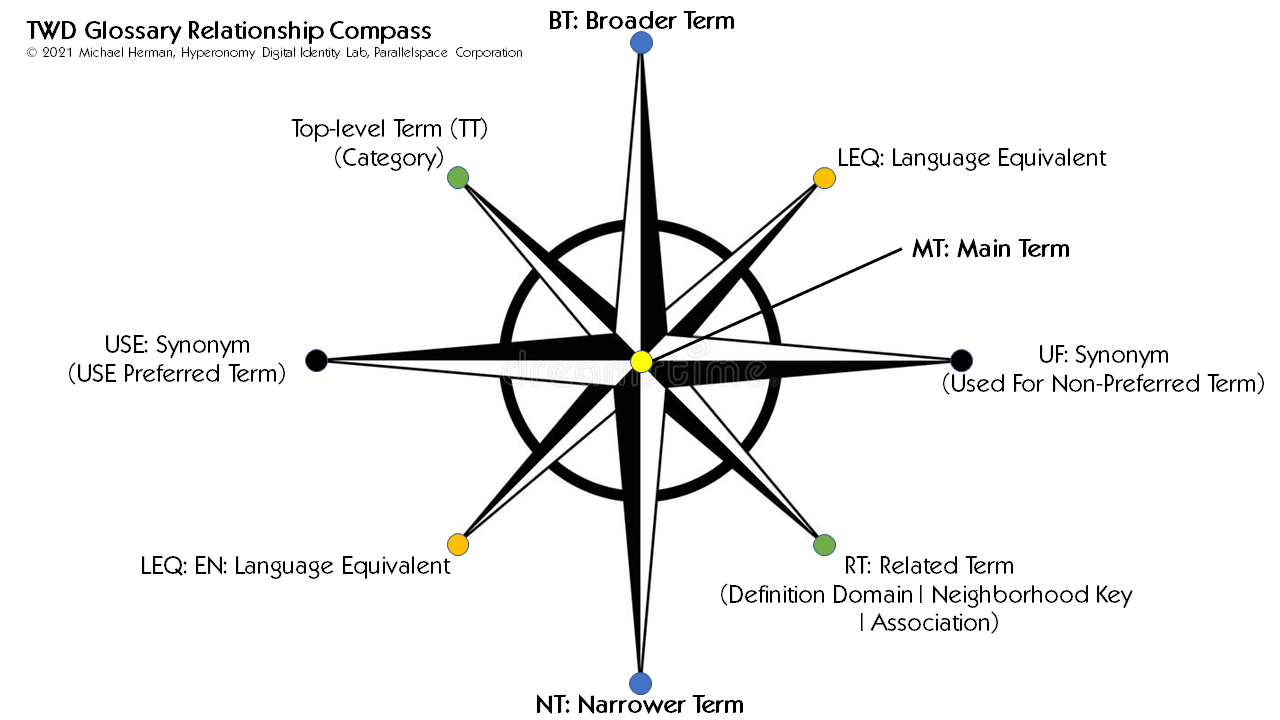
The points of the TDW Glossary Relationship Compass are based on the relationship types defined in ANSI/NISO Z39.19-2005.
