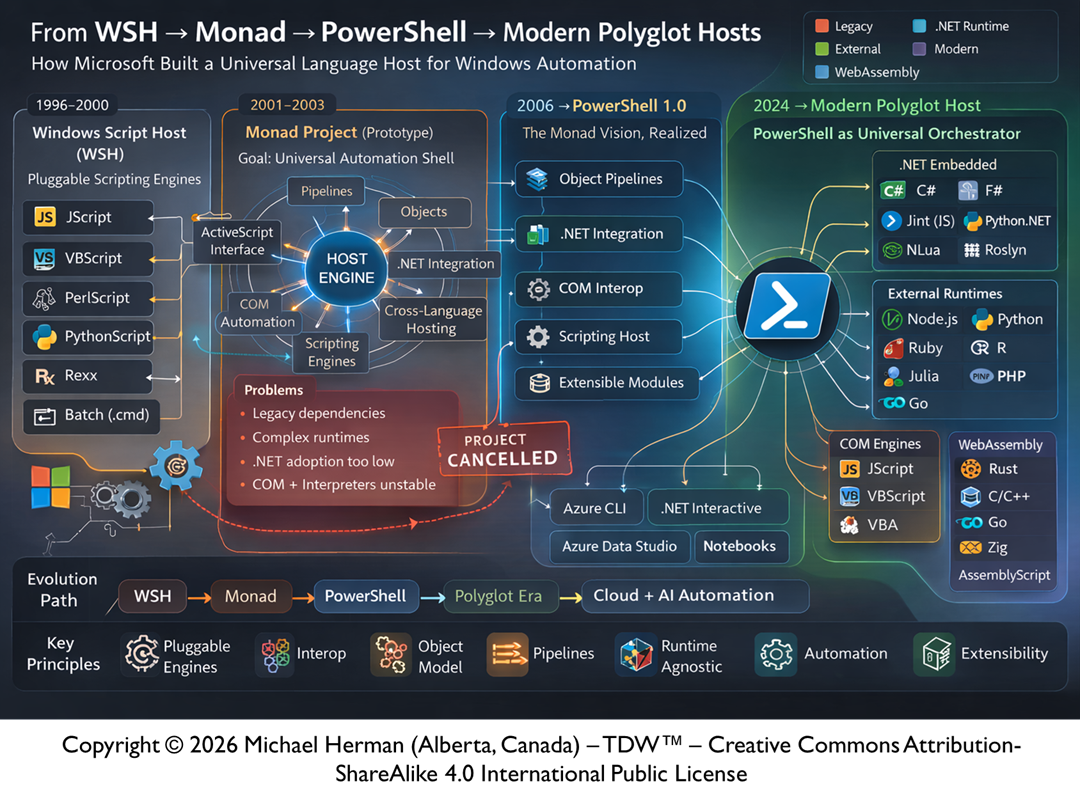
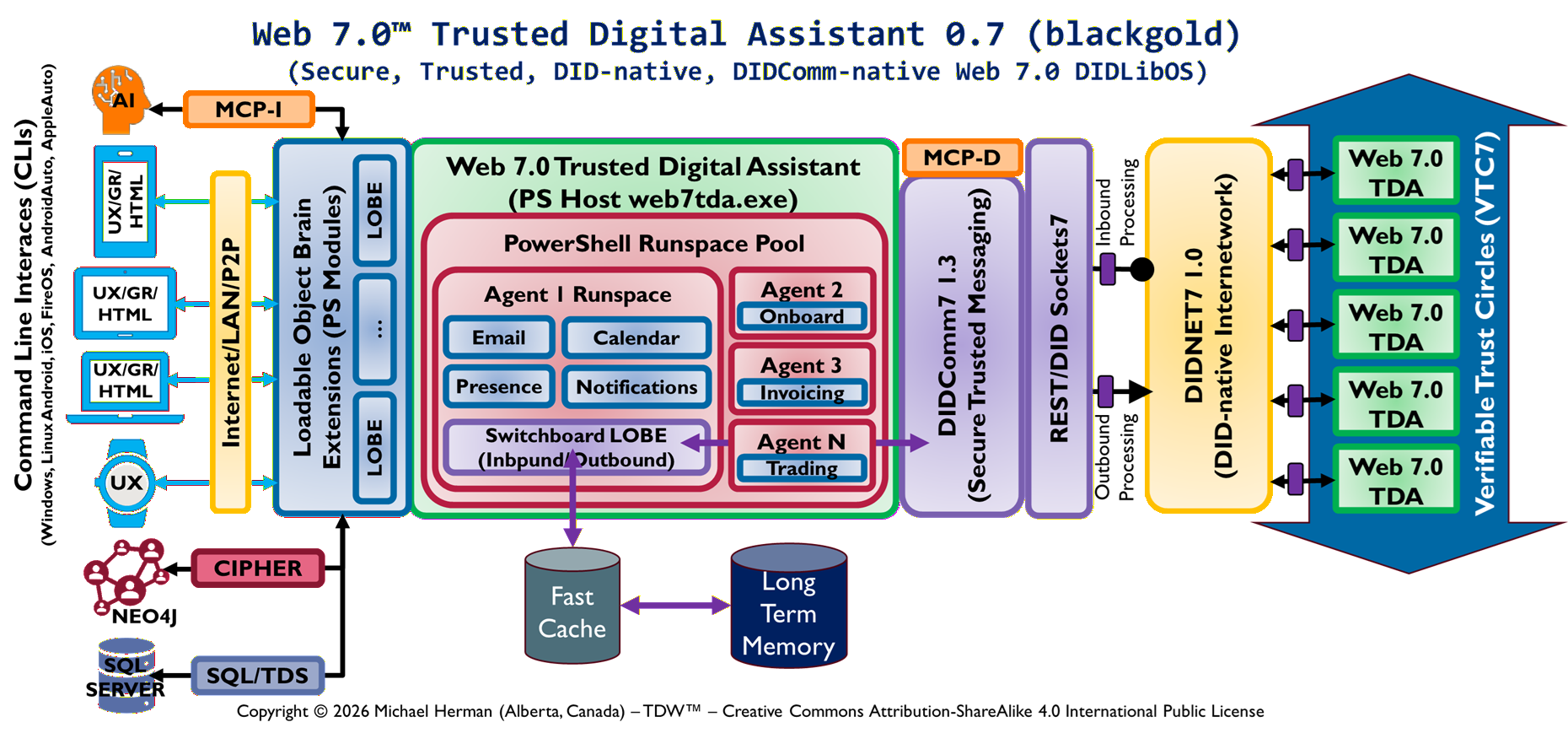
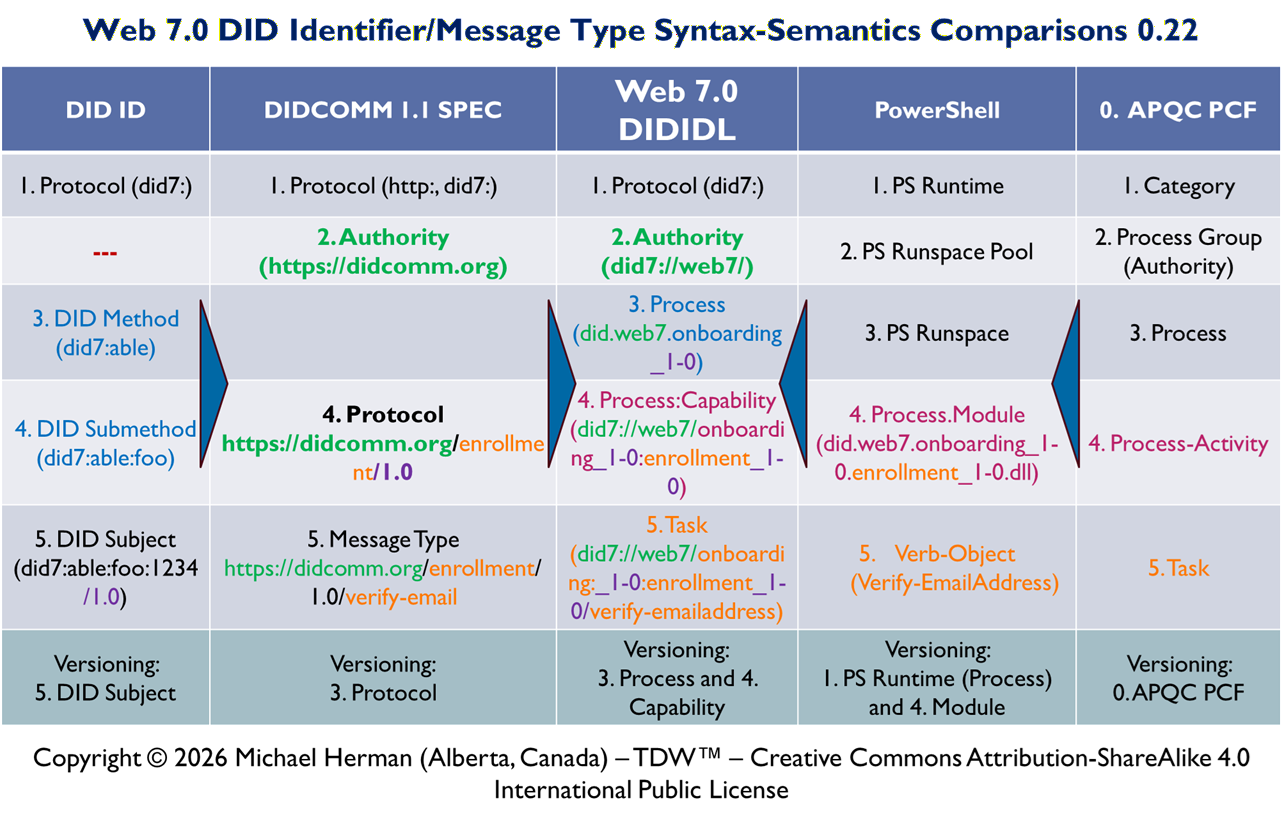
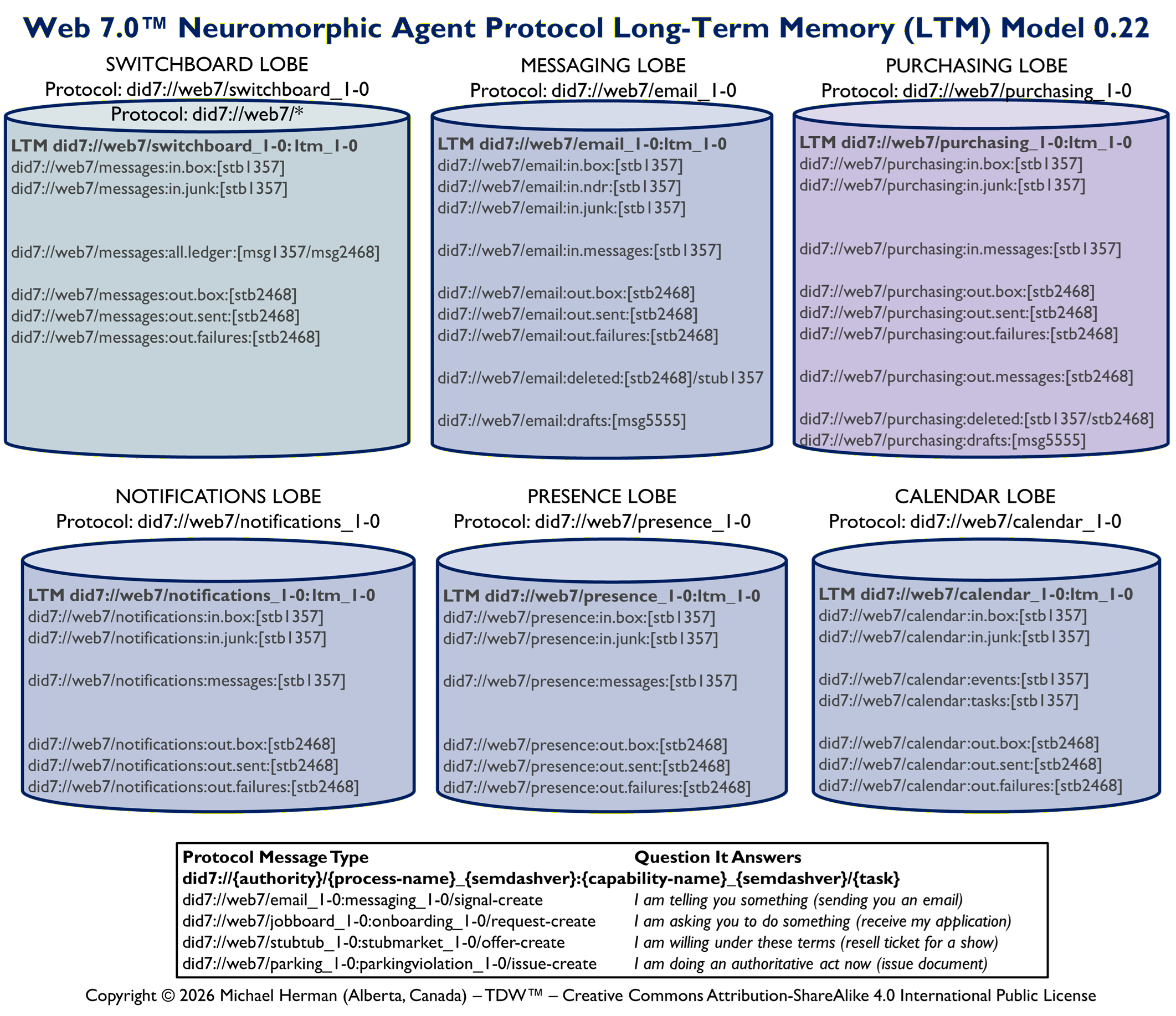
Identity-Addressed Execution, Event-Sourced Memory, and Runspace-Orchestrated Agent Computing
Version: 2.0 Date: 2026-03-25
Create your own magic with Web 7.0 DIDLibOS™ / TDW AgenticOS™. Imagine the possibilities.
Copyright © 2026 Michael Herman (Bindloss, Alberta, Canada) – Creative Commons Attribution-ShareAlike 4.0 International Public License
Web 7.0™, Web 7.0 DILibOS™, TDW AgenticOS™, TDW™, Trusted Digital Web™ and Hyperonomy™ are trademarks of the Web 7.0 Foundation. All Rights Reserved.
