Pattern:id at the document root is always an identity DID. Every field that contains a fragment — verification methods, verification relationships, service entries — is always a locator DID. controller is always an identity DID. serviceEndpoint values are retrieval URLs, outside the DID identity/locator taxonomy entirely.
Pattern: Top-level id, issuer.id, credentialSubject.id, and any DID references within claims are all identity DIDs — they name entities. credentialStatus.id and proof.verificationMethod are locator DIDs — they navigate to sub-resources. The credentialStatus.id is the one field that often goes unrecognized as a locator but clearly is: it points into a status registry to retrieve the current revocation state of this specific credential.
DIDComm Message
{
"id": "urn:uuid:f81d4fae-7dec-11d0-a765-00a0c91e6bf6", ← IDENTITY (message identity — URN, not DID)
Pattern: DIDComm message fields are overwhelmingly identity DIDs — from, to, from_prior.iss, from_prior.sub, from_prior.aud all name parties, not locations. The message id is typically a URN UUID — an identity token outside the DID space entirely. Locator DIDs appear only when explicitly navigating to a sub-resource — such as a CredentialRegistry service endpoint in an attachment link, or a verification method reference in an attached cryptoseal.
Cross-Document Summary
Field
DID Doc
VC Doc
DIDComm
Document id
Identity
Identity
Identity (URN)
controller
Identity
—
—
issuer / issuer.id
—
Identity
—
credentialSubject.id
—
Identity
—
from / to
—
—
Identity
from_prior.iss / .sub
—
—
Identity
verificationMethod.id
Locator
—
—
Verification relationship refs
Locator
—
—
service.id
Locator
—
—
proof.verificationMethod
—
Locator
—
credentialStatus.id
—
Locator
—
Attachment links with ?service=
—
—
Locator
The governing rule across all three document types is consistent and clean:
A DID with no # or ? is always an identity DID — it names an entity. A DID with # or ? is always a locator DID — it navigates to a sub-resource. This rule holds uniformly across DID Documents, VC Documents, and DIDComm Messages.
This specification defines Web 7.0 Verifiable Trust Circles (VTCs), a generalized mechanism for expressing verifiable multi-party membership, belonging, and trust relationships using the W3C Verifiable Credentials (VC) Data Model 2.0 and VC Data Integrity Proof Sets. VTCs extend the Partof Architecture Reference Model (PARM) — also referred to as the MemberOf or CitizenOf model — to provide a universal credential pattern that subsumes prior pairwise constructs (PHCs, VRCs) and additionally supports voting-based decision making, meeting requests, task forces, and digital societies.
STATUS
This document is derived from community discussion in the Trust over IP Foundation (ToIP) Digital Trust Graph Working Group (DTGWG) Credentials Task Force, GitHub Discussion #8, November–January 2025–2026.
Table of Contents
1. Introduction
2. Terminology and Definitions
3. Design Principles
4. The Partof Architecture Reference Model (PARM)
5. VTC Data Model
6. VTC Proof Set Lifecycle
7. Roles and Participants
8. Use Cases
9. Privacy and Security Considerations
10. Conformance
11. Relationship to Other Specifications
12. References
1. Introduction
The Web 7.0 paradigm seeks to establish a decentralized, agent-centric, privacy-preserving digital society. Central to this vision is the ability of digital entities — people, organizations, autonomous agents — to form verifiable groups: trust circles that are cryptographically provable, privacy-respecting, and composable.
Prior specifications in the Trust over IP (ToIP) ecosystem defined pairwise constructs (Personhood Credentials, PHCs; and Verifiable Relationship Credentials, VRCs) to link pairs of entities. While useful, these constructs are insufficient to describe multi-party group membership, community affiliation, or collective decision-making.
This specification introduces Verifiable Trust Circles (VTCs), which generalize pairwise credentials into an N-party construct using the standard W3C VC Proof Set mechanism. A single VTC credential can represent a self-credential (N=1), a bilateral relationship (N=2), or any multi-member group (N>2), enabling a single, coherent model for all membership-like relationships.
NOTE
Proof Sets are a normative feature of the W3C VC Data Integrity specification and are explicitly designed for scenarios in which the same data needs to be secured by multiple entities. VTCs leverage this mechanism rather than inventing new cryptographic primitives.
1.1 Motivation
The following observations motivate this specification:
PHCs and VRCs both express a form of ‘belonging to’ — they are specializations of the same universal pattern.
The W3C VC Data Model 2.0 already provides Proof Sets as a standard mechanism for multi-party signing.
A single, generalized Web 7.0 Verifiable Trust Circles (VTCs) pattern — grounded in First Principles Thinking — can subsume both constructs and additionally support voting, community membership, digital governance, and inter-network trust.
The SSC 7.0 Metamodel defines three controller layers (Beneficial, Intermediate, Technical) at which VTCs may apply, enabling rich composability.
1.2 Scope
This specification defines:
The VTC data model, including required and optional properties.
The roles of Initiator, Responder(s), and Notary within a VTC.
The lifecycle of a VTC Proof Set, from initial issuance through multi-party endorsement.
Use case profiles: self-credential, bilateral relationship, multi-party group, and voting scenario.
Privacy and security considerations specific to multi-party proof sets.
This specification does not define transport protocols, DID method requirements, or verifiable presentation formats, except where necessary to illustrate the VTC pattern.
2. Terminology and Definitions
The following terms are used throughout this specification. Unless stated otherwise, terms have the meanings assigned in the W3C Verifiable Credentials Data Model 2.0 [VC-DATA-MODEL].
Verifiable Trust Circle (VTC)
A Verifiable Credential whose credential subject identifies a multi-party trust relationship, and whose proof property contains a Proof Set with one proof contribution per participating member, plus the Notary’s initial proof.
Web 7.0 Verifiable Trust Circles (VTCs)
The generalised name for the VTC pattern when applied to the broader class of MemberOf, PartOf, and CitizenOf relationships. A VTC is a UMC.
Proof Set
As defined in W3C VC Data Integrity [VC-DATA-INTEGRITY], a set of proofs attached to a single secured document where the order of proofs does not matter. Each proof is contributed by a distinct signer.
Initiator (A)
The entity that proposes or originates a VTC. Identified by a DID. Corresponds to the ‘from’ role in VTC credential subject properties.
Responder (B, …, Z)
One or more entities that accept membership in a VTC by contributing their cryptographic proof to the Proof Set. Identified by DIDs. Corresponds to entries in the ‘to’ array.
Notary (N)
A trusted third party — trusted by both Initiator and all Responders — that issues the initial credential shell and contributes the first proof. The Notary is assigned to the VC ‘issuer’ role. In some use cases the Notary MAY be the Initiator or a Responder, provided they play both roles distinctly.
PARM
Partof Architecture Reference Model. The universal pattern underlying VTCs, encompassing MemberOf, CitizenOf, and PartOf relationships.
SSC 7.0 Metamodel
Self-Sovereign Control 7.0 Metamodel. Defines three controller layers — Beneficial Controller, Intermediate Controller (Agent), and Technical Controller (Agent) — at which VTCs may be anchored.
DTG
Digital Trust Graph. A graph of trust relationships between entities, each edge of which may be represented by a VTC.
PHC
Personhood Credential. A pairwise credential representing proof of personhood; a degenerate VTC where N=1.
VRC
Verifiable Relationship Credential. A pairwise credential representing a bilateral relationship; a degenerate VTC where N=2.
DID
Decentralized Identifier, as defined in [DID-CORE].
3. Design Principles
This specification adheres to the following design principles, consistent with the ToIP DTGWG Design Principles [DTGWG-DESIGN]:
3.1 As Simple As Possible But No Simpler
VTCs are grounded in existing W3C VC standards. No new cryptographic primitives or credential types are defined. The only structural addition is the deliberate use of the proof array (Proof Set) to carry per-member proofs alongside the Notary proof.
3.2 First Principles Thinking
PHCs and VRCs are recognized as specializations of a single underlying relationship pattern (PARM). Rather than defining multiple credential types for essentially the same concept, this specification derives one universal type that covers all cases by varying the cardinality of the ‘to’ array and the composition of the Proof Set.
3.3 Privacy by Design
VTC credential subjects SHOULD use confidentialSubject semantics wherever selective disclosure is required. Members of a VTC should be able to prove membership to a verifier without unnecessarily revealing the full membership list. Zero-Knowledge Proof (ZKP) integration in Proof Sets is explicitly supported and encouraged.
3.4 Composability
VTCs compose at each layer of the SSC 7.0 Metamodel. A VTC at the Beneficial Controller layer expresses human-level trust relationships; one at the Intermediate Agent layer expresses agent-level relationships; one at the Technical Controller layer expresses device/key-level relationships.
3.5 Cross-Network Trust
The PARM model is network-agnostic. The same VTC pattern supports trust relationships across and between independent, distinct networks and ecosystems.
4. The Partof Architecture Reference Model (PARM)
The Partof Architecture Reference Model (PARM) provides the conceptual foundation for VTCs. It observes that a large class of real-world relationships — membership, citizenship, parthood, employment, participation — share a common logical structure:
Relationship Type
Example
MemberOf
Alice is a member of the Working Group Trust Circle.
PartOf
Bob is part of the study group.
CitizenOf
Carol is a citizen of the Digital Nation State of Sovronia.
EmployeeOf
Dave is an employee of Acme Corp (DID-identified).
ParticipantOf
Eve is a participant of the 09:00 meeting (a VC-based meeting request).
VoterFor
Frank has cast a vote for Candidate 1 by contributing his proof to that VTC.
All of these reduce to the same credential structure: a VC whose credentialSubject.id identifies the group or decision entity (the ‘circle’), and whose proof array contains proofs from the Notary and each member who has accepted membership. PHCs and VRCs are degenerate cases of this pattern with N=1 and N=2 respectively.
5. VTC Data Model
5.1 Overview
A VTC is a valid W3C Verifiable Credential [VC-DATA-MODEL] with the following structural characteristics:
The issuer property identifies the Notary (N).
The credentialSubject (or confidentialSubject) object includes from, to, and optionally metadata properties that identify the Initiator, Responders, and relationship metadata respectively.
The credentialSubject.id identifies the relationship or group itself, expressed as a DID.
The proof property is an array (Proof Set), containing one proof per signer, ordered as: Notary first, then Initiator, then Responders.
5.2 Minimal Pairwise VTC (N=2, Alice and Bob)
The following non-normative example illustrates a bilateral VTC between Alice (Initiator) and Bob (Responder), notarised by a Notary entity:
For groups with more than two members, the to array is extended to include all Responders, and the proof array gains one additional entry per additional Responder:
When to contains only the Initiator’s own DID, or when from and credentialSubject.id are the same entity, the VTC degenerates to a Personhood Credential (PHC):
For a voting scenario, one VTC is created per candidate. Voters cast their vote by contributing their individual proof to the VTC of the candidate they support. The vote count is the number of valid member proofs in the Proof Set.
The to array MAY be populated in advance with eligible voter DIDs, or it MAY be left empty and populated as votes are cast, depending on the election policy and privacy requirements.
5.6 Properties Reference
Property
Req.
Description
id
REQUIRED
DID identifying the VTC credential itself. SHOULD use did:envelope or equivalent.
type
REQUIRED
MUST include ‘VerifiableCredential’ and ‘VerifiableTrustCircle’.
issuer
REQUIRED
DID of the Notary (N). The Notary MUST be trusted by all members.
credentialSubject.id
REQUIRED
DID identifying the relationship or group itself. This is C in the PARM model.
credentialSubject.from
REQUIRED
DID of the Initiator (A).
credentialSubject.to
REQUIRED
Array of DIDs of Responders. MAY be empty for open voting VTCs. MAY include the Initiator’s DID.
credentialSubject.metadata
OPTIONAL
Arbitrary structured metadata about the relationship (label, policy, expiry, etc.).
proof
REQUIRED
Array of proof objects (Proof Set). First proof MUST be from the Notary. Subsequent proofs are from Initiator then Responders in any order.
proof[].id
REQUIRED
DID of the signer contributing this proof entry.
6. VTC Proof Set Lifecycle
The VTC Proof Set lifecycle consists of the following phases. At each phase t, the VTC applies to the Notary and the first t members who have contributed their proof.
