
Project “Shorthorn” is a parody project name based on Microsoft’s Windows “Longhorn” WinFS project (a SQL-based Windows File System project) with which the author was involved in from a design preview and feedback, consulting, and PM technical training (Groove Workspace system architecture and operation) perspectives (circa 2001-2002).
What makes Shorthorns great: – They’re good at turning grass into meat (great efficiency). – Shorthorn cows are amazing mothers and raise strong, healthy calves (nurture great offspring). – Their genetics blend well with other breeds for strong hybrid calves (plays well with others). …and so it is with TDW AgenticOS™.
Web 7.0 Foundation
The Web 7.0 Foundation, a federally-incorporated Canadian non-profit corporation, is chartered to develop, support, promote, protect, and curate the Web 7.0 ecosystem: TDW AgenticOS operating system software, and related standards and specifications. The Foundation is based in Alberta, Canada.
What we’re building at the Web 7.0 Foundation is described in this quote from Don Tapscott and co.:
“We see an alternate path: a decentralized platform for our digital selves, free from total corporate control and within our reach, thanks to co-emerging technologies.” “A discussion has begun about “democratizing AI.” Accessibility is critical. Mostaque has argued that the world needs what he calls “Universal Basic AI.” Some in the technology industry have argued that AI can be democratized through open source software that is available for anyone to use, modify, and distribute. Mostaque argues that this is not enough. “AI also needs to be transparent,” meaning that AI systems should be auditable and explainable, allowing researchers to examine their decision-making processes. “AI should not be a single capability on monolithic servers but a modular structure that people can build on,” said Mostaque. “That can’t go down or be corrupted or manipulated by powerful forces. AI needs to be decentralized in both technology, ownership and governance.” He’s right.” You to the Power Two. Don Tapscott and co. 2025.
A Word about the Past
The Web 7.0 project has roots dating back approximately 30 years to before 1998 with the release of Alias Upfront for Windows. Subsequent to the release of Upfront (which Bill Gates designated as the “most outstanding graphics product for Microsoft Windows 3.0”), the AUSOM Application Design Framework was formalized.
AUSOM Application Design Framework
AUSOM is an acronym for A User State of Mind — the name of a framework or architecture for designing software applications that are easier to design, implement, test, document and support. In addition, an application developed using the AUSOM framework is more capable of being: incrementally enhanced, progressively installed and updated, dynamically configured and is capable of being implemented in many execution environments. This paper describes the Core Framework, the status of its current runtime implementations and its additional features and benefits.
What is AUSOM?
The AUSOM Application Design Framework, developed in 1998, is a new way to design client-side applications. The original implementation of the framework is based on a few basic concepts: user scenarios and detailed task analysis, visual design using state-transition diagrams, and implementation using traditional Windows message handlers.
The original motivation for the framework grew out of the need to implement a highly modeless user interface that was comprised of commands or tasks that were very modal (e.g. allowing the user to change how a polygon was being viewed while the user was still sketching the boundary of the polygon).
The following is essentially the same advice I received from Charles Simonyi when we were both at Microsoft (and one of the reasons why I eventually left the company in 2001).
“No problem can be solved from the same level of consciousness that created it.” [Albert Einstein] “The meaning of this quote lies in Einstein’s belief that problems are not just technical failures but outcomes of deeper ways of thinking. He suggested that when people approach challenges using the same assumptions, values, and mental habits that led to those challenges, real solutions remain out of reach. Accoding to this idea, improvement begins only when individuals are willing to step beyond familiar thought patterns and question the mindset that shaped the problem.” [Economic Times]