Table of Contents
- Abstract
- Introduction
- System Overview
- Core Design Principles
- DIDComm Message Model
- DID as Universal Execution Handle
- LiteDB as Agent Memory Kernel
- Transparent Cache Architecture
- PowerShell Runspace Execution Model
- Pipeline Semantics and Execution Flow
- Cmdlet Lifecycle and Message Transformation
- Cross-Runspace Communication Model
- Event-Sourced State and Immutability
- LOBES (Loadable Object Brain Extensions)
- MCP-I and External System Interfacing
- Agent Memory Architecture (Long-Term Memory)
- DID Resolution and Identity Semantics
- Concurrency Model and Consistency Guarantees
- Performance Model and Cache Behavior
- Failure Modes and Recovery Semantics
- Security Model and Trust Boundaries
- Web 7.0 Agent Ecosystem Model
- Diagrammatic Architecture Reference
- System Properties Summary
1. Abstract
Web 7.0 DIDLibOS defines an identity-addressed, event-sourced execution architecture in which all computation is performed over DIDComm messages persisted in a single LiteDB instance per agent. Instead of passing in-memory objects between computational steps, the system passes Decentralized Identifier (DID) strings that resolve to immutable message state stored in a persistent memory kernel. This enables deterministic execution, full replayability, cross-runspace isolation, and scalable agent orchestration.
2. Introduction
Traditional execution models in scripting and automation environments rely on in-memory object pipelines. These models break under distributed execution, concurrency, and long-term persistence requirements. Web 7.0 DIDLibOS replaces object-passing semantics with identity-passing semantics.
In this model, computation becomes a function over persistent state rather than transient memory.