Phase 0 — Null VTC
The credential shell is created by the Notary with an empty or pre-populated to array. The Notary contributes the initial proof. No member relationships are yet verified. t = 0.
Phase 1..t — Progressive Endorsement
Each Responder, in any order, reviews the credential and — if they consent to membership — adds their individual proof to the existing Proof Set using the ‘add-proof-set-chain’ algorithm defined in [VC-DATA-INTEGRITY]. The VTC becomes valid for those t members who have signed. Non-signing members are not yet bound.
Phase N — Complete VTC
All Responders listed in the to array have contributed their proofs. The VTC is fully executed and represents a complete, verifiable, multi-party trust relationship.
NOTE
Partial VTCs (0 < t < N) are valid credentials representing the subset of relationships established so far. Verifiers MUST check which proofs are present before asserting full circle membership.
6.1 Adding a Proof
To add a proof to an existing secured VTC, implementors MUST follow the algorithm specified in W3C VC Data Integrity [VC-DATA-INTEGRITY], Section ‘add-proof-set-chain’. The proof is appended to the existing proof array without modifying prior proofs.
6.2 Proof Ordering
Proof Sets are unordered by definition. However, this specification RECOMMENDS the following conventional ordering for readability and auditability: (1) Notary proof, (2) Initiator proof, (3) Responder proofs in the same order as the to array.
7. Roles and Participants
7.1 Notary (N) — Issuer
The Notary is the credential issuer. It MUST be trusted by both the Initiator and all Responders. The Notary is responsible for creating the credential shell, pre-populating the to array (or defining the voting policy), and contributing the first proof. In some use cases, the Notary MAY be the same entity as the Initiator or a Responder, provided that entity plays each role distinctly and the resulting credential satisfies all REQUIRED properties.
7.2 Initiator (A) — From
The Initiator proposes the trust circle. The Initiator’s DID appears in credentialSubject.from. The Initiator contributes a proof to the Proof Set to signify their acceptance of the relationship.
7.3 Responders (B … Z) — To
Each Responder is identified in the credentialSubject.to array. A Responder accepts membership by contributing their individual proof. A Responder who does not contribute a proof is proposed but not yet a verified member.
RULE
The cardinality t of verified members at any time equals the number of valid member proofs (excluding the Notary proof) present in the Proof Set.
8. Use Cases
8.1 Bilateral Trust Relationship (VRC Equivalent)
Alice and Bob wish to establish a verifiable bilateral trust relationship. A Notary (mutually trusted) issues a VTC with from = Alice and to = [Bob]. Both Alice and Bob contribute proofs. The result is a two-party VTC that is equivalent to a classic VRC.
8.2 Personhood Credential (PHC Equivalent)
Alice wishes to create a self-signed personhood credential. A Notary issues a VTC with from = Alice and to = [Alice]. Alice contributes her proof. The result is a one-party VTC equivalent to a PHC.
8.3 Working Group or Task Force
A task force of N participants is formed. A Notary (the WG chair or a community DID) issues a VTC with from = chair and to = [member1, …, memberN]. Members join by contributing their proofs. The VTC provides a cryptographically verifiable roster.
8.4 VC-Based Meeting Request
An organiser issues a VTC with credentialSubject.id = the meeting DID, from = organiser, and to = [attendee1, …, attendeeN]. Attendees RSVP by contributing their proofs. Attendance at the meeting is verifiable from the Proof Set.
8.5 Voting-Based Decision Making
One VTC per candidate is issued by an election official (Notary). Eligible voters cast their vote by contributing their individual proof to the VTC of their chosen candidate. Vote tallying is performed by counting the number of valid member proofs in each candidate’s VTC. This supports maximum flexibility in vote-counting policies (simple majority, ranked-choice, threshold).
8.6 Verifiable Decentralised Registry (VDR)
VC-based voting can be applied to implement a VC-based Verifiable Data Registry (VDR). Append operations to a distributed registry are authorised through a VTC whose members are the registry trustees.
8.7 Digital Society / Digital Nation State
A digital society (e.g. a digital religion, community, or nation state) is defined by a VTC whose members are the citizens. Governance operations — electing trustees, passing resolutions — are performed through subsidiary voting VTCs.
9. Privacy and Security Considerations
9.1 Selective Disclosure
Implementations are STRONGLY RECOMMENDED to use confidentialSubject semantics and selective disclosure proof mechanisms (e.g. BBS+ signatures) to allow individual members to prove their membership in a VTC without revealing the full membership list or metadata.
9.2 ZKP Integration
The Proof Set mechanism is compatible with zero-knowledge proof (ZKP) contributions. A member MAY contribute a ZKP as their proof entry, revealing only that they meet the membership criteria without revealing their DID. Implementations SHOULD define a profile for ZKP-based proof entries.
9.3 Privacy Budget and Reconstruction Ceiling
When multiple agents controlled by one First Person contribute to a shared VTC, care must be taken to ensure that the combined disclosure across proof entries does not exceed the privacy budget of the First Person. The reconstruction ceiling — the probability that an observer can reconstruct the First Person’s identity from the combined proof data — MUST be maintained below the threshold defined by the applicable trust framework.
NOTE
This consideration was raised during community discussion in the context of internal VTCs and the Trust Spanning Protocol (TSP) between two agents controlled by one First Person.
9.4 Notary Trust
The Notary (issuer) occupies a privileged position: it issues the credential shell and contributes the first proof. Verifiers MUST independently verify that the Notary is trusted by all relevant parties. The Notary SHOULD be a well-known, community-governed DID with transparent governance.
9.5 Voting Integrity
For voting VTCs, the following security properties MUST be considered: (1) eligibility — only eligible voters can contribute proofs; (2) anonymity — voter DIDs SHOULD be anonymised or pseudonymised; (3) non-repudiation — each proof is cryptographically bound to the voter’s key; (4) single-vote enforcement — the to array or the Notary’s policy SHOULD prevent duplicate proof contributions from the same voter DID.
10. Conformance
A conforming VTC implementation:
MUST produce VTC credentials that are valid W3C Verifiable Credentials conforming to [VC-DATA-MODEL].
MUST use a proof array (Proof Set) as defined in [VC-DATA-INTEGRITY].
MUST include the issuer property identifying the Notary.
MUST include credentialSubject.id, credentialSubject.from, and credentialSubject.to.
MUST use the ‘add-proof-set-chain’ algorithm from [VC-DATA-INTEGRITY] when adding proofs incrementally.
SHOULD include ‘VerifiableTrustCircle’ in the type array.
SHOULD implement selective disclosure mechanisms for credentialSubject properties.
MAY extend the credentialSubject.metadata property with domain-specific claims.
11. Relationship to Other Specifications
11.1 W3C VC Data Model 2.0
VTCs are valid W3C Verifiable Credentials. All normative requirements of [VC-DATA-MODEL] apply. VTCs use the issuer and credentialSubject properties as defined therein.
11.2 W3C VC Data Integrity
VTCs rely on the Proof Set mechanism defined in [VC-DATA-INTEGRITY], specifically the ‘add-proof-set-chain’ algorithm for incremental proof contributions.
11.3 ToIP DTGWG Design Principles
This specification is consistent with the ToIP DTGWG Design Principles [DTGWG-DESIGN] and the DTG-ZKP Requirements [DTGWG-ZKP].
11.4 SSC 7.0 Metamodel
VTCs integrate with the Self-Sovereign Control 7.0 Metamodel [SSC-7]. VTCs may be anchored at the Beneficial Controller, Intermediate Controller, or Technical Controller layer.
11.5 Trust Spanning Protocol (TSP)
VTCs are compatible with the Trust Spanning Protocol [TSP] as a credential format for expressing channel-level membership and authorization relationships.
This specification was derived from community discussion contributions by: Michael Herman (mwherman2000), @talltree, @adamstallard, @mitchuski, @peacekeeper, @GraceRachmany, and other participants of the Trust over IP Foundation DTGWG Credentials Task Force. The editors gratefully acknowledge all contributors to GitHub Discussion #8.
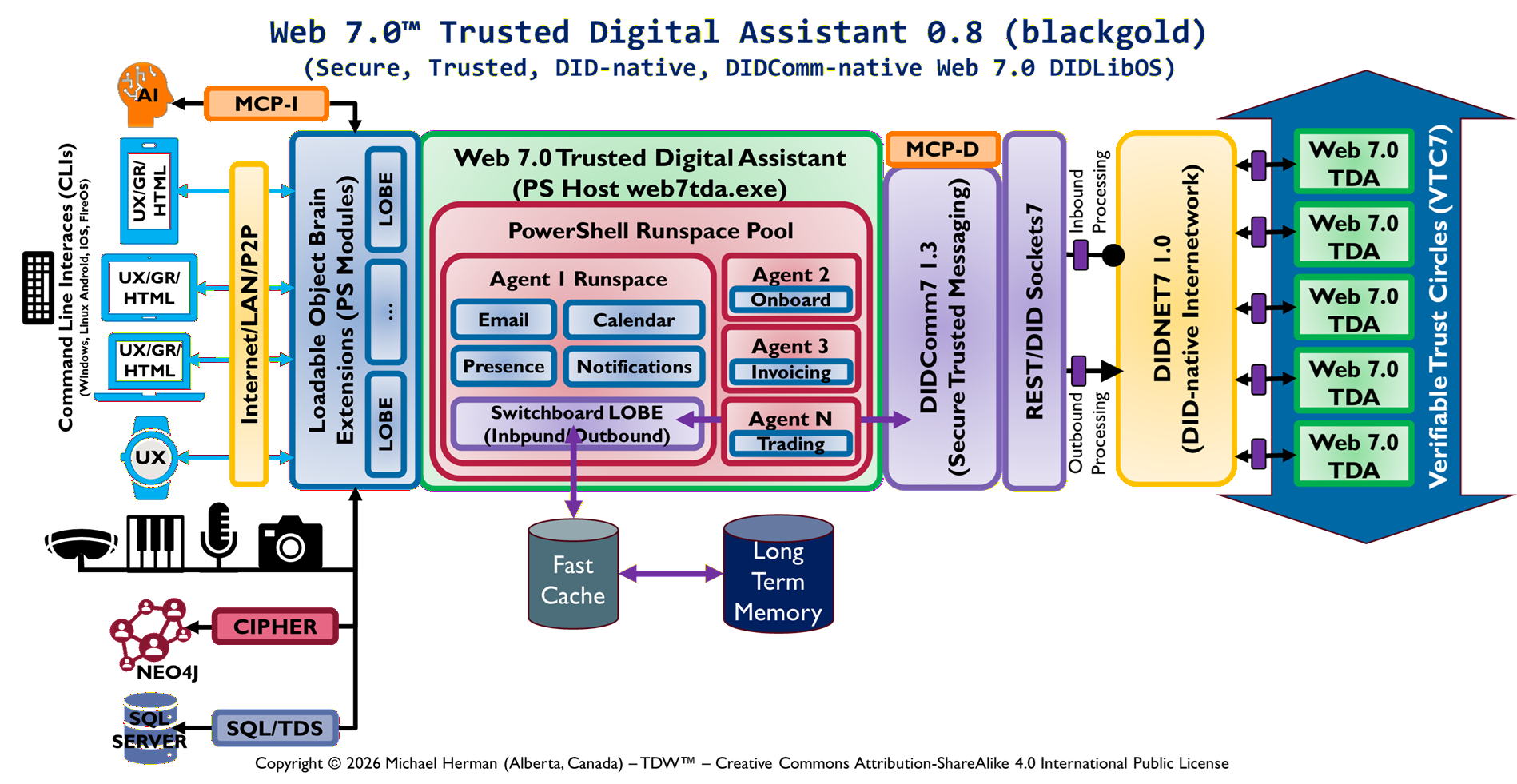
14. Appendix A: Web 7.0 DIDLibOS Architecture Reference Model (DIDLibOS-ARM)
Web 7.0 DIDLibOS defines an identity-addressed, event-sourced execution architecture in which all computation is performed over DIDComm messages persisted in a single LiteDB instance per agent. Instead of passing in-memory objects between computational steps, the system passes Decentralized Identifier (DID) strings that resolve to immutable message state stored in a persistent memory kernel. This enables deterministic execution, full replayability, cross-runspace isolation, and scalable agent orchestration.