Simonyi et al., in the paper Intentional Software, state:
For the creation of any software, two kinds of contributions need to be combined even though they are not at all similar: those of the domain providing the problem statement and those of software engineering providing the.implementation. They need to be woven together to form the program.
TDW AgenticOS is the software for building decentralized societies.
A Word about the Future
“Before the next century is over, human beings will no longer be the most intelligent or capable type of entity on the planet. Actually, let me take that back. The truth of that last statement depends on how we define human.” Ray Kurzweil. 1999.
NOTE: “Artificial Intelligence” (or “AI”) does not appear anywhere in the remainder of this article. The northstar of the Web 7.0 project is to be a unified software and hardware ecosystem for building resilient, trusted, decentralized systems using decentralized identifiers, DIDComm agents, and verifiable credentials – regardless of whether the outcome (a Web 7.0 network) uses AI or not. Refer to Figures 4a, 4b, and 6 for a better understanding.
DIDComm Notation, a visual language for architecting and designing decentralized systems, was used to create the figures in this article.
Value Proposition
By Personna
Business Analyst – Ability to design and execute, secure, trusted business processes of arbitrary complexity across multiple parties in multiple organizations – anywhere on the planet.
Global Hyperscaler Administrators – Ability to design and execute, secure, trusted systems administration processes (executed using PowerShell) of arbitrary complexity across an unlimited number of physical or virtual servers hosted by an unlimited number of datacenters, deployed by multiple cloud (or in-house) xAAS providers – anywhere on the planet.
App Developers – Ability to design, build, deploy, and manage secure, trusted network-effect-by-default apps of arbitrary complexity across multiple devices owned by anybody – anywhere on the planet.
Smartphone Vendors – Ability to upsell a new category of a second device, a Web 7.0 Always-on Trusted Digital Assistant – a pre-integrated hardware and software solution, that pairs with the smart device that a person already owns. Instead of a person typically purchasing/leasing one smartphone, they can now leverage a Web 7.0-enabled smartphone bundle that also includes a secure, trusted, and decentralized communications link to a Web 7.0 Always-on Trusted Digital Assistant deployed at home (or in a cloud of their choosing).
Digital Church/Religion Builders – Ability to create a new decentralized digital religion for 1 billion people in Communist China.
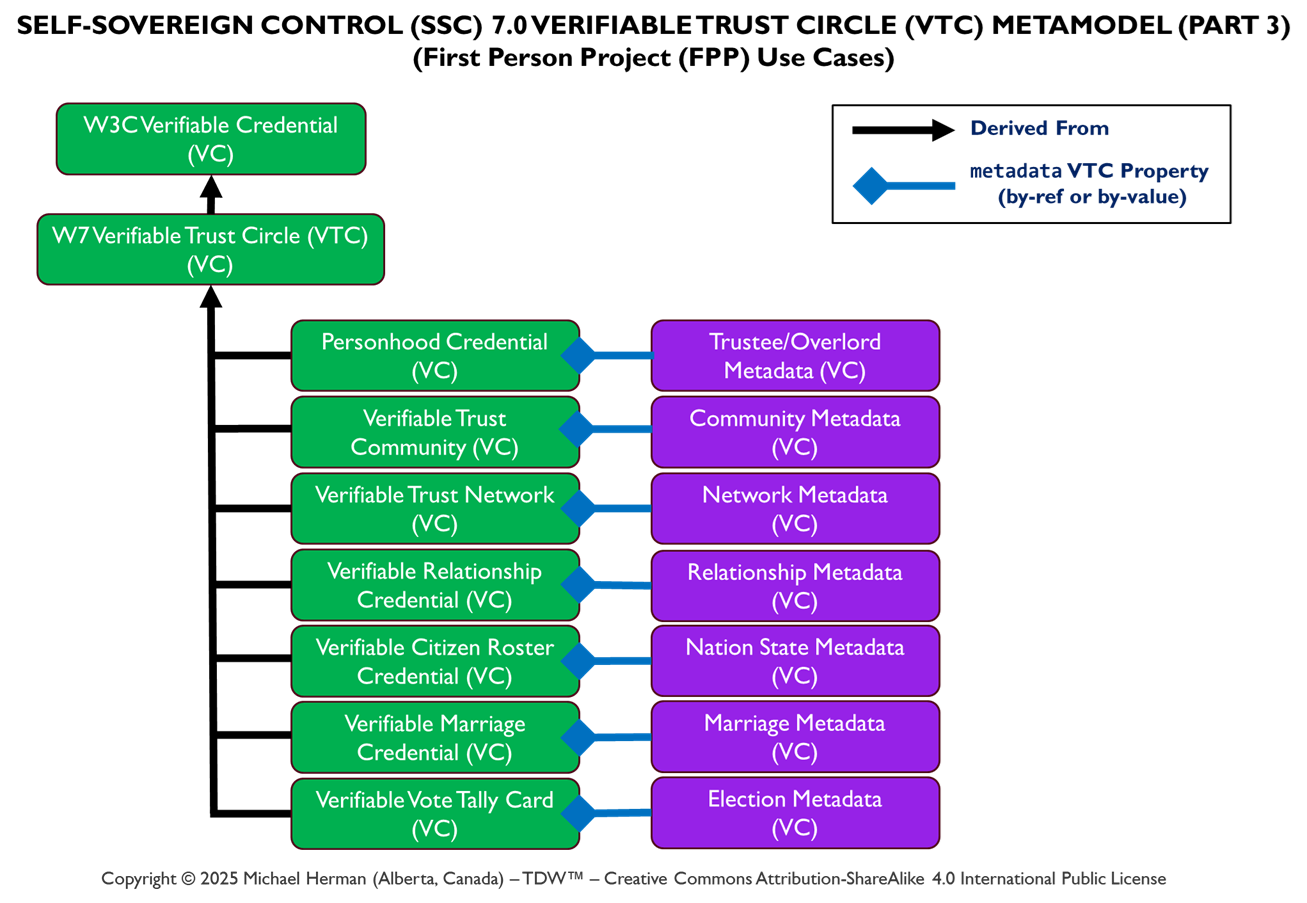
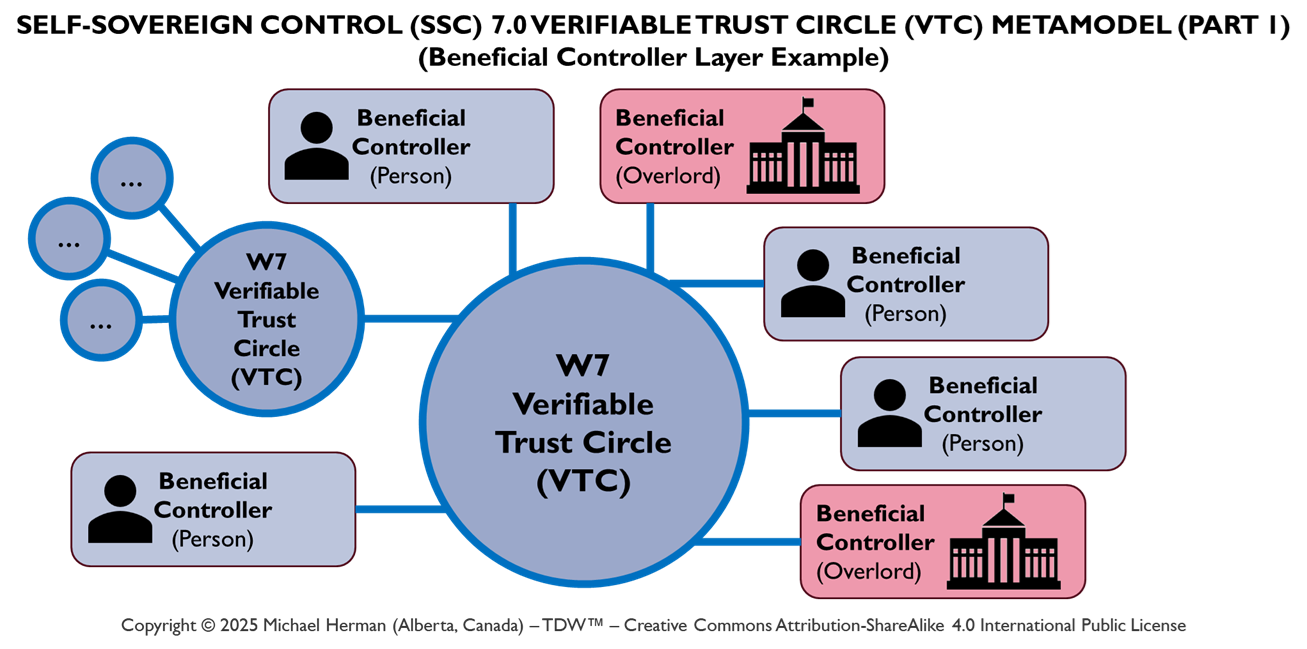
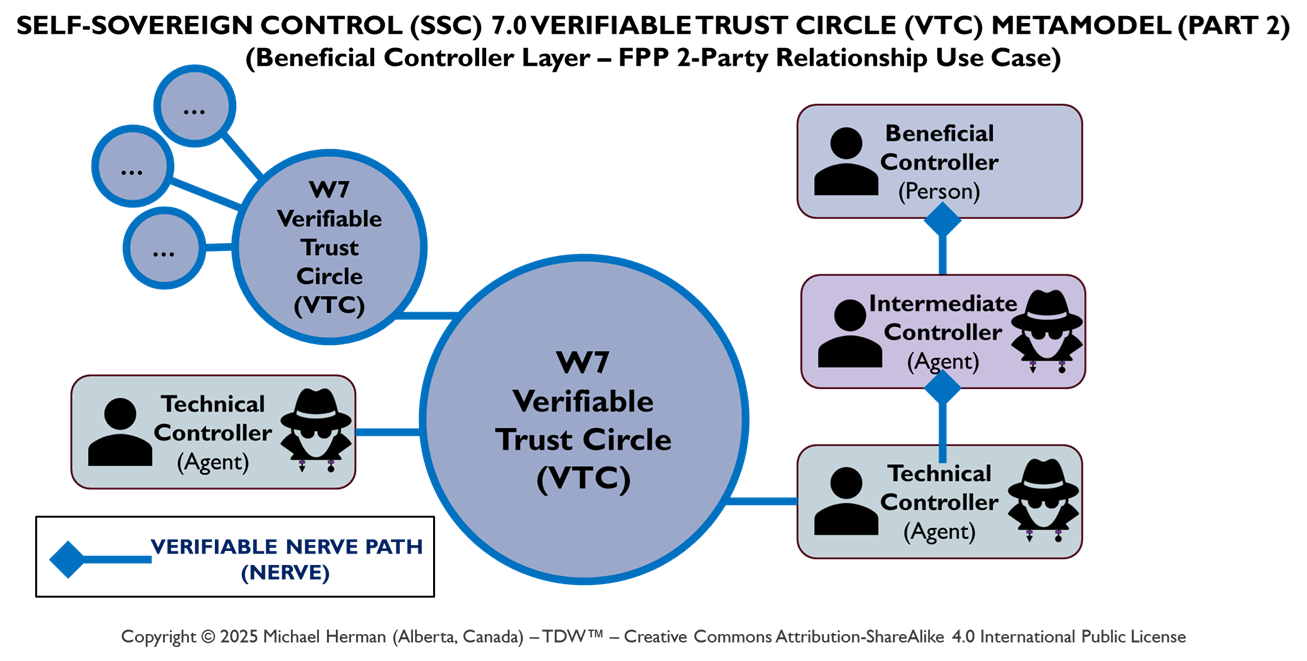
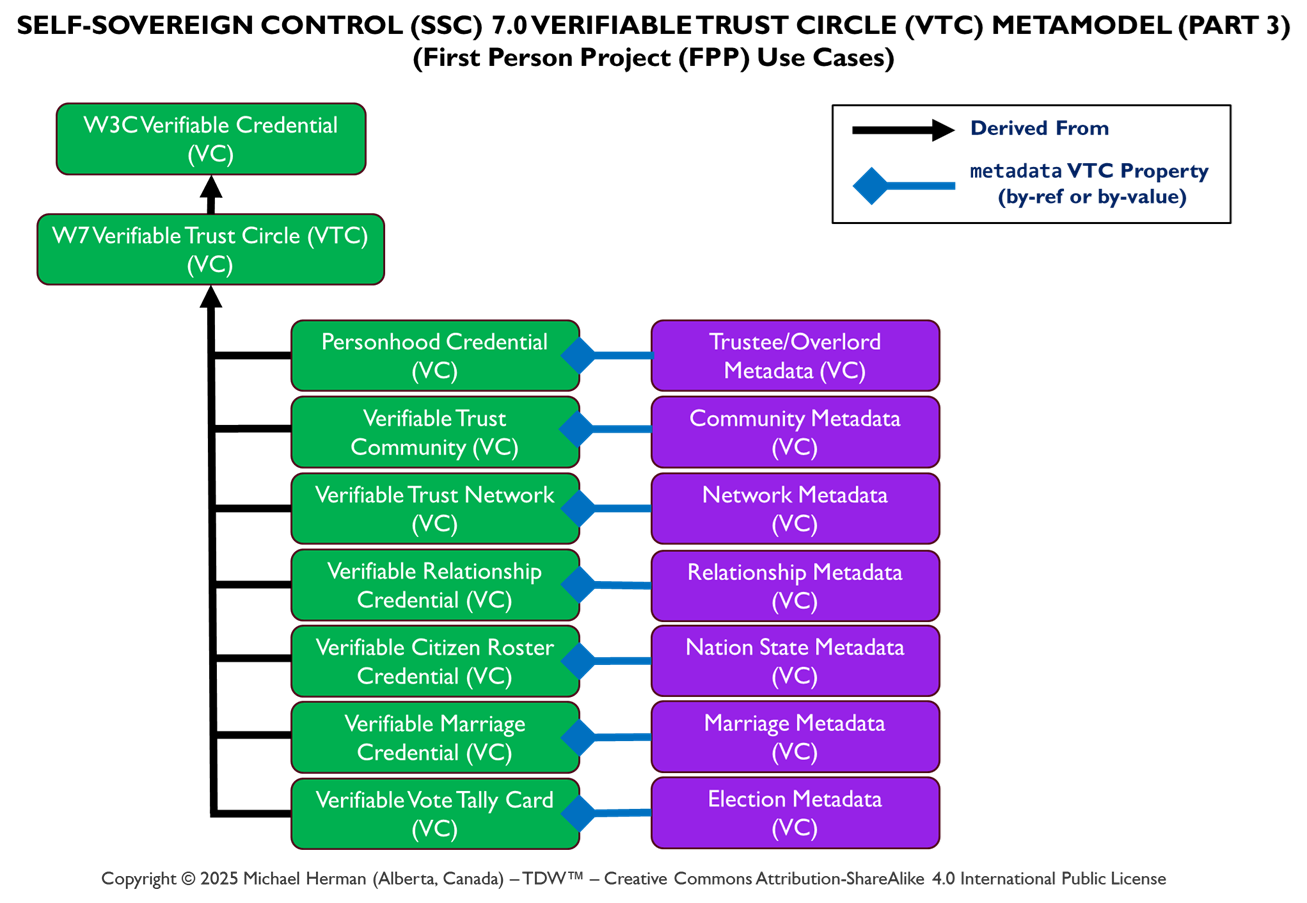
By Trust Relationship (Verifiable Trust Circle (VTC))
Secure, Trusted Agent-to-Agent Messaging Model
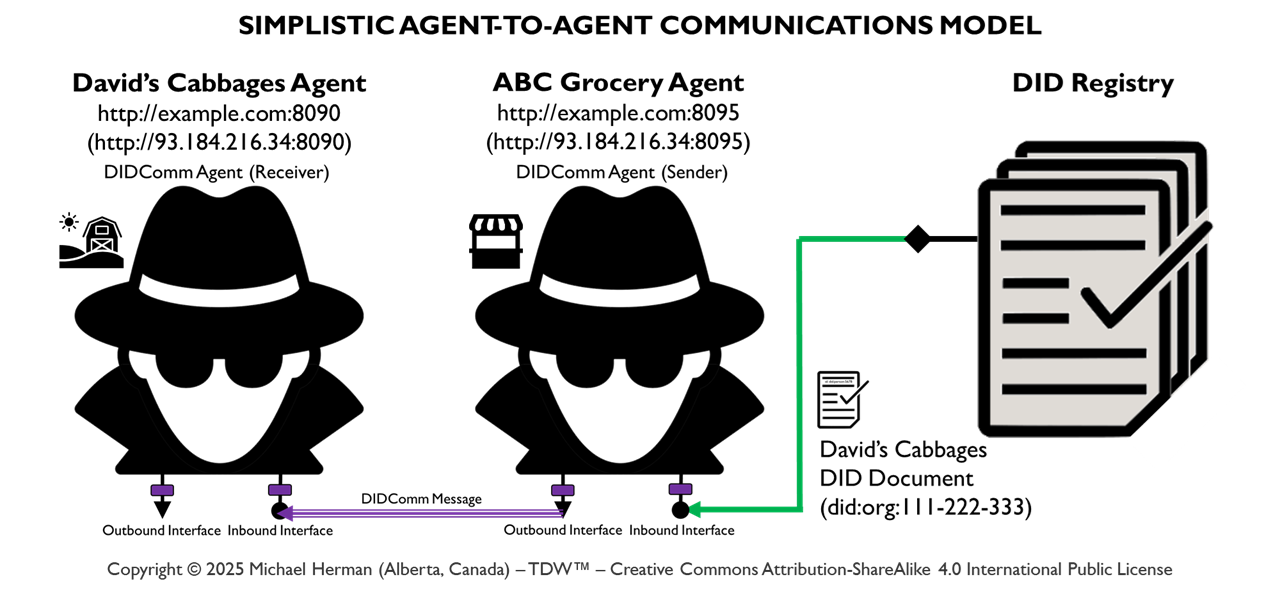
Figure 0. Simple Agent-to-Agent Communications Model
Figure 0. depicts the design of a typical simple agent-to-agent communications model. DIDComm Notation was used to create the diagram.
TDW AgenticOS: Conceptual and Logical Architecture
The Web 7.0 architecture is illustrated in the following figure.
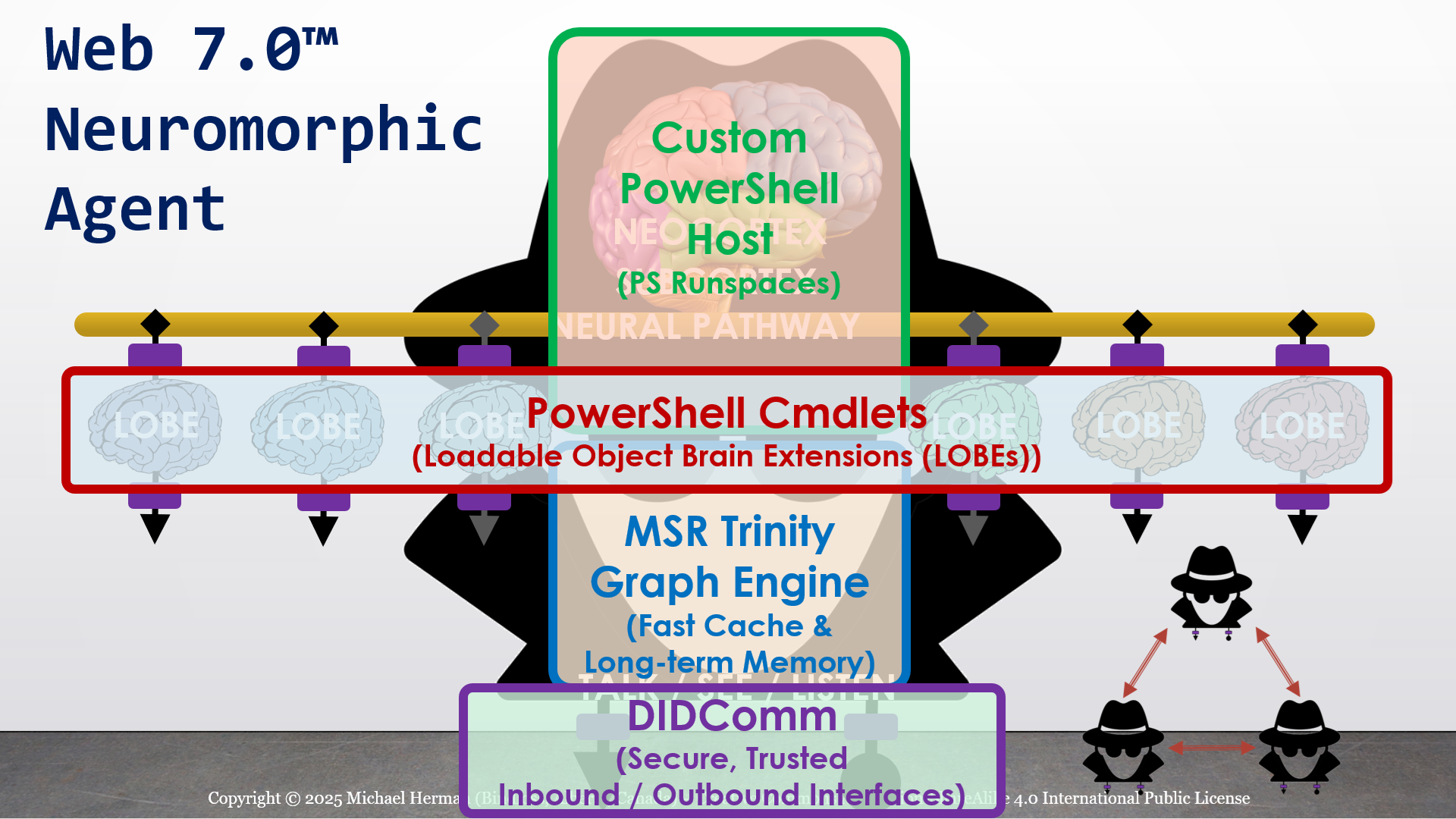
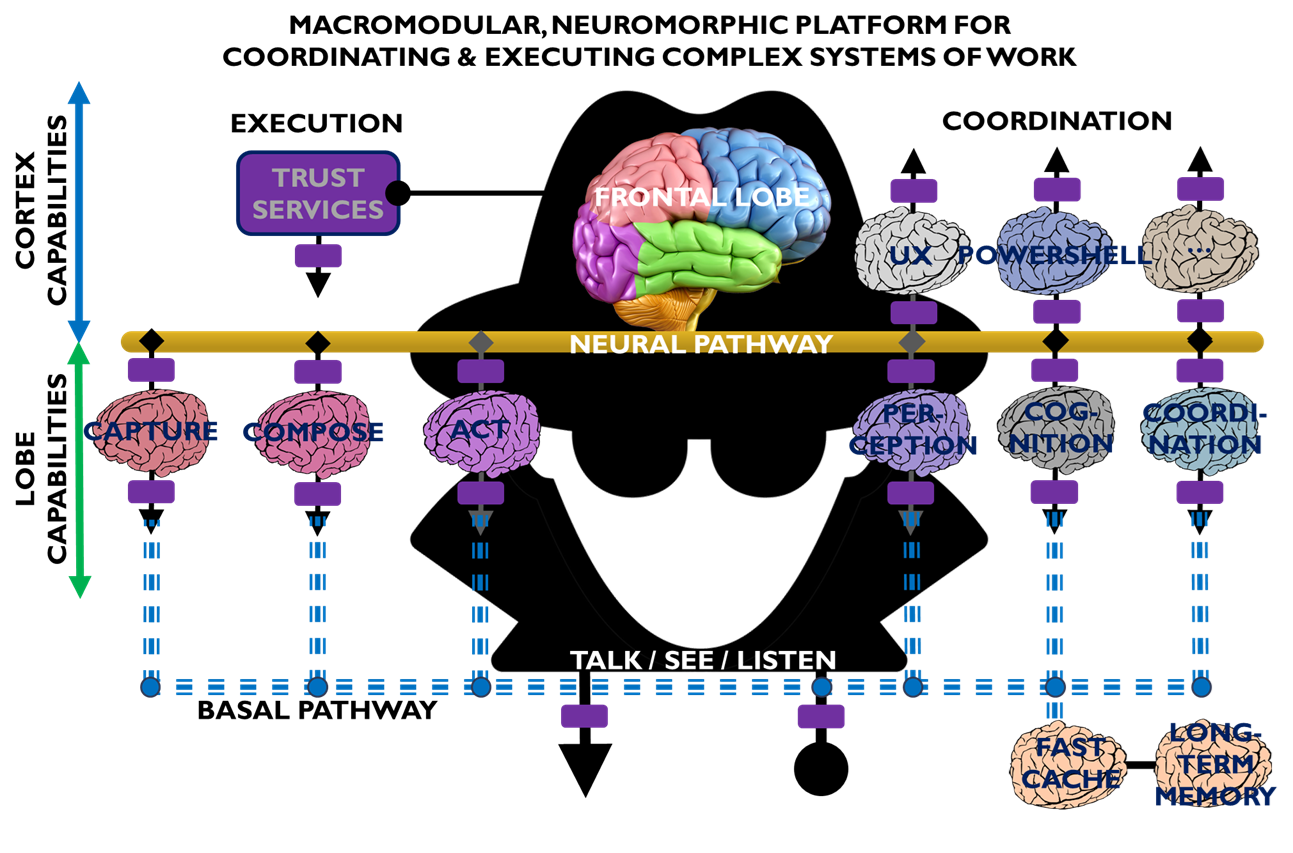
Figure 1. Web 7.0 Neuromorphic Agent
Figure 1 is an all-in illustration of the conceptual architecture of a Web 7.0 Neuromorphic Agent. A Web 7.0 Agent is comprised of a Frontal LOBE and the Neural Messaging pathway. An Agent communicates with the outside world (other Web 7.0 Agents) using its Outbound (Talking), Seeing, and Inbound (Listening) Interfaces. Agents can be grouped together into Neural Clusters to form secure and trusted multi-agent organisms. DIDComm/HTTP is the default secure digital communications protocol (see DIDComm Messages as the Steel Shipping Containers of Secure, Trusted Digital Communication). The Decentralized Identifiers (DIDs) specification is used to define the Identity layer in the Web 7.0 Messaging Superstack (see Figure 6 as well as Decentralized Identifiers (DIDs) as Barcodes for Secure, Trusted Digital Communication).