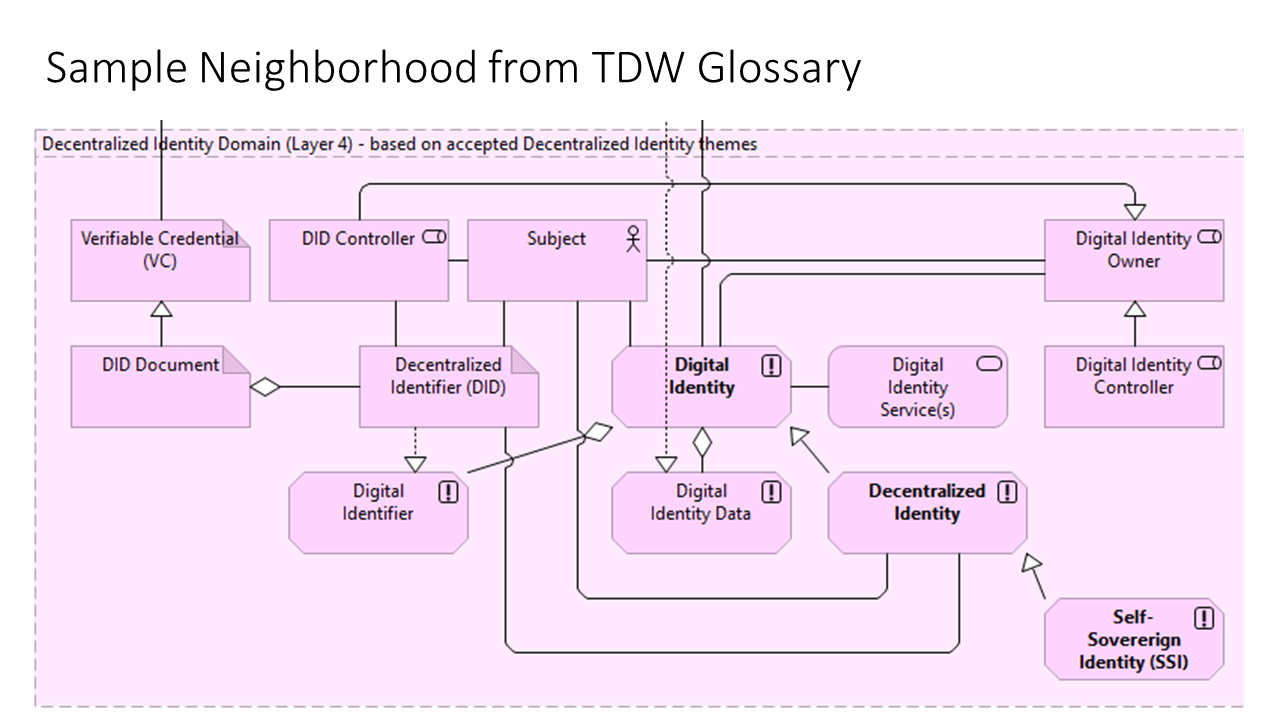
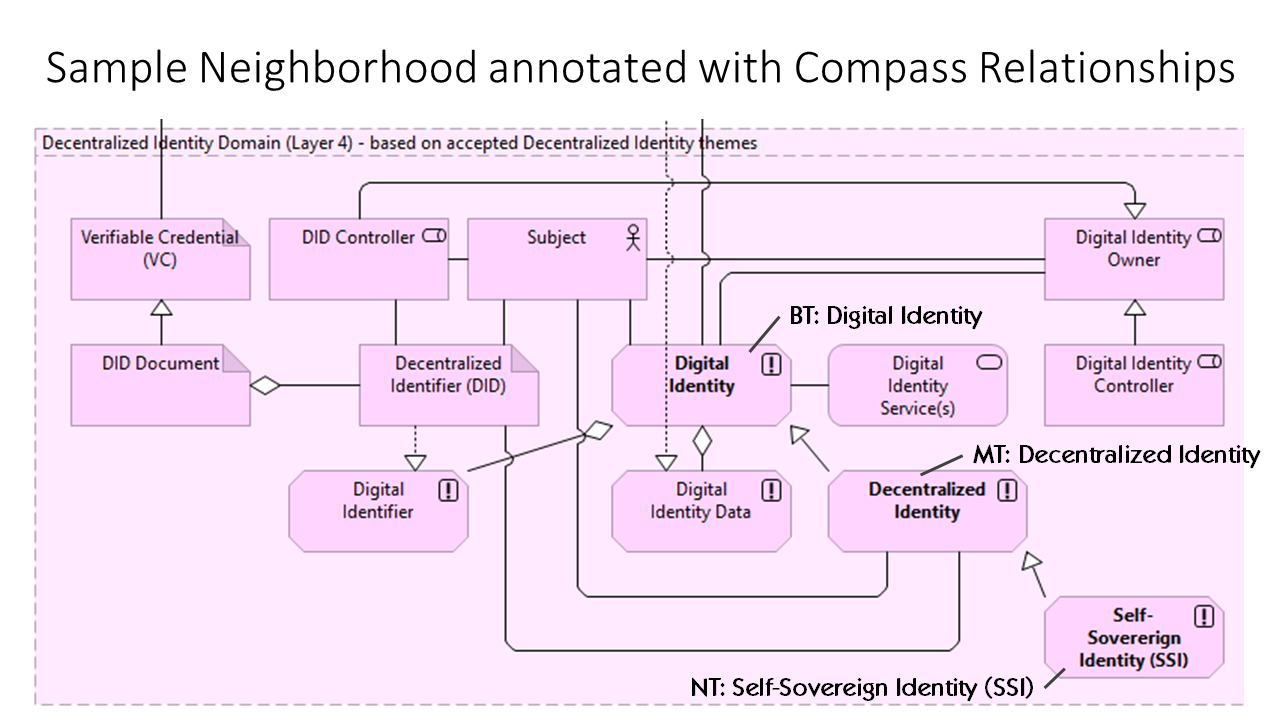
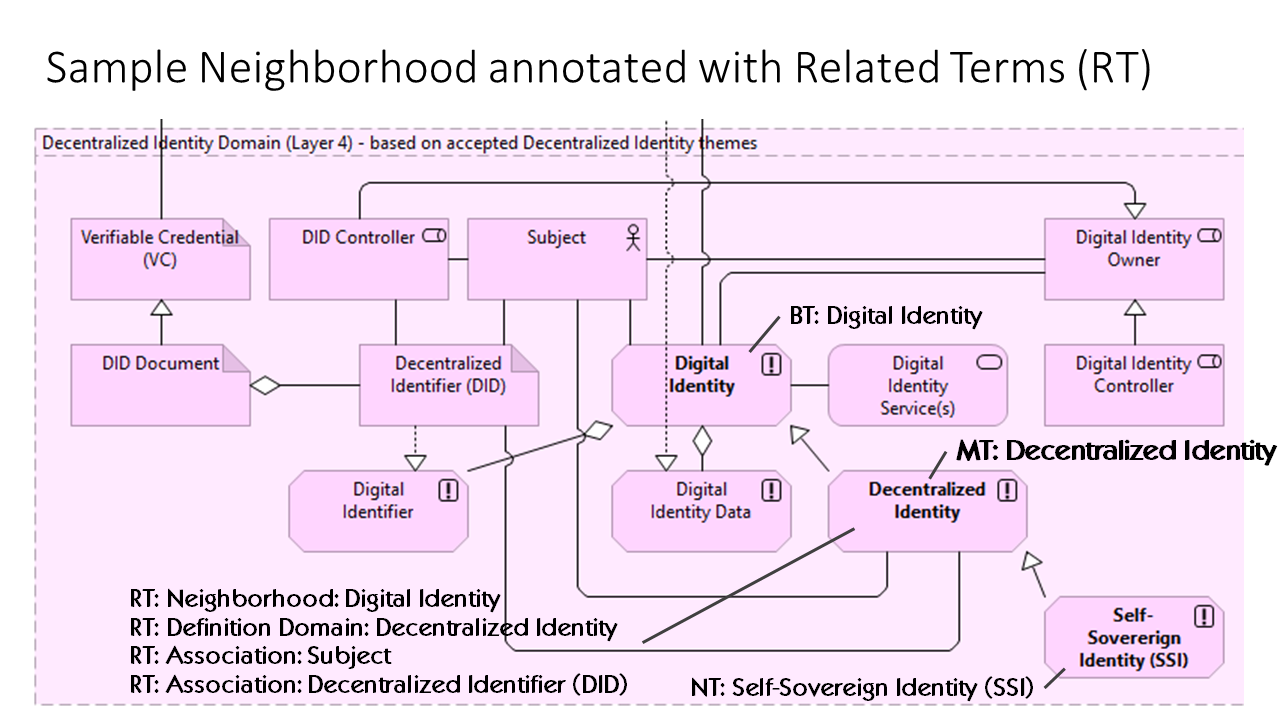
Figure 1. TDW Glossary Relationship Compass Figure 2. Neighborhood example from the TDW Glossary: MT: Digital IdentityFigure 3. TDW Glossary Relationship Compass for an example: MT: Decentralized IdentityFigure 4. Neighborhood example annotated using the TDW Glossary Relationship Compass: MT: Decentralized IdentityFigure 5. Neighborhood example annotated with Related Terms (RT): MT: Decentralized Identity
Click the HUB-ARM to enlarge it. It will open in a new tab. Read the narration provided below the HUB-ARM.