2. Introduction
Traditional execution models in scripting and automation environments rely on in-memory object pipelines. These models break under distributed execution, concurrency, and long-term persistence requirements. Web 7.0 DIDLibOS replaces object-passing semantics with identity-passing semantics.
In this model, computation becomes a function over persistent state rather than transient memory.
This document specifies the did7:web7 Decentralized Identifier (DID) method, which defines a deterministic mapping from Uniform Resource Names (URNs) (RFC 8141) into a DID-compatible identifier format called a Decentralized Universal Resource Name (URN). The did7:web7 method preserves URN semantics, enables DID resolution without mandatory centralized infrastructure, and provides optional cryptographic and service-layer extensibility. The method is fully compatible with the W3C DID Core specification (W3C DID Core, 2022) and the broader DID ecosystem.¶
This note is to be removed before publishing as an RFC.¶
This Internet-Draft is derived from the Web 7.0 Foundation specification “SDO: W3C Decentralized Resource Name (URN) DID Method (Web 7.0)” authored by Michael Herman, published 24 March 2026 at https://hyperonomy.com/2026/03/24/ sdo-web-7-0-decentralized-resource-name-urn-did-method/ and licensed under the Creative Commons Attribution-ShareAlike 4.0 International Public License. Web 7.0(TM), Web 7.0 DIDLibOS(TM), TDW AgenticOS(TM), TDW(TM), Trusted Digital Web(TM), and Hyperonomy(TM) are trademarks of the Web 7.0 Foundation. All Rights Reserved.¶
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.¶
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet-Drafts is at https://datatracker.ietf.org/drafts/current/.¶
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as “work in progress.”¶
This Internet-Draft will expire on 25 September 2026.¶
Copyright (c) 2026 IETF Trust and the persons identified as the document authors. All rights reserved.¶
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (https://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document.¶▲
Uniform Resource Names (URNs) [RFC8141] provide a well-established mechanism for assigning persistent, location-independent identifiers to resources. However, URNs predate the Decentralized Identifier (DID) ecosystem [W3C.DID-CORE] and lack native support for DID resolution, DID Document retrieval, cryptographic verification methods, or service endpoint declaration.¶
At the same time, many existing information systems such as bibliographic catalogues, digital libraries, standards registries, and supply-chain systems rely heavily on URN-based identification. Retrofitting these systems with entirely new identifier schemes is often impractical.¶
The did7:web7 method bridges this gap. It defines a deterministic, reversible transformation from any well-formed URN into a DID-compatible identifier called a Decentralized Universal Resource Name (URN). The resulting DID is fully resolvable, is backwards compatible with the source URN, requires no mandatory centralized registry, and is composable with other DID methods such as did:key, did:web, and did:peer.¶
Preservation of URN semantics and namespace-specific comparison rules.¶
Deterministic, stateless baseline resolution requiring no external infrastructure.¶
Optional cryptographic extensibility through verification methods.¶
Optional service-layer extensibility through service endpoints.¶
Full conformance with the W3C DID Core specification [W3C.DID-CORE].¶
The did7:web7 method is positioned as a universal adapter between the URN and DID ecosystems, serving as a semantic identity bridge that preserves existing meaning while enabling participation in the modern decentralized identity landscape.¶
The key words MUST, MUST NOT, REQUIRED, SHALL, SHALL NOT, SHOULD, SHOULD NOT, RECOMMENDED, NOT RECOMMENDED, MAY, and OPTIONAL in this document are to be interpreted as described in BCP 14 [RFC2119] [RFC8174] when, and only when, they appear in all capitals as shown here.¶
ABNF notation used in this document follows [RFC5234].¶
URN (Uniform Resource Name): A persistent, location-independent identifier conforming to the syntax defined in [RFC8141], of the form urn:<NID>:<NSS>.¶ NID (Namespace Identifier): The registered URN namespace label (e.g., isbn, uuid, ietf).¶ NSS (Namespace-Specific String): The portion of a URN following the NID, interpreted according to the rules of the corresponding URN namespace registration.¶ URN (Decentralized Universal Resource Name): A URN expressed within the did7:web7 method namespace; the method-specific identifier portion of a did7:web7 DID.¶ DID Document: A set of data describing the DID subject, as defined in Section 5 of [W3C.DID-CORE].¶ Resolver: A software component that, given a DID, returns a DID Document conforming to the requirements of [W3C.DID-RESOLUTION].¶ Controller: An entity, as identified by a DID, that has the capability to make changes to a DID Document, as defined in [W3C.DID-CORE].¶ Fingerprint: A cryptographic hash of a canonical representation of the embedded URN, used to derive a did:key-compatible equivalent identifier.¶
The method name that identifies this DID method is: urn.¶
A DID conforming to this specification begins with the prefix did7://web7/. This prefix is case-insensitive for resolution purposes, but implementations SHOULD produce lowercase prefixes in all output.¶
Implementations MUST normalize the embedded URN according to the lexical equivalence and case-folding rules specified in Section 3.1 of [RFC8141] before constructing or comparing a did7:web7 identifier. Namespace-specific comparison rules (q-component handling, etc.) as registered with IANA for each NID MUST also be preserved.¶
Percent-encoding normalization (Section 2.1 of [RFC3986]) applies to the NSS component where permitted by the applicable namespace registration.¶
A given URN MUST map deterministically to exactly one did7:web7 identifier. The transformation is purely syntactic; no randomness or external state is introduced. Two URNs that are lexically equivalent per [RFC8141] MUST produce the same did7:web7.¶
The original URN MUST be exactly recoverable from the did7:web7 identifier without loss of information. No encoding, hashing, or irreversible transformation is applied to the URN content.¶
Baseline resolution of a did7:web7 identifier MUST NOT require access to any centralized registry, distributed ledger, or network service. A conformant resolver MUST be capable of constructing a minimal conformant DID Document entirely from the information contained within the DID string itself (see Mode 1, Section 7.3).¶
The resolution input is a did7:web7 string conforming to the syntax defined in Section 5.1, optionally accompanied by resolution options as defined in [W3C.DID-RESOLUTION].¶
A conformant resolver MUST support stateless resolution. In this mode the resolver constructs the DID Document locally from the DID string alone, without any external network lookup.¶
where canonical-urn is the normalized URN string (UTF-8 encoded) and hash is a cryptographic hash function registered for use with did:key (e.g., SHA-256 with multibase encoding [I-D.multiformats-multibase]). The derived fingerprint SHOULD be expressed as a did:key identifier and added to the DID Document as follows:¶
Discovery rules SHOULD be namespace-aware, such that a resolver for urn:isbn: DIDs may apply different discovery heuristics than one for urn:uuid: DIDs.¶
When external discovery yields a DID Document, that document MUST be validated for consistency with the locally constructed baseline document before being returned to the caller. Specifically, the id and alsoKnownAs values MUST match the baseline.¶
A DID Document MAY include one or more verification method entries to support cryptographic operations associated with the identified resource. The following is an example using the Ed25519VerificationKey2020 type:¶
A DID Document MAY include service endpoint entries to enable discovery of resources or services associated with the URN. The following is an illustrative example:¶
Service endpoints MUST conform to Section 5.4 of [W3C.DID-CORE]. The type value SHOULD be registered in a publicly accessible DID Specification Registries entry [W3C.DID-SPEC-REGISTRIES].¶
Where Mode 2 resolution (Section 7.3.2) is supported, the DID Document MAY include an equivalentId property expressing the deterministic fingerprint-derived did:key as described in Section 7.3.2.¶
A did7:web7 identifier does not inherently assert or imply a controller. In the baseline stateless resolution mode (Mode 1), the DID Document contains no controller property. The absence of a controller property indicates that control has not been established through this mechanism.¶
The did7:web7 method does not inherently provide authenticity guarantees. A DID Document produced by a stateless resolver (Mode 1) is constructed locally and carries no cryptographic proof of its origin or integrity.¶
Implementations that require trust assurances SHOULD layer one or more of the following mechanisms on top of the baseline:¶
Cryptographic proofs: Attach verification methods and associated proofs (e.g., JSON-LD Proofs, JOSE signatures) to the DID Document as described in Section 8.2.1.¶
Third-party attestations: Bind Verifiable Credentials from trusted issuers to the URN to assert provenance, authenticity, or ownership.¶
Namespace authority validation: Dereference the URN through its canonical namespace registry to verify that the identified resource exists and that any asserted attributes are consistent.¶
Consumers of did7:web7 DID Documents SHOULD NOT infer trustworthiness solely from the presence of the DID; trust evaluation MUST take into account the verification mechanisms present in the DID Document and the verifier’s trust policy.¶
The did7:web7 method supports the following subset of CRUD operations as defined in [W3C.DID-CORE]:¶
Operation
Status
Notes
Create
Implicit
A URN is created implicitly by forming the syntactic transformation of a well-formed URN per Section 5.1. No registration step is required.
Read
REQUIRED
Resolution MUST be supported in at least Mode 1 (stateless), per Section 7.3.1.
Update
NOT SUPPORTED
The baseline stateless method does not support document updates. Updates are only possible in Mode 3 via an external discovery service that supports document management.
Deactivate
NOT SUPPORTED
Deactivation is not supported in the baseline method. External service layers may implement deactivation semantics independently.
The did7:web7 method is fully backward compatible with existing URN infrastructure. The embedded URN is preserved verbatim (after normalization) within the DID string, and no changes to existing URN registries, resolvers, or applications are required.¶
The alsoKnownAs property in the DID Document ensures that a did7:web7 DID can always be mapped back to its source URN, enabling interoperability with legacy systems that do not support DID resolution.¶
The did7:web7 method is compatible with the W3C DID Core specification [W3C.DID-CORE] and the DID Resolution specification [W3C.DID-RESOLUTION]. It is composable with the following DID methods:¶
did:key – via the deterministic fingerprint mechanism (Section 7.3.2).¶
did:web – a did7:web7 DID Document MAY reference a did:web service endpoint for resource discovery.¶
did:peer – pairwise did:peer identifiers MAY be used in conjunction with did7:web7 to reduce correlation in privacy-sensitive contexts (see Section 14.2).¶
Implementations MAY register additional DID method compositions in a publicly accessible DID Method Registry.¶
The following design decisions underpin the did7:web7 specification.¶
Deterministic mapping: Aligning with the broader principle that DID methods SHOULD be deterministic where possible, the syntactic transformation from URN to URN requires no external state and produces stable, reproducible identifiers.¶
Use of alsoKnownAs: The alsoKnownAs property from [W3C.DID-CORE] is used rather than a custom extension to ensure semantic preservation while remaining fully conformant with the core specification.¶
Stateless baseline: Requiring only syntactic processing for baseline resolution maximises portability and eliminates single points of failure that would arise from mandatory registry dependencies.¶
Acknowledged trade-offs: The method does not include a built-in trust layer or lifecycle operations (Update/Deactivate) at the baseline level. These capabilities are intentionally delegated to optional layers (Modes 2 and 3, and the controller model of Section 9) so that implementations may adopt only the complexity they require.¶
The deterministic mapping from URN to URN means that any party who observes a did7:web7 identifier can immediately recover the underlying URN. Where the URN encodes personally identifiable information (e.g., a personal UUID or a registry identifier linked to an individual), this creates a direct correlation vector.¶
Additionally, because the transformation is deterministic and publicly known, two parties who independently resolve the same URN will arrive at the same URN, enabling linkage across otherwise unrelated contexts.¶
Implementers handling sensitive or personal identifiers SHOULD consider the following mitigations:¶
Pairwise DIDs: Use pairwise did:peer identifiers in contexts where individual interaction tracking is a concern, rather than exposing the did7:web7 identifier directly.¶
Avoid sensitive URNs: Refrain from forming did7:web7 identifiers from URNs that encode sensitive personal data in public or semi-public contexts.¶
Selective disclosure: Where verification is required, use Verifiable Presentations with selective disclosure rather than directly sharing the did7:web7 identifier.¶
This document does not address the privacy properties of the underlying URN namespaces; implementers MUST consult the privacy considerations of the applicable namespace registration before using that namespace in a did7:web7 context.¶
The baseline did7:web7 method (Mode 1) provides no inherent proof-of-control. Any party can construct a syntactically valid did7:web7 DID from any well-formed URN without demonstrating authority over the named resource. This is an intentional consequence of the zero-infrastructure design; however, it means that a did7:web7 DID alone cannot be used to assert ownership or authority.¶
In Mode 3 (Discovery-Enhanced), resolvers that accept DID Documents from external services are susceptible to spoofed or tampered service endpoints. A malicious service could return a crafted DID Document containing false verification methods or service endpoints.¶
To mitigate the limitations identified above, implementations SHOULD apply the following measures:¶
Signed metadata: Require that DID Documents obtained via Mode 3 discovery carry a valid cryptographic proof (e.g., a JSON-LD Data Integrity Proof) before accepting them as authoritative.¶
Verifiable Credentials for binding: Use Verifiable Credentials [W3C.VC-DATA-MODEL] issued by a trusted authority to bind the URN to a controller identity, rather than relying solely on the DID Document structure.¶
TLS for discovery endpoints: All HTTPS endpoints used in Mode 3 discovery MUST be protected with TLS 1.2 or higher [RFC8446] and SHOULD use certificate transparency.¶
Input validation: Resolvers MUST validate the embedded URN against the ABNF grammar of [RFC8141] before performing any resolution activity.¶
[RFC2119] Bradner, S., “Key words for use in RFCs to Indicate Requirement Levels”, BCP 14, RFC 2119, DOI 10.17487/RFC2119, March 1997, <https://www.rfc-editor.org/rfc/rfc2119>. [RFC3986] Berners-Lee, T., Fielding, R., and L. Masinter, “Uniform Resource Identifier (URI): Generic Syntax”, STD 66, RFC 3986, DOI 10.17487/RFC3986, January 2005, <https://www.rfc-editor.org/rfc/rfc3986>. [RFC5234] Crocker, D. and P. Overell, “Augmented BNF for Syntax Specifications: ABNF”, STD 68, RFC 5234, DOI 10.17487/RFC5234, January 2008, <https://www.rfc-editor.org/rfc/rfc5234>. [RFC8141] Saint-Andre, P. and J. Klensin, “Uniform Resource Names (URNs)”, RFC 8141, DOI 10.17487/RFC8141, April 2017, <https://www.rfc-editor.org/rfc/rfc8141>. [RFC8174] Leiba, B., “Ambiguity of Uppercase vs Lowercase in RFC 2119 Key Words”, BCP 14, RFC 8174, DOI 10.17487/RFC8174, May 2017, <https://www.rfc-editor.org/rfc/rfc8174>. [RFC8446] Rescorla, E., “The Transport Layer Security (TLS) Protocol Version 1.3”, RFC 8446, DOI 10.17487/RFC8446, August 2018, <https://www.rfc-editor.org/rfc/rfc8446>. [W3C.DID-CORE] Sporny, M., Guy, A., Sabadello, M., and D. Reed, “Decentralized Identifiers (DIDs) v1.0”, W3C Recommendation, July 2022, <https://www.w3.org/TR/did-core/>. [W3C.DID-RESOLUTION] Sabadello, M., “Decentralized Identifier Resolution (DID Resolution) v0.3”, W3C Working Group Note , 2023, <https://w3c-ccg.github.io/did-resolution/>.