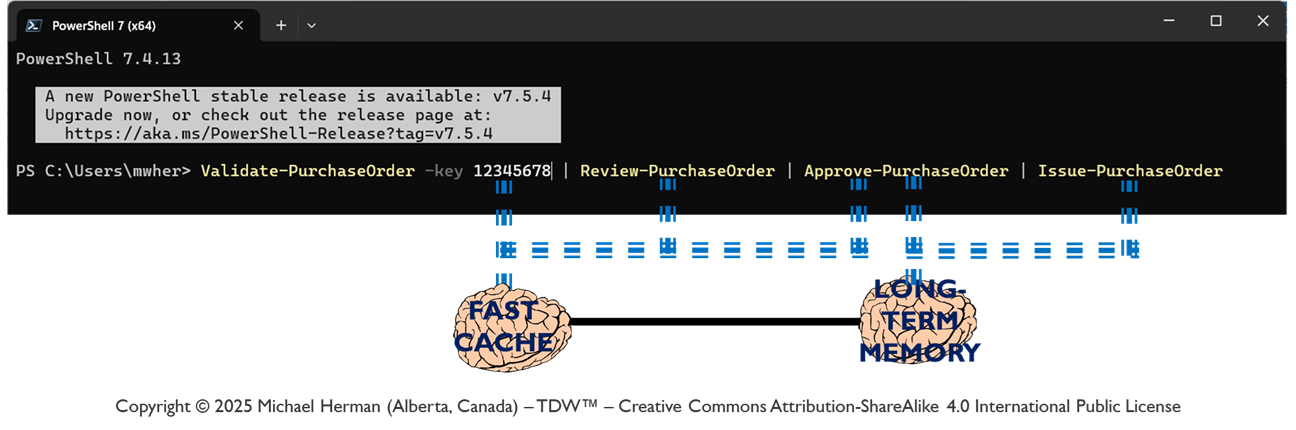
An agent remains dormant until it receives a message directed to it and returns to a dormant state when no more messages are remaining to be processed. An agent’s message processing can be paused without losing any incoming messages. When an agent is paused, messages are received, queued, and persisted in long-term memory. Message processing can be resumed at any time.
Additionally, an Agent can include a dynamically changing set of Coordination and Execution LOBEs. These LOBEs enable an Agent to capture events (incoming messages), compose responses (outgoing messages), and share these messages with one or more Agents (within a specific Neural Cluster or externally with the Beneficial Agent in other Neural Clusters (see Figure 5)).
What is a LOBE?
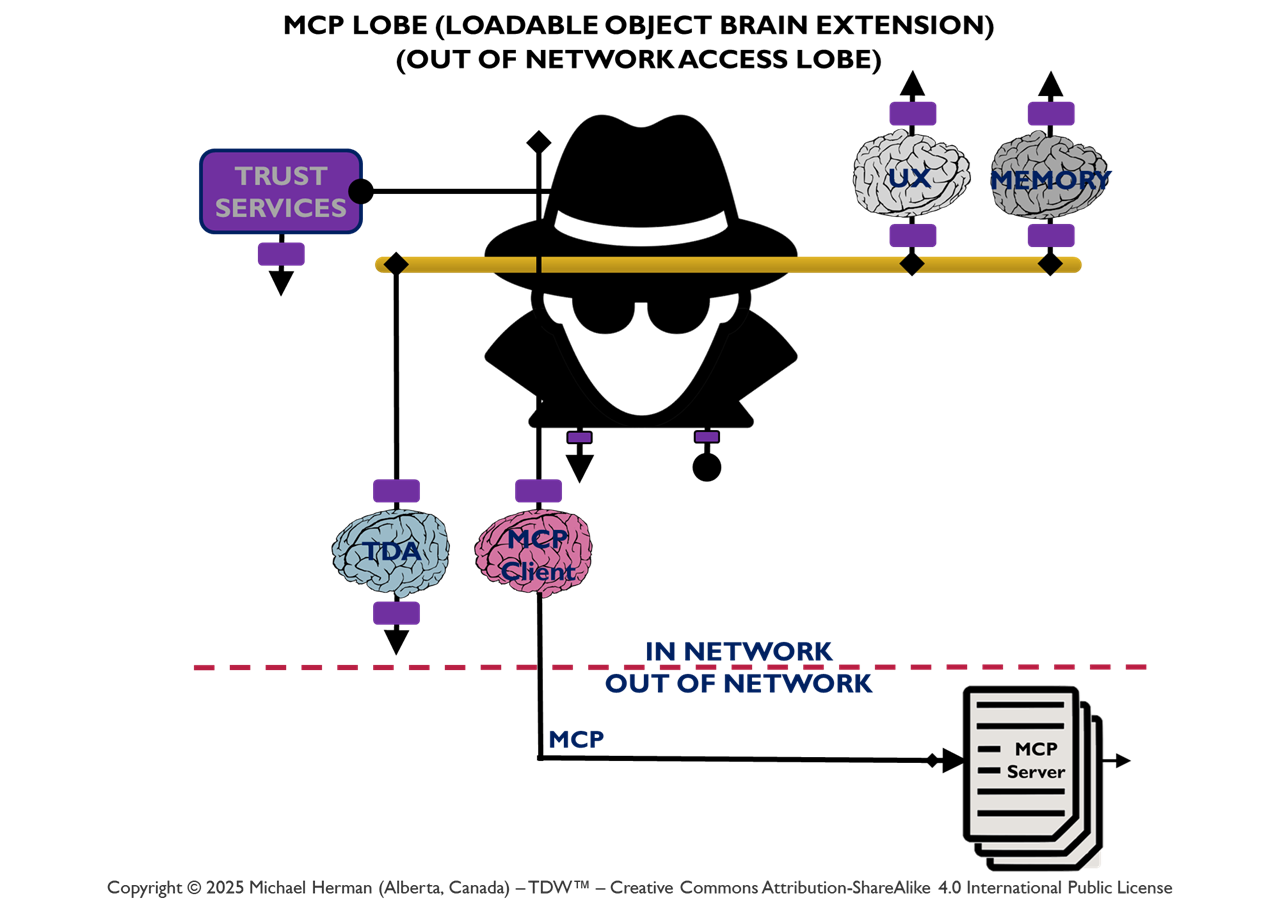
LOBE (Loadable Object Brain Extensions) is a macromodular, neuromorphic intelligence framework designed to let systems grow, adapt, and evolve by making it easy to add new capabilities at any time. Each LOBE is a dynamically Loadable Object — a self-contained cognitive module that extends the Frontal LOBE’s functionality, whether for perception, reasoning, coordination, or control (execution). Together, these LOBEs form a dynamic ecosystem of interoperable intelligence, enabling developers to construct distributed, updatable, and extensible minds that can continuously expand their understanding and abilities.
LOBEs lets intelligence and capability grow modularly. Add new lobes, extend cognition, and evolve systems that learn, adapt, and expand over time. Expand your brain. A brain that grows with every download.
What is a NeuroPlex?
A Web 7.0 Neuroplex (aka a Neuro) is a dynamically composed, decentralized, message-driven cognitive solution that spans one or more agents, each with its own dynamically configurable set of LOBEs (Loadable Object Brain Extensions). Each LOBE is specialized for a particular type of message. Agents automatically support extraordinarily efficient by-reference, in-memory, intra-agent message transfers. A Web 7.0 Neuroplex is not a traditional application or a client–server system, but an emergent, collaborative execution construct assembled from independent, socially-developed cognitive components (LOBEs) connected together by messages. Execution of a Neuroplex is initiated with a NeuroToken.
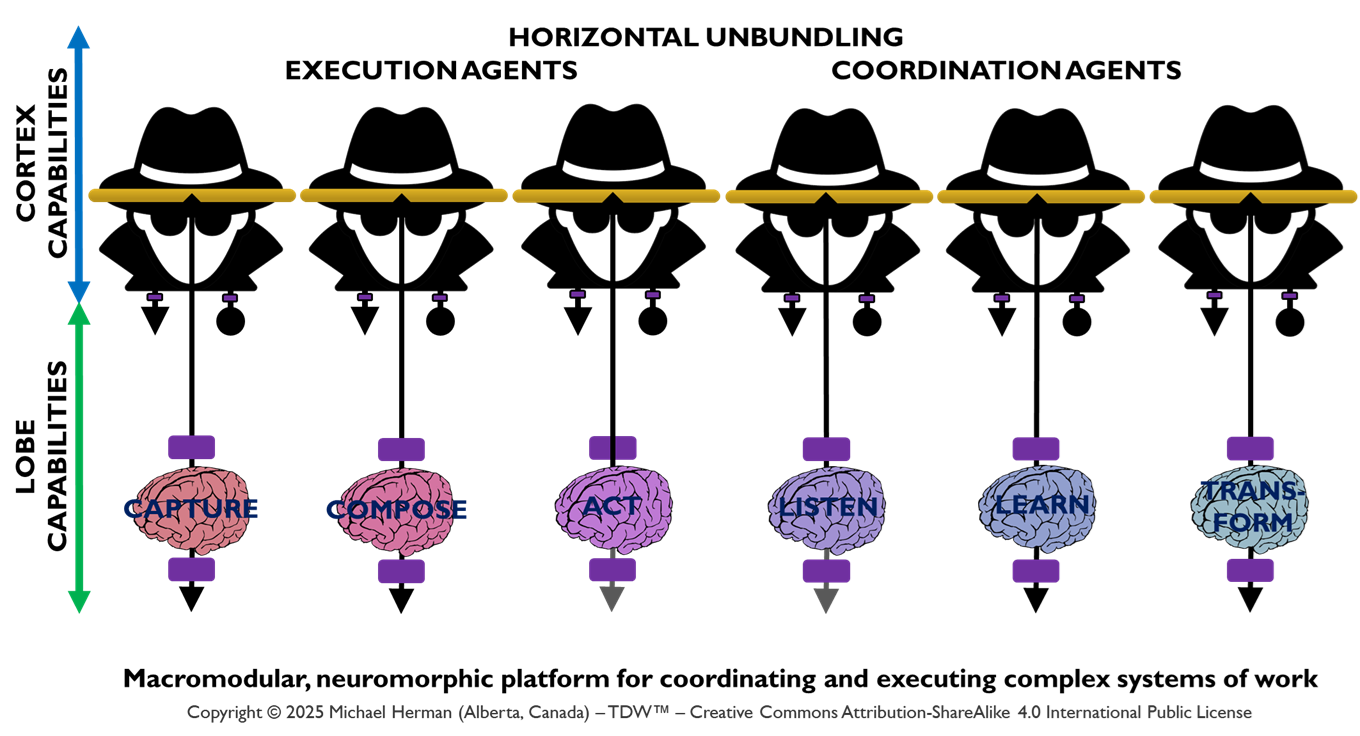
Horizontal Unbundling: Coordination and Execution Agents
Figure 2 illustrates how the deployment of Coordination and Execution LOBEs can be horizontally unbundled – with each LOBE being assigned to a distinct Frontal LOBE. This is an extreme example designed to underscore the range of deployment options that are possible. Figure 3 is a more common pattern.
