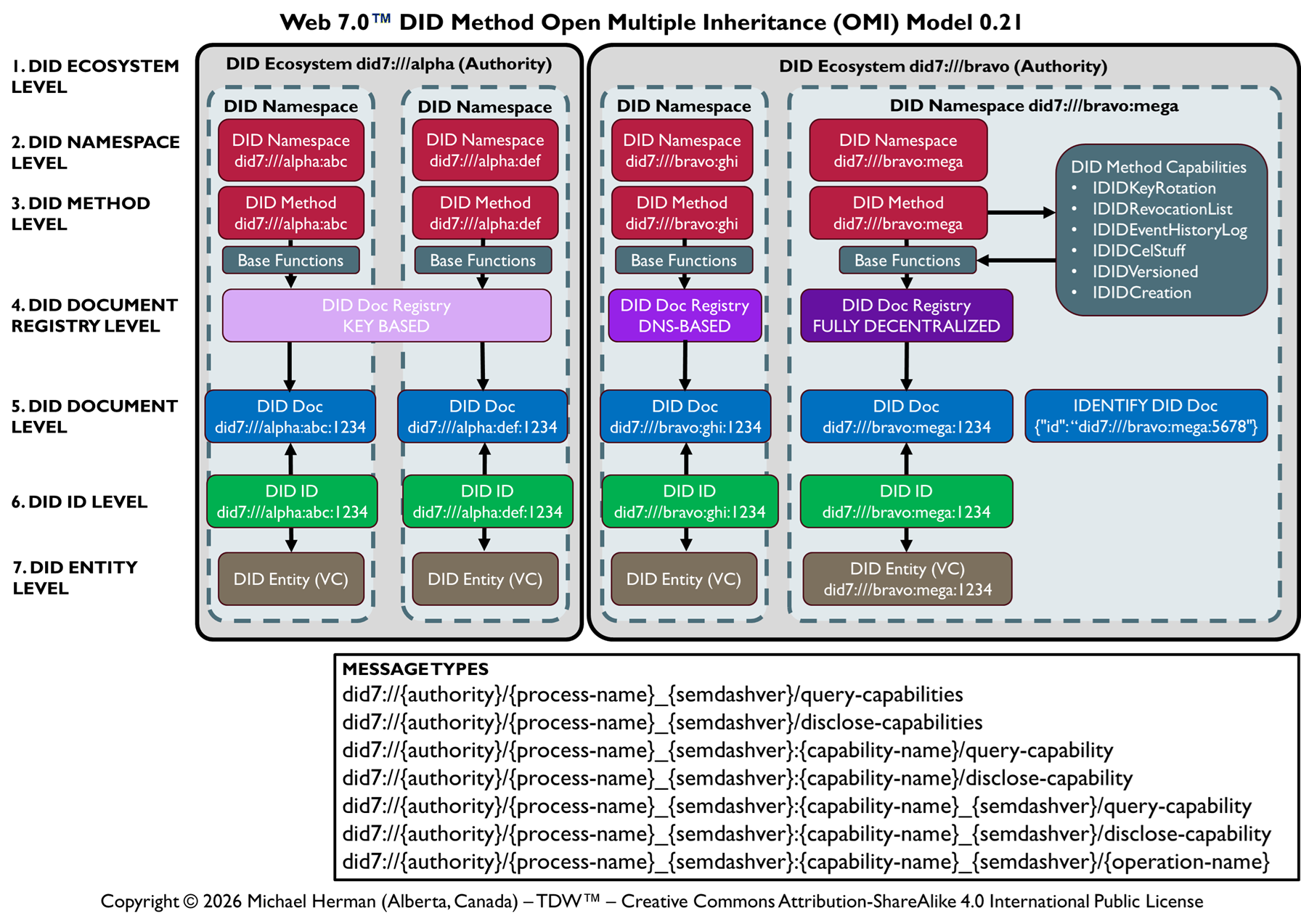
The goal of this model is enable a developer, on the spot, while coding his/her app, to model and immediately put to use any DID Ecosystem, DID Namespace, and/or DID Method they need (and as many as they want to) …and make the task as easy as defining a new database table or an object class for a new data store.
The Model
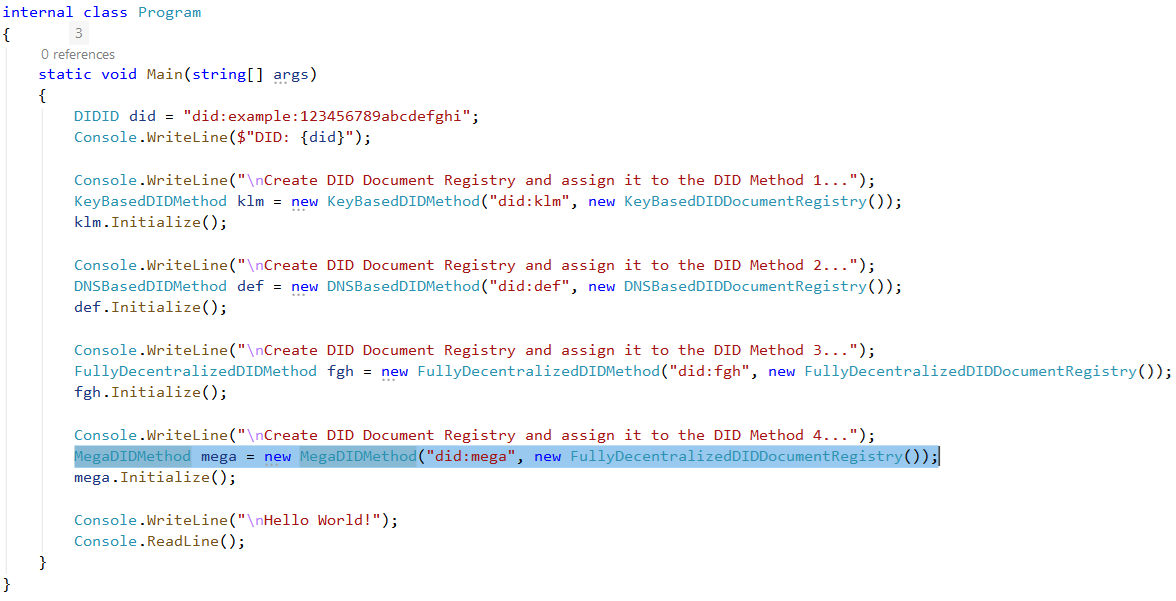
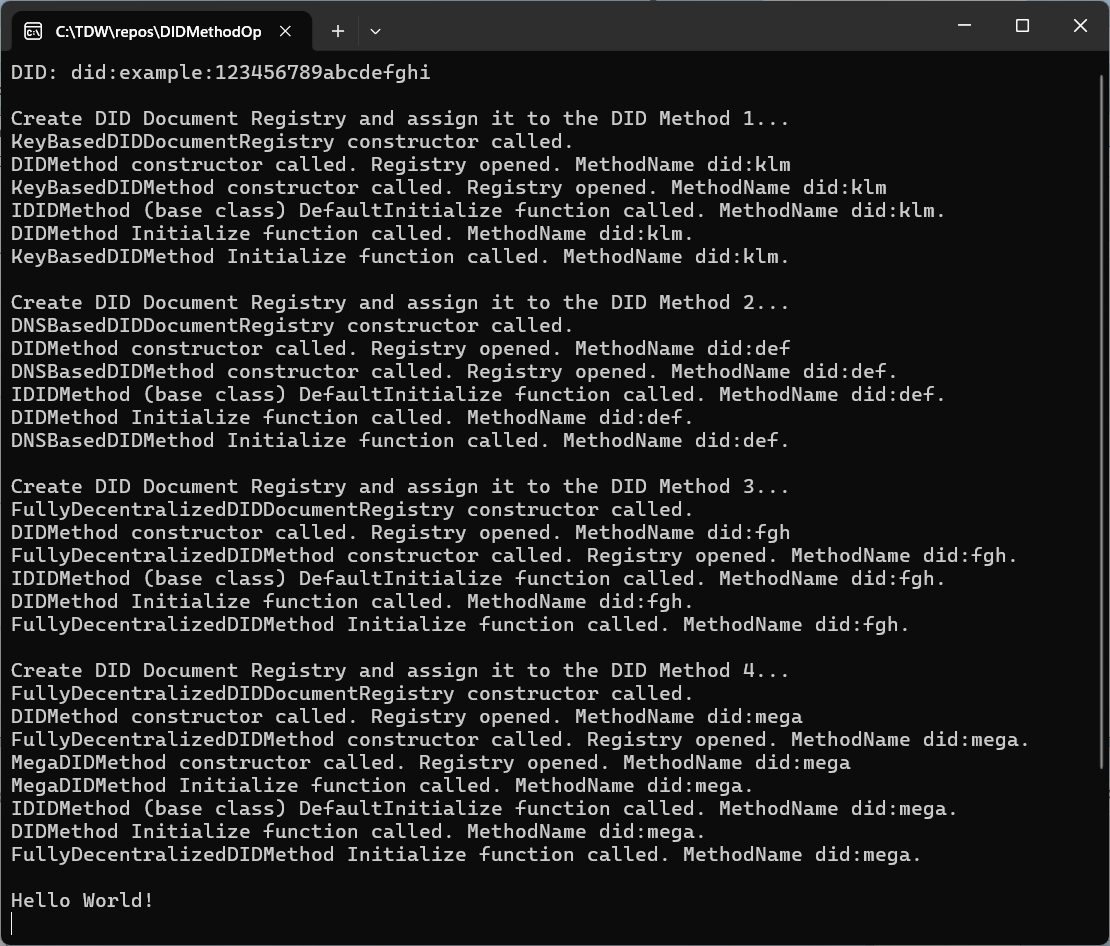
Pseudocode Example
Scroll down (or use Find) to locate the declaration and first use of MegaMethod()…
using System;
using System.Collections.Generic;
using DIDID = System.String;
using DIDMETHODNAME = System.String;
namespace DIDMethodOpenInheritanceModel1
{
public class DIDDocument
{
DIDID? id { get; set; }
//
// Other properties of a DID Document would go here, such as public keys, authentication methods, service endpoints, etc.
The idea for the original article, Why is Knowledge like Steam?, came to me while attending the 2002 McMaster World Congress on Intellectual Capital hosted by Dr. Nick Bontis and McMaster University.
Ten Reasons why Data is like Steam
10. Like steam, data will collect somewhere.
9. Even though data can collect anywhere at any time, this doesn’t imply it is easy to create, find, or use – so too with steam.
8. Small amounts of steam do not appear significant until they are collected and put to work – so too it is with data. Small amounts of data do not appear significant until they connect, collect, and their energies combine.
7. There is no danger of there being too much steam. Excess steam can be vented or sold. So too it is with data.
6. The greater the number of sources of steam you have around you, the more likely you are to have it when you need it. So too it is with data.
5. The commercial value of steam is highest when it is new and concentrated – so too it is with data.
4. Steam can be used to create more steam – so too it is with data.
3. Steam can be condensed into a purer, distilled form – so too it is with data (data distillation).
2. There are many fuels and methods that can be used to create steam and put it to work – not all of which will be economic at a given point in time – so too it is with data.
1. If you don’t create it, capture it, channel it, and put it to work, its value is marginalized. So too it is with data.
Michael Herman, Decentralized Systems Architect, Web 7.0™. February 2026.