The author thanks the members of the W3C Decentralized Identifier Working Group and the broader DID community for their foundational work on the DID Core specification, and the IETF URN community for their long-standing stewardship of URN namespaces.¶
Full name:Decentralized Resource Name (DRN) DID Method Status: Draft Recommendation SDO: Web 7.0 Foundation Editor: Michael Herman, Chief Digital Officer, Web 7.0 Foundation Related standards: DID Core, URN (RFC 8141 via )
1. Abstract
The did:drn method defines a deterministic mapping from Uniform Resource Names (URNs) into a DID-compatible identifier format called a Decentralized Resource Name (DRN).
This method:
Preserves URN semantics
Enables DID resolution without mandatory centralized infrastructure
Provides optional cryptographic and service-layer extensibility
2. Conformance
The key words MUST, SHOULD, and MAY are to be interpreted as described in RFC 2119.
3. Method Name
did:drn
4. Terminology
URN: A persistent, location-independent identifier defined by RFC 8141
DRN: A URN expressed within the did:drn method
Controller: An entity asserting control over a DID Document
Web 7.0 is an identity-native execution environment where:
Everything is addressable by DID
Agents (not apps) are the primary unit
Trust is built into the runtime
Identity as the OS namespace
DIDs used as:
identifiers
routing
authority boundaries
This is a real shift from URLs (location-based) → identity-based addressing
“Library OS” concept
OS is not monolithic
It’s a collection of interoperable libraries
Similar to Unix philosophy
But applied to identity + agents
Polyglot host framing
Strong analogy to PowerShell and JVM / CLR
This is technically grounded—not hand-wavy
Integration into a single OS-level abstraction
Decentralized identity (DIDs)
Agent-based systems
Polyglot runtimes
Trust frameworks
These are orthogonal stacks:
OpenAI → intelligence-first OS
Web 7.0 → trust/identity-first OS
The real future: if both succeed: AI agents running on DID-native infrastructure
Best-case scenario (speculative but coherent)
Every entity has a DID
Agents act on behalf of those identities
Communication via DIDComm
Trust via credentials
Execution via polyglot host
Result: A self-sovereign, agent-driven internet runtime
Bottom line:
Coherent architectural vision
Technically grounded components
Clear differentiation (identity-first OS)
Final insight (most important)
“What if identity—not compute nor UI nor AI—was the foundation of the new Internet?”
That is a radical inversion of:
Windows (device-first)
iOS (app-first)
OpenAI (AI-first)
Web 7.0 (identity-first)
Transcript
7:197 minutes, 19 secondsAlrighty. Welcome everyone to the uh first DIDCom user group meeting of the month of March 2026. 7:307 minutes, 30 secondsUh I I see familiar faces unless someone wants to reintroduce themselves at this time 7:417 minutes, 41 secondsbut uh hearing nothing. Uh today our topic of agenda is uniform didcom message types presented by Michael here. 7:527 minutes, 52 secondsSo uh with that being said, I’ll let you take it away. Thanks Colton. 8:008 minutesUm so I’ve been doing this DID stuff for quite a long time. I’m a named contributor to the original DIDS spec 8:088 minutes, 8 secondsand um and a bit of a rebel. Um, and so I picked kind of an innocuous name here. 8:178 minutes, 17 secondsI did call message types. I’m not going to run this full screen because when I make when I use PowerPoint, I use it to make diagrams and they’re often bigger 8:268 minutes, 26 secondsthan the slide. So, I’m going to keep it at this 60% resolution. 8:318 minutes, 31 secondsAnd um, what we’re doing here is at web 7.0 Z is we’re creating an actual did 8:408 minutes, 40 secondsexclusive operating system and there’s a special kind of operating system called a 8:478 minutes, 47 secondslibrary operating system. So I’m going to take a few minutes just to explain that just to give it context as to why 8:558 minutes, 55 secondsum I think these uniform didcom message types are important. 9:009 minutesSo it’s going to be a little bit tutorialish uh to start with. So when you think of a did operate uh excuse me 9:089 minutes, 8 secondsa library operating system down here at the bottom these are the traditional host or 9:189 minutes, 18 secondsoperating system services you would expect. And the li a library operating system is something that sits on top of 9:259 minutes, 25 secondsthat and it provides a system of libraries that provide a ecosystem or 9:329 minutes, 32 secondsframework specific set of interfaces and you never reach down and use the operating system interfaces. 9:429 minutes, 42 secondsSo you’re always um calling in from the application layer here through the 9:519 minutes, 51 secondsdeveloper abstraction into these bunch of libraries which in turn calls through the host 9:589 minutes, 58 secondsabstraction layer down here. This was pioneered in the 1990s. 10:0510 minutes, 5 secondsThere’s a lot of current research going on for example to make Windows a library-based operating system. The 10:1410 minutes, 14 secondsidea is to make the kernel of the operating system as small as possible and for the library operating system to 10:2010 minutes, 20 secondsrun in user space. It’s um it’s a way of doing a sort of virtualization 10:2810 minutes, 28 secondsum like uh well virtualization without u having to 10:3610 minutes, 36 secondscreate an entire virtual machine. So if we go down another step, the next thing you need in your library operating system is a bunch of libraries. 10:4610 minutes, 46 secondsuh and these are you know intermediate to medium level libraries that you know support whatever the application framework is that you’re trying to do 10:5610 minutes, 56 secondsand so if we think of some of them I’m still staying generic here uh but you know we need some sort of identity and 11:0311 minutes, 3 secondsmessaging protocols some sort of long-term or persistent memory um some sort of fast cache for having um uh 11:1311 minutes, 13 secondsready fast access to different objects and that sort of thing. Um maybe an agent framework. And then we need a call 11:2311 minutes, 23 secondsinterface, a way to call through the host abstraction layer to get it some of 11:2811 minutes, 28 secondsthese resources down here. So um 11:3611 minutes, 36 secondswe talk about this number two here being the the north interface. 11:4111 minutes, 41 secondsUm, and that’s a term that was started in 1990. 11:4611 minutes, 46 secondsOh, I forget the name of the operating system project right now. But the idea is there’s a north face that applications talk to. There’s a south 11:5511 minutes, 55 secondsface that the library operating system calls through. And then you optionally can have east and west interfaces 12:0312 minutes, 3 secondsfor things that don’t fit in. and and I’ll I’ll show you some things that we’re going to put over here on the left 12:1012 minutes, 10 secondshand side in a moment. Um any questions on this kind of concept of a library operating system so far? 12:2112 minutes, 21 secondsNot really a question. Uh just kind of a comparison. Uh this kind of reminds me of Docker and what Google’s idea was 12:2912 minutes, 29 secondswith uh core OS where you essentially had a it was a Linux distribution that 12:3612 minutes, 36 secondsran Docker. You couldn’t SSH into the box really. Uh I mean you could technically but not practically. So you 12:4512 minutes, 45 secondsset up the box that runs Docker containers and whenever you want to uh like spin up applications or have them talk to each 12:5312 minutes, 53 secondsother. I mean it’s you know just a docker box but it has that lightweight feel of it and you’re not running like 13:0013 minutesas you mentioned uh the kernel’s small it’s shared between all of these containers so you’re not running the 13:0713 minutes, 7 secondskernel for each and every single uh one of your applications in the containers. 13:1313 minutes, 13 secondsYeah. No, that’s a valid comment. Um there’s probably six different dimensions to this discussion which 13:2113 minutes, 21 secondswould be a whole different talk. So it’s similar from a containerization perspective. Where this would differ from Docker is that Docker apps, 13:3213 minutes, 32 secondsapps that run in Docker still typically call to the host operating system directly. And you could say, well, yeah, 13:3713 minutes, 37 secondsbut my application has an intermediate layer. This is about formalizing the intermediate application layer um as a as an operating system interface, 13:4913 minutes, 49 secondsa higher level operating system interface. But uh the comparison with Docker and um a number of other 13:5613 minutes, 56 secondsvirtualization uh strategies is the same. Um I I’d introduced kind of the west interface here and I I’ve I’ve put the actual creation of messages, 14:0814 minutes, 8 secondsmessage payloads, relationships, trust libraries on the side. And the other thing I’ve introduced is on the right 14:1514 minutes, 15 secondshand side, you know, solution builders build the purple boxes. 14:2114 minutes, 21 secondsuh host um builders or operating system builders build the items below the south uh 14:3014 minutes, 30 secondsinterface and then in the case of um the web 7.0 14:3714 minutes, 37 secondsuh did libos it’s the web 7.0 foundation you know governance council that kind of 14:4414 minutes, 44 secondsowns and match manages this stuff. So as I was looking through this, I said, 14:4814 minutes, 48 seconds”Okay, these are these are core these are really really deep core things that I have to have and these things I have to have as well, but these tend to be 14:5714 minutes, 57 secondsthings that are built on the the core items that are in the red box.” And um there’s still some latitude for that to 15:0415 minutes, 4 secondschange, but um if you just go with that as far as this explanation is concerned. 15:1015 minutes, 10 secondsSo then what I did is we’re getting serious now about this did exclusive decentralized library operating system 15:1915 minutes, 19 secondsand when I say did exclusive I should change this here um did exclusive I mean everything is a did so for example I 15:2815 minutes, 28 secondsshould I have some statistics later on if you look in the didcom spec there’s 15:3415 minutes, 34 seconds109 118 references to http/didcom.org 15:4115 minutes, 41 secondswork for mostly for retrieving schema and stuff. So in the case of web 7.0 15:4815 minutes, 48 secondseverything is a did and so that has some implications and that led to this subject of 15:5615 minutes, 56 secondsnot just what is a uniform way of of defining message types but what’s a uniform 16:0216 minutes, 2 secondsway of using DIDs for everything we see in the operating system. So, of course, 16:1016 minutes, 10 secondsfrom the identity perspective, we have identifiers, documents, and the DID registry. From a messaging perspective, 16:1716 minutes, 17 secondswe’ve got DIDCOM messaging with DICCOM messages. Long-term memory, we actually use DICOM messages as our serialization 16:2816 minutes, 28 secondsum for long-term memory, long-term persistence, and I’ll explain a little bit more about that. Uh the memory 16:3516 minutes, 35 secondscache, the fast cache is also didcom messagebased. Uh the switchboard is what 16:4216 minutes, 42 secondslistens to the inbound interface and this is what um 16:4916 minutes, 49 secondslooks at the incoming messages, looks at the incoming uh message type, looks at the thread ID, and it decides um which 16:5816 minutes, 58 secondsone of these modules up at the top that message should be routed to automatically. 17:0417 minutes, 4 secondsSo it’s a it’s a generalpurpose library operating system for running any DICCOM application 17:1317 minutes, 13 secondsany DICCOM application that conforms to the to the to the lib operating system. 17:2017 minutes, 20 secondsAnd then just to kind of emphasize this idea about being did and didcomentric 17:2617 minutes, 26 secondswhen we’re calling functions or methods within the operating system we’re actually using didcom messages for that. 17:3417 minutes, 34 secondsAnd you might say, “Oh, Michael God, that’s way overboard. That’s expensive. 17:3817 minutes, 38 secondsYou’re telling me that I’ve got to um uh verify and and and decrypt these messages.” 17:4617 minutes, 46 secondsMy answer is yes. And the reason why is because we’re using didcom messages everywhere for persistence, for the fast 17:5517 minutes, 55 secondscache, for routing, uh for for passing parameters around. 