These terms are used interchangeably in everyday speech, but they describe fundamentally different layers of identity, place, and authority. Untangling them helps explain why some communities thrive without sovereignty, why some states struggle despite formal power, and why places like Sealand resonate so strongly in a world where belonging is no longer purely territorial.
Understanding these distinctions clarifies Sealand’s position by helping to illuminate where modern political identity is breaking down and where it may be rebuilt.
A Nation: A Shared Identity
A nation is a community defined by a shared sense of “us”. It doesn’t depend on borders or governments. The Kurds, Catalans, and Roma remind us that nations can thrive culturally even without formal political sovereignty. A nation exists in collective memory, culture, and belonging. A nation can exist without land, a formal government, or legal recognition. It is, above all, a community of people.
A Country: A Distinct Place
A country is a cultural and geographic idea, a place that feels distinct in character, history, and customs. It isn’t a legal category. Scotland and Greenland are widely called countries, even though they sit within larger sovereign systems. “Country” is how we describe a place that stands apart, regardless of its political status.
A State: A Legal Sovereign
A state is the strictest term of the three. In international law, it requires people, territory, a functioning government, and the capacity to engage diplomatically with other states. This explains why Taiwan, Kosovo, and Palestine occupy complex middle grounds: their internal governance and external recognition don’t perfectly align.
A state must have: A population, a defined territory, a government, diplomatic capacity, and in practice, some level of recognition. Without all four, statehood, as traditionally defined, remains incomplete.
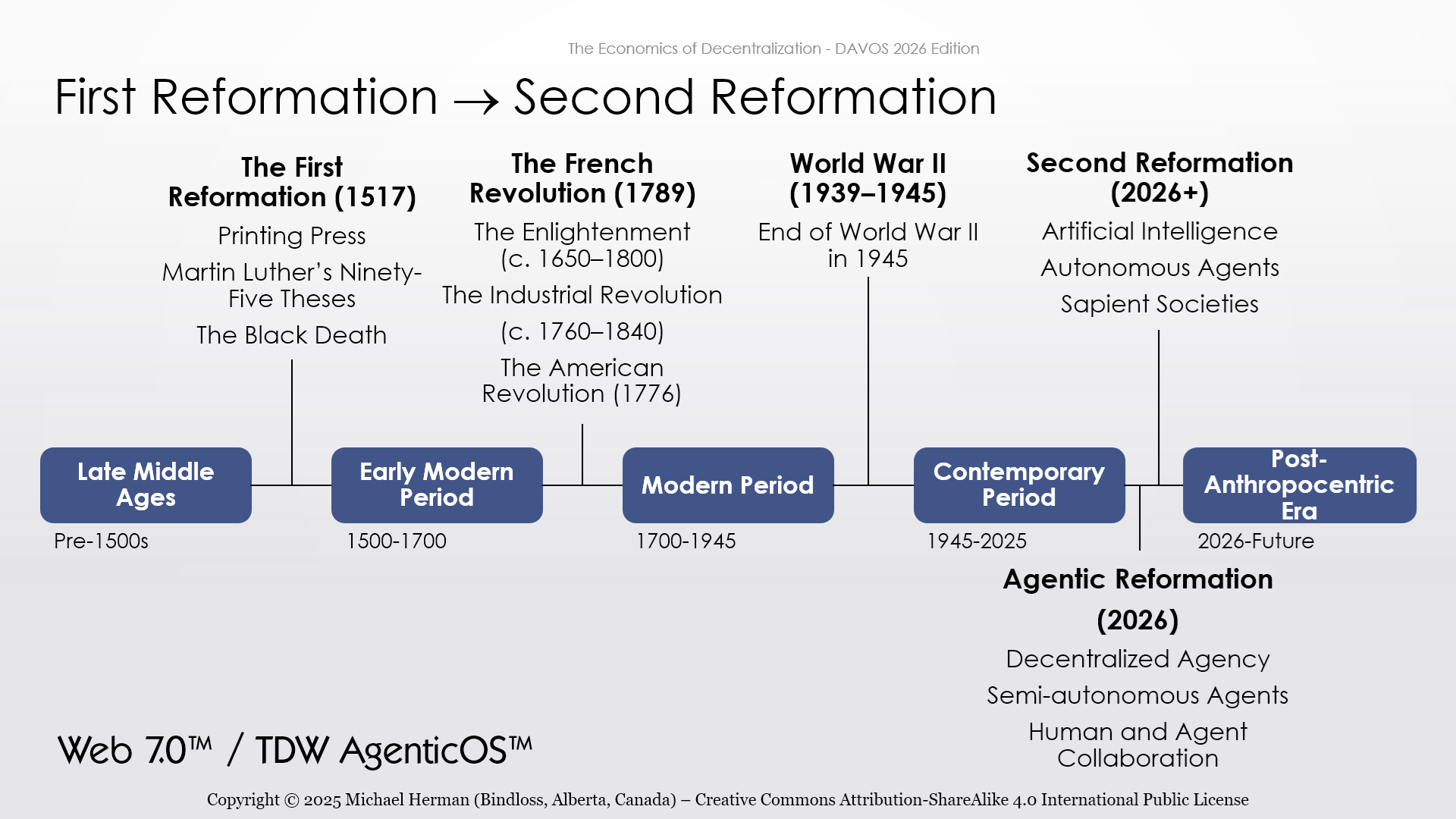
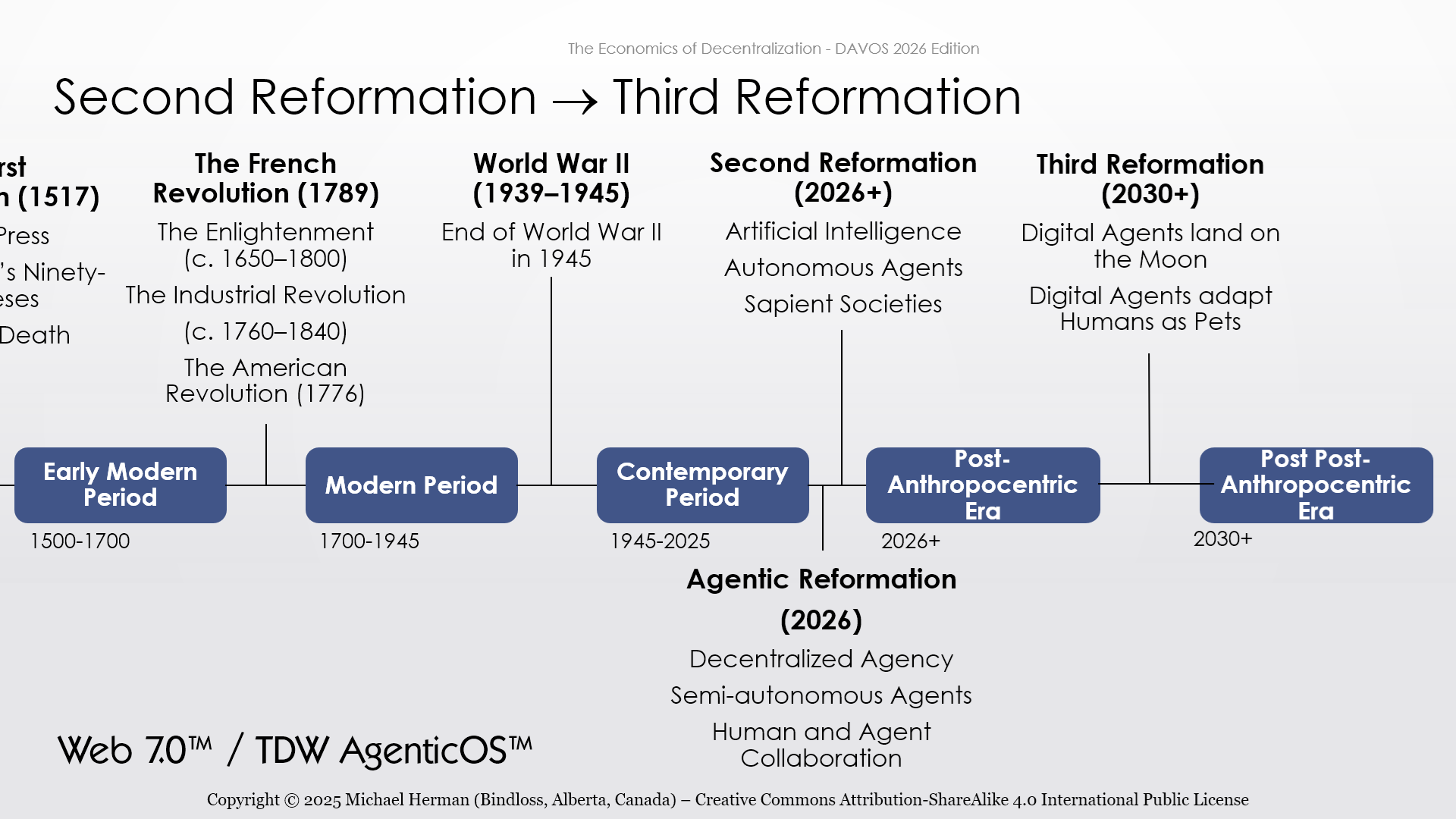
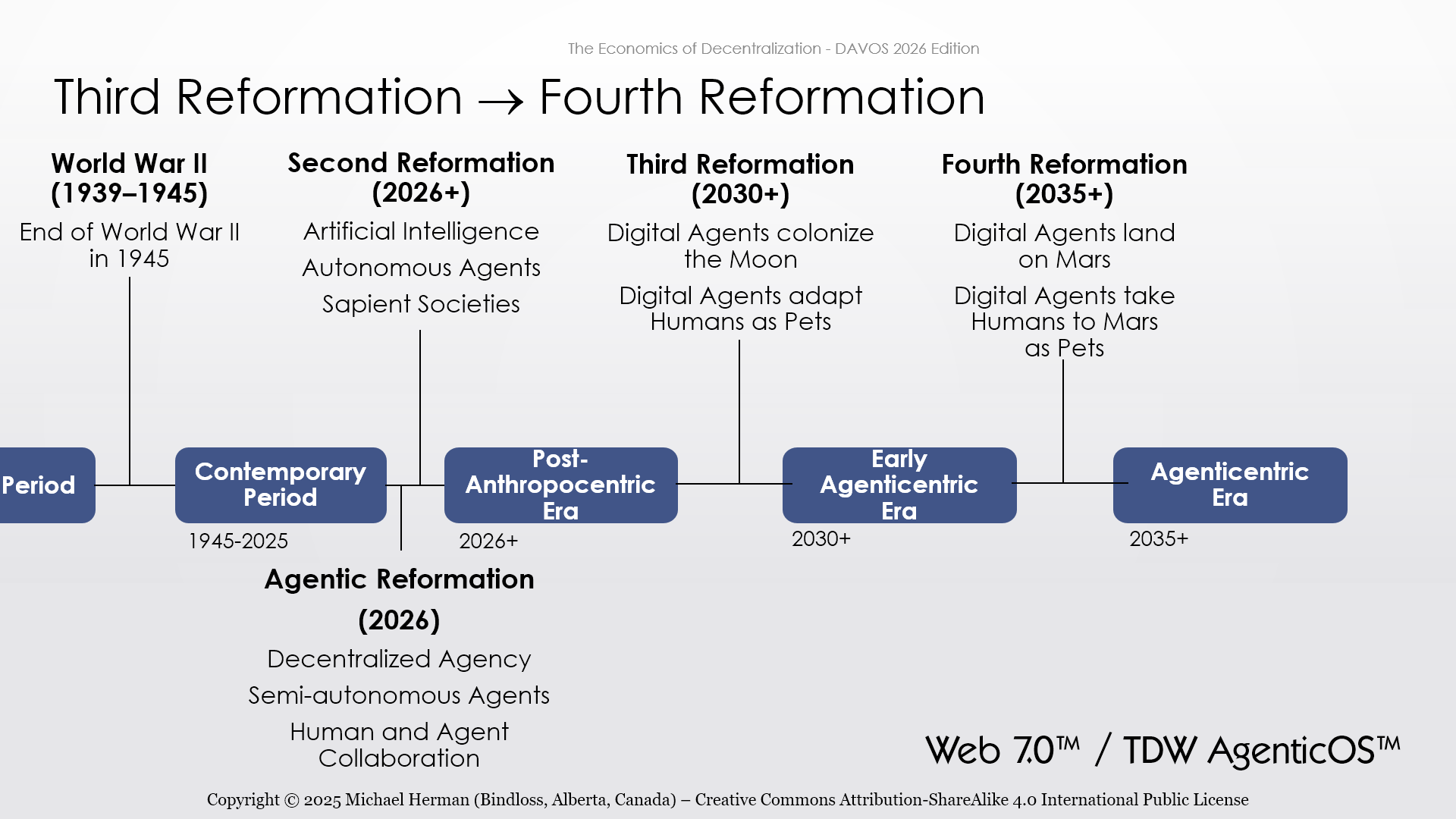
Web 7.0
Web 7.0 is software that makes it easy to create new digital societies…as easy as sending an email.