Figure 1. TDW Hub Architecture Reference Model (HUB-ARM)
Narration
Each bullet in the list below describes a numbered bubble in the diagram above.
Alice’s App (1) has secure access to Alice’s Public Data (5), Alice’s Private Data (8), and Alice’s Secret Data (11).
Alice’s App (1)’s secure access is realized by the Layer D Hub Service Endpoints (2). The Layer D Hub Service Endpoints (2) support intelligent, semantics-based, query-by-schema access via a pubic interface exposed by a collection of Hub Protocol Handlers (3).
Layer D Hub Service Endpoints (2)’s collection of supported Hub Protocol Handlers (3) might include: Bluetooth, HTTP REST, gRPC, Web Sockets, etc.
Layer D Hub Service Endpoints (2) primarily provide access to the functionality supported by the Layer D Federated Query and Retrieval Service (4). The functionality supported by the Layer D Federated Query and Retrieval Service includes intelligent federated routing of semantics and schema-based queries plus aggregated retrieval of matching resources from Alice’s Public Data (5), Alice’s Private Data (8), and/or Alice’s Secret Data (11).
Alice’s Public Data (5) is managed by the Hub Microkernel (6) which supports UJWT Data Vaults (7) containing collections of unsigned JWT resources.
The Hub Microkernel (6) provides CRUD access to the collections of unsigned JWT resources in one or more UJWT Data Vaults (7) attached to the Hub Microkernel (6).
One or more UJWT Data Vaults (7) can be attached to a Hub Microkernel (6) and are used to store collections of unsigned JWT resources.
Alice’s Private Data (8) is managed by the Hub Microkernel (9) which supports JWS Data Vaults (10) containing collections of JWS (signed JWT) resources.
The Hub Microkernel (9) provides CRUD access to the collections of JWS (signed JWT) resources in one or more JWS Data Vaults (10) attached to the Hub Microkernel (9).
One or more JWS Data Vaults (10) can be attached to a Hub Microkernel (9) and are used to store collections of JWS (signed JWT) resources.
Alice’s Secret Data (11) is managed by the EDV Microkernel (12) which supports JWE Data Vaults (13) containing collections of JWE (encrypted JWT) resources.
The EDV Microkernel (12) provides CRUD access to the collections of JWE (encrypted JWT) resources in one or more JWE Data Vaults (13) attached to the EDV Microkernel (12).
One or more JWE Data Vaults (13) can be attached to an EDV Microkernel (12) and are used to store collections of JWE (encrypted JWT) resources.
An Indexing Crawler Service (14) might enable the indexing of publicly available content in Alice’s Data Vaults (7, 10, 13). Private and Secret Data Vaults will most likely not expose any indexable data vault-level or resource-level data.
A Data Vault Directory Service (DVDS) (15) might exist to enable the lookup and resolution of Alice’s Data Vaults (7,10, 13) by various public data vault properties. Private and Secret Data Vaults will most likely not expose any public data vault properties and would not be locatable using the DVDS (15).