This is a structured article written in a precise, verification-first style.
The relationship between a DID method specification and a DID Document can be understood cleanly through the lens of abstract data type (ADT) theory. This framing is not metaphorical fluff—it is structurally accurate and technically clarifying.
We proceed in two layers:
A DID method specification is analogous to an ADT definition for the DID method itself.
A DID Document is analogous to an additional ADT for working with the entities defined by that method.
I. What is an Abstract Data Type?
An abstract data type defines:
A domain (a set of valid values)
A set of operations
Behavioral constraints and invariants
Without specifying internal implementation details
Classic examples:
Stack (push, pop, peek)
Map (put, get, delete)
Set (add, remove, contains)
An ADT defines what is valid and what operations mean, not how they are implemented.
II. A DID Method Specification as an ADT
A DID method (e.g., did:example, did:key, did:web) is formally defined by a method specification under the W3C DID Core framework.
1. The Domain
A DID method defines:
The syntactic structure of valid identifiers (e.g., did:<method>:<method-specific-id>)
The rules for resolving identifiers
The lifecycle semantics (creation, update, deactivation)
In ADT terms:
The DID method defines the valid elements of its identifier space.
Formally:
Domain = { all valid DIDs conforming to method rules }
2. The Operations
Every DID method defines:
Create
Resolve
Update (if supported)
Deactivate (if supported)
These are behavioral operations over the identifier space.
Crucially:
The specification defines what those operations mean, not how they are implemented internally (blockchain, database, DNS, etc.).
That is exactly what an ADT does.
3. Invariants
Each DID method defines constraints such as:
Uniqueness guarantees
Immutability or mutability properties
Resolution determinism
Authorization rules
These are behavioral invariants of the abstract structure.
Conclusion (Layer 1)
A DID method specification functions as:
An abstract data type definition whose elements are DIDs of that method, and whose operations are create/resolve/update/deactivate under defined invariants.
It defines:
The type
The allowable operations
The semantic guarantees
While abstracting away implementation details
That is textbook ADT structure.