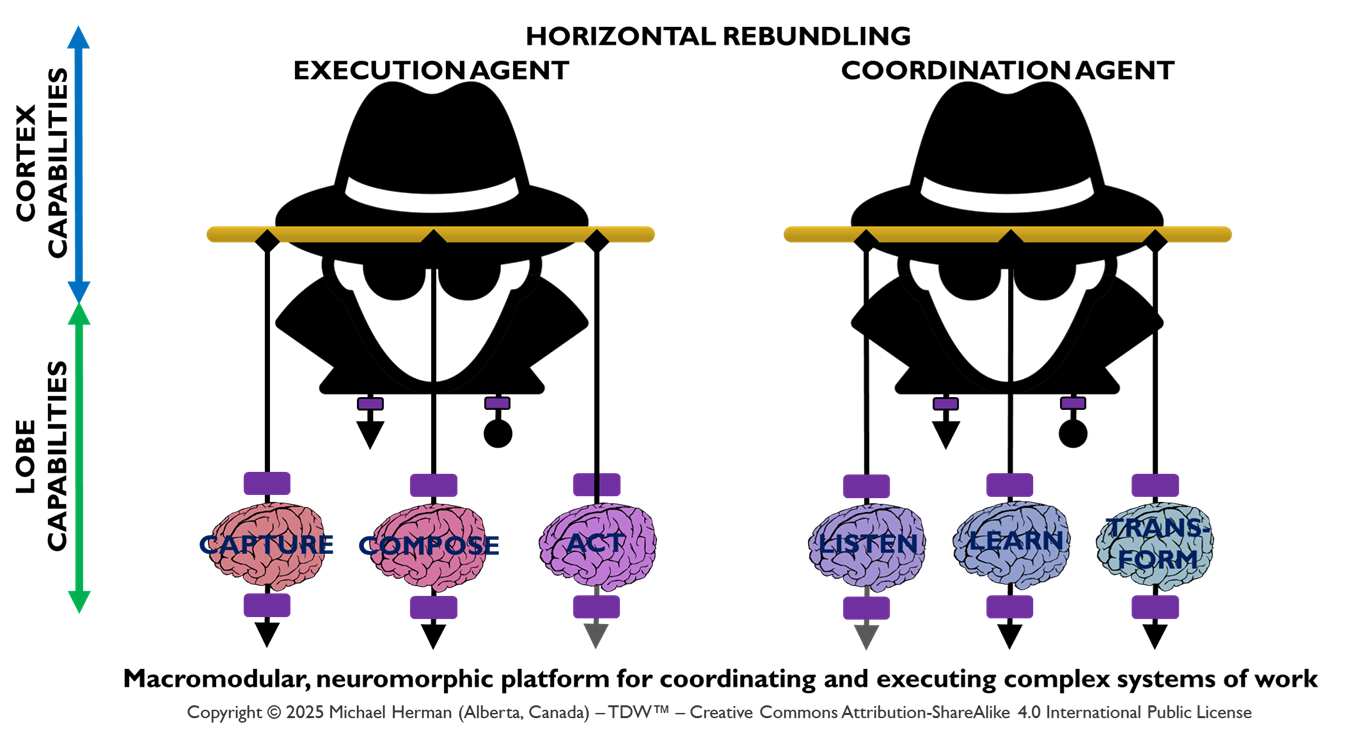
Figure 3 depicts a more common/conventional deployment pattern where, within a Neural Cluster, a small, reasonable number of Frontal LOBEs host any collection of Coordination and/or Execution LOBEs.
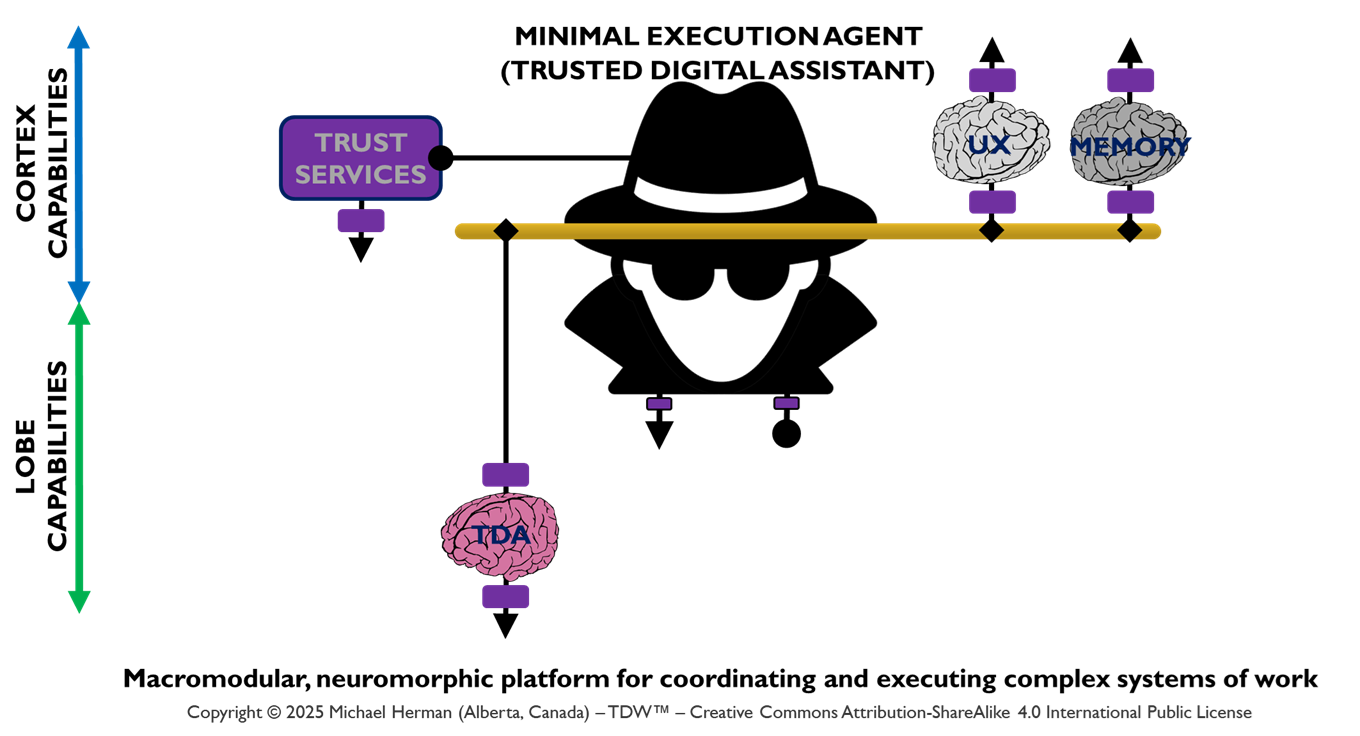
Minimal Execution Agent (Trusted Digital Assistant)
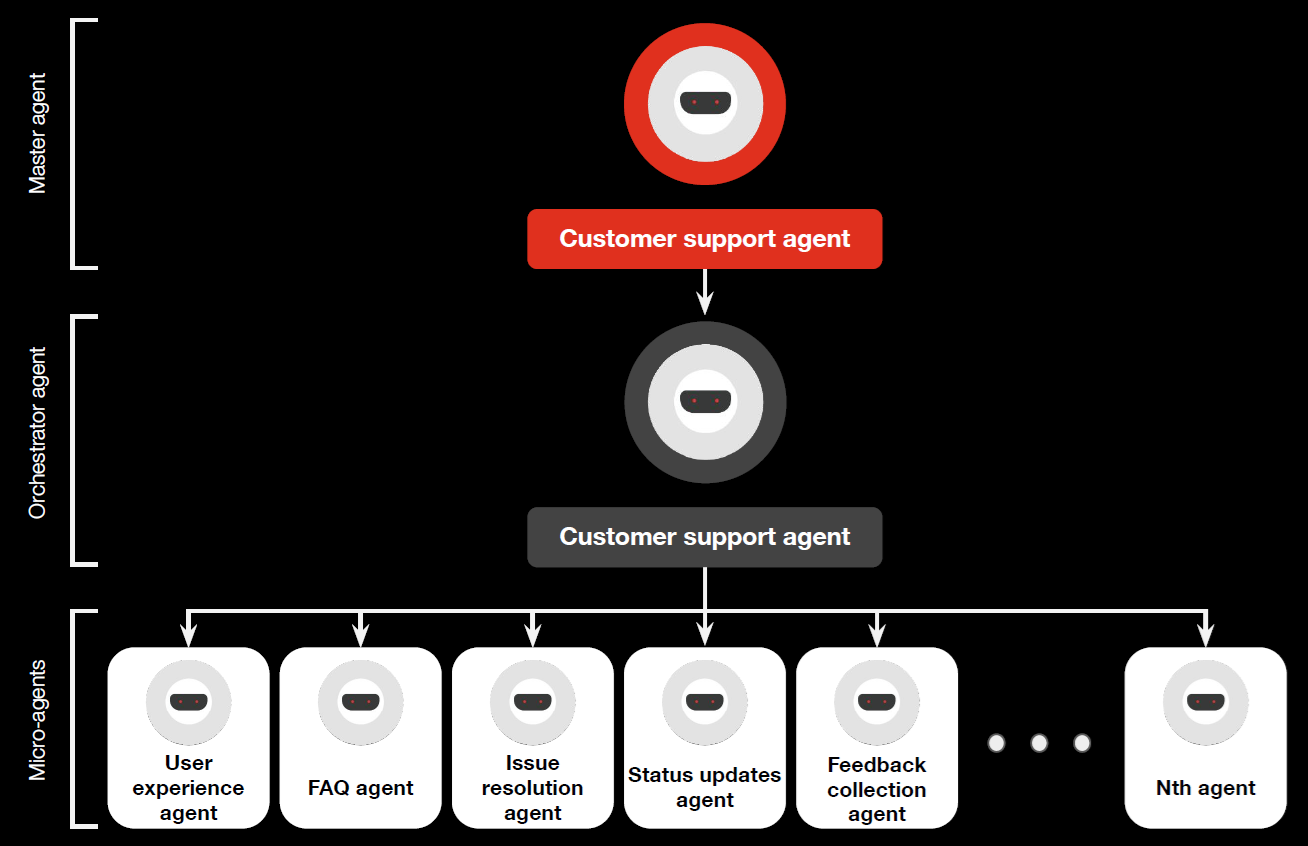
Figure 5 depicts the deployment of a Web 7.0 Neural Cluster. Messages external to the Neural Cluster are only sent/received from the Beneficial Agent. Any additional messaging is limited to the Beneficial, Coordination, and Execution LOBEs deployed within the boundary of a Neural Cluster. A use case that illustrates the Neural Cluster model can be found in Appendix D – PWC Multi-Agent Customer Support Use Case.
Figure 6a is an all-in illustration of the conceptual architecture of a Web 7.0 Neuromorphic Agent. DIDComm Messages can be piped from the Outbound Interface of the Sender agent to the Inbound Agent of of Receiver agent – supporting the composition of secure, trusted agent-to-agent pipelines similar (but superior) to: i) UNIX command pipes (based on text streams), and ii) PowerShell pipelines (based on a .NET object pump implemented by calling ProcessObject() in the subsequent cmdlet in the pipeline).
NOTE: PowerShell does not clone, serialize, or duplicate .NET objects when moving them through the pipeline (except in a few special cases). Instead, the same instance reference flows from one pipeline stage (cmdlet) to the next …neither does DIDComm 7.0 for DIDComm Messages.
Bringing this all together, a DIDComm Message (DIDMessage) can be passed, by reference, from LOBE (Agenlet) to LOBE (Agenlet), in-memory, without serialization/deserialization or physical transport over HTTP (or any other protocol).
PowerShell
DIDComm 7.0
powershell.exe
tdwagent.exe
Cmdlet
LOBE (Loadable Object Brain Extension)
.NET Object
Verifiable Credential (VC)
PSObject (passed by reference)
DIDMessage (JWT) (passed by reference)
PowerShell Pipeline
Web 7.0 Verifiable Trust Circle (VTC)
Serial Routing (primarily)
Arbitrary Graph Routing (based on Receiver DID, Sender DID, and DID Message type)
Feedback from a reviewer: Passing DIDComm messages by reference like you’re describing is quite clever. A great optimization.
Coming to a TDW LOBE near you…
DIDComm 7.0 Superstack
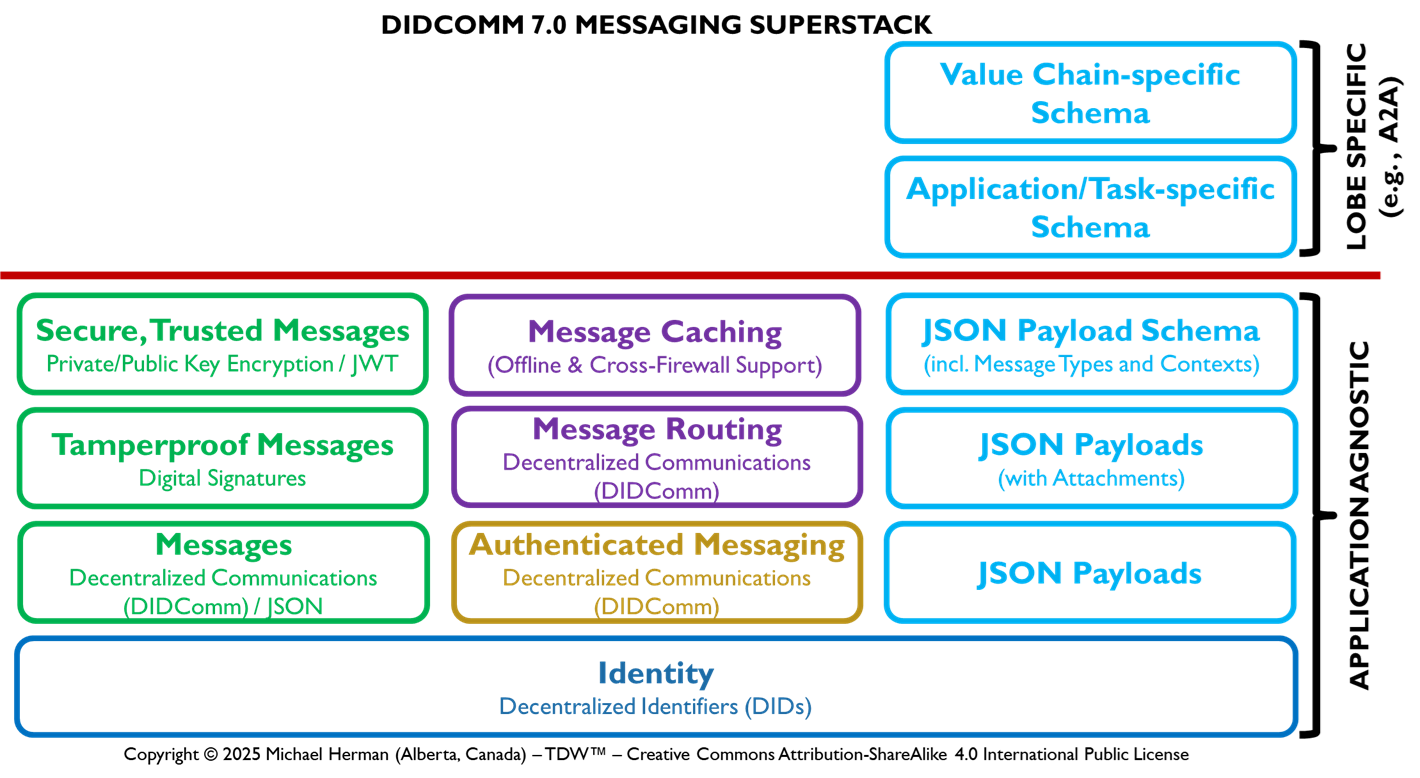
Figure 6b. DIDComm 7.0 Messaging Superstack
Figure 6b illustrates the interdependencies of the multiple layers within the DIDComm 7.0 Superstack.