Acknowledgements
The above proposal for describing a Hub using the TDW Hub Architecture Reference Model (HUB-ARM) was inspired by Daniel Buchner’s verbal description of a Hub during the DIF SDS/CS call on Thursday, March 11, 2021 plus subsequent conversations on the DIF SDS/CS mailing list (Adrian Gropper).
I didn’t discover/understand I was a First Principles Thinker until relatively recently. Now, it’s my goto skill. Onward…
“Sometimes called “reasoning from first principles,” the idea is to break down complicated problems into basic elements and then reassemble them from the ground up. It’s one of the best ways to learn to think for yourself, unlock your creative potential, and move from linear to non-linear results.”
“I think it is most important to reason from first principles rather than by analogy. One of the ways we conduct our lives is we reason by analogy. We do this because something was like something else that was done or it was like what other people were doing. It’s mentally easier to reason by analogy rather than from first principles.”
“You boil things down to the most fundamental truths And you say “what are we sure is true” or “as sure as possible, what is true” And then “reason up from there” That takes a lot more mental energy.”
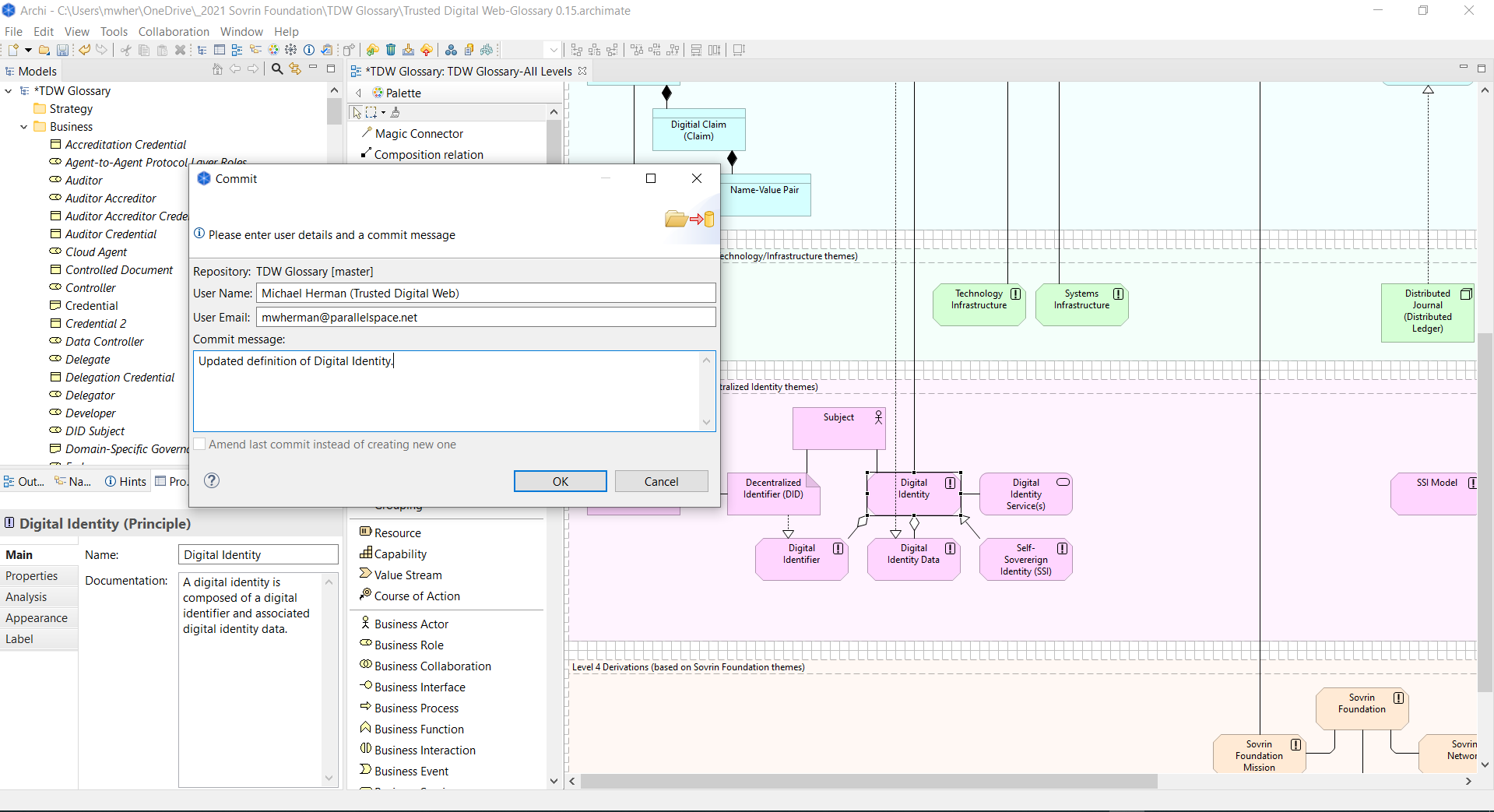
Yesterday afternoon, I downloaded and imported the entire Sovrin Glossary V3 into Archi and the https://github.com/mwherman2000/tdw-glossary-1 repository. It contains all 249 SF Glossary terms and definitions plus a couple dozen of my own definitions (yes, the TDW Glossary supports ingesting multiple upstream glossaries and can create/refresh multiple downstream glossaries.)
Here are some screenshots:
Figure 1. Layered visualization using the TDW Glossary 6-Layer Domain (and Relationship) ModelFigure 2: Digital Identity Neighborhood ExampleFigure 3. Archi free, open-source, GUI tool doing a check-in of the term “Digital Identity” and its definition into the https://github.com/mwherman2000/tdw-glossary-1 repositoryFigure 4. Open Group ArchiMate 3.0 Architecture Modeling Platform support in Archi 4.8.1
Archi Open Source Modeler for Architecture Modeling