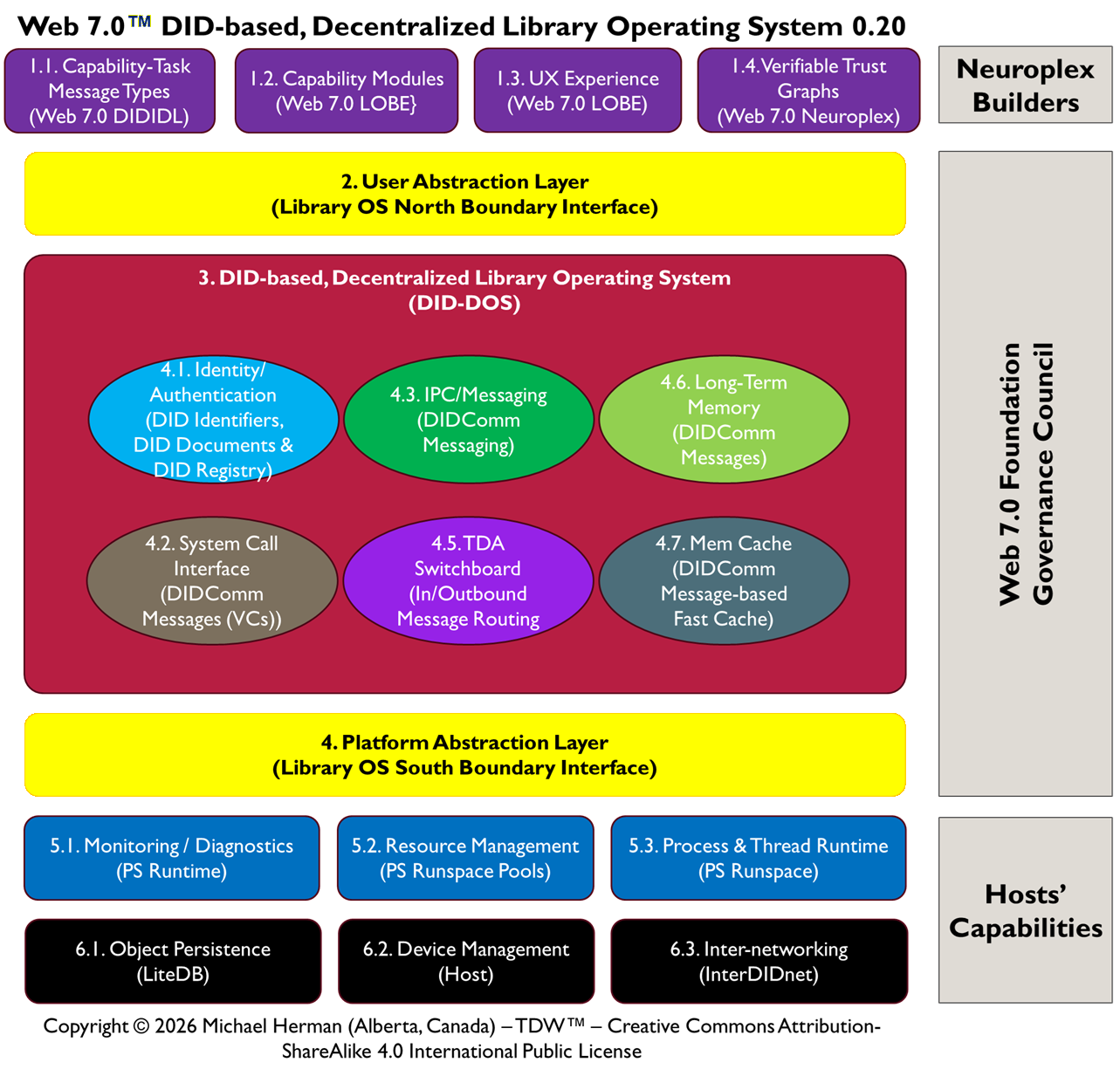
3. System Overview
The system consists of four primary layers:
- Execution Layer: PowerShell runspaces executing cmdlets
- Identity Layer: DIDComm message identifiers (DIDs)
- Memory Layer: LiteDB persistent store per agent
- Acceleration Layer: Transparent in-memory cache managed by LiteDB
All computation flows through these layers via identity resolution.