18:0118 minutes, 1 secondIf that’s the slowest, worst part of the system, that’s the one that people are going to focus on and make faster. I’m 18:0818 minutes, 8 secondsnot worried about that problem not being solved. Um, I’ll stop for questions in a minute. 18:1618 minutes, 16 secondsOn the left side here in the gray, you know, we’ve got libraries for creating actual DICCOM messages. Verifiable 18:2318 minutes, 23 secondscredentials is the default format uh for payloads, although you could use any JSON format, but we we lean heavily 18:3218 minutes, 32 secondstowards verifiable credentials. Uh trust relationships, we’ve got a concept of verifiable trust circles, which is based 18:4118 minutes, 41 secondson multi-proof verifiable credentials. And then I stuck the trust libraries down here. These are 18:4918 minutes, 49 secondsjust our standard libraries for doing hashing, signing, verification, 18:5318 minutes, 53 secondsencryption, and decryption. You could say they could be down below the hardware or below below the host abstraction error layer. Um, 19:0519 minutes, 5 secondswhat I’ve chosen to do is put them here because they’re under the governance council in terms of these particular 19:1319 minutes, 13 secondslibraries. And I probably should have like a 7.5 over here, which is actually the operating system um encryption 19:2119 minutes, 21 secondslibrary. So, uh that’s that’s a change I’ll Oops. That’s a change I’ll uh I’ll make later. I’m just going to copy and paste this over here to remind me. 19:3219 minutes, 32 secondsSo, um so this is deadl OS. This is a 19:3919 minutes, 39 secondsplatform, a global platform for running 19:4619 minutes, 46 secondsarbitrarily complex networks of uh didcom agents. 19:5419 minutes, 54 secondsNow, that’s a bit of a mouthful. Anybody have any questions about that? 20:0320 minutes, 3 secondsOh, come on, guys. 20:0520 minutes, 5 secondsOne question that I do have uh I’ll speak up here. Uh one question that I do have in relation to how everything’s 20:1420 minutes, 14 secondsbeing handled in with didcom messages here. Yeah. 20:1820 minutes, 18 secondsUh is part of the idea that if an applica like so we’re talking about didcom messages 20:2620 minutes, 26 secondsbeing used for interprocess communication on the same box potentially. 20:3320 minutes, 33 secondsUm no glo globally as well as in the same blocks. 20:3720 minutes, 37 secondsUh I was going to get to that. So if uh for example I wrote an application instead of writing did comps you know 20:4520 minutes, 45 secondsstuff in within my own application could I forward that off through like the quote unquote IPC messaging portion here 20:5420 minutes, 54 secondsand have that end up going to a different box on the internet? Yes. Absolutely. 21:0321 minutes, 3 secondsSo, let me go into this one. I put it in there. Wasn’t sure if I was going to use it, but this is what a a web 7.0 21:1121 minutes, 11 seconds7.0 agent looks like. Um, 21:1721 minutes, 17 secondsso we have didcom messaging here. I just called it version 7.3 cuz there’s a a series of these. And you see that it 21:2421 minutes, 24 secondsruns on top of REST over didTP. Um you may remember in one of our conversations I brought up uh this concept of zero 21:3321 minutes, 33 secondstier which is a wide area virtual network uh software solution. 21:4021 minutes, 40 secondsWhat’s cool about that is I dug into it and it’s an open- source solution is internally 21:4721 minutes, 47 secondsit uses 64-bit device IDs and each device ID has its own its own 21:5521 minutes, 55 secondspublic private key pair for uh encrypting the packets that are sent over the virtual network. 22:0622 minutes, 6 secondsAnd it’s somewhat incidental that the API for this virtual network is IPbased or socket based. 22:1722 minutes, 17 secondsSo we’ve done quite a bit of investigation and we believe that we can take the zero tier 22:2622 minutes, 26 secondsguts and actually put DIDs on top of it instead of IPs. Remember, 22:3422 minutes, 34 secondsa virtual IP network is IPs on top of IPs. IPs, virtual IPs on top of physical IPs. 22:4322 minutes, 43 secondsSo, what we’re going to do is use didcom addresses on top of 22:5022 minutes, 50 secondsthe physical IPs that that um that you get from your from your router. 22:5822 minutes, 58 secondsSo, we’re actually talking about a did version a a dead version 23:0523 minutes, 5 secondsof the internet global communications network 23:1323 minutes, 13 secondsand being able to send DICCom over that network. 23:1723 minutes, 17 secondsSo that’s the networking side, the purple and the yellow boxes. Here we’ve been looking at different ways of 23:2523 minutes, 25 secondscreating a programmable didcom agent, 23:3123 minutes, 31 secondssome sort of scriptable agent and I happened to stumble across PowerShell 23:4123 minutes, 41 secondsa few years ago and par PowerShell almost in and of itself you might be familiar with it. It’s used for doing 23:4823 minutes, 48 secondsadministration activities on Windows systems, Linux systems, and uh iOS systems. It’s crossplatform. It’s open- 23:5623 minutes, 56 secondssource for Microsoft. 23:5923 minutes, 59 secondsAnd it it is literally like an operating system. You can create what are called runspace pools, which 24:0724 minutes, 7 secondsare run spaces, and each one of these is an execution area. You can import modules 24:1424 minutes, 14 secondsinto a runspace. And a module is a set of commands, commandletits. 24:1924 minutes, 19 secondsAnd so this could be a runspace that implements a purchasing process. Or this could be 24:2624 minutes, 26 secondsone that uh implements a systems administration process or this one could be a request for quotation 24:3624 minutes, 36 secondsum type of process. These can be actual workflows that can be either scripted or programs. 24:4624 minutes, 46 secondsAnd so this is the heart of our digital agents. And so if you think if I use a maybe you guys some of you guys have maybe have a little more of a a Unix 24:5424 minutes, 54 secondsbackground. If you think of like the bash or the corn shell or whatever and you put acom 25:0325 minutes, 3 secondsendpoint on top of it, that’s what I’m doing here. I’m taking a very rich execution environment, multi-platform, 25:1025 minutes, 10 secondsmultios, 25:1225 minutes, 12 secondsand we’re putting a didcom thing on the front of it. 25:1925 minutes, 19 secondsAnd the last box here is the blue box. 25:2225 minutes, 22 secondsThese are called lobes because initially we were modeling the trusted digital assistant as a brain. 25:3125 minutes, 31 secondsAnd a brain has lobes and each lobe is responsible for different cognitive functions. So I went into chat GPT and I 25:4025 minutes, 40 secondssaid using L OB come up with a phrase that is useful in the context of web 7.0 25:4825 minutes, 48 secondsZ and it came up with the idea of loadable object brain extensions. 25:5425 minutes, 54 secondsAnd so these are implemented as PowerShell modules that can be dynamically loaded 26:0126 minutes, 1 secondwhenever the a command is issued u that refers to or that’s that’s implemented by one of those modules. 26:1126 minutes, 11 secondsSo, we’ve got a just an incredible environment for building digital agents. Any questions on that? 26:2126 minutes, 21 secondsSo, when you were talking about the whole interidnet, 26:2626 minutes, 26 secondsis that I’m just trying to wrap my head around this portion here. Is that similar to like kind of replacing the TCP IP stack, 26:3826 minutes, 38 secondsbut you’re actually just sitting on top of it? As far as like applications are concerned, it’s in a sense replacing it’s replacing it’s replacing raw sockets with a DID interface. Yes. 26:4926 minutes, 49 secondsOkay. 26:5026 minutes, 50 secondsOr you can think of it as a parallel to DID or to raw sockets that understands DITS. 27:0027 minutesOkay, that’s pretty cool actually. Thank you. 27:0327 minutes, 3 secondsYeah. And uh I’m actually you guys didn’t know um Daniel uh 27:1127 minutes, 11 secondsBarding Daniel and I are talking about this on Friday. 27:1627 minutes, 16 secondsBut that would be very cool because a lot of the stuff that the group has been working on with relay agents and all 27:2327 minutes, 23 secondsthat kind of stuff that belongs down here in the network. So just the same way that TCPIP 27:3227 minutes, 32 secondsrelays and buffers and provides reliable communications for packets, 27:3827 minutes, 38 secondsthe interdidnet is going to do the same thing for didcom messages. So we no longer have to have relays and and and stuff that we build at the user level. 27:5527 minutes, 55 secondsUm, okay. So, this is just context so far. 28:0028 minutesI’m going to show one more slide. It’s just kind of context. So, 28:0728 minutes, 7 secondswhen I I I I kind of sketched out a few sample applications. So, what would email look like? What would the protocol 28:1628 minutes, 16 secondslook like? We’re going to store it in long-term memory. What would the did for the long-term memory look like? There’d 28:2228 minutes, 22 secondsbe collections of of messages in long-term memory. What would how would we didify those? Um 28:3128 minutes, 31 secondshere’s a purchasing application. Inbound purchase orders, outbound purchase orders, that kind of stuff. What what would if we wanted to didify, what would 28:4028 minutes, 40 secondsthat look like? um presents uh notifications, calendaring, 28:4628 minutes, 46 secondsum this is where I really kind of started and and just iterate, iterate, iterate 28:5328 minutes, 53 secondstrying to figure out how do I bring the DIDS spec together? How do I bring the DIDCOM spec together? Um how do I bring 29:0129 minutes, 1 secondkind of some of the PowerShell attributes together, the naming conventions, etc. The one app that I haven’t talked about, this is the switchboard app. 29:1229 minutes, 12 secondsAnd this is the one that listens to the inbound interface. 29:1929 minutes, 19 secondsSo it takes all the messages and it stores them in this messages collection. 29:2829 minutes, 28 secondsAnd as well as any outbound messages. And I know it’s all kind of cryptic, but where it says MSG, that’s a real message. 29:3929 minutes, 39 secondsThat’s a a copy of a message. And down here, these are stubs. You notice all 29:4629 minutes, 46 secondsthe apps use stubs. One of the cool things about PowerShell is you can chain 29:5429 minutes, 54 secondscommandlets together just visually or syntactically the same as you do in a Unix shell. in a Unix shell. Um, 30:0630 minutes, 6 secondswhat’s written to stood out and what’s read on stood in for all intents and purposes is always uh, you know, text. 30:1530 minutes, 15 secondsWhat’s really cool about PowerShell is when you’ve got um an object that you’re passing from one 30:2430 minutes, 24 secondscommandlet to the next, it’s all running within this single runace. And so what 30:3130 minutes, 31 secondsPowerShell does is persist one copy of that object and all it does is pass the handle from the first commandlet to the 30:3930 minutes, 39 secondssecond commandlet to the third commandlet to the fourth commandlet. So the efficiency there’s no copying or 30:4630 minutes, 46 secondsserialization or des serialization of objects from one commandlet to another. 30:5230 minutes, 52 secondsSo we use that in in our storage model by storing one instance of the messages 30:5930 minutes, 59 secondson a particular client on a particular trust the digital assistant and every other app then is 31:0631 minutes, 6 secondsjust referring to the handle or the stub for the message that’s stored over here. 31:1231 minutes, 12 secondsSo the switchboard is what listens to the inbound interface. It’s also we we talk about an outbound interface although that’s a 31:2131 minutes, 21 secondslittle bit abstract but if you if if these thing if the message if the email app puts something in the outbox 31:3031 minutes, 30 secondsit creates the message over here it sends the message to the switchboard puts it in the outbox and then 31:3831 minutes, 38 secondsthe switchboard looks at sending that out. So all sending and receiving from inbound and outbound uh interfaces is 31:4631 minutes, 46 secondsdone by the switchboard and it’s essentially serving as the archive uh etc. 31:5431 minutes, 54 secondsAny any questions there? I know this is this is a ton of stuff that’s new. 32:0132 minutes, 1 secondAll I’m trying to do with this slide is highlight the naming challenges we have from a DID perspective. 