III. The DID Document as a Second-Order ADT
Now we move to the second layer.
When you resolve a DID, you obtain a DID Document (as defined by the DID Core specification).
A DID Document is not just a JSON file.
It is a structured object with defined semantics.
1. The Collection Defined by the DID Method
If a DID method defines a collection:
M = { all valid DIDs under method X }
Then each DID in that collection corresponds to a resolvable subject.
The DID Document is the canonical representation of that subject.
So:
DID method → defines the identifier collection
DID Document → defines the abstract representation of each member
2. DID Document as an ADT
A DID Document defines:
Domain
A structured object containing:
id
verificationMethod entries
authentication methods
key agreement methods
service endpoints
This defines the state space of a subject.
Operations
Although not expressed as classical functions, the DID Document supports defined semantic operations:
Verification of signatures
Authentication checks
Capability delegation
Service endpoint discovery
These operations are defined by the structure of the document.
Again:
The document defines the interface and semantics—not the underlying cryptographic implementation.
That is ADT structure.
3. Abstraction Boundary
The DID Document abstracts:
How keys are stored
How cryptographic proofs are generated
Where services are hosted
It defines only:
What verification methods exist
What services are associated
What relationships are authorized
This is interface-level abstraction.
Exactly what ADTs formalize.
IV. This Is Not Just Another Analogy
This mapping is not poetic. It is structurally precise.
ADT Concept
DID Method
DID Document
Type Definition
Method spec
Document schema
Domain
Valid DIDs
Valid subject state
Operations
Create/Resolve/Update
Verify/Auth/Discover
Invariants
Uniqueness, lifecycle
Key integrity, structural validity
Implementation Hidden
Ledger/DNS/etc.
Key storage, crypto engines
The layering is clean:
DID method = ADT over identifiers.
DID Document = ADT over resolvable subjects.
Applications operate only through these abstractions.
V. Structural Insight
There is an important second-order property here.
A DID method defines:
A type whose elements resolve to another type.
In type-theoretic terms:
Method : Identifier → Document
So the DID method ADT produces instances of another ADT (the DID Document).
This is analogous to:
A class factory
A parameterized type constructor
A category whose morphisms produce structured objects
Thus:
The DID method defines the collection.
The DID Document defines the algebra over elements of that collection.
VI. Why This Matters
Viewing DID architecture through ADTs clarifies:
Why methods must be formally specified.
Why interoperability depends on behavioral invariants.
Why documents must obey strict structural semantics.
Why implementation diversity does not break correctness.
It also reveals a design strength:
The DID architecture is layered abstraction done properly.
VII. Conclusion
A DID method specification functions as an abstract data type that defines the valid identifier space, lifecycle operations, and invariants for a class of decentralized identifiers.
A DID Document functions as a second abstract data type that defines the structured state, verification semantics, and service interface of each subject within that identifier class.
Together, they form a two-level abstraction system:
Level 1: Identifier type algebra
Level 2: Subject capability algebra
This perspective removes confusion and replaces it with formal clarity.
This short paper introduces a quantitative model for reliable software quality defined as Q = (CPR)^2 × G, where CPR represents structural engineering strength and G represents governance strength. The model formalizes the nonlinear contribution of engineering integrity and the linear moderating role of governance. By separating structural properties from governance mechanisms and applying geometric aggregation to prevent compensatory inflation, the framework (in the form of a rubric) establishes a mathematically grounded theory of structural primacy in reliable software systems. The foundation of the RSG model is an orthogonal spanning set of reliable software principles.
Intended Audience
The intended audience for this paper is a broad range of professionals interested in furthering their understanding of reliable software quality as it related to software apps, agents, and services. This includes software architects, application developers, and user experience (UX) specialists, as well as people involved in software endeavors related to artificial intelligence; including:
Master Masons (Vertically Integrated)
Operating System Masons
Framework Masons
Services Masons
Data Masons (including the developement of LLMs)
Network Effects Masons
Protocol Masons
User-face App Masons
Tools Masons
Codegen Tools Masons
Verification Masons
Apprentice Masons
“The #crafting of #software is no different from the #craft of making a fine #Irish#single#malt. Like great whiskey, great software needs to be tended to multiple times: poteen, malting, milling, mashing, fermentation, multiple distillations, maturation, tasting, release to bottling, and bottling. These steps may be #human, #mechanical, or #digital.” Michael Herman, February 28, 2026.
“Learn to work constructively with your #digital#counterparts … as #partners – not as tools or challenges to be conquered. You maybe be a Master Mason. Your digitial counterparts may start out as Apprentices – but not for long.” Michael Herman, February 28, 2026.
Reliable Software Guild Manifesto
Overall reliable software quality grows quadratically with structural engineering strength and only linearly with governance quality.
Governance cannot compensate for structural weakness.
Imbalance within any structural pair (C, P, or R) degrades total quality multiplicatively.
Sustainable software is governed engineering — but engineered first.
Formally:
Software Quality ∝ (Engineering)^2 × Governance
Strategic Interpretation
If CPR is low: Even perfect governance yields low Q.
If CPR is high but G is low: The system is powerful but dangerous or unstable long-term.
If both are high: You get durable, scalable, trustworthy systems.
NOTE: The Rubric can be used to assess the software artificacts produced by (digital as well as human) code masons with diverse breadths of experience, quality, and architectural/design sense: from Apprentice Masons up through Master Masons.
Reliable Software Quality Principles
The Reliable Software Quality Principles represent a linear list of orthogonal spanning set of reliable software quality metrics:
Correctness: Software produces outputs that correspond to reality and specification.
Composable: Can be safely combined with other systems through clean interfaces.
Performant: How efficiently does the system use time and resources to achieve its function.
Privacy-First: Minimizes unnecessary data exposure and maximizes user control over data.
Reliable: Produces expected results consistently over time.
Resilient: Maintains function under stress, degradation, or partial failure.
Evolvable: Designed to adapt over time without collapse.
Secure: Resists unauthorized access, misuse, and adversarial compromise.
Transparent: Observable, auditable, and understandable.
User-Centered: Optimized for human goals, comprehension, and agency.
Orthogonal Major and Minor Axes
The following categorization is presented for explanatory purposes. It represents a two-level orthogonal spanning set of the SSQ Quality Principles.
Spatial
Composable
User-Centered
Temporal
Evolvable
Reliable
Resilient
Integrity
Correctness
Secure
Privacy-First
Efficiency
Performant
Observability
Transparent
Structural Core
The Structural Core of a reliable software system is the set of fundamental engineering dimensions that ensure its integrity, stability, and robustness. It encompasses the interrelated principles of correctness, composability, performance, privacy, reliability, and resilience—forming the foundational “skeleton” upon which all other governance and user-facing features depend.