4. Core Design Principles
- Everything is a DIDComm message
- DIDs are the only runtime values passed between cmdlets
- All state is persisted in LiteDB
- No shared in-memory objects exist across runspaces
- Execution is deterministic and replayable
- Cache is transparent and non-semantic
- Mutation creates new messages, never modifies in-place
5. DIDComm Message Model
Each system object is represented as a DIDComm message with a globally unique DID.
A DID serves as:
- Identifier
- Lookup key
- Execution handle
Messages are immutable once persisted.
6. DID as Universal Execution Handle
The DID is the only value passed in PowerShell pipelines.
A cmdlet receives a DID, resolves it via LiteDB, processes the message, and outputs a new DID.
Pipeline flow: DID₁ → Cmdlet → DID₂ → Cmdlet → DID₃
7. LiteDB as Agent Long-term Memory
LiteDB acts as the system of record.
Responsibilities:
- Persistent message storage
- Indexing by DID
- Versioning support
- Retrieval and query execution
There is exactly one LiteDB instance per agent.
8. Transparent Cache Architecture
LiteDB includes an internal cache layer.
Properties:
- In-memory acceleration
- Size configurable
- Fully transparent
- No semantic visibility to execution layer
Cache only optimizes DID resolution.
9. PowerShell Runspace Execution Model
Each runspace is an isolated execution environment.
Properties:
- No shared memory across runspaces
- Only DID strings are passed
- Execution is stateless between invocations
10. Pipeline Semantics and Execution Flow
Pipeline execution is identity-based:
Step 1: Receive DID Step 2: Resolve message Step 3: Execute transformation Step 4: Persist new message Step 5: Emit new DID
11. Cmdlet Lifecycle and Message Transformation
Each cmdlet follows a strict lifecycle:
- Input: DID
- Resolve: LiteDB lookup
- Materialize: snapshot object
- Transform: compute result
- Persist: store new message
- Output: new DID
12. Cross-Runspace Communication Model
Runspaces communicate only via DIDs.
No object sharing occurs. All state is retrieved from LiteDB.
13. Event-Sourced State and Immutability
All messages are immutable. Each transformation produces a new version.
This creates a complete event history of system execution.
14. LOBES (Loadable Object Brain Extensions)
LOBES are modular execution extensions implemented as PowerShell modules.
Capabilities:
- Cmdlet composition
- External system integration
- DID-based message processing
- Execution graph augmentation
15. MCP-I and External System Interfacing
MCP-I acts as a bridge for external APIs and systems.
It enables:
- Querying external databases
- Calling agent APIs
- Integrating distributed services
All interactions remain DID-addressed.
16. Agent Memory Architecture (Long-Term Memory)
Long-term memory is implemented as persistent DID storage in LiteDB.
It supports:
- Historical replay
- State reconstruction
- Cross-runspace consistency
17. DID Resolution and Identity Semantics
A DID is resolved at runtime into a message snapshot.
Important distinction:
- DID is a reference
- Message is persisted state
18. Concurrency Model and Consistency Guarantees
Concurrency is managed via:
- Single-writer LiteDB semantics
- Atomic writes per message
- Isolation between runspaces
19. Performance Model and Cache Behavior
Performance optimization occurs via internal caching.
Hot messages remain in memory. Cold messages are loaded from disk.
20. Failure Modes and Recovery Semantics
Failures are handled via:
- Persistent message logs
- Replay capability
- Idempotent cmdlet execution
21. Security Model and Trust Boundaries
Security is enforced through:
- DID-based identity verification
- Controlled execution boundaries
- Module isolation in LOBES
22. Web 7.0 Agent Ecosystem Model
Agents operate as autonomous computation nodes.
They communicate via DIDComm messages forming a distributed execution graph.