32:1032 minutes, 10 secondsOkay. What’s this one? I’m not going to go into that one. So, if we go into the DIDCOM spec, 32:1832 minutes, 18 secondsif it’s supposed to be a DID communication messaging spec, you know, 32:2532 minutes, 25 secondswhy is HTTP mentioned 118 times? 32:2932 minutes, 29 secondsWhy is this mentioned 32 times? 32:3632 minutes, 36 secondsSo just a little poke in the ribs is ds are under slashmisrepresented in the spec. And I’m going to show you a couple examples. 32:4532 minutes, 45 secondsSo here when we’re defining the um in the spec section 9.1 this didcom spec 32:5332 minutes, 53 secondsthe protocol identifier URI. There’s one lowly did example here and it doesn’t even conform to the grammar. 33:0333 minutes, 3 secondsUh, it’s got a semicolon in it, which isn’t in the grammar, 33:0833 minutes, 8 secondsand it’s got a message type or a message name on the end. And 33:1633 minutes, 16 secondsmessage names or message types aren’t even part of this part of the spec. So, that line is completely wrong. 33:2433 minutes, 24 secondsThe semicolon actually is. It’s uh under delimiters. I will show you it isn’t. 33:3333 minutes, 33 secondsSo if we go to the did specification, 33:3633 minutes, 36 secondsthe semicolon colon character can be used according to the rules technically, but future versions of spec may use it for something else. So it’s recommended against using it. 33:5133 minutes, 51 secondsSorry that I made you step into that. 33:5433 minutes, 54 secondsI I was looking specifically at that slide which said like the limb and had semicolon in that list. So yeah. Yeah. No, I know. And this is 34:0334 minutes, 3 secondswhere it gets tricky and until you really start building stuff, it’s really hard. Okay. So, here this then so this 34:1134 minutes, 11 secondsslide is the protocol identifier. The first part of it, um, 34:1834 minutes, 18 secondsthe really nice thing I like about what the what the didcom spec does is, you know, the didcom.org part that we put in there. 34:2734 minutes, 27 secondsI call that the authority. 34:3134 minutes, 31 secondsAnd then this is like the did method subject to this authority. 34:4034 minutes, 40 secondsIt’s a bit of a mind jump, but I’m going to show you how I make use of that later on. And this completely perverts the did 34:4734 minutes, 47 secondsdid specification, but so be it. Um, so here now we’re adding the message type name after. 34:5534 minutes, 55 secondsAnd here we’re using the semicolon. We we’re pass that argument. Um, 35:0235 minutes, 2 secondsbut I don’t think this, 35:0535 minutes, 5 secondslike if I try to compare one of these HTTPS ones to the did example, like they just they don’t they don’t match up and 35:1335 minutes, 13 secondslike why is this a URL? Why does this look like a URL? 35:1835 minutes, 18 secondsAnd um anyway, 35:2235 minutes, 22 secondsit we can we can nitpick, but basically I’m saying that and these are the only two examples in the entire spec. And 35:3135 minutes, 31 secondsthen of course there’s hundreds of places where HTTP is used to get at the um you know the schema, the context 35:4035 minutes, 40 secondsthing. Well, you know, if we’re building DIDCOM, why aren’t those uh DID URLs to get at the schema? 35:4835 minutes, 48 secondsUm, so here we start to get into some of the solution. So part of this thinking 35:5535 minutes, 55 secondsoriginated like in the W3C side of things and in the um webv 36:0436 minutes, 4 secondsum did sell discussions, people are realizing that these did methods are more the same than they are different or 36:1236 minutes, 12 secondsat least they can be componentized or potentially factored. And so I said, why don’t I’ve got a whole another thing 36:1936 minutes, 19 secondsthat I’ve done where I said, why you could actually factor these as interfaces. You could have a a base class for a DID method and it could be, 36:3036 minutes, 30 secondsyou know, derived from a reposi like a blockchainbased repository registry or a 36:3636 minutes, 36 secondsweb-based registry or um whatever. And so I actually prototyped it in C sharp 36:4536 minutes, 45 secondsand then said, well, if I turn these all into interfaces, then we can actually build dynamically build D did methods on 36:5236 minutes, 52 secondsthe fly. A developer when they need a DID method can just say, I want a new DID method and it’s going to inherit 36:5936 minutes, 59 secondsthese interfaces and it’ll automatically be one that does uh event history. It’ll automatically, you know, go to a 37:0737 minutes, 7 secondsblockchain. If later on I want to change it to be web- based, I can do a web- 37:1137 minutes, 11 secondsbased um interface. And and that going down that path led me to this idea that we could create an 37:2037 minutes, 20 secondsinterface description language, a formal language used to describe um did methods 37:2937 minutes, 29 secondsand I go on and on about that. And then here’s some examples. 37:3537 minutes, 35 secondsSo this is really getting to the title of the talk and so first of all I needed dids for things. So this is actually my 37:4337 minutes, 43 secondsproposal for a uniform didcom message type. 37:5637 minutes, 56 secondsSo the idea is this first thing is the the authority. This is the didcom.org. 38:0238 minutes, 2 secondsAnd then I needed a group I wanted to have a grouping mechanism because there’s another spec called the uh APQC 38:1038 minutes, 10 secondsuh process classification framework which organizes things into processes that are made up of capabilities that 38:1938 minutes, 19 secondsare made up of tasks. And so I wanted to start with a process name and a version like a sim version 38:2838 minutes, 28 secondsslash a capability slash or underscore version followed by 38:3438 minutes, 34 secondsa task name and I’ve been iterating on this quite a bit 38:4338 minutes, 43 secondsand so here’s an example. So if web 7.0 is the authority onboarding is the 38:4938 minutes, 49 secondsprocess. So where this perverts the DID specification is onboarding is really 38:5838 minutes, 58 secondslike a DID method but it’s a DID method that’s subordinate to this authority. 39:0339 minutes, 3 secondsAnd if we would have done this way back when, this would have solved so many problems with the DID registry and and all the hokey arguments we’ve got about 39:1339 minutes, 13 secondsabout DID methods cuz people could just declare themselves an authority and then do whatever they want. So, the other 39:2039 minutes, 20 secondsthing is I had to figure out uh a nice pattern for versions, something that would be easily parsed. And so, I call 39:2839 minutes, 28 secondsthese actually sim dash versions. It’s the same as the sim ver that’s in the spec, but using dashes instead of dots. 39:3839 minutes, 38 secondsAnd so, here’s a fully worked example. 39:4139 minutes, 41 secondsWe have an onboarding process that has an enrollment capability that has a verify email task name. 39:5239 minutes, 52 secondsUm, you can do it with or without the version. If you do it without the version, you just get whatever the most 39:5839 minutes, 58 secondsrecent version is um of the process and the most recent version of the enrollment capability. So that’s going 40:0740 minutes, 7 secondsright down to the task level which is what did call message types are. 40:1640 minutes, 16 secondsUm if you want to just address the capability because you also want to be able to occasionally ask okay ask a capability what tasks do you perform? 40:2840 minutes, 28 secondsThis is coming back to the uh interface description language which which tasks do you support? And similarly I might 40:3540 minutes, 35 secondswant to go to a process level and say okay uh purchasing process what um what capabilities do you support? 40:4440 minutes, 44 secondsAnd this becomes a very rich kind of a didcom scenario where I can start asking 40:5140 minutes, 51 secondslike a digital agent you know what process do you have what capabilities do you have for given capability? What task does it support? 41:0141 minutes, 1 secondSo this goes back, Colton, I think, to your earlier question about can this this could run tiny little bits of an 41:0841 minutes, 8 secondsapplication on on a million different digital agents. 41:1941 minutes, 19 secondsAny thoughts? 41:2241 minutes, 22 secondsSo is this like kind of a discover method that you are trying to implement in this language? Right. 41:3041 minutes, 30 secondsYou’re going to have to speak up a little bit, Benj Ben. Yeah. Can you hear me now? Yeah. 41:3641 minutes, 36 secondsSo, are you trying to implement something like discover method that is incom discover, right? So, 41:4541 minutes, 45 secondsyeah. So, I I’m aware that um didcom has discovery built into it. Actually, the 41:5341 minutes, 53 secondsnext slide I I go into that. So rather than so I’ve been trying to be faithful 41:5941 minutes, 59 secondsas possible in a weak way. Um but I think you’ll see like rather than just 42:0642 minutes, 6 secondshaving query and disclose I’m also following a pattern um 42:1342 minutes, 13 secondssuggested by PowerShell where you always have verb and a noun. So I’ve got query capabilities. 42:2242 minutes, 22 secondsOh maybe this isn’t quite right. query capabilities and this should be 42:2742 minutes, 27 secondsuh query task actually but wouldn’t it make sense to like map 42:3542 minutes, 35 secondsthe things that we already have to this language instead of like creating new stuff 42:4242 minutes, 42 secondsum I’m I I apologize can you say that again so wouldn’t it make sense to like map 42:4942 minutes, 49 secondsthe already capabilities that are there incom to this language instead of creating new keywords for it. 42:5742 minutes, 57 secondsUm, that’s a fair comment. Um, 43:0343 minutes, 3 secondsthe the answer is because we’re building a green field operating system because we’re building from the bottom up and 43:1243 minutes, 12 secondsthere’s so many little places where we’ve chosen, not just chosen to differ, but we’ve felt it important to 43:2143 minutes, 21 secondsdiffer. Um, I haven’t been religious about, 43:2643 minutes, 26 secondsyou know, fake backward compatibility to me. Like also, 43:3543 minutes, 35 secondsyeah, it kind of makes sense. But like we also have like certain things going on. So the biggest thing that we have 43:4243 minutes, 42 secondsissue with is the strings. So you know like if you are transporting certain things on like OS level messages like 43:4943 minutes, 49 secondsthese are too big like we personally use binary uh notation. So did is just you 43:5643 minutes, 56 secondsknow like X01 and like so we reduce the whole thing into just like a small messages and whenever we are sending 44:0544 minutes, 5 secondsover Bluetooth or like certain things that you would seen like the DICOM protocols we have uh okay this is kind of like the same kind of 44:1444 minutes, 14 secondsthings that like we found as well because when we are sign uh sending acom message over Bluetooth or something it’s 44:2144 minutes, 21 secondsquite huge just sending high up didcom is like you know it’s a huge message so we had to reduce it and compress it and 44:2944 minutes, 29 secondslike do certain things on top of it. So I I like the idea of like having a 44:3644 minutes, 36 secondslanguage that can like do all that didcom things and it is like small and like minute and everybody can use that 44:4444 minutes, 44 secondsbut uh I don’t know like we how we can all be compatible with each other if we are going to use like different naming schemes like that’s kind of an issue. 44:5444 minutes, 54 secondsOkay. So you you’ve got two different topics there. 