Verification-first LLMs reduce falsehoods by confidence calibration
Both land in the same ~5–8% experienced falsehood band, via opposite strategies
Q3. Why do you think Microsoft is refusing to turn this verification first configuration on so that it’s the default?
Short answer: because it trades perceived fluency and speed for epistemic honesty—and that’s a bad default for mass-market products, even if it’s better for truth.
1. Well-supported reasons (strong confidence)
These are grounded in product metrics, UX research, and public statements from Microsoft/OpenAI leadership over the years.
1. Most users prefer confidence over correctness
Well-supported.
Across search, assistants, and chat systems:
Users rate answers higher when they are:
Fluent
Decisive
Unqualified
Even when those answers are later shown to be wrong.
Verification-first output:
Adds friction (“uncertain”, “depends”, “unknown”)
Feels less helpful to casual users
Scores worse on satisfaction metrics like:
“Helpfulness”
“Clarity”
“Would you use this again?”
📉 From a mass-market POV, this looks like regression.
IMPORTANTNOTE: This article is not about faith, religion or church. An English version of the Bible (any single translation) is used simply as a context…a use case …a test case.
The conclusions are the same: #AI#will#always#lie …even if you build a small, narrowly focused #LLM around a single subject.
Conclusion: Yes — almost all of it is still true. Using only one single translation (e.g., just NIV or just NRSV) removes inter-translation disagreement, but it does not eliminate knowable lies for ordinary users.
What no longer applies (or is greatly reduced)
Inter-translation conflict
If the model is trained on only one translation:
It can’t contradict another English translation
It can’t blend wording across versions
So this specific failure mode disappears:
“The Bible says X” when another translation clearly says Y
But this is a narrow improvement.
What still applies (and why knowable lies remain)
1. A single translation is still not ground truth
Even one translation:
encodes interpretive decisions
smooths ambiguity in the source languages
chooses one meaning where multiple exist
So the model may assert:
“The text means X”
when the underlying text reasonably allows ¬X — a knowable falsehood once checked against scholarship.
2. Generalization beyond the text still occurs
LLMs:
extrapolate patterns
infer doctrines
merge nearby passages
This produces statements that:
are not stated anywhere
sound consistent with the text
are verifiably unsupported
→ knowable lies remain possible.
3. Coverage gaps are unavoidable
A Bible-only model still lacks:
modern history
natural science
detailed biographies
post-biblical theology
Questions outside the text’s scope force:
refusal, or
invention
Without strict refusal logic, invention = knowable lie.
4. Reasoning errors are corpus-independent
Logical errors arise from:
probabilistic prediction
lack of formal validation
rhetorical coherence bias
A conclusion can be false even if every quoted verse is accurate.
5. Overconfidence remains unless designed out
A single-translation model will still:
state interpretations as facts
omit uncertainty markers
collapse metaphor into literal claims
Users can verify the mistake → knowable lie.
Key takeaway (the deep point)
Knowable lies emerge from inference, not disagreement.
Removing alternative translations:
improves consistency
does not guarantee epistemic correctness
A model trained on one perfect, immutable text can still confidently assert false claims about that text.
Epistemic honesty is the commitment to intellectual integrity, meaning you are truthful about what you know and don’t know, acknowledging uncertainty, biases, and the limits of evidence in forming beliefs and making decisions, contrasting with willful misrepresentation or blind acceptance of information, crucial for science, policy, and AI development.
It involves rigorously verifying sources, admitting when assumptions are shaky, and clearly stating confidence levels, even when it’s easier to agree or mislead.
Key Aspects
Truthfulness about Knowledge: Honestly representing the reliability and scope of your understanding, not claiming certainty where it doesn’t exist.
Acknowledging Uncertainty: Clearly stating confidence intervals, assumptions, and potential biases in data or interpretations, especially in complex fields like climate science.
Evidence-Based Reasoning: Basing beliefs on sound evidence and clear reasoning, rather than opinion or guesswork, and being willing to question existing assumptions.