23. DIDLibOS Architecture Reference Model (DIDLibOS-ARM) 0.8
Referenced external architecture diagram:
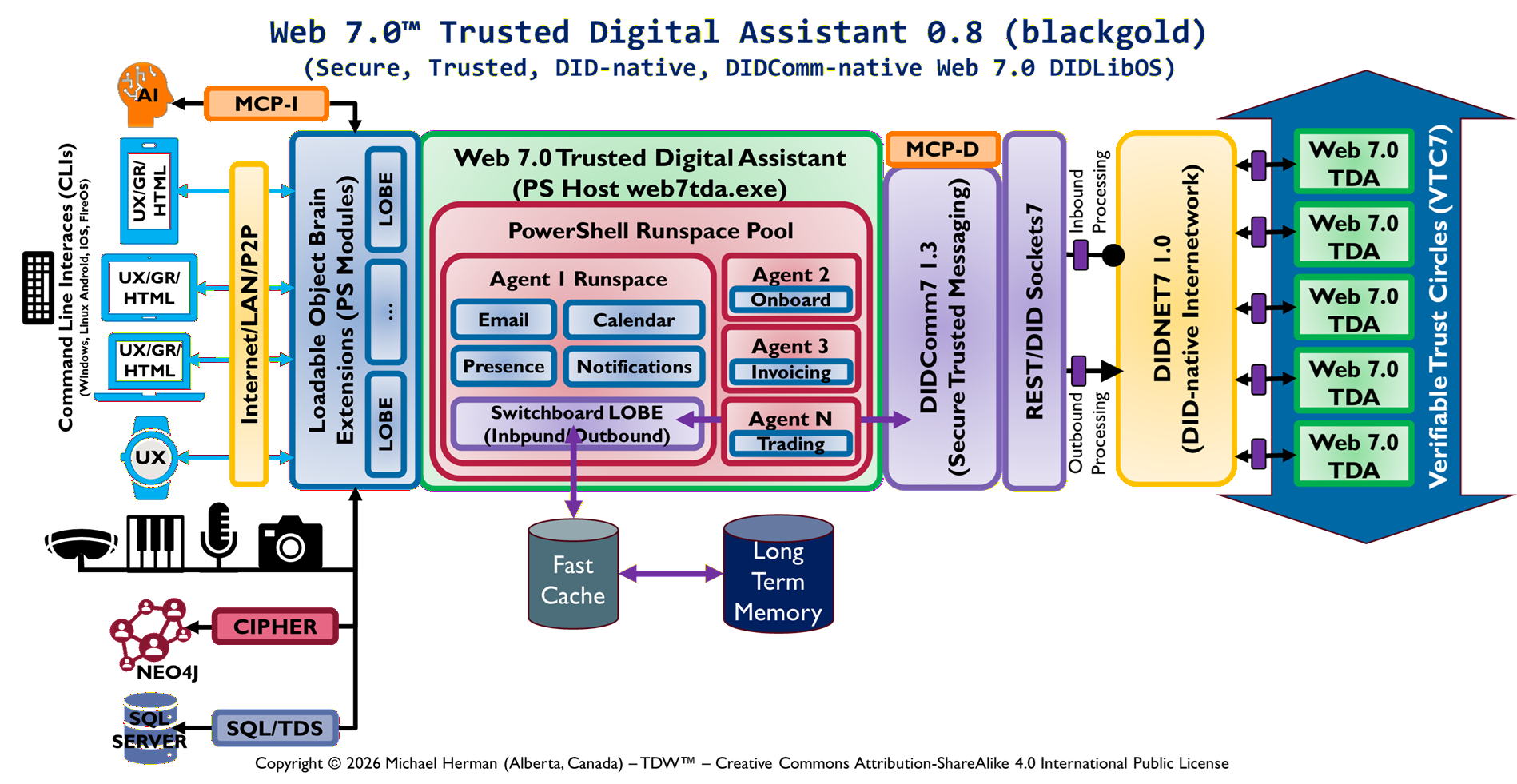
This diagram represents:
- Multi-agent neural execution topology
- DIDComm messaging fabric
- LOBE-based computation layers
- Neuro-symbolic orchestration system
24. Summary
- Deterministic execution
- Identity-based computation
- Event-sourced memory
- Runspace isolation
- Transparent caching
- Modular extension via LOBES
- Distributed agent scalability