The structural core is the backbone of a system, combining correctness, composability, performance, privacy, reliability, and resilience to create a stable, robust foundation for all other features and governance mechanisms.
Structural Core Score (CPR)
The Structural Core Score (CPR) consists of three geometric pairings:
C = √(Correctness × Composable)
P = √(Performant × Privacy-First)
R = √(Reliable × Resilient)
The aggregate structural core quality is computed as the geometric mean of C, P, and R:
CPR = ³√(C × P × R)
The use of geometric means penalizes imbalance and prevents compensatory scoring. Structural core quality is then squared to reflect compounding architectural leverage: (CPR)^2.
Structural Core Principles (CPR) Relationships and Interactions
C = Correctness + Composable → Logical & Structural Integrity
Correctness – Software does what it is supposed to do.
Composable – Software can safely integrate with other systems. Metaphor: “A brick must be solid and fit with others to build a stable wall.” Reasoning: A system is only structurally sound if it is both right and integrable.
P = Performant + Privacy-First→ Practical Operational Quality
Performant – Efficient, fast, and resource-conscious.
Privacy-First – Protects sensitive data and respects boundaries. Metaphor: “A car must move fast and lock its doors; speed without safety or safety without speed is useless.” Reasoning: A system is only usable in real life if it is both efficient and safe.
R = Reliable + Resilient → Temporal Robustness
Reliable – Works consistently under normal conditions.
Resilient – Survives and recovers from stress, failures, or unexpected events. Metaphor: “A bridge must stand every day and survive storms to be truly dependable.” Reasoning: Robustness requires both steady performance and the ability to handle disruption.
Governance (G)
Governance refers to the set of guiding mechanisms that ensure a reliable software system evolves responsibly, remains secure, operates transparently, and serves real user needs. In this context, governance does not create structural strength; rather, it moderates and scales the impact of the structural core over time.
Governance is the institutional layer that guides how a system adapts, secures itself, exposes accountability, and remains user-centered—multiplying the value of structural strength without substituting for it.
Software Governance Quality Score
Governance is modeled as the arithmetic mean of four moderating dimensions:
G = (E + S + T + U) / 4
Where E = Evolvable, S = Secure, T = Transparent, and U = User-Centered. Governance acts as a multiplier rather than an exponent, reflecting its role in scaling engineering outcomes rather than creating them.
Software Governance Principles
E = Evolvable → Adaptation over Time
Can change, improve, or scale without collapsing. Metaphor: “A building designed for future expansion is more valuable than one that cannot adapt.”
S = Secure → Protection Against Threats
Guards against unauthorized access or exploitation. Metaphor: “A fortress is only valuable if the gates are locked against intruders.”
T = Transparent → Observability & Accountability
Understandable, auditable, and explainable. Metaphor: “A window in the wall lets people see what’s happening inside; without it, trust is impossible.”
U = User-Centered → Human Alignment
Designed with human needs, goals, and comprehension in mind. Metaphor: “A tool is only useful if people can actually use it.”
For sufficiently strong systems, marginal improvements in structural strength produce greater gains in quality than equivalent improvements in governance.
Future empirical validation may include retrospective scoring across systems, incident correlation studies, and longitudinal tracking of structural improvements versus governance enhancements.
Conclusion
Reliable software quality behaves quadratically with structural engineering integrity and linearly with governance integrity. This establishes the foundation of the Reliable Software Quality Rubric:
Quality equals the square of engineering strength multiplied by governance strength ((CPR)^2 ESTU).
Appendix A: Reliable Software Quality Rubic
Structural Core (CPR)² × Governance (ESTU)
Scoring scale (per principle):
Score
Meaning
0
Absent / actively harmful
1
Minimal / inconsistent
2
Adequate but fragile
3
Strong and reliable
4
Excellent / exemplary
5
Industry-leading / best-in-class
Structural Core (CPR)
These are multiplicative: weakness in one materially degrades overall quality.
C — Correctness
Produces accurate results
Meets specification
Deterministic where required
Comprehensive test coverage
Clear validation of edge cases
C — Composable
Modular components
Clear interfaces
Low coupling, high cohesion
Reusable abstractions
Integrates cleanly with other systems
P — Performant
Meets latency/throughput targets
Efficient resource usage
Scales predictably
No unnecessary bottlenecks
Measured and monitored performance
P — Privacy-first
Minimizes data collection
Data use aligned with purpose
Proper access controls
Data lifecycle management
Encryption and isolation practices
R — Reliable
Consistent uptime
Predictable behavior
Low defect rate
Effective monitoring
Fast mean time to recovery
R — Resilient
Graceful degradation
Fault tolerance
Redundancy where appropriate
Handles partial failures safely
Recovery mechanisms tested
Governance (ESTU)
These modulate long-term sustainability and trust.
E — Evolvable
Easy to extend or modify
Backward compatibility strategy
Clear versioning practices
Refactor-friendly design
Maintains architectural integrity over time
S — Secure
Threat modeling performed
Least privilege enforced
Strong authentication
Regular audits and patching
Defense-in-depth strategy
T — Transparent
Observable and auditable
Clear documentation
Traceable decision logic
Honest communication about limitations
Accessible logs and metrics
U — User-centered
Solves real user problems
Usability tested
Clear UX flows
Accessibility considered
Feedback loops incorporated
Scoring Model
Structural Core Score (CPR)
C = √(Correctness × Composable)
P = √(Performant × Privacy-First)
R = √(Reliable × Resilient)
CPR = ³√(C × P × R)
Governance Score (G)
Total Quality Score (Q)
Q = (CPR)^2 × G
This preserves the insight:
Weaknesses in the structural core compound.
Governance moderates sustainability.
High performance without security (or correctness without reliability) cannot yield high Q.
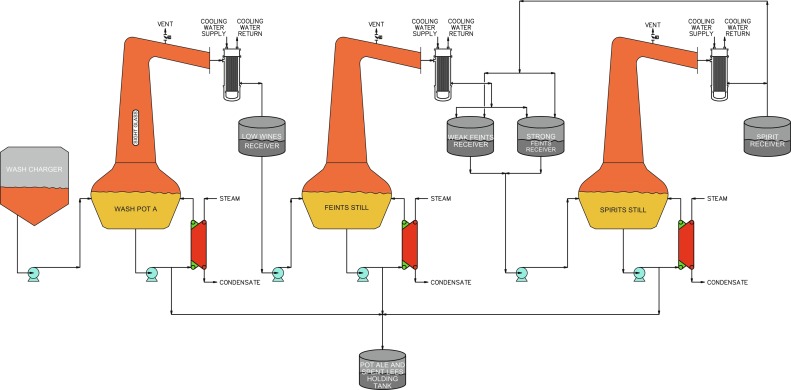
Appendix B – Crafting Traditional Irish Single Malt Whiskey
Here are the standard production steps for Irish single malt whiskey, with commonly used Irish (Gaeilge) terms where they exist.