Technology Wheel of Reincarnation: Win32 generic.c
Figure 7. Web 7.0 Neuromorphic Agent Identity Model (NAIM)
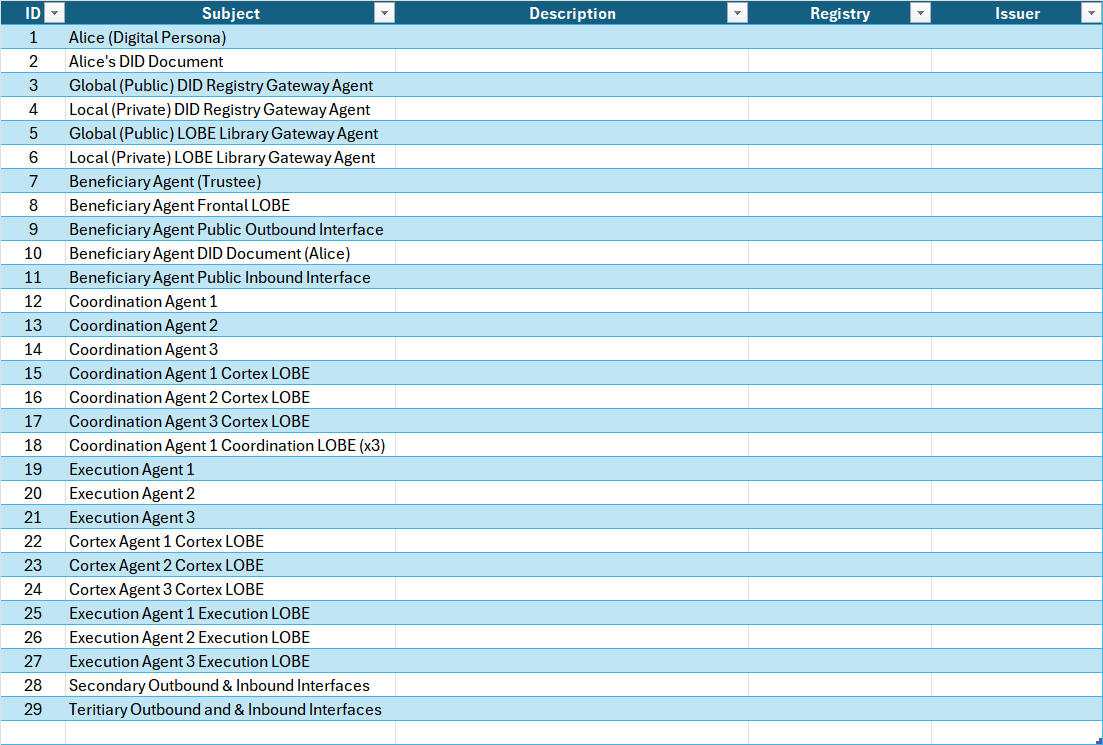
The NAIM seeks to enumerate and identify all of the elements in the AARM that have or will need an identity (DID and DID Document). This is illustrated in Figure 7.
Table 1. Web 7.0 Neuromorphic Agent Identity Model (NAIM) Chart
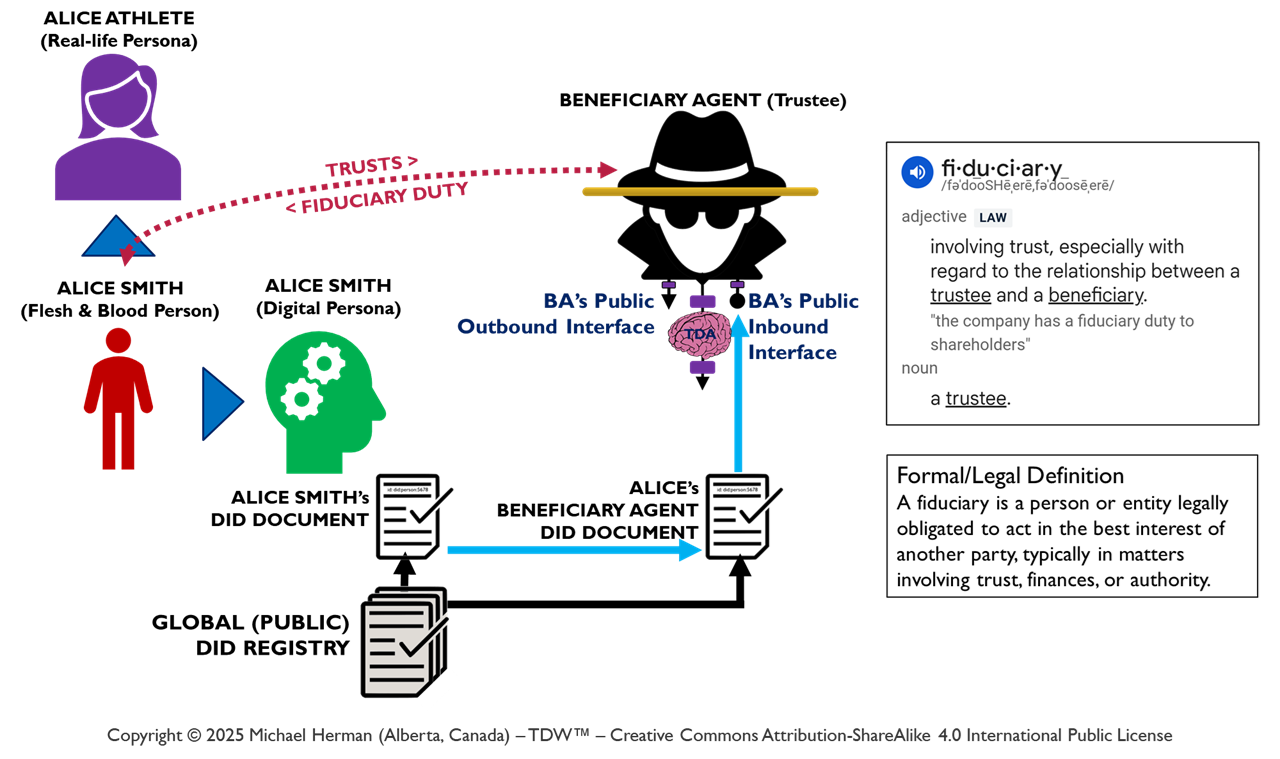
Beneficiaries, Trustees, and Fiduciary Duty
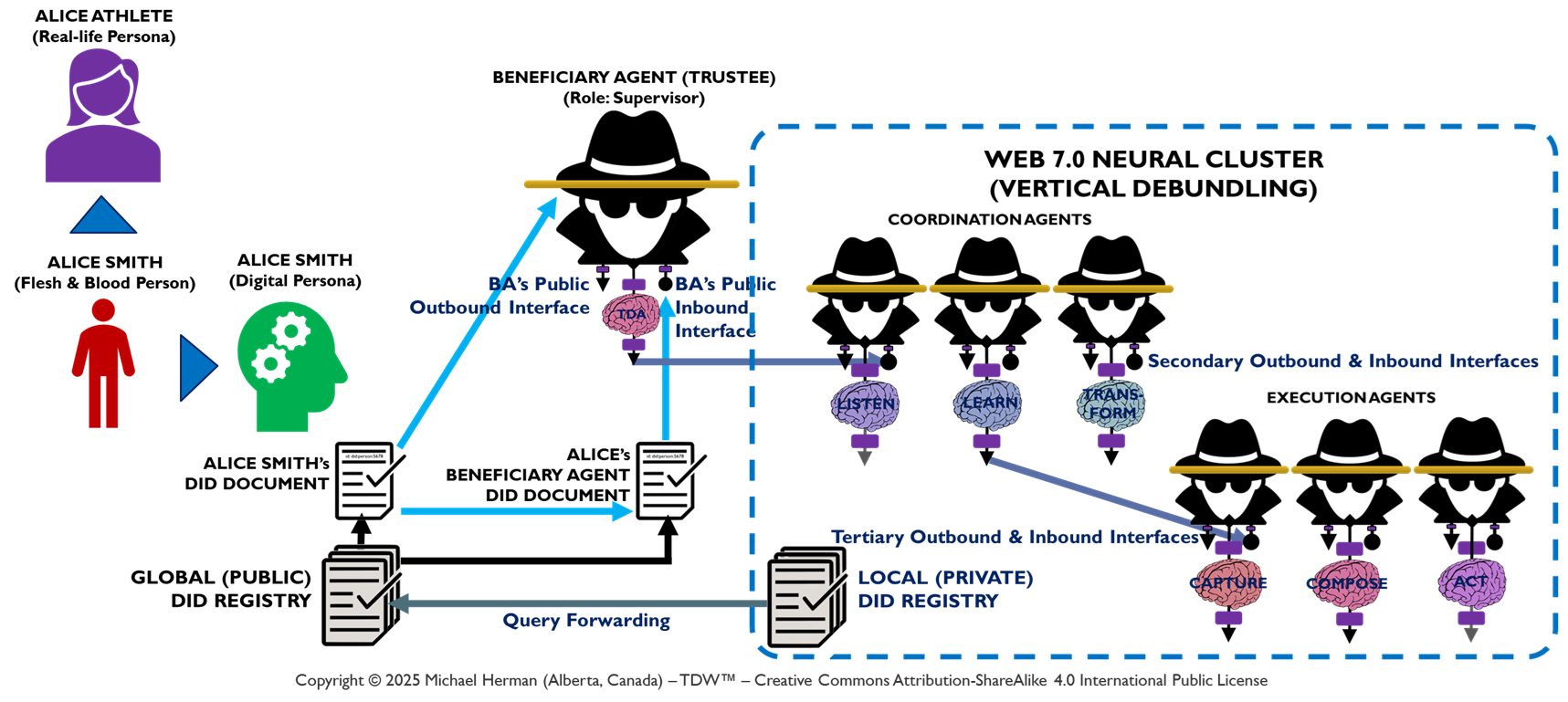
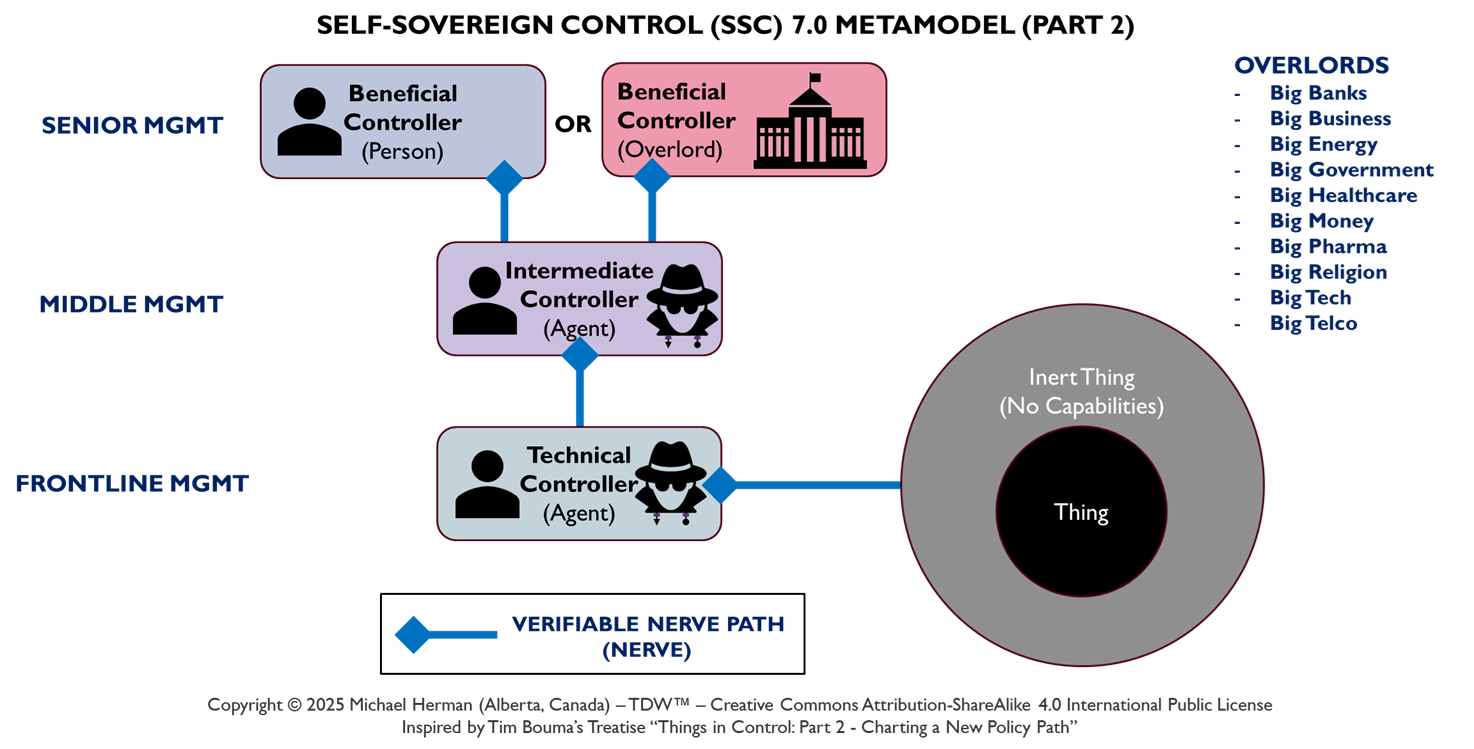
Figure 8. Beneficiaries, Trustees, and Fiduciary Duty
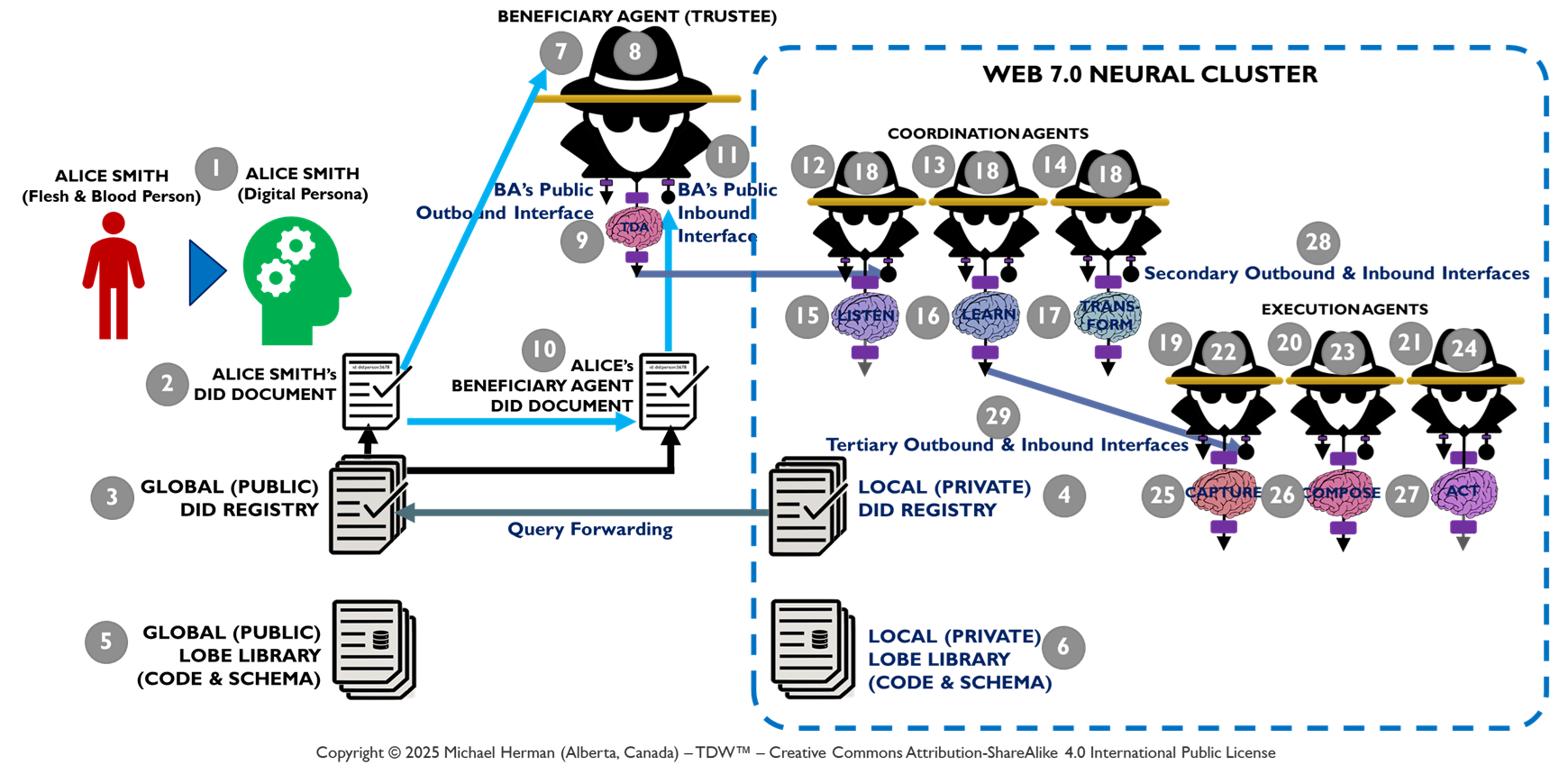
Figure 8 highlights in red the trusts and fiduciary duty relationships between (a) a Beneficiary (Alice, the person) and (b) her Beneificiary