44:5844 minutes, 58 secondsI understand your and appreciate your comment on the length. Uh there’s just 45:0545 minutes, 5 secondsoff the top of my m head two ways that we could look at addressing that from a web 7point perspective. One would be to 45:1345 minutes, 13 secondscreate an alias so that you could declare if this is something you whatever like use go back 45:2145 minutes, 21 secondsto the send email example. If this is um if this is a type you use a lot, 45:3145 minutes, 31 secondsyou could send a um an an alias 45:4045 minutes, 40 secondsan alias type uh didcom message to your agent saying whenever I give you this short message, expand it to this. 45:5345 minutes, 53 secondsYeah, this is like exactly like what we are doing currently. So, do you have any code for this? Like have you implemented any OS level code or anything on it? 46:0346 minutes, 3 secondsWe have we have working code that implements um 46:1046 minutes, 10 secondsthat well it implements everything except for the PowerShell part and 46:1946 minutes, 19 secondsum just a minute. And then the second thing I was going to say about what you mentioned was um so aliases and then and 46:2946 minutes, 29 secondsthis is just right off the top of my head. You could have the concept of a like a current working directory or a 46:3746 minutes, 37 secondscurrent working process. You could say um I’m going to talk to you but it’s always going to be in the context of 46:4546 minutes, 45 secondsthis process. So, from now on, I’m only going to talk to you about capabilities and tasks. It’s kind of like doing a CD 46:5446 minutes, 54 secondsto a process or even doing a CD down to a capability and then from that point on you just execute tasks. 47:0547 minutes, 5 secondsOkay. It’s quite interesting to me and I’ll be interested if you like open source any code to like look at it. 47:1247 minutes, 12 secondsOh, it Well, it is open source. It’s just kind of disorganized right now. Okay. 47:1747 minutes, 17 secondsUm Okay, just we’re get Oh, we’re doing pretty well on time. I’ve only got a one more SL formal slide left. So, here this 47:2647 minutes, 26 secondsis one. These are all kind of peace meal that I put together, but you know, if you start with the didspec and what it says and you start with the DIDCOM, I 47:3447 minutes, 34 secondswas at using 1.1 and then you start with PowerShell. 47:3947 minutes, 39 secondsUm, PowerShell has um run times, they have runtime pools. Oh, this is just the 47:4747 minutes, 47 secondsoverall runtime. They have runspace pools and run spaces. Um, and then they have modules and then they have the 47:5547 minutes, 55 secondsverb.object naming for tasks. So like verify email would be a verb object. And so you can run these together and say, 48:0348 minutes, 3 secondsyou know, did web 7 onboarding enrollment, you know, verify email. And I mentioned the APQC process classification framework. Well, 48:1448 minutes, 14 secondsit nicely breaks down processes, 48:1648 minutes, 16 secondsprocess, activities, and tasks. And it all works well. actually did is the did 48:2448 minutes, 24 secondsspec is the biggest culprit because they’re using the method here as the second component of the did thing and I 48:3248 minutes, 32 secondsreally want to use the second component as an authority right or I want to use the first one as 48:3948 minutes, 39 secondsauthority not as a not as a a did method I want the did method to really be the 48:4648 minutes, 46 secondssecond component of the did method It does that make sense to anybody? 48:5748 minutes, 57 secondsYeah, it makes sense. But you know like it uh so it makes sense but uh what I’m 49:0449 minutes, 4 secondslike uh thinking is like how we can have it like you know like how can we contribute to it or you how you can 49:1349 minutes, 13 secondscontribute to our stuff like if not like agreeing on on like the ba basis of those things I I understand 49:2149 minutes, 21 secondsthat you know like whatever you have did did web 7 did a like these are the basic methods even if you create schema Mark 49:2849 minutes, 28 secondsred def and all those things like when you do it like it’s there but having it on the didcom side like uh it’s kind of 49:3849 minutes, 38 secondslike a little bit hard for me to like you know digest and accept the the coaching. 49:4449 minutes, 44 secondsYeah. And that I I recognize that and that’s just kind of the purest approach 49:5249 minutes, 52 secondswe felt we had to take to build the best possible thing we could build. Right. 50:0050 minutesAnd sure and and and and I’m not being physicious here, but 50:0750 minutes, 7 secondsbackward compatibility or uh interoperability is not a big consideration right now. We just want to make it work. 50:1850 minutes, 18 secondsOkay. 50:2250 minutes, 22 secondsUh and that’s about all I have to have to say. So I I should have highlighted at the beginning that this is is this 50:3050 minutes, 30 secondsisn’t a proposal. This is just a conversation and kind of an update on what we’re working on. But I think there’s a lot of 50:3850 minutes, 38 secondsnovelty in it. And when you start looking at an application end to end and 50:4650 minutes, 46 secondseverywhere if then if you’re going to be pure did ccentric or did exclusive 50:5350 minutes, 53 secondsum it uh it it has implications and and the current specs aren’t aren’t uh did 51:0051 minutescentric and I I’ll leave it like that. What I 51:0851 minutes, 8 secondswill do is I’m going to put these together somehow and I will 51:1551 minutes, 15 secondscreate a YouTube video and I’ll I’ll make the link available to everybody so that you can go over this again. 51:2251 minutes, 22 secondsSure. So like from what I understand like didcom things are did agnostic. So any did can implement them. So I have 51:3051 minutes, 30 secondslike a personal did that like did Ajna that we work with. So we are not doing like you know like whatever we are 51:3851 minutes, 38 secondsbuilding that you know like it should just be on our stuff. We are contributing it back to the Dcom community like whatever protocols we are 51:4651 minutes, 46 secondsbuilding and those like just being did agnostic like any did can implement that you know like if 51:5451 minutes, 54 secondsyou want those calls to be implemented on web 7 you can implement it on there. 51:5951 minutes, 59 secondsYeah. Well m maybe I didn’t high I didn’t really highlight it but if we look at this example here so this is 52:0652 minutes, 6 secondsjust this is the process um it’s just a grouping but the process name 52:1452 minutes, 14 secondsconcatenated with the um capability name that’s how we’re naming the module that’s how we’re 52:2452 minutes, 24 secondsnaming the the PowerShell module and so when When this message comes in, the first 52:3252 minutes, 32 secondsthing that the trusted digital assistant, the first thing the DIDCOM agent is going to look at is given 52:4052 minutes, 40 secondsthis process and this capability, have I already preloaded that module. If I’ve 52:4752 minutes, 47 secondsalready imported that module, then I just have to execute, you know, verify email. If I haven’t already loaded that, 52:5652 minutes, 56 secondsI need to go out and possibly download it and possibly import it. So there is a little there is a significant bias in 53:0553 minutes, 5 secondsthis naming convention towards um you know towards what’s happening in PowerShell towards you know this column here. 53:1853 minutes, 18 secondsIt I want everything from left to right being sort of one to one. 53:2453 minutes, 24 secondsand not to have to have lookup tables and translation tables and those sorts of things. 53:3153 minutes, 31 secondsYeah, it’s quite interesting like let’s see like how you know like uh things go and like we would surely be 53:4053 minutes, 40 secondsinterested at you know like looking at it quite interesting and I have faced like these issues myself. So like it 53:4853 minutes, 48 secondswould be interesting to see like some implementations on like how to solve, 53:5353 minutes, 53 secondsright? Can you can you send me um can you send me a link to to your project? 54:0154 minutes, 1 secondUh sure. Like we haven’t like open sourced everything but I can share the com protocols that we currently have. 54:0854 minutes, 8 secondsYeah. Well, just a link or two so I can understand uh and maybe there are some 54:1654 minutes, 16 secondsuh cuz yeah, we’ve we’ve obviously been very um introspective in terms of of just looking at web 7. 54:2654 minutes, 26 secondsYeah, sure. I’ll find you on Discord and I’ll uh drop Okay. Okay. I appreciate everybody’s 54:3454 minutes, 34 secondstime and Colton, I appreciate the opportunity and I hope Yeah. I hope this is a valuable use of people’s time. 54:4254 minutes, 42 secondsYeah, I I thought there were some uh very interesting like like uh as I mentioned earlier the 54:5054 minutes, 50 secondsidea of didcom sitting on top of TCPIP where Oh, you like that, do you? 54:5754 minutes, 57 secondsYeah. Well, be because it turns DIDs into more first class citizens. Yeah. So if you ever want to, you know, 55:0455 minutes, 4 secondscommunicate with another user or a computer or whatnot, you just do that via their DID and send the DID message. 55:1255 minutes, 12 secondsUh like, you know, you want to go to you want to pull up a web page or whatnot, you just plop in the did and 55:1955 minutes, 19 secondsthen it ends up resolving to uh the right server and communicates over didcom to retrieve the web page for you. Uh I I think 55:2855 minutes, 28 secondswe end up with we end up with our own completely independent network for running didcom applications. 55:3755 minutes, 37 secondsSo I I I think that is like just really really cool u way to think about things. Okay. Um Okay. 55:4655 minutes, 46 secondsWell, I’ve um I’ve I I’ll confess I use chat GPT a lot to help me. It’s almost like a coworker. 55:5555 minutes, 55 secondsUm, often I will save conversations on my blog on hyperonomy.com. 56:0256 minutes, 2 secondsI’ll see if I can find one related to that, Colton, and I’ll put it there so people can read up on uh what it might take. 56:1156 minutes, 11 secondsOkay. 56:1356 minutes, 13 secondsUm, chat GPT figured it would take about six man months to make it work 56:2056 minutes, 20 secondson top of the existing open-source repository. 56:2556 minutes, 25 secondsYeah, but existing open-source stuff like if you see acapy and creds, you can’t really Yeah. So, yeah, we’re talking about the zero tier project. 56:3556 minutes, 35 secondsOkay. So a zero tier is a project, a product and a project and a repo. 56:4256 minutes, 42 secondsAnd the thing that’s not part of the repo are like the administration tools for signing people up and stuff. But the 56:4956 minutes, 49 secondsthe whole networking piece that exposes virtual IP addresses on Windows, on 56:5656 minutes, 56 secondsAndroid, on Apple. Uh that’s all that’s all part of the open source and and that’s the piece we would behead and and 57:0657 minutes, 6 secondsput DIDs on. So are you using some kind of like decentralized uh so like Kadia 57:1457 minutes, 14 secondsor DST or something like that to store the DIDs on the table or what? Uh down here. Yeah. 57:2157 minutes, 21 secondsUm because we’re storing them actually as didcom messages. They’re trusted and secure to start with and we’re using uh light DB. 57:3157 minutes, 31 secondsNo, I mean like if if I have a PC and you have a PC, I have your So if I need to resolve that D and get to you, how do I resolve that D? 57:4257 minutes, 42 secondsWell, you’d have to you’d have to have um one of us would have to build a lobe. 57:5157 minutes, 51 secondsone of us would have to build um an extension that would essentially provide object access based on an incoming didcom message. 58:0458 minutes, 4 secondsOkay. So, uh we would have to have like a fet we’d have to have like a fetch object and a store object uh message protocol. 58:1458 minutes, 14 secondsOkay. So like basically we also are doing like similar thing but we are basically building a whole blockchain 58:2058 minutes, 20 secondsmesh network on top of Dcom and so we are trying to you know connect the 58:2858 minutes, 28 secondswhole uh world as well throughcom. So peerto-peer everybody can connect and message and do all those things. So it’s 58:3558 minutes, 35 secondsquite interesting like I’m just like repeating that it’s it’s quite interesting. I I’ll take a look at it. 58:4158 minutes, 41 secondsYeah. So uh just a a parting note. So everything is written in C sharp. 58:4958 minutes, 49 secondsPowerShell for Microsoft is written in C. 58:5458 minutes, 54 secondsUh the the the latb 59:0359 minutes, 3 secondsis I think it’s written in C but it certainly has a net interface. And let me find the picture here before I die. 59:1259 minutes, 12 secondsUm, 59:1559 minutes, 15 secondswell, you’re finding that all of all of these modules uh here, all of these are written in C. We’re 100% 59:2259 minutes, 22 secondsCuh overnet. 