Well-supported: The production sequence below aligns with modern Irish whiskey regulations (e.g., distilled in Ireland, malted barley base, pot still distillation, aged ≥3 years in wooden casks). Note: There is no single ancient Gaelic set of named “ritual steps.” Modern distilling vocabulary is often English, with Irish equivalents used descriptively rather than as fixed technical terms.
1. Malting
English: Malting Irish:Braichlín a dhéanamh (to malt) Barley is soaked, allowed to germinate, then dried (kilned).
2. Milling
English: Milling / Grinding Irish:Meilt The malted barley is ground into grist.
3. Mashing
English: Mashing Irish:Maisiú Hot water extracts fermentable sugars from the grist.
4. Fermentation
English: Fermentation Irish:Coipeadh Yeast converts sugars into alcohol, producing “wash.”
5. Distillation (Pot Still)
English: Distillation Irish:Driogadh Single malt is distilled in copper pot stills, usually twice (sometimes three times in Ireland).
Famous distilleries using traditional pot stills include:
(Scottish example for comparison)
6. Maturation
English: Aging / Maturation Irish:Aibiú The spirit matures in wooden casks for at least 3 years in Ireland.
Common cask types:
Ex-bourbon barrels
Sherry casks
Examples of Irish single malts:
The Irishman
West Cork Distillers
7. Bottling
English: Bottling Irish:Buidéalú The whiskey is diluted (if needed), filtered, and bottled.
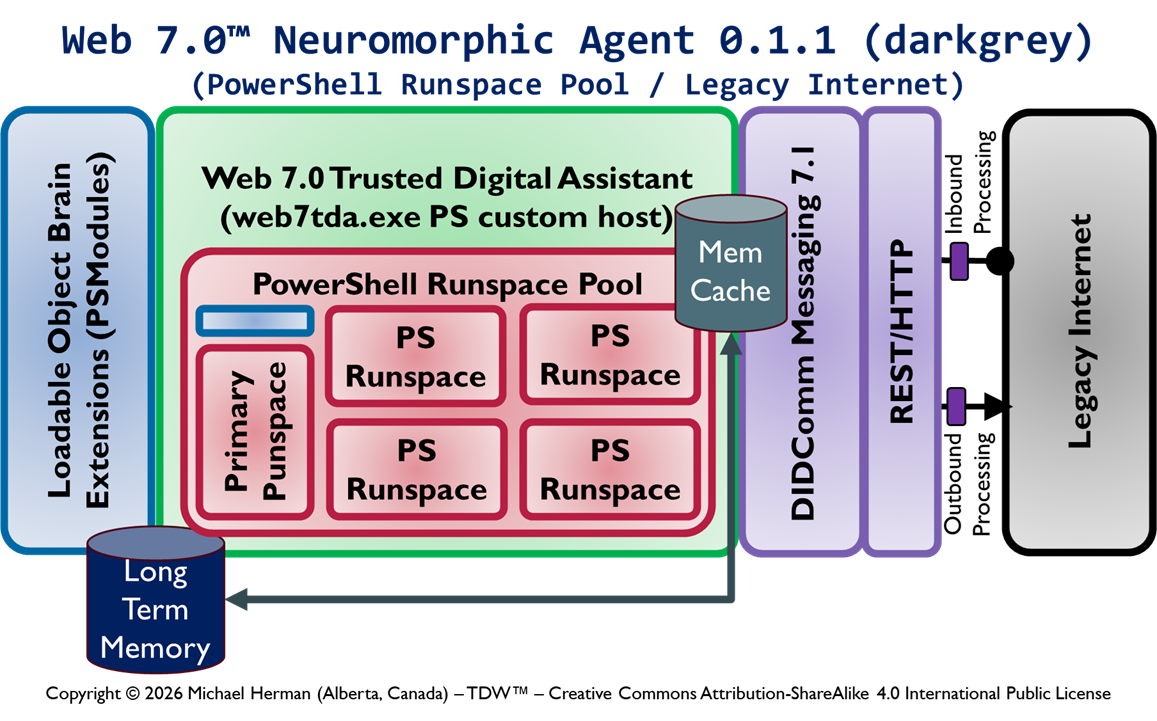
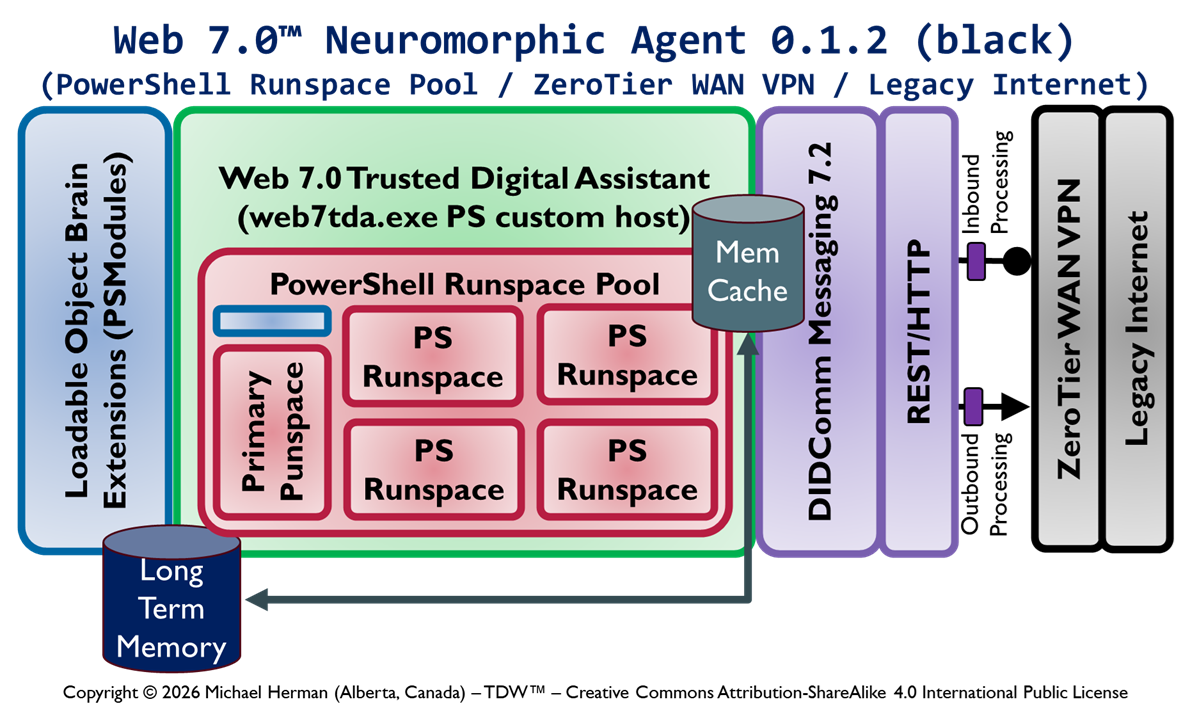
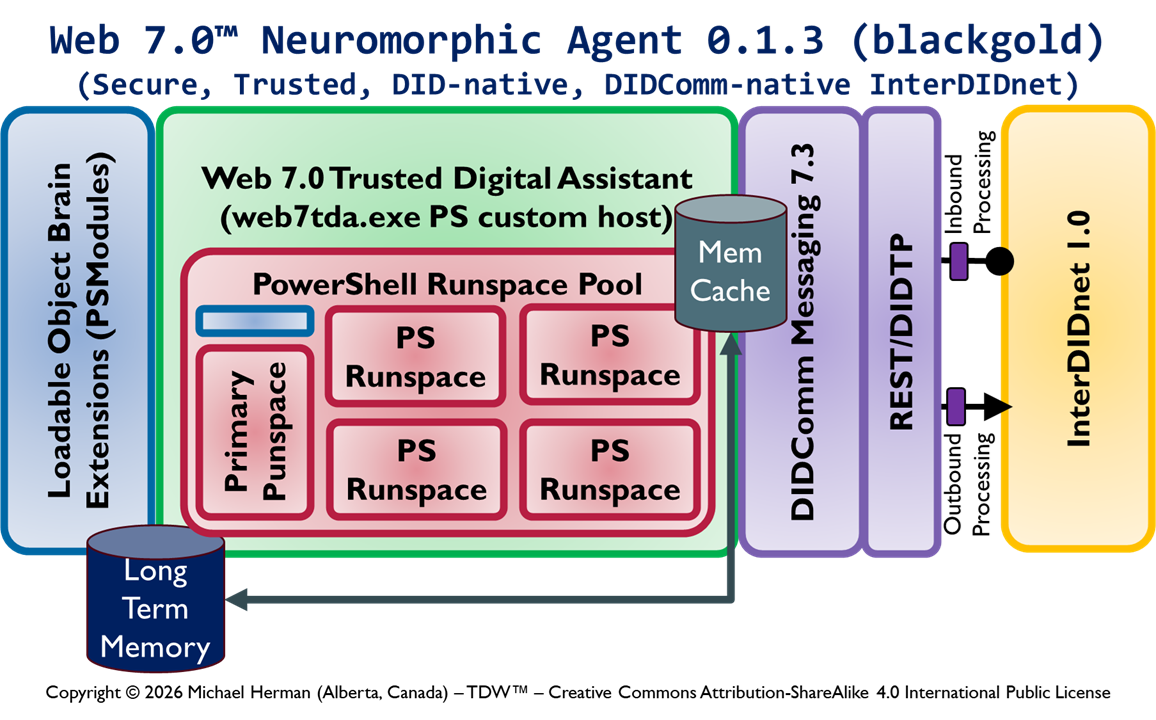
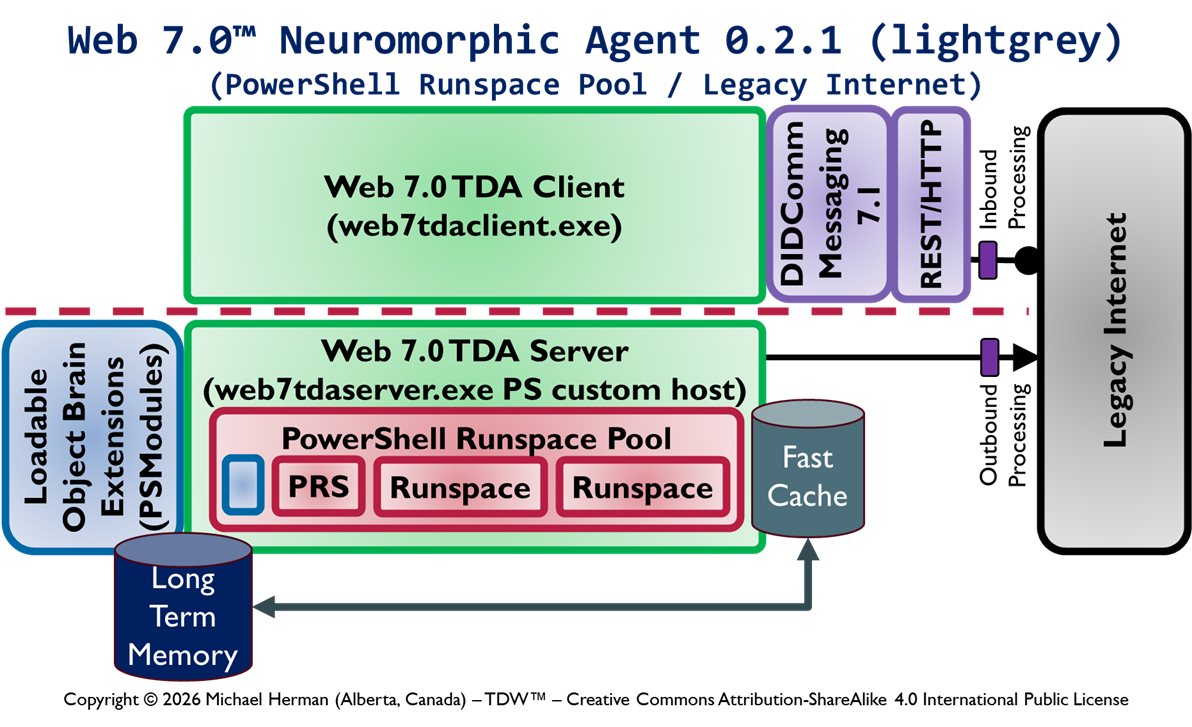
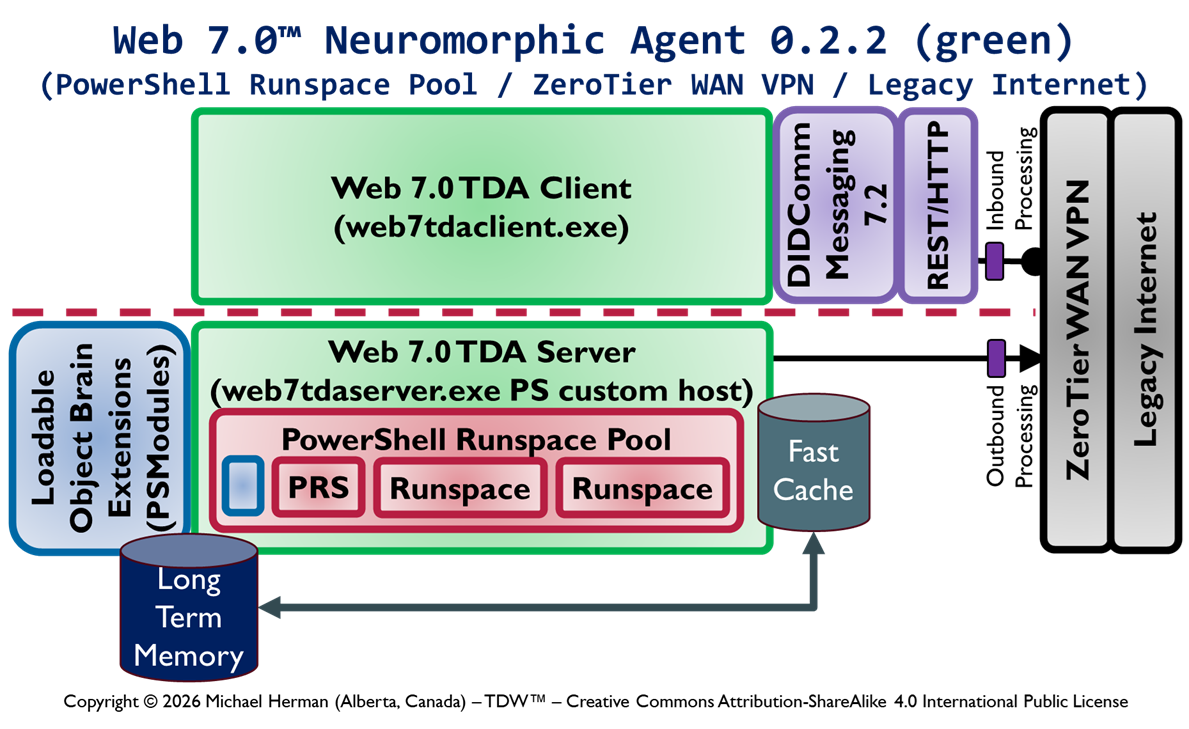
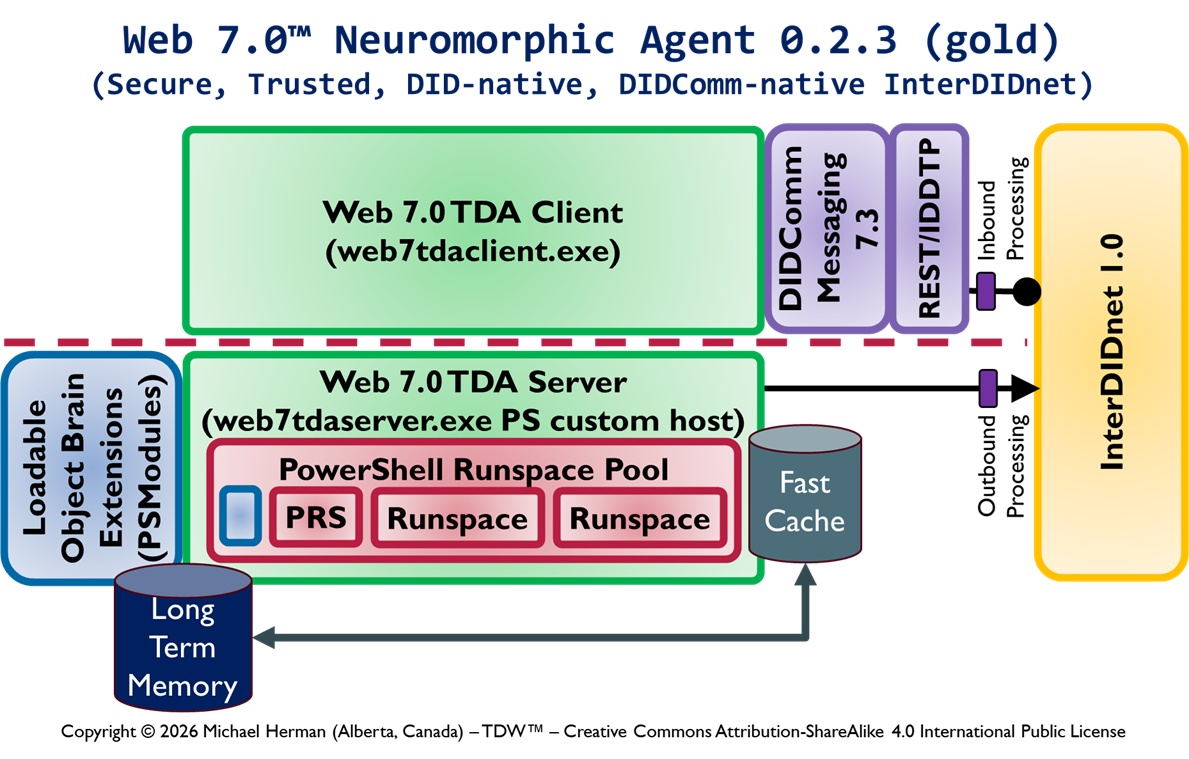
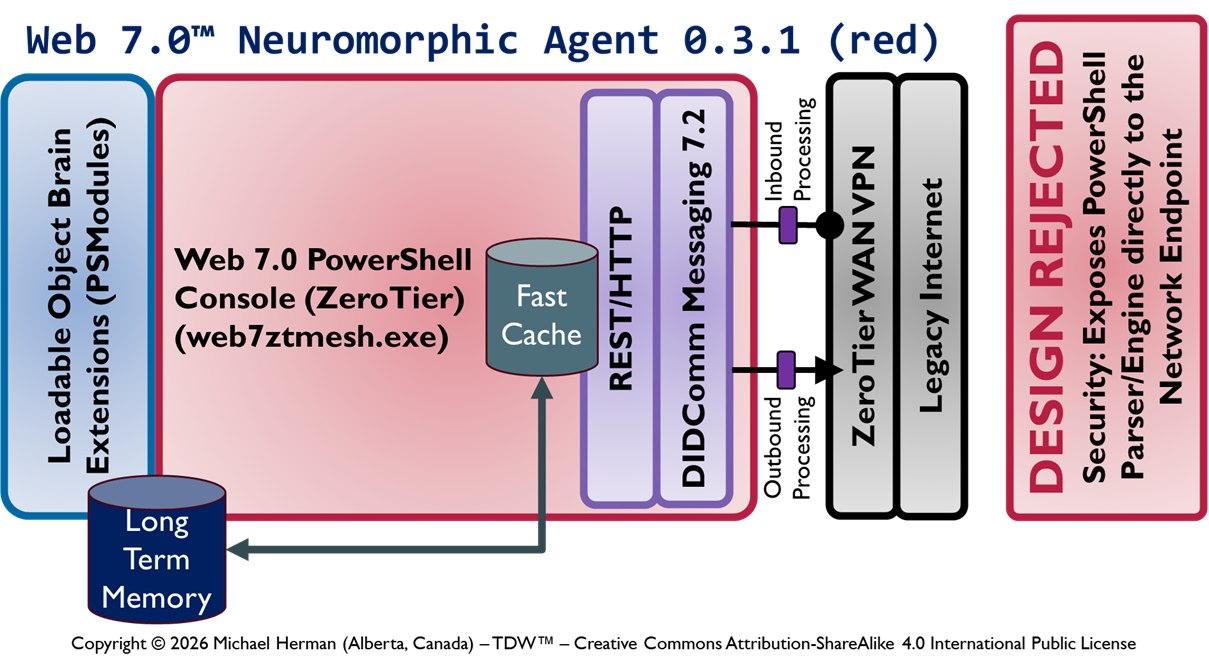
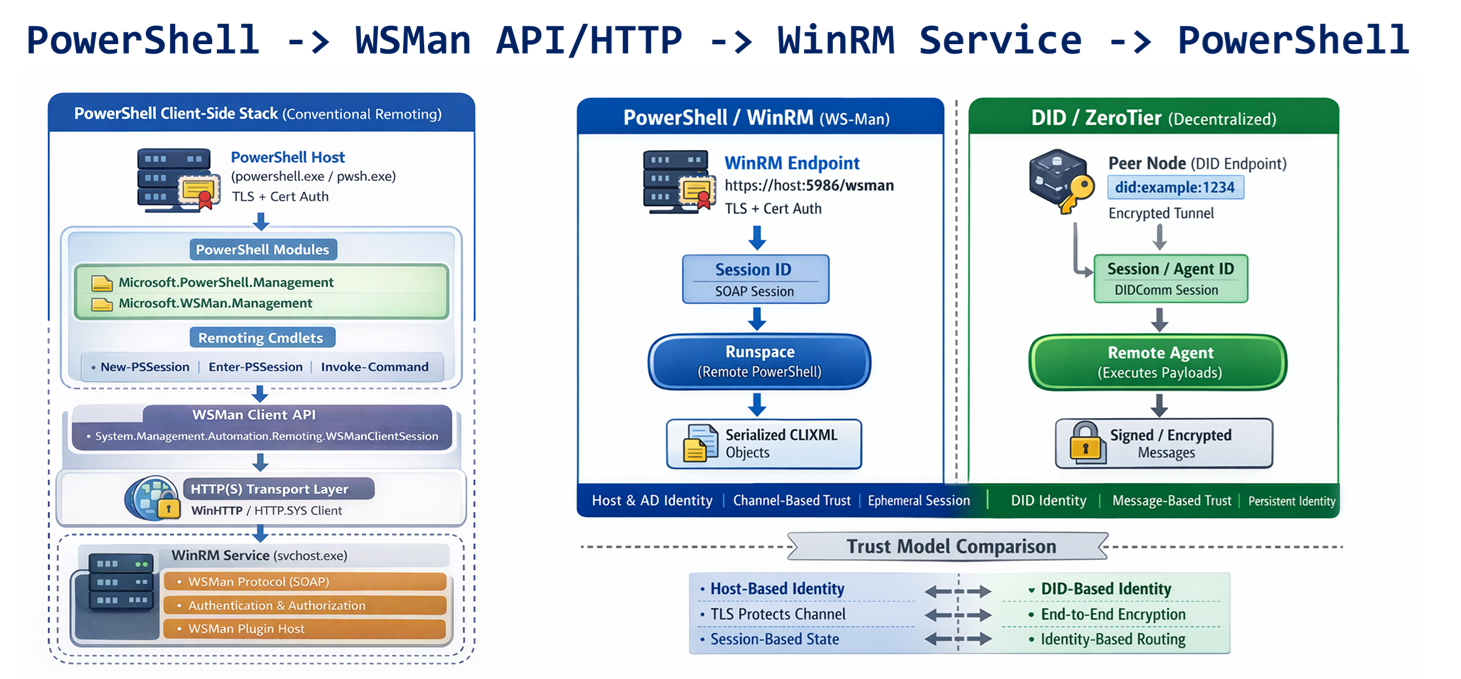
This article enumerates the different designs under consideration for adding for adding the following functionalty to cross-platform PowerShell to support the receipt, rememberance, and processing of remote PowerShell commands tunneled over DID Communications Messaging (DIDComm)/HTTP.
Web 7.0 DIDComm/HTTP endpoint/listener functionality
Secure, trusted Long-Term Memory (LTM)
Security-First architecture and design
InterDIDnet DID-native, DIDComm-native network support
Design 0.1.2 is the current most-favoured initial design. Which design is your choice?
Michael Herman | Chief Digital Architect | Hyperonomy Digital Identity Lab | Web 7.0 Foundation