Agent (a trustee). Similarly, any pair of agents can also have pair-wise trusts and fiduciary duty relationships where one agent serves in the role of Beneficiary and the second agent, the role of Trustee.
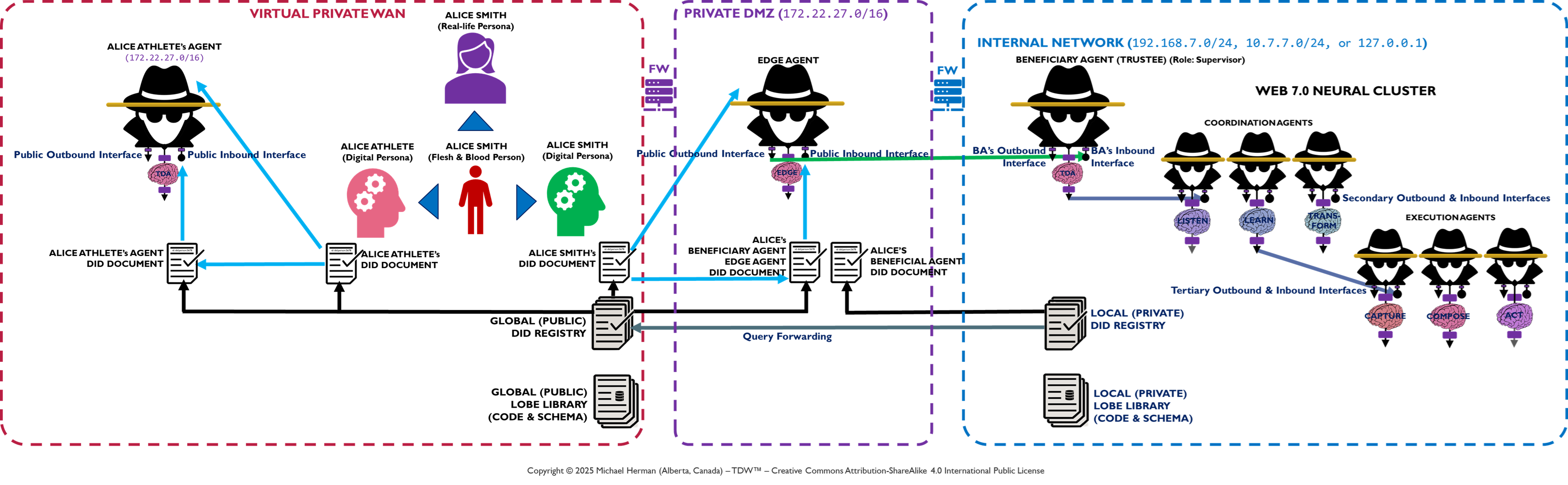
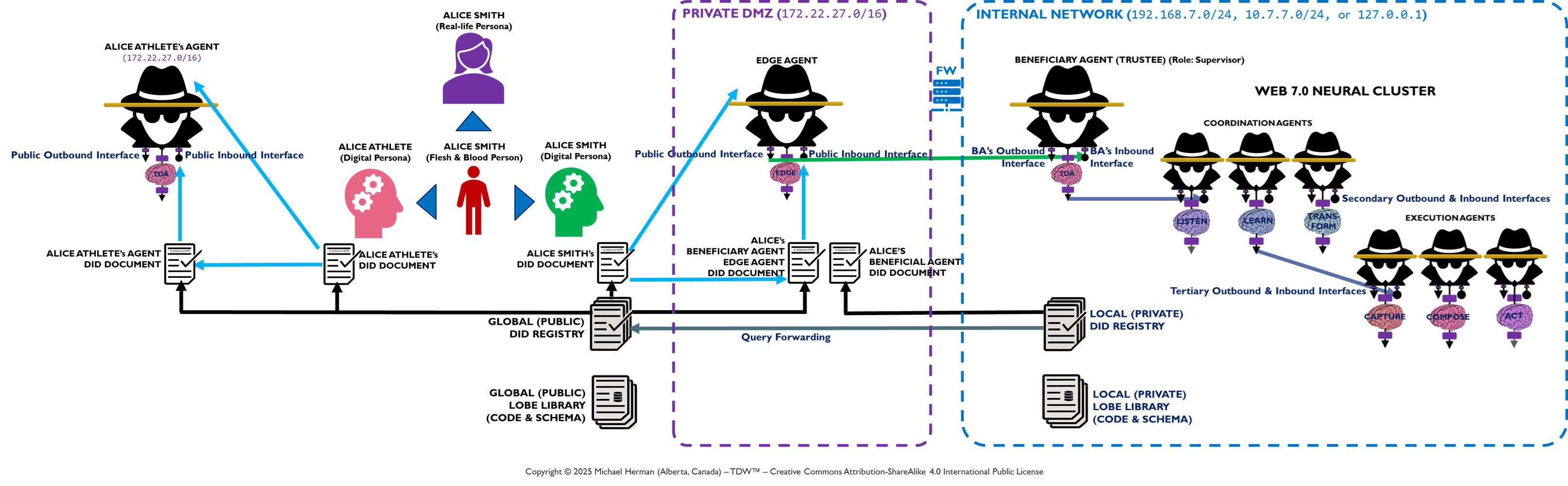
Appendix A – TDW AgenticOS: Edge Agent DMZ Deployment
Appendix B – TDW AgenticOS: Multiple Digital Persona Deployment
This section is non-normative.
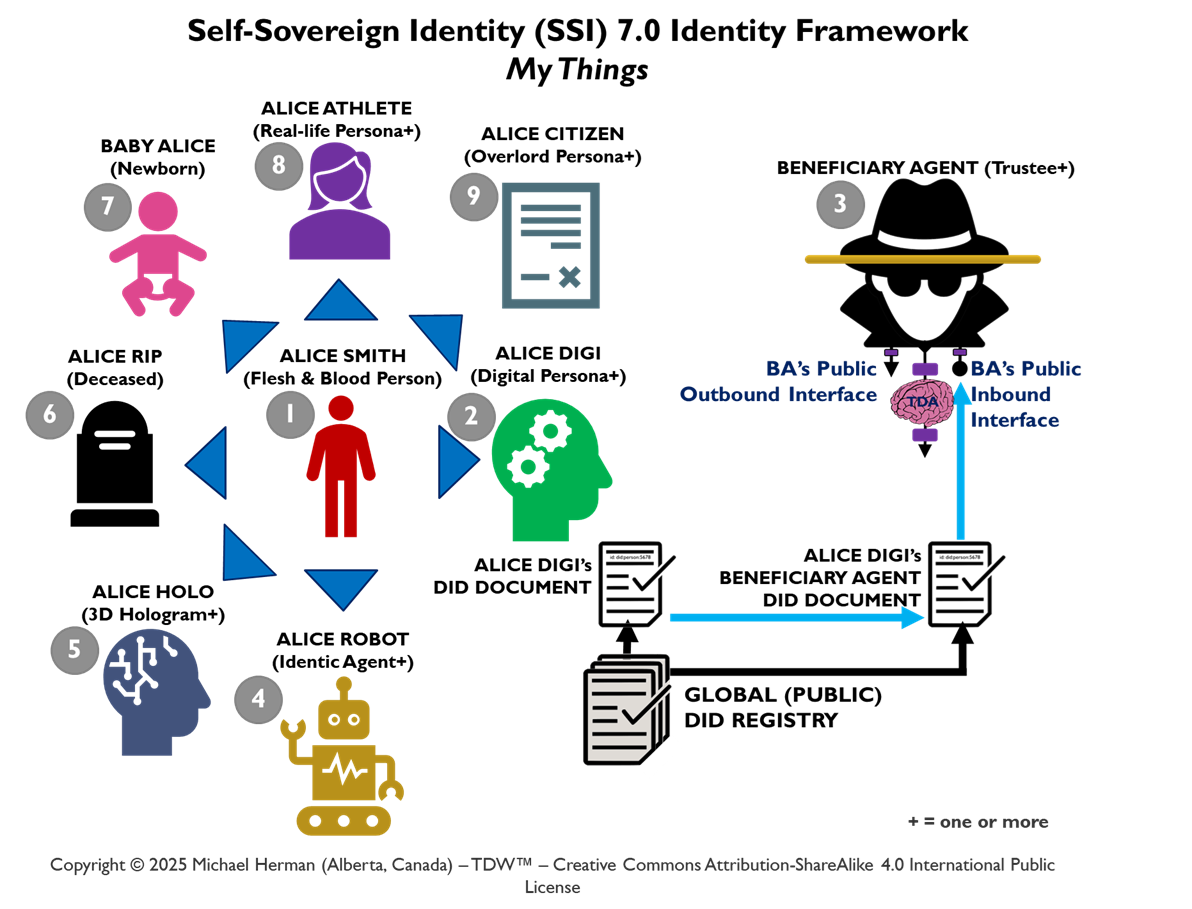
Figure B-1. TDW AgenticOS: Multiple Digital Persona Deployment
Alice has 2 digital personifications: Alice Smith and Alice Athlete. Each of these personifications has its own digital ID. Each of Alice’s personas also has its own Trusted Digital Assistant (TDA) – an agent or agentic neural network.