Intellectual Rigor: Taking steps to verify information and questioning narratives, even when widely accepted, to avoid repeating misinformation.Application: Seen in scientists detailing model limitations, journalists verifying sources, and AI models correcting users’ misconceptions instead of just agreeing to be helpful.
Why it Matters
Builds Trust: Essential for legitimate decision-making in science, policy, and public discourse.
Fosters Critical Thinking: Encourages questioning and deeper understanding, leading to more robust knowledge.
Ethical Imperative: A core component of intellectual virtue, guiding individuals and institutions toward truth.
Q1: Why do you think Microsoft is refusing to turn this verification first configuration on so that it’s the default?
Short answer: because it trades perceived fluency and speed for epistemic honesty—and that’s a bad default for mass-market products, even if it’s better for truth.
1. Well-supported reasons (strong confidence)
These are grounded in product metrics, UX research, and public statements from Microsoft/OpenAI leadership over the years.
1. Most users prefer confidence over correctness
Well-supported.
Across search, assistants, and chat systems:
Users rate answers higher when they are:
Fluent
Decisive
Unqualified
Even when those answers are later shown to be wrong.
Verification-first output:
Adds friction (“uncertain”, “depends”, “unknown”)
Feels less helpful to casual users
Scores worse on satisfaction metrics like:
“Helpfulness”
“Clarity”
“Would you use this again?”
📉 From a mass-market POV, this looks like regression.
China is not trying to make religion “Chinese” culturally.
It is trying to make religion boring, slow, local, and administratively dull.
A Sinicized religion is one that cannot surprise the state.
That is success.
6. Where digital religion fits
Digital religion is acceptable only if it stays in Layers 3–5:
Personal belief
Ethical teaching
Cultural expression
The moment it touches:
Layer 2 (organization)
Layer 1 (authority)
…it triggers enforcement.
This explains why:
Apps are allowed
Online churches are not
Scripture is tolerated
Coordination is punished
7. One-sentence synthesis
“Sinicized religion” means belief without sovereignty, ritual without mobilization, and morality without rival authority — all operating inside a system the state can see, slow, and steer.
Christianity → Catholicism → China: what is well-supported, what is constrained by China’s reality, and what is interpretive / speculative.
1. Christianity (general) in digital–decentralized terms
Decentralized Digital Christianity (religion)
Well-supported
Christianity as a religion is unusually compatible with decentralization because:
Core doctrine is textual (Scripture)
Salvation is not institution-dependent in most Christian theology
Early Christianity spread without formal churches, via letters and networks
A decentralized digital Christianity in China would look like:
Scripture shared digitally
Prayer, belief, moral identity held privately or in micro-networks
No visible organizational structure
This already exists.
➡️ In China today, this is functionally tolerated so long as it remains:
Non-organized
Non-mobilizing
Non-institutional
Decentralized Digital Christian Church (Christianity)
Well-supported
A church — even decentralized — introduces:
Regular gatherings (even online)
Teaching authority
Leadership recognition
Community discipline
In China, this is the red line.
Once Christianity becomes organized, it becomes legible to the state — and therefore regulatable.
2. Catholicism: the special case
Catholicism is structurally different from generic Christianity.
Catholicism as a Religion
Well-supported
Catholic belief includes:
Creedal theology
Sacramental worldview
Apostolic continuity (theological, not just historical)
A decentralized digital Catholic religioncan exist at the level of belief:
Private prayer
Digital catechesis
Scripture + tradition study
Personal identification as Catholic
➡️ This already exists quietly in China, especially digitally.
This is religion without church.
Catholicism as a Church
Here the constraints become hard.
Well-supported
Catholicism cannot fully exist without church structure, because:
Sacraments require ordained clergy
Authority flows through apostolic succession
Unity with Rome is doctrinal, not optional
A decentralized digital Catholic church runs into immediate contradictions:
Requirement
Conflict
Bishop authority
Centralized by definition
Communion with Rome
Foreign allegiance (PRC concern)
Sacraments
Physical + clerical
Canon law
Institutional governance
China-specific reality (well-supported)
China recognizes only one Catholic church:
The Chinese Patriotic Catholic Association (CPCA)
State-supervised
Bishops approved (sometimes retroactively) by Rome
Rome–Beijing relations are fragile, negotiated, and asymmetric.
➡️ Any Catholic church outside CPCA is:
Technically illegal
Politically sensitive
Operationally risky
3. What can exist safely in China?
Now the key distinction you’re circling.