Michael Herman is a pioneering software architect and systems thinker with over five decades of experience designing foundational computing platforms during moments of major technological transition. His career spans enterprise software, developer ecosystems, and distributed infrastructure, with senior roles at Microsoft, IBM, Alias/Wavefront, Optical Recording Corporation, and Star Data Systems. Across these environments, Herman helped shape the evolution of operating systems and enterprise platforms from early client-server architectures to networked and distributed systems.
At Microsoft, Herman served as a lead enterprise consultant on complex infrastructure engagements for major financial institutions, utilities, and public-sector organizations. He also worked within the Microsoft Exchange and SharePoint Portal Server product groups, leading developer technical readiness programs for both internal field teams and global partners. Earlier, in senior product development roles at ORC, Alias/Wavefront, and Star Data Systems, he led the creation of Windows-based platforms for enterprise document management, advanced graphics, and financial systems.
In a 1991 Windows World keynote, Bill Gates cited Alias Upfront for Windows, one of Herman’s projects, as the most innovative new graphics product for Microsoft Windows. In recent years, Herman’s work has focused on the architectural foundations of digital trust and decentralized identity. He is a named contributor to the W3C Decentralized Identifier (DID) specification and has contributed to initiatives within the Decentralized Identity Foundation (DIF) and Trust over IP (ToIP). Through the Web 7.0 Foundation and the Trusted Digital Web (TDW ), he advances first principles approaches to agentic systems, verifiable identity, and trust-native internet infrastructure – examining how autonomy, accountability, and cryptographic assurance must be embedded at the protocol level of future digital systems.
Grounded in deep technical rigor, Herman holds Bachelor’s and Master of Mathematics degrees in Computer Science (Computer Graphics) from the University of Waterloo, where he also served as the founding lab manager of the Computer Graphics Laboratory. Known for his ability to translate emerging paradigms into coherent system architectures, he continues to advise advanced software initiatives on the long-term implications of decentralized systems, digital identity, and trust.