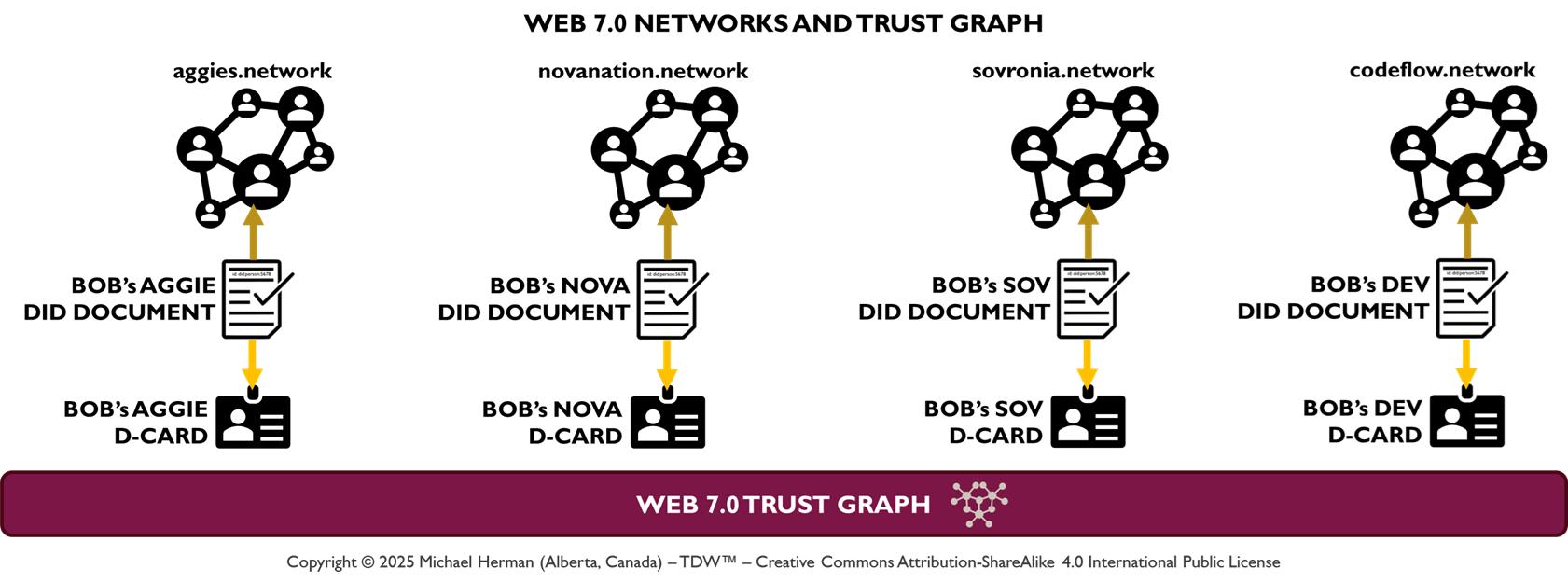
Figure B-2. Web 7.0 Networks and Trust Graph
Bob has (at least) 4 digital personifications: Bob Aggie, Bob Nova, Bob Sovronia, and Bob Developer. Using Web 7.0 Trust Graph Relationships and Verifiable Trust Credentials (VTCs), Bob can also have personas that are members of multiple Web 7.0 networks.
Appendix C – Different Brain Functionalities and Their State of Research in AI (2025)
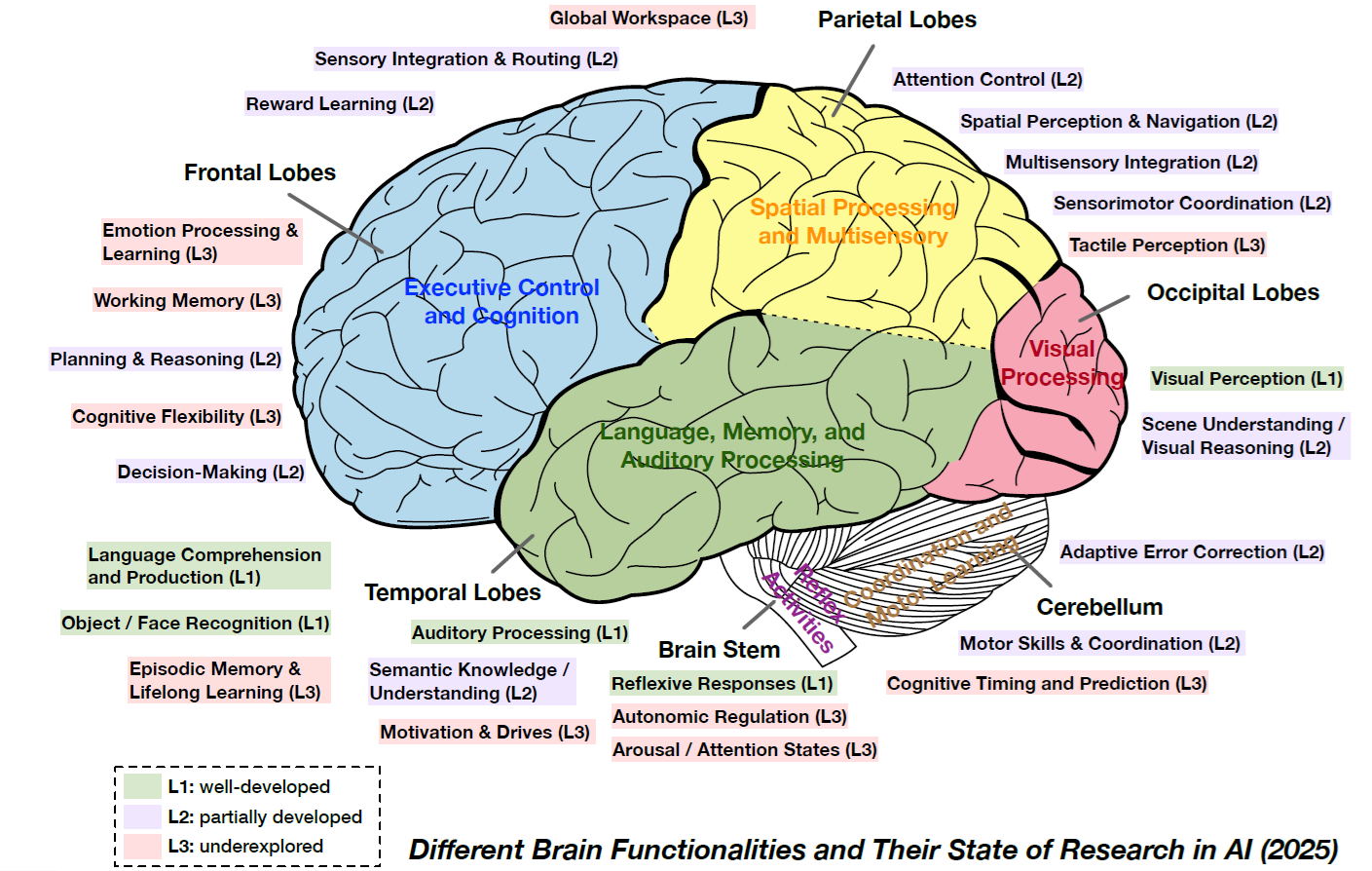
Figure C-1. Different Brain Functionalities and Their State of Research in AI (2025)
Source: Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems. arXiv:2504.01990v2 [https://arxiv.org/abs/2504.01990v2]. August 2025.
In Figure C-3, the Trust Library forms the Inner core and the UX LOBEs, the Crust. The Outer core is comprised of the Fast Cache and Long-Term Memory LOBEs, Neural and Basal Pathways, DID Registry, and LOBE Library. The Mantle is where the Coordination and Execution LOBEs execute.
Appendix D – PWC Multi-Agent Customer Support Use Case
Figure D-1. PWC Multi-Agent Customer Support Use Case
Source: Agentic AI – the new frontier in GenAI. PWC Middle East. 2024.
This use case exemplifies the use of the Web 7.0 Neural Cluster model. Table D-1 maps the PWC Use Case terminology to the corresponding Web 7.0 AARM terminology.
Web 7.0 NAARM
PWC Use Case
Beneficiary Agent
Master agent
Coordination Agent (and LOBEs)
Orchestrator agent
Execution Agent LOBEs
Micro-agents
Table D-1. Web 7.0 AARM – PWC Use Case Terminology Cross-Reference
Android modularization: Google could further modularize Android (e.g. via Project Mainline, Play Services) to allow more granular control over APIs and updates—making it easier to support or restrict super app behaviors.
Policy recalibration: In response to regulatory pressure (e.g. DMA in Europe), Google may loosen Play Store restrictions, support alternative billing, and allow more sideloading to stay competitive.
Developer Layer: Ecosystem Incentives
Play Console evolution: Google could offer new SDKs and monetization APIs tailored for mini-apps or embedded services, encouraging developers to build within Google’s ecosystem rather than third-party super apps.
Firebase + App Actions: Deep integration with Google Assistant, Search, and Android widgets could give developers super app-like reach without needing a host app.
Distribution Layer: Search as a Super App
Google Search + Discover + Assistant already function as a meta-layer for app discovery and engagement. Google may double down on this by:
Surfacing app content directly in search results
Promoting App Clips / Instant Apps
Offering deep links into services without full app installs
Monetization Layer: Bundled Value
Google One + Pixel Pass: Bundling cloud, security, and device services into a subscription model mimics super app economics.
Play Points + Wallet: Loyalty programs and integrated payments could be expanded to create a unified commerce layer across apps.
User Layer: Identity & Privacy
Google Identity Services: Strengthening federated login, cross-app personalization, and privacy dashboards positions Google as a trusted identity broker.
Privacy Sandbox: Google’s push for privacy-preserving ad tech (e.g. Topics API) could be framed as a safer alternative to super app data centralization.
Strategic Narrative
Google doesn’t need to build a super app—it already operates one in disguise. Android + Search + Assistant + Wallet + Play Store form a distributed super app ecosystem. The challenge is coherence: can Google unify these services into a seamless user experience without triggering antitrust alarms?
This is the outcome of an October 19, 2025 conversation between Michael Herman and Copilot.
🧩 Developer Incentives: Fragmentation vs Aggregation
Super apps flip the traditional developer model:
Old Model
Super App Model
Build standalone apps
Build mini-programs or plug-ins within super apps
Compete for store visibility
Compete for in-app placement and promotion
Monetize via ads or subscriptions
Monetize via bundled services, commissions, or shared revenue pools
Own user data
Share or rent access to super app user base
🔁 Strategic Shifts
Incentive realignment: Developers trade independence for reach. The super app offers instant distribution, but at the cost of brand autonomy and data ownership.
Modular architecture: Developers must adopt SDKs, APIs, and design systems tailored to the host super app.
Revenue reshuffling: Instead of direct monetization, developers may earn through usage-based payouts, affiliate models, or loyalty programs.
🏛️ Platform Governance: Centralization vs Regulation
Super apps challenge traditional platform governance:
App Store Governance
Super App Governance
Apple/Google set rules
Super app owner sets rules (e.g. WeChat, Grab)
OS-level privacy and security
App-level identity, payments, and data control
Regulatory oversight (DMA, GDPR)
Emerging scrutiny over super app monopolies
⚖️ Governance Tensions
Regulatory gray zones: Super apps blur lines between platform and app, raising questions about antitrust, data sovereignty, and consumer protection.
Policy fragmentation: Developers must navigate not only OS-level rules but also super app-specific governance—creating multi-layered compliance burdens.
User lock-in: Super apps centralize identity, payments, and services, making it harder for users to switch ecosystems—potentially triggering regulatory intervention.
🔮 Strategic Forecast
Developers will increasingly specialize in microservices, loyalty mechanics, and embedded commerce.
Platforms may respond with their own super app strategies (e.g. Apple Pay + Messages + Maps integration) or loosen restrictions to retain developer loyalty.
Regulators will likely push for interoperability, data portability, and transparency in super app ecosystems.
This layered breakdown is a sharp way to visualize how control dynamics and strategic shifts ripple through the mobile ecosystem.
This is the outcome of an October 10, 2025 conversation between Michael Herman, ChatCGT, and Copilot.