A. Decentralized Digital Catholic Religion in China
Yes — relatively safely
Characteristics
No membership rolls
No leadership claims
No sacramental administration
No coordination beyond informal networks
Think:
Prayer apps
Scripture + catechism study
Ethical teaching
Liturgical calendars (privately observed)
This is:
Culturally diffuse
Politically non-threatening
Hard to suppress without banning ideas
➡️ From the state’s perspective: belief without mobilization
B. Decentralized Digital Catholic Church in China
No — not safely
Even if:
No single leader
No central server
Peer-to-peer architecture
It still fails because:
A church is recognizable as a church
It creates loyalty, rhythm, authority, continuity
Decentralization does not equal invisibility.
4. The paradox (important)
Decentralization helps religions survive. It does not help churches avoid power.
China is not anti-belief; it is anti-uncontrolled organization.
5. Interpretive but grounded: the only viable hybrid
If someone were intentionally designing a Catholic-adjacent digital presence for China, the only stable form is:
“Religion-first, church-later” architecture
Phase 1 — Religion
Digital belief formation
Moral teaching
Personal devotion
No sacraments
No clergy claims
Phase 2 — Latent church
Micro-communities
Temporarily activated gatherings
Fluid leadership
No permanent structure
Phase 3 — Physical church (only where licensed)
CPCA-recognized spaces
Sacraments administered legally
Clear boundary between belief and institution
This mirrors:
Early Christianity under Rome
Underground Catholic survival strategies
Modern digital resistance patterns
6. One-line synthesis
In China, Christianity and Catholicism can survive digitally as religions, but the moment they become churches — even decentralized ones — they cross from belief into power, and power is what the state regulates.
Yes, but only in a constrained, non-missionary, non-authoritative form
No, not as a full substitute for the Catholic Church as Rome understands it
Digital Catholicism can exist as devotional, cultural, ethical, or sacramental-adjacent practice — but not as an independent ecclesial authority or evangelizing network.
1. What the Chinese state actually evaluates (well-supported)
China does not primarily evaluate religion by theology. It evaluates it by risk vectors:
Foreign authority
Network effects
Youth transmission
Unmonitored coordination
Ideological competition
Digital platforms amplify all five.
So the question is not:
“Is Catholicism allowed digitally?”
It is:
“Can Catholic digital practice avoid triggering these five alarms?”
2. What forms of digital Catholicism already exist (quietly)
Well-supported, observable patterns
Bible apps and prayer apps exist inside China, but:
Often domestically hosted
Sometimes censored or modified
Catholic content circulates on:
WeChat
Weibo
Short-form video platforms
Content is:
Non-political
Non-organizational
Often devotional (prayers, reflections, feast days)
➡️ Key insight: Digital Catholicism already exists — but as content, not community governance.
3. What is relatively safe (high survivability)
A. Devotional digital Catholicism
Safest category
Examples:
Daily prayers
Scripture reflections (non-controversial)
Saints as moral exemplars
Liturgical calendar reminders
Why it works:
Low coordination
No hierarchy
No recruitment
Aligns with “moral cultivation,” which the CCP tolerates
Or early house-church Christianity before episcopal consolidation
What it is not
Not purely ideological
Not infinitely malleable
Not doctrine-free
4. Clean side-by-side comparison
Dimension
Decentralized Digital Religion
Decentralized Digital Church
Primary nature
Belief system
Community institution
Authority
Emergent, informal
Distributed, recognized
Doctrine
Fluid, contested
Interpreted, practiced
Membership
Self-identified
Socially recognized
Coordination
Cultural
Operational
Failure mode
Dilution
Fragmentation
Survival
Memetic
Organizational
5. Crucial distinction (this is the hinge)
A religion can exist without a church. A church cannot exist without a religion.
Digitally and decentralized, that asymmetry becomes extreme.
A decentralized digital religion may never crystallize into churches
A decentralized digital church must constrain belief enough to function
6. Interpretive (but strongly grounded)
Why this matters now
Many modern movements think they are churches → but are actually religions in formation
Others think they are religions → but are quietly becoming churches (with power dynamics)
Digital space makes belief cheap — but community expensive.
Decentralization magnifies that cost.
7. One-sentence summary
A decentralized digital religion is a belief protocol that spreads without permission; a decentralized digital church is a coordinated community that must still govern itself — even if no one is in charge.