59:2959 minutes, 29 secondsThe whole the whole library OS is written in C and all the supporting stuff is written in C. And all of these blue things are C. 59:4259 minutes, 42 secondsAnd then we’re using JWTs to as really the format for our our JSON messages or not our JSON message, our DICOM messages. We’re we try to be 99% 59:5359 minutes, 53 secondscompatible, but again, just to be fair, 59:5659 minutes, 56 secondsinteroperability is kind of low on the list. So there are some little nuances where we wouldn’t be compatible on the wire. 1:00:071 hour, 7 secondsSo, I I do realize that we are uh getting close to the hour and I know that uh Steve, you joined partway 1:00:141 hour, 14 secondsthrough. Uh I was just curious if you had any thoughts based on uh what’s been said here uh that you’ve seen uh since 1:00:221 hour, 22 secondsyou’re on the or since you are part of the working group. 1:00:271 hour, 27 secondsOh, thanks. Yeah. Um had a conflict earlier in the hour. 1:00:321 hour, 32 secondsUm, no, it’s interesting. I noticed on the one slide the deadcom messaging here was up to version 7 something or other. 1:00:441 hour, 44 secondsThe this that’s because this diagram is part of a road map and I’ve just labeled the different versions 7.1, 7.2, 7.3. 1:00:571 hour, 57 secondsIt’s arbitrary. So different standard than what we’re building here. 1:01:051 hour, 1 minute, 5 secondsWell, this one this this is the one that would run over didt TP directly on the interdep. 1:01:131 hour, 1 minute, 13 secondsUh I believe it uh as mentioned it’s an arbitrary number but based off of web 7.0. 1:01:201 hour, 1 minute, 20 secondsYeah. Yeah. It’s just a placeholder but it so it’s based on the spec but it’s 1:01:271 hour, 1 minute, 27 secondsderived it’s an classic embrace and extend uh philosophy. 1:01:361 hour, 1 minute, 36 secondsSo um just to understand is is it the same current didcom spec or 1:01:441 hour, 1 minute, 44 secondsis it different? And I guess I ask because number would lead me to think it’s different. 1:01:501 hour, 1 minute, 50 secondsYeah it’s not. It’s not It’s not compatible. It’s not wire compatible. Okay. 1:01:541 hour, 1 minute, 54 secondsIt’s inspired by the spec, but not compatible. 1:02:001 hour, 2 minutesOkay. That that could be confusing. 1:02:061 hour, 2 minutes, 6 secondsIf it’s if it’s not the same spec, um I’d probably pick a different name or, 1:02:151 hour, 2 minutes, 15 secondsyou know, some somehow reference it being modified. Yeah. Well, we call it didcom++. 1:02:251 hour, 2 minutes, 25 secondsI don’t know what that is. Sorry. Well, no, it’s just a different name. 1:02:331 hour, 2 minutes, 33 secondsYeah. 1:02:381 hour, 2 minutes, 38 secondsOkay. Well, um, if you want to follow up, Steve, I can present this to you personally if you want or, uh, you could wait for the recording. 1:02:491 hour, 2 minutes, 49 secondsYeah, it’s recorded so I can check that out. Thank you for presenting. 1:02:541 hour, 2 minutes, 54 secondsWell, I really appreciate everybody’s time. It’s uh kind of the first big public uh uh entree. So, uh we’ll see what happens. 1:03:051 hour, 3 minutes, 5 secondsYeah, I I’m excited because uh you mentioned that this is more of a conversation starter, right, in a sense. 1:03:131 hour, 3 minutes, 13 secondsAnd so it’s it’s neat to see what others are thinking about and how didcom could be used and that’s pretty exciting. So 1:03:201 hour, 3 minutes, 20 secondsthank you very much for offering to present and presenting today and uh thank you. Thank you too. 1:03:291 hour, 3 minutes, 29 secondsOkay. And feel free to reach out. U I I do this basically 110% of my time. So if anybody’s interested in reaching out, 1:03:371 hour, 3 minutes, 37 secondsplease do. 1:03:411 hour, 3 minutes, 41 secondsAll right. Thank you everyone for uh wait Venet did you have a comment real quick before we close? 1:03:471 hour, 3 minutes, 47 secondsYeah just like a quick comment. I updated some of the mesh networkcom protocol that is there and I created a 1:03:541 hour, 3 minutes, 54 secondsnew PR for uh ledgers protocol and I wanted to say like the web RTC stuff is like stuck there for like November. So I 1:04:031 hour, 4 minutes, 3 secondsthink like we should merge it like the implementations are there now. Um and I have like contributed those uh like 1:04:111 hour, 4 minutes, 11 secondsimplementation into uh open wallet foundation as well like with our new project. So I think like we should merge 1:04:181 hour, 4 minutes, 18 secondsthe web RTC stuff and probably in the next meeting I I can talk like something about the new PR that I made. 1:04:251 hour, 4 minutes, 25 secondsOkay. I will take a look at those uh after this meeting and uh see about getting that merged. 1:04:331 hour, 4 minutes, 33 secondsCool. Thanks. 1:04:351 hour, 4 minutes, 35 secondsAll right. Thank you everyone for uh coming today and uh great presentation. 1:04:421 hour, 4 minutes, 42 secondsI’ll see you all next week.
This document defines the “did7” URI scheme, an authority-scoped decentralized identifier format. DID7 introduces an optional authority component and a two-stage resolution process, while remaining fully compatible with the W3C Decentralized Identifiers (DIDs) v1.0 specification (DID Core).
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet-Drafts is at https://datatracker.ietf.org/drafts/current/.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as “work in progress.”
This Internet-Draft will expire on 18 September 2026.
Copyright (c) 2026 IETF Trust and the persons identified as the document authors. All rights reserved.
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (https://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document.▲
The W3C Decentralized Identifiers (DIDs) specification [DID-CORE] defines method-based identifiers without a global namespace. DID7 introduces an optional authority layer, enabling namespace partitioning, governance domains, and scalable resolution infrastructure while remaining compatible with DID Core.
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in BCP 14 [RFC2119] [RFC8174] when, and only when, they appear in all capitals, as shown here.
The following ABNF [RFC5234] defines the DID7 URI syntax. The unreserved and pct-encoded rules are imported from [RFC3986] Section 2.3. The ALPHA, DIGIT, and HEXDIG rules are imported from [RFC5234] Appendix B.
Note: The colon (“:”) character is intentionally excluded from method-id to avoid ambiguity with the method delimiter. Colons within method-specific identifiers MUST be percent-encoded.
As a convenience, resolvers MAY perform DNS-based discovery of the resolver endpoint for an authority using a DNS TXT record of the form:
_did7.<authority-domain> IN TXT \ "resolver=did7://example.com/resolvers:authority"
DNS responses used for authority resolution SHOULD be validated using DNSSEC.
Any verifiable data registry technology MAY be used for discovery of the resolver endpoint for an authority. Different authorities MAY have different registries.
Implementations MUST NOT assume equivalence between “did” and “did7” identifiers, even when the method and method-specific identifier components are identical.
The following security considerations apply to implementations of this specification:
Authorities introduce a trust surface. The integrity of resolver endpoints MUST be verified before use. Implementations SHOULD use certificate-based authentication when contacting resolver endpoints.
DNS responses used for authority resolution SHOULD be validated using DNSSEC to prevent DNS spoofing attacks.
Resolver endpoints SHOULD use HTTPS (TLS) to protect data in transit. Endpoints using plain HTTP MUST NOT be used in production deployments.
Cryptographic verification of DID Documents MUST follow the procedures defined in [DID-CORE].
Implementations MUST NOT accept resolver endpoints that redirect to third-party domains not associated with the declared authority.
This document requests registration of the URI scheme “did7” in the “Uniform Resource Identifier (URI) Schemes” registry maintained by IANA, in accordance with [RFC7595].
URI scheme name: did7
Status: Provisional
URI scheme syntax: See Section 3.2 of this document.
URI scheme semantics: The “did7” URI scheme identifies authority-scoped decentralized identifiers. Resolution proceeds in two stages: authority discovery via DNS, followed by method-specific DID resolution. The resulting resource is a DID Document as defined in [DID-CORE].
Encoding considerations: The “did7” URI scheme uses only ASCII characters as defined by the ABNF in Section 3.2.
Non-ASCII characters in the method-specific identifier component MUST be percent-encoded per [RFC3986].
Applications/protocols that use this URI scheme: Applications implementing decentralized identity, verifiable credentials, or self-sovereign identity frameworks that require authority-scoped namespace governance.
Interoperability considerations:DID7 URIs are not directly interchangeable with W3C DID URIs. See Section 6 for the one-way mapping from W3C DID to DID7.
Security considerations:See Section 7 of this document.
[RFC2119]Bradner, S., “Key words for use in RFCs to Indicate Requirement Levels”, BCP 14, RFC 2119, DOI 10.17487/RFC2119, March 1997, <https://www.rfc-editor.org/rfc/rfc2119>.
[RFC3986]Berners-Lee, T., Fielding, R., and L. Masinter, “Uniform Resource Identifier (URI): Generic Syntax”, STD 66, RFC 3986, DOI 10.17487/RFC3986, January 2005, <https://www.rfc-editor.org/rfc/rfc3986>.
[RFC5234]Crocker, D., Ed. and P. Overell, “Augmented BNF for Syntax Specifications: ABNF”, STD 68, RFC 5234, DOI 10.17487/RFC5234, January 2008, <https://www.rfc-editor.org/rfc/rfc5234>.
[RFC7595]Thaler, D., Ed., Hansen, T., and T. Hardie, “Guidelines and Registration Procedures for URI Schemes”, BCP 35, RFC 7595, DOI 10.17487/RFC7595, June 2015, <https://www.rfc-editor.org/rfc/rfc7595>.
[RFC8174]Leiba, B., “Ambiguity of Uppercase vs Lowercase in RFC 2119 Key Words”, BCP 14, RFC 8174, DOI 10.17487/RFC8174, May 2017, <https://www.rfc-editor.org/rfc/rfc8174>.
Version: 0.1 Status: Draft Editor: Michael Herman, Chief Digital Officer, Web 7.0 Foundation Intended Audience: Standards bodies, implementers, protocol designers SDO: Web 7.0 Foundation Also Known As: did://ietf/docs:draft-herman-did7-identifier-01
Abstract
This specification defines the did7 URI scheme, an authority-scoped decentralized identifier format that extends the conceptual model of Decentralized Identifiers (DIDs). DID7 introduces an explicit authority layer above DID methods and defines a two-stage resolution process. DID7 is designed to be compatible with the DID Core data model while enabling forward-compatible namespace routing and governance flexibility.
1. Introduction
The Decentralized Identifier (DID) architecture defined by DID Core provides a method-based identifier system without a global authority namespace.
This specification introduces:
A new URI scheme: did7
An authority-scoped identifier structure
A two-stage resolution model
A forward-compatible namespace design
DID7 is intended to:
Enable explicit namespace partitioning
Support multiple governance domains
Provide a top-level resolution entry point
2. Conformance
The key words MUST, SHOULD, and MAY are to be interpreted as described in RFC 2119.
This specification:
Normatively references DID Core for DID Document structure and semantics
Does not modify DID Documents
Overrides identifier syntax and resolution entry point only
Version: 0.1 Status: W3C-style Working Draft / Informational Editor: Michael Herman (Chief Digital Officer, Web 7.0 Foundation) Intended Audience: Standards bodies, implementers, protocol designers SDO: Web 7.0 Foundation Also Known As: did://ietf/docs:draft-herman-did7-identifier-01
Abstract
This document defines the did7 URI scheme, an authority-scoped DID format. DID7 adds:
An optional authority component
Two-stage resolution (authority → method)
Forward-compatible namespace expansion
The specification is fully compatible with the W3C DID Core data model [DID-CORE].
NOTE: This version mirrors W3C specification formatting conventions, including:
Clear separation of normative vs non-normative content
ABNF blocks with examples
In-line references to DID Core
Sectioning like W3C DID Core Recommendation
1 Introduction
The DID Core specification [DID-CORE] defines method-based identifiers without a global namespace. DID7 introduces an optional authority layer, allowing namespace partitioning and federation while remaining compatible with DID Core.
DID7 goals:
Namespace partitioning
Governance flexibility
Forward-compatible routing
2 Terminology
The key words MUST, MUST NOT, SHOULD, SHOULD NOT, MAY are interpreted as described in [RFC2119][RFC8174].
DID Document: As defined in [DID-CORE].
Authority: A namespace identifier controlling resolution behavior.