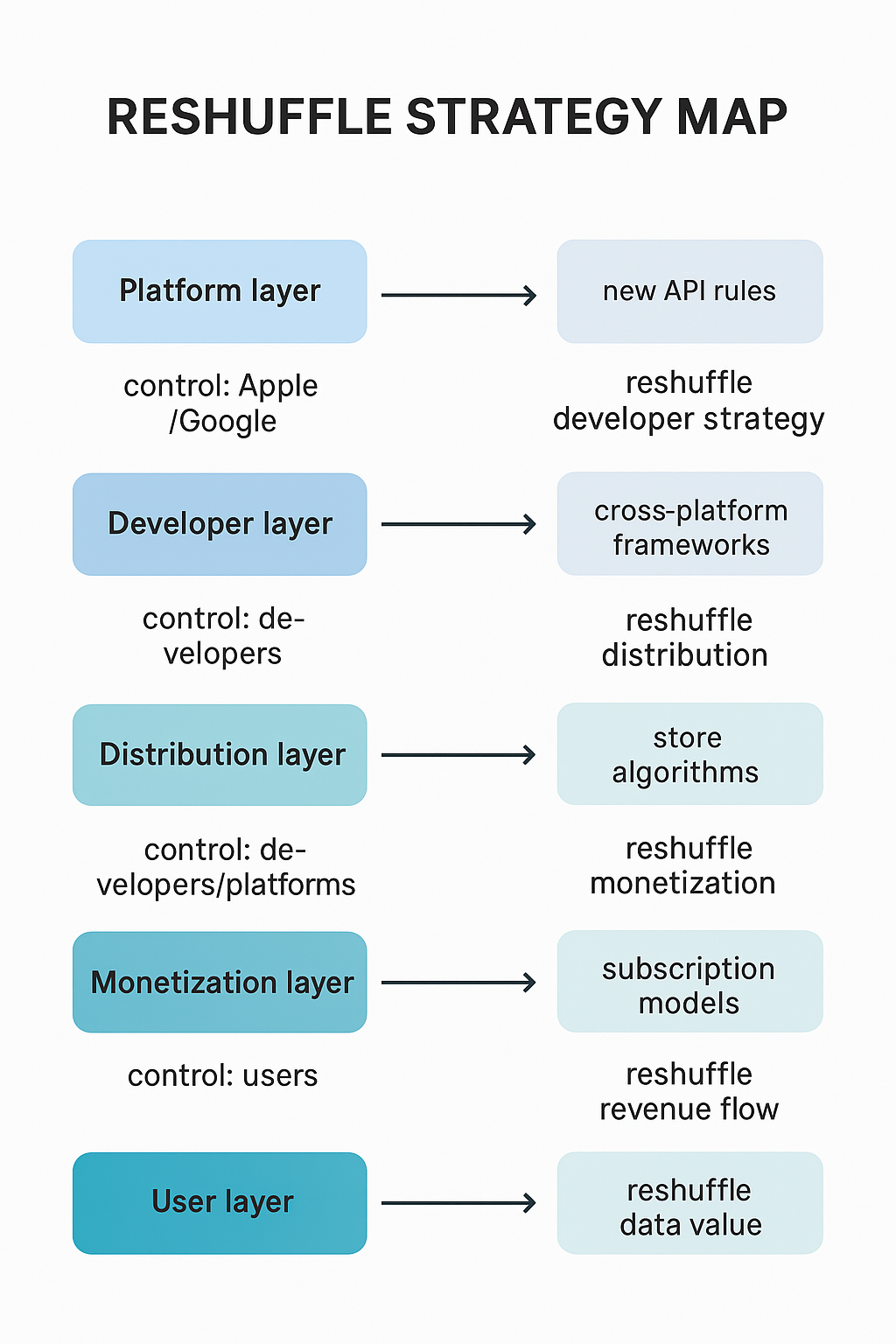
📱 Mobile Ecosystem Power Stack
Layer
Primary Control
Catalyst for Reshuffle
Strategic Impact
Platform Layer
Apple / Google
New API rules, OS policies
Developers must realign strategies to comply or compete
Developer Layer
App creators
Rise of cross-platform frameworks
Distribution becomes more fragmented and flexible
Distribution Layer
Platforms (App Stores)
Algorithmic curation, ranking
Monetization models shift based on visibility and reach
Monetization Layer
Developers / Platforms
Subscription-first models
Revenue flows restructured, favoring retention over acquisition
User Layer
End users
Enhanced privacy controls
Data value redefined, impacting targeting and personalization
🔄 Strategic Cascades
Top-down pressure: Platform rule changes (e.g. ATT, DMA compliance) force developers to rethink how they build, distribute, and monetize apps.
Bottom-up resistance: Users assert control via privacy settings, reshaping the value of behavioral data and forcing platforms to adapt monetization logic.
Middle-layer fluidity: Distribution and monetization are increasingly interlinked—algorithmic visibility directly affects revenue, while subscriptions demand deeper engagement.
A Reshuffle value chain is basically a rethinking of a traditional value chain where value is reorganized around control points — places in the chain where power, influence, or leverage exists. In the mobile app ecosystem, Reshuffle means understanding how the ecosystem is changing and identifying where control is concentrated so that new entrants, incumbents, or platforms can leverage or defend those points.
Based on an October 19, 2025 conversation between Michael Herman and ChatGPT.
Users consuming apps, engaging with services, making purchases.
2. Reshuffle Value Chain in Mobile Apps
Reshuffle shifts the view of the value chain to highlight new control points — places where power is concentrated that weren’t as visible before, and where value creation & capture is happening.
Here’s what a reshuffled mobile app value chain might look like:
Hardware → Operating System → App Store Distribution → Developer Enablement → Service Platforms → User Engagement → Monetization
But reshuffled control points reorder priorities. For example:
In a reshuffle, control points move from being purely physical or technical to being gatekeeping points where access, distribution, or monetization is mediated.
For the mobile app ecosystem, the main control points are:
Operating System / API Access — iOS and Android control core APIs.
App Stores — discovery, ranking, and distribution rules.
Developer Tools & SDKs — frameworks that create lock-in.
Payment Infrastructure — control of monetization flows.
User Data & Engagement Platforms — control of analytics and personalization.
Based on an October 10, 2025 conversation between Michael Herman and ChatGPT.
I feel the following doesn’t match 100% with what is presented in the book #Reshuffle but there are a few interesting parallels.
🧩 1. Background: What the “Reshuffle” Model Means
In the book Reshuffle, the core concept is that platforms continually reconfigure (“reshuffle”) the value chain — deciding:
Where to play (which layers of the ecosystem to own, open, or delegate)
How to win (by controlling key interfaces, user access, or data flows)
A reshuffle happens when a player changes the architecture of participation — shifting value, control, and power between ecosystem actors.
📱 2. Applying This to the Decentralized Mobile App Ecosystem
Let’s consider the mobile ecosystem as layers (simplified):
Layer
Examples
Current Gatekeepers
Hardware
Apple, Samsung, Qualcomm, Google
Apple, Google
OS / Runtime
iOS, Android, Windows
Apple, Google
Distribution
App Store, Play Store, Web 7.0™ Store
Apple, Google
Payment / Identity
Apple Pay, Google Pay, Sign in with Apple
Apple, Google
Apps / Services
TikTok, Uber, Spotify
Independent developers
User Relationships / Data
Analytics, Ads, Web 7.0™ Trust Graph
Meta, Google, Apple increasingly
🔀 3. What a “Reshuffle” Looks Like Here
A reshuffle model describes how control, innovation, or value capture moves between these layers. Here are several current and emerging reshuffles:
A. Reshuffle Downward (Re-integration)
Platform owners pull value back down toward themselves:
Apple limits tracking (ATT) → cripples ad networks → reclaims privacy and ad advantage.
Google moves privacy features into Android → weakens cross-app data collection.
Super apps (WeChat, Grab) integrate multiple mini-apps inside one shell → pull distribution away from OS-level stores.
🧭 Effect: Platforms reclaim data, monetization, and developer dependence.
B. Reshuffle Upward (Decentralization / Open APIs)
Some innovations push value upward to developers and users:
Progressive Web Apps (PWAs) bypass app stores.
Cross-platform frameworks (Flutter, React Native) reduce dependency on native SDKs.
Alternative app stores / sideloading (EU’s DMA) redistribute control.
🧭 Effect: Developers gain autonomy and flexibility, though discovery and monetization remain bottlenecks.
C. Reshuffle Laterally (New Platform Entrants)
New layers emerge, shifting boundaries:
AI agents / assistants become new distribution channels (e.g., OpenAI’s ChatGPT apps, Perplexity’s mobile UI).
Super app frameworks (e.g., Telegram mini-apps) become meta-platforms inside mobile OSes.
Wallet-based ecosystems (identity, crypto, digital goods) create cross-platform continuity.
🧭 Effect: Gatekeepers may lose user touchpoints to “meta-platforms” that sit on top of the OS.
⚙️ 4. A “Reshuffle Business Model Canvas” for Mobile Apps
Element
Description
Example
Trigger
What changes the distribution of value or control?
Regulatory changes (DMA), new tech (AI agents), shifts in user behavior
Anchor Layer
Which layer redefines the interface?
OS, identity, or payments
Redistributed Value
What moves?
Revenue, data, trust, discovery
New Gatekeepers
Who gains control?
AI assistants, mini-app frameworks
Old Gatekeepers
Who loses control?
App stores, SDK-based ad networks
User Benefit
What improves for users?
Choice, interoperability, integrated experience
Developer Impact
What improves or worsens?
Distribution, economics, discoverability
🧠 5. Example: The “AI Agent Reshuffle”
In 2025 and beyond, an AI-driven reshuffle looks like this:
Before
After
Users search for apps in App Store
Users ask AI assistants to “book a taxi” or “edit a photo”
Developers fight for app visibility
AI intermediates app selection and invocation
App Store controls discovery
AI layer controls orchestration and recommendation
OS owns distribution
AI owns user intent
🧭 Reshuffle Result: AI interfaces become the new “home screen.” App stores become backend registries. The distribution and discovery value shifts to the AI layer.
🏁 6. Summary
A Reshuffle model for the mobile app ecosystem describes how power and value continually move among:
OS and hardware vendors (Apple, Google)
Developers and third-party ecosystems
New intermediaries (AI agents, super apps)
Regulators (mandating openness)
The model emphasizes layer-by-layer realignment — each “reshuffle” altering where innovation, value, and control reside.
The invention of the barcode transformed retail and supply chains by providing a universal, machine-readable identifier that ensured accuracy, efficiency, and interoperability across diverse systems. Similarly, Decentralized Identifiers (DIDs) represent a foundational innovation for digital ecosystems: a universal, cryptographically verifiable identifier that enables trusted communication across domains and platforms. This paper explores the analogy between DIDs and barcodes, examining how both enable end-to-end interoperability, reduce friction, and unlock new models of value creation.
In 1974, a pack of Wrigley’s gum was scanned at a Marsh supermarket in Ohio, marking the first use of the Universal Product Code (UPC). That moment marked the beginning of a transformation in retail, logistics, and global commerce. By providing a standardized identifier, barcodes automated inventory management, accelerated checkout, reduced human error, and laid the foundation for today’s global supply chains.
Digital ecosystems in the 21st century face an equivalent problem: how to create universal, secure, and machine-readable identifiers that work across organizations, platforms, and jurisdictions. While domain names, IP addresses, and UUIDs serve as identifiers, none are self-sovereign, portable, and verifiable across trust boundaries. Decentralized Identifiers (DIDs) aim to solve this.
This paper argues that DIDs are the barcodes of digital trust: a universal, machine-readable system for identifying entities in secure communications, enabling a new end-to-end supply chain of digital trust.
2. The Barcode Revolution
2.1 Before Barcodes
Manual price tags and clerical data entry.
Inventory tracking prone to human error.
Inefficient supply chains with frequent stockouts and overstocking.
Lack of standardization across retailers and manufacturers.
2.2 With Barcodes
Universal identifiers: UPC and EAN standards.
Machine readability: fast, automated scanning reduced labor costs and errors.
End-to-end traceability: from manufacturer → distributor → retailer → checkout.
Scalability: millions of products, billions of transactions.
Impact: Barcodes enabled just-in-time inventory, global retail expansion, and precise supply chain optimization [Brown, Inventing the Barcode, 2010]. The key insight: a universal, interoperable identifier unlocks systemic efficiencies across the value chain.
3. DIDs: A Digital Barcode for Trust
3.1 What are DIDs?
Decentralized Identifiers (DIDs) are globally unique identifiers that are self-sovereign, verifiable, and resolvable without reliance on centralized registries. Defined by the W3C, DIDs point to DID Documents, which contain public keys, service endpoints, and metadata necessary for establishing secure communication.
3.2 Core Features
Universality: A DID can represent a person, organization, device, or digital asset.
Machine readability: DIDs are structured and resolvable by software.
Cryptographic trust: Integrity and authenticity are verifiable through signatures and key material.
Decentralization: No single issuing authority required; anyone can create a DID.
Extensibility: Support for multiple DID methods (blockchain, ledger, peer-to-peer).
3.3 Why It Matters
Just as barcodes freed retail from manual, siloed processes, DIDs free digital ecosystems from centralized identity silos (e.g., social logins, proprietary identity providers).
4. Mapping the Analogy: Barcodes vs. DIDs
Barcode Property
DID Equivalent
Implications
Universal product identifier
Universal decentralized identifier
Enables global recognition of digital actors
Machine-readable
Machine-resolvable DID Document
Automated verification by software agents
Standardization (UPC/EAN)
W3C DID Core standard
Cross-platform interoperability
Scannable at every point in supply chain
Resolvable across trust domains
End-to-end verifiable identity
Facilitates inventory management
Facilitates trust management
Ensures secure digital transactions
Enables retail efficiency
Enables digital trust ecosystems
Reduces cost, friction, and fraud
5. Benefits of the Barcode Analogy
End-to-End Traceability
Barcodes track goods from origin to checkout.
DIDs enable trust from authentication through data exchange to audit.
Any barcode scanner can read a UPC; any DID-compliant system can resolve a DID.
Scalability
Barcodes scaled to billions of products; DIDs can scale to billions of devices, people, and services.
Systemic Transformation
Barcodes reshaped retail; DIDs could reshape finance, healthcare, IoT, and governance.
6. Limits of the Analogy
Centralization vs. Decentralization: Barcodes are managed by centralized registries (GS1), whereas DIDs are inherently decentralized.
Trust Layer: Barcodes encode only identity (the product number), not integrity or authenticity. DIDs add cryptographic verifiability.
Complexity: Scanning a barcode is simpler than resolving a DID, which requires cryptographic operations and network lookups.
Adoption: Barcodes achieved rapid, global retail adoption; DIDs remain in early deployment phases.
7. Strategic Implications
7.1 Identity and Access
DIDs could serve as the UPC of digital identity, enabling universal, interoperable identity across organizations.
7.2 Supply Chain and IoT
DIDs can extend barcodes’ logic into digital-physical convergence, providing secure digital twins for physical assets.
7.3 Finance and Governance
DIDs provide the foundational layer of trust for verifiable credentials, smart contracts, and cross-border compliance.
7.4 The “Barcode Moment”
Just as retail only transformed once barcodes were widely adopted, the digital trust economy will require a tipping point of DID adoption to realize systemic benefits.
8. Conclusion
The barcode transformed retail by enabling universal, machine-readable product identification across the supply chain. DIDs can do the same for digital ecosystems by enabling universal, machine-readable, and verifiable identity.
If DIDs achieve broad adoption, they could serve as the universal identifiers of digital trust, enabling secure, scalable, and interoperable communication across the global digital economy — much as barcodes enabled the rise of global retail supply chains.
References
Brown, George. Inventing the Barcode. MIT Press, 2010.