The Archi® modeling toolkit is targeted toward all levels of Enterprise Architects and Modelers. It provides a low cost to entry solution to users who may be making their first steps in the ArchiMate modeling language, or who are looking for an open-source, cross-platform ArchiMate modeling tool for their company or institution and wish to engage with the language within a TOGAF® or other Enterprise Architecture framework.
A generic Replication Pipeline is illustrated below.
Figure 1. A Generic Replication Pipeline (Credit: Syntergy Replicator for SharePoint)
Outbound Processing Service
Outbound Processing Service is responsible for capturing and recording Replication Events that occur in the Source Repository. Outbound Processing Service is controlled by Replication Maps which determine what Events need to be captured, packaged, and transferred to the Target Repository. Groups of Replication Events are packaged into two types of messages or objects: Queued Items and Replication Packages.
Queued Item
A Queued Item is a unit of work to be transferred to a Target Repository for remote execution. The Replication Web Service on a Target Repository is called to push a Queued Item from the Source Repository to a Target Repository.
Replication Package
A Replication Package is a collection of one or more Replication Events plus data about the changed information that is packaged in a format specific to the Replication Transport being used. When an Event is being processed, Outbound Processing Service calls the Source repository object model to extract the changed information from the Source Repository.
Package Transfer Service
The Package Transfer Service activity is responsible for the transfer and receipt of Queued Items and the downloading of Replication Packages (Packages) from the Source Repository to the Target Repository. Package Transfer is the process that sits between Outbound Processing Service (on the Source Repository) and Inbound Processing Service (on the Target Repository).
Inbound Processing Service
Inbound Processing Service is responsible for processing the Queued Items and Packages received and accepted by the Target Repository and applying them to the repository. The Queued Items and Packages are applied to the Target Repository content base by calling